背景
起源
TDT research began as a pilot project funded by the U.S. Government’s Defense Advanced Research Project Agency (DARPA) in 1997. The pilot project was followed by yearly benchmark evaluations from 1998 to 2004. 
5个任务具体的内容下面介绍
与事件抽取的区别
event与topic


有的论文的story有不同定义:https://yuque.antfin.com/hvnuga/sxhoe4/vbpqdt#lEAza
但event和topic概念差不多
event:特定的时间和地点发生的新闻,具体发生的事,如:孟晚舟9月25日获释,从加拿大即将回国
topic:多个event的汇总,没有特定的时间、地点。如:孟晚舟案件/孟晚舟获释
五个任务
SS是基础任务,当前使用的不多
FSD & TT 在线运行
topic detection(cluster detection) 可以离线运行,处理大量语料
link detection 是服务于其他任务的子任务,核心任务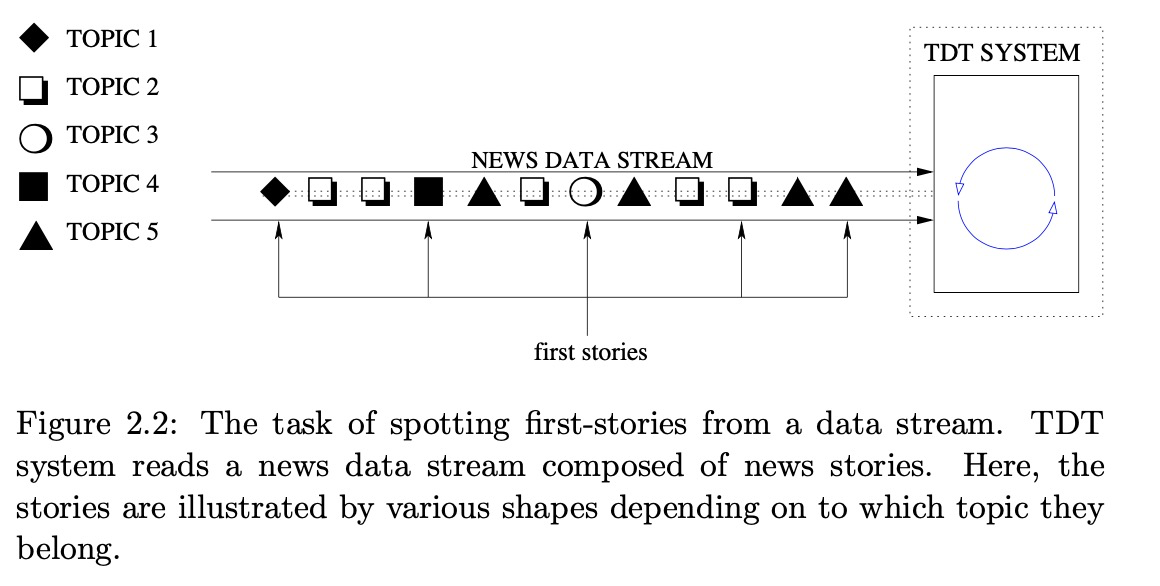
技术演进
VSM
1、UMass
改进tfidf

cos计算相似,大于阈值归为一个topic
2、CMU
KNN(instance-based (or lazy) classifier)
每个topic有几个正样本和负样本
问题
1、事件在发展,质点在漂移,使用原始的模型/数据会让召回下降
- 如何自适应:新事件也加入到描述中,且取最近的/最早的几个事件求相似(都有利弊)
2、基于内容计算而不是基于事件会出问题
- 两个飞机失事的事故很容易放在一起
Language Models
query和doc集合匹配的概率 -> doc集合生成query的概率 -> 语言模型
语言模型 -> 数据稀疏 -> 平滑 -> 线性插值法 -> BackGround model -> relevance model
语言模型: 
线性插值法: 
小结:
1、以上做法的基本假设:词共现越多,两个event越相似,不同的技术在于选择哪些词来共现,如何加权
2、角度不同:query匹配doc set,和doc set生成query
2、相关性模型扩充原event没有但相关的词
Use of semantical and contextual information
- 出发点:类似飞机失事的新闻,除了少数地点、人物不一样,其他描述都类似。
- 方案:从一个向量到多个特征:时间、地点、人物、组织、term,然后计算几个元素的相似性
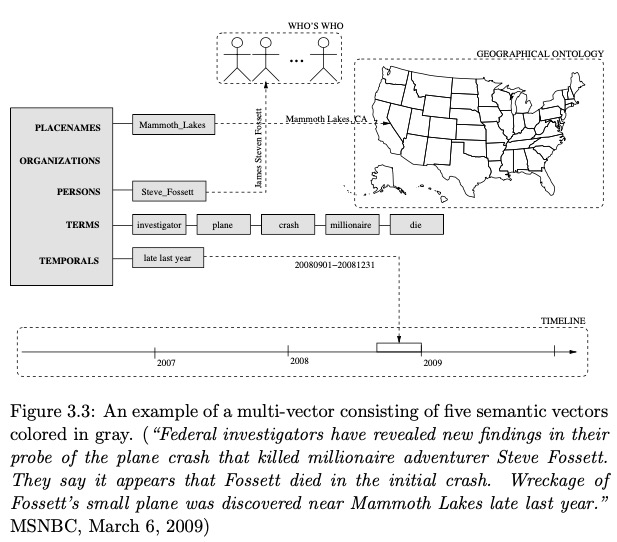
lda
deep-learning
survey on ED model of for Text Data Streams(SNs-2020)

- Query based:抽取时间、地点,关联多个SN下的多个事件,简单但局限在特定事件
- Statistical Based Methods :统计不同时间窗口的关键词-词频/tfidf => 傅立叶变换/小波变换 => 频域
- Probabilistic Based Methods :LDA及变种
clustering based
Graph based

近期的一些论文
文本匹配(Matching Article Pairs with Graphical Decomposition and Convolutions)
1、news多为长文本,长文本的match比sentence/query的匹配难,因为语义更丰富
2、CIG(有权重的概念图)来表示文章,概念是kw或kw集合;两个概念用一个边连接
3、分而治之的思路 部分流程备注
部分流程备注
1、concept和sentience的tfidf计算cos小于阈值的的挂在dummy伪节点上
2、边权重计算:点上附着的sentience concate起来计算两两之间相似度,实验证明tfidf效果最好;
3、社区识别可选,为了降低计算复杂度,效果稍微损失一些
4、sentence 1 和sentence 2都是一个概念下的句子集合
5、孪生encoder:context_layer一般使用 BiLSTM/CNN
6、Term-based:5种特征,TDIDF cos/TF cos/BM25 similarity/Jaccard of 1-gram/Ochiai similarity
7、GCN顶点的特征是两种相似度的concat

8、Global matching是bert出来的结果,不过实验显示增加global matching结果没啥提升。未提供更多信息
9、分而治之的思想:将doc切分为多个概念,然后计算在这些概念上的相似度
newsLens(2017)
抽取
1、extracting keywords from articles:TFIDF>阈值
2、creating topics: local groups of articles in time
文章作为顶点,相似的kw大于阈值就建立边,为解决错连接,使用社区识别做分割
3、solidifying the local topic clusters into stories: long-ranging sets of articles that share a common theme
窗口滑动来扩充新的cluster到topic
linking:滑动窗口产生新的topic与之前的topic的文章重合度大于阈值
spliting:社区发现算法将topic分开
merging:两个话题,随着发展,文章重合数大于阈值。比如:“Olympics in Rio” 与 “Athletes worried about the Zika virus” 
事件都是连续发展的假设有局限性,比如MHMH317马航失联事件,如果与历史topic相似性很大,则merge。
4、automatically naming the stories
“North Korea nu- clear tests”, “Ukraine crisis”, “Ebola outbreak”, “Brexit vote”, “Paris attacks”. The features these names have in common are:
- A story name is a noun phrase, ==> 名词性短语/主谓结构
- It contains a proper noun (entity), ==>含专有名字
- It contains a common noun or word, and
- One of the words is abstract (test, crisis, out- break, …). ==》xxxx案件/事件/事故

可视化(略过)


小结
抽kw -> 窗口内构图(kw共现为边/文章为顶点) -> 社区发现 -> 窗口滑动 -> 合并/分割 -> 命名
1、每次构造local graph,采用一小段时间(比如一周),语料少、社区识别算法加持,效果会好一些(巧妙使用了时间这个要素)
2、采用滑动窗口来模拟事件的发展,然后link/merge/split流程来解决它带来的问题
3、为story命名的思路我我们的做法类似
缺点:
特定语料/大语料有效,无监督不好控制,无法解决多种类型事件的聚合
阈值太多
Event-Driven News Stream Clustering using Entity-Aware Contextual Embeddings(amazon internship)
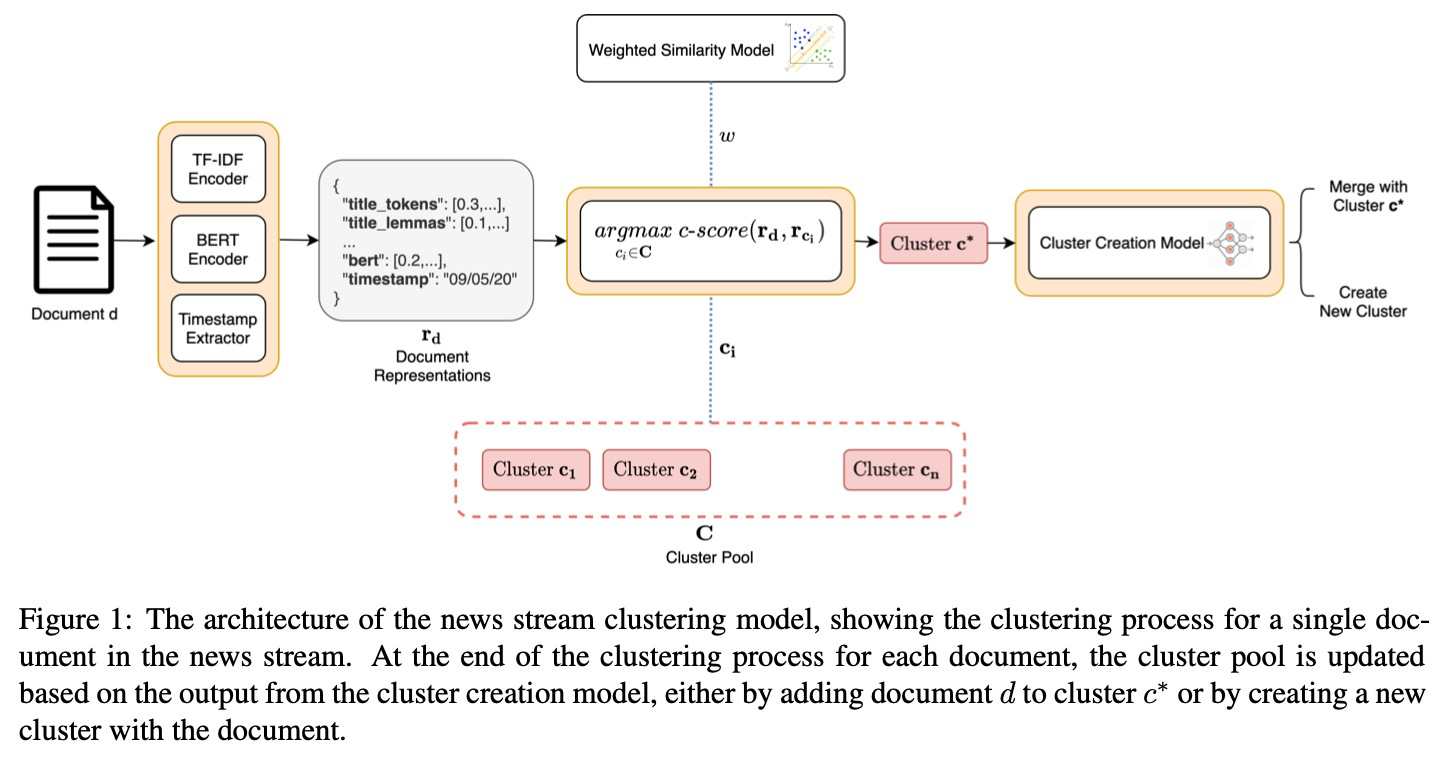
特征:
- title/content/title+content * token/lemmas/entities 一共九个稀疏特征
- bert 结果作为稠密特征(尝试多种bert向量,5种)
- pre-trained Bert
- event-classification bert(分类任务微调)
- event-similarity Bert(相似任务微调)
- entity-aware Bert(引入外部知识、增加特征使用上述两种)
- 抽取时间标准化

c-score :doc和cluster的各特征分别计算相似度,然后加权,权重模型训练通过获得
cluster-creation model 的输入是最相似的那个cluster的表示和相似度,模型是一个浅层网络
story-forest
定义:


美国总统大选是topic,2016年美国大选是story,川普和希拉里的第一次电视辩论是event
流程图

输入输出
输入:doc、feature、pre-trained relation classifer
输出:set(Event)
详细流程
kw抽取 —> co-keywords G(共现数、条件概率) -> 社区发现 -> topic G -> doc G -> relation pred -> 社区发现->Event G -> belong or create story -> update story
特别地:
1、抽关键词使用有监督算法,防止一些不必要的词进入候选,kw可控,GBDT
双层聚合实现doc cluster&event extraction
2、topic G->doc G:doc与topic求tfidf相似度,大于阈值的doc聚合在一起
3、doc G内部,两两doc计算relation,svm预测是否是同一event ,之后社区发现
4、计算doc是否属于现有story:
1) doc和story的keyword的Jaccard similarity > 阈值,story最新的doc标题与之共现词> N
2) update:merge/extent/insert
在线预估流程
new doc -> keywords -> which story -> which event -> update story tree
which story: keyword tf-idf 相似性
which event:candidate event doc relation pred
yes -> merge
no -> which is parent node -> insert/extend,考虑三点
一致性:与中心文档TF的距离
连贯性:s_0-s_j-s_c 链路上一致性的平均
时效性:时间差的反比

若有收获,就点个赞吧
0 人点赞
