CPU内存模型
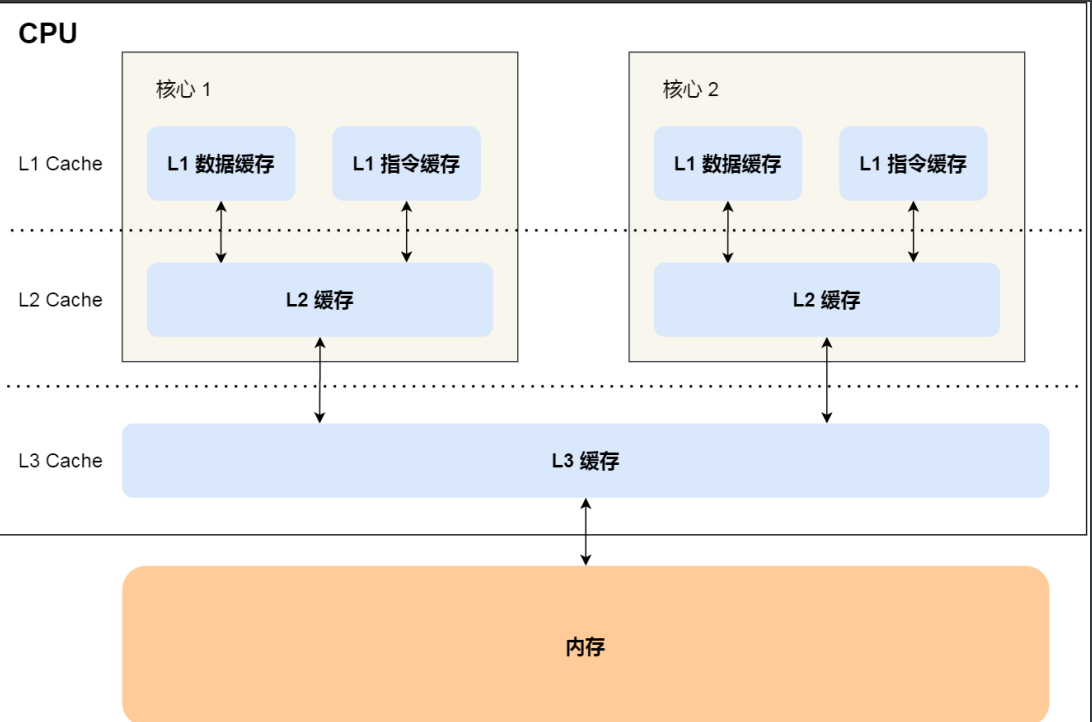
- 在多核⼼的 CPU ⾥,每个核⼼ 都有各⾃的 L1/L2 Cache,⽽ L3 Cache 是所有核⼼共享使⽤的
- 当数据发生改动(缓存与内存的数据不同时),这时候就需要数据同步。
由于CPU基本都是多核的,而L1、L2 Cache又是多核各自独有的,那就会带来缓存一致性问题。
缓存一致性
两个核⼼的 CPU同时运行两个线程,都有一个共同的变量i
假设线程a操作了变量i(递增操作),恰巧这时另一个线程b也在读
而这时线程a还没完成数据同步,则意味着这时候的变量是脏数据,这就是缓存一致性问题。
如何解决呢?要保证以下两点:
- 写传播: 某个 CPU 核⼼⾥的 Cache 数据更新时,必须要传播到其他核⼼的 Cache
- 事务的串行化: 某个 CPU 核⼼⾥对数据的操作顺序,必须在其他核⼼看起来顺序是⼀样的
MESI 协议
MESI协议就做到了 CPU 缓存⼀致性。
- Modified,脏值: 代表该 Cache Block 上的数据已经被更新过, 但是还没有写到内存里。
- Exclusive,独占 : 独占状态的时候,意味着数据只存储在⼀个 CPU 核⼼的 Cache,cpu可以自由写⼊,而不需要通知其他 CPU 核⼼
- Shared,共享: 当我们要更新 Cache ⾥⾯的数据的时候,不能直接修改,⽽是要先向所有的其他 CPU 广播⼀个请求,要求先把其他核⼼的 Cache 中对应的 Cache Line 标记为「⽆效」状态,然后再更新当 前 Cache 里面的数据
Invalidated,已失效 :数据已失效
这四个状态来标记 Cache Line 四个不同的状态。
互斥
当多线程相互竞争操作共享变量时,会发生竞争条件(race condition)
因此我们将此段代码称为临界区(critical section),它是访问共享资源的代码片段,一定不能给多线程同时执行。 这就是互斥。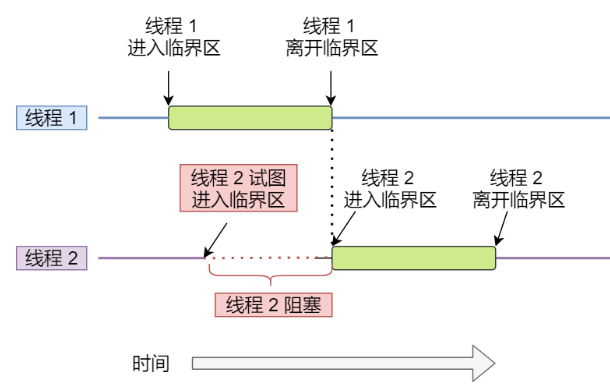
而解决这种问题的办法就要完成进程间同步
- 锁(自旋锁、无等待锁)
- 信号量
自旋锁的缺陷

信号量
通常信号量表示资源的数量,对应的变量是一个整型(sem)变量。
另外,还有两个原子操作的系统调用函数来控制信号量的,分别是:
- P 操作:将 sem 减 1,相减后,如果 sem < 0,则进程/线程进入阻塞等待,否则继续,表明 P 操作可能会阻塞;
- V 操作:将 sem 加 1,相加后,如果 sem <= 0,唤醒一个等待中的进程/线程,表明 V 操作不会阻塞;

进程互斥的实现方法:
软件方式:
- Peterson算法

硬件方式:
- 中断屏蔽
- TestAndSet指令
- swap指令

死锁
死锁的形成条件
- 互斥:线程对于需要的资源进行互斥的访问(例如一个线程抢到锁)
- 持有并等待:线程持有了资源(例如已将持有的锁),同时又在等待其他资源(例 如,需要获得的锁)
- 非抢占:线程获得的资源(例如锁),不能被抢占
- 循环等待:线程之间存在一个环路,环路上每个线程都额外持有一个资源,而这个资源又是下一个线程要申请的
死锁的预防
循环等待破解—>顺序获取锁: 获取锁时提供一个线性的锁, 每次都先申请 L1 然后申请 L2…以此类推
//线程 B 函数,同线程 A 一样,先获取互斥锁 A,然后获取互斥锁 Bvoid *threadB_proc(void *data){printf("thread B waiting get ResourceA \n");pthread_mutex_lock(&mutex_A);printf("thread B got ResourceA \n");sleep(1);printf("thread B waiting get ResourceB \n");pthread_mutex_lock(&mutex_B);printf("thread B got ResourceB \n");pthread_mutex_unlock(&mutex_B);pthread_mutex_unlock(&mutex_A);return (void *)0;}
持有并等待破解—> 原子地抢锁 : 保证了在抢锁的过程中,不发生不合时宜的线程切换
非抢占破解—>

互斥破解—>通过cas构造不需要锁的数据结构
通过调度算法避免死锁:
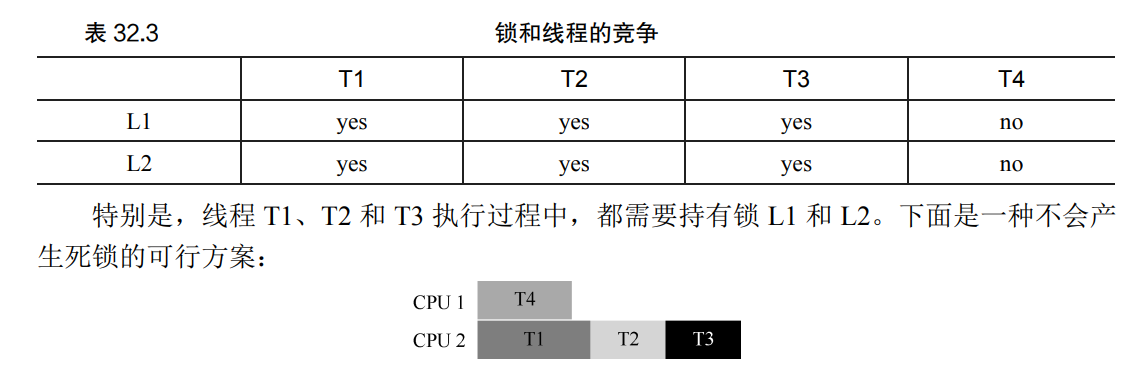
如果多个线程会互相抢占锁,我们就将其错开,如T1、T2 和 T3 运行在同一个处理器上,这种保守的方案会明显增加完成任务的总时间。但为了避免死锁,我们没有这样做, 而是付出了性能的代价。

若有收获,就点个赞吧
0 人点赞
