寄存器
寄存器存储的数据的大小,决定了具体使用哪个寄存器
不同寄存器的作用
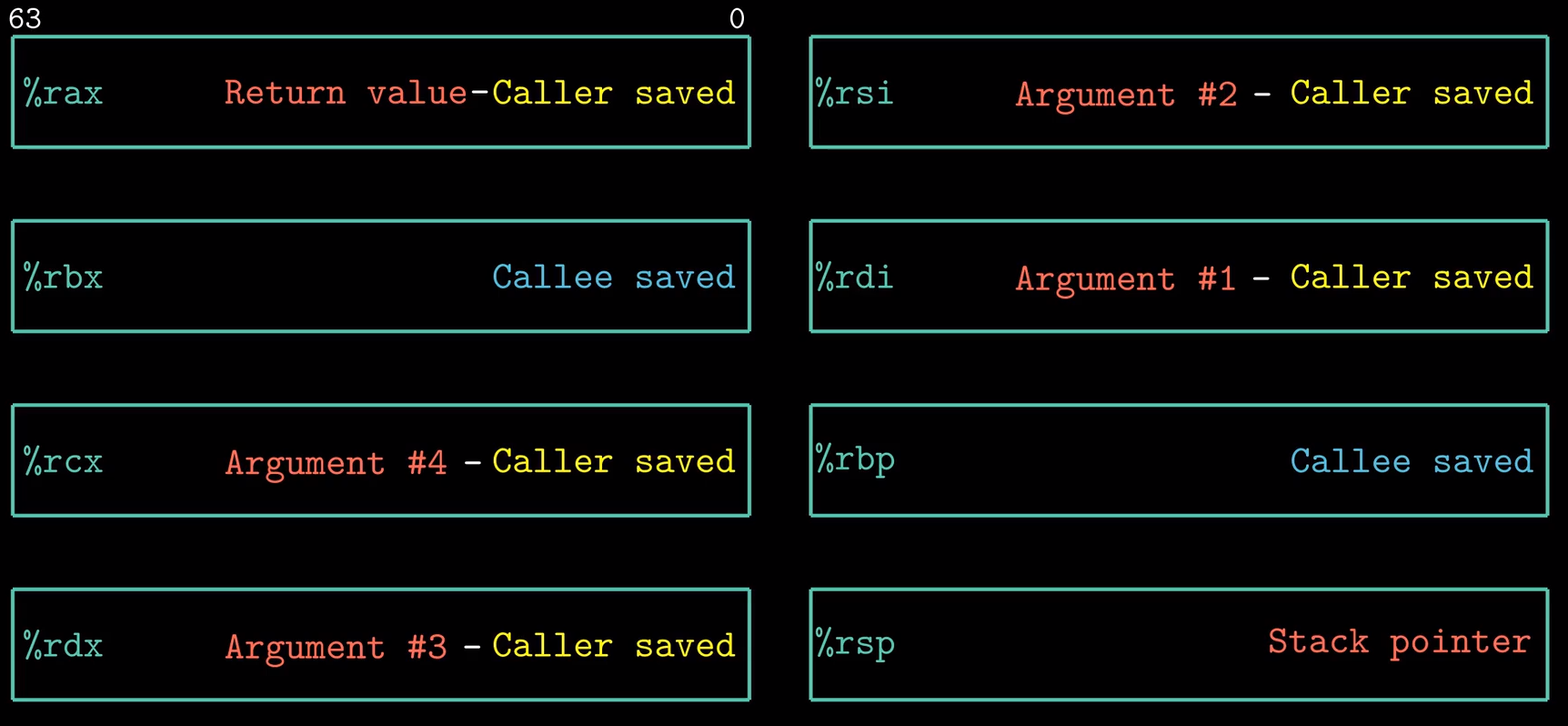
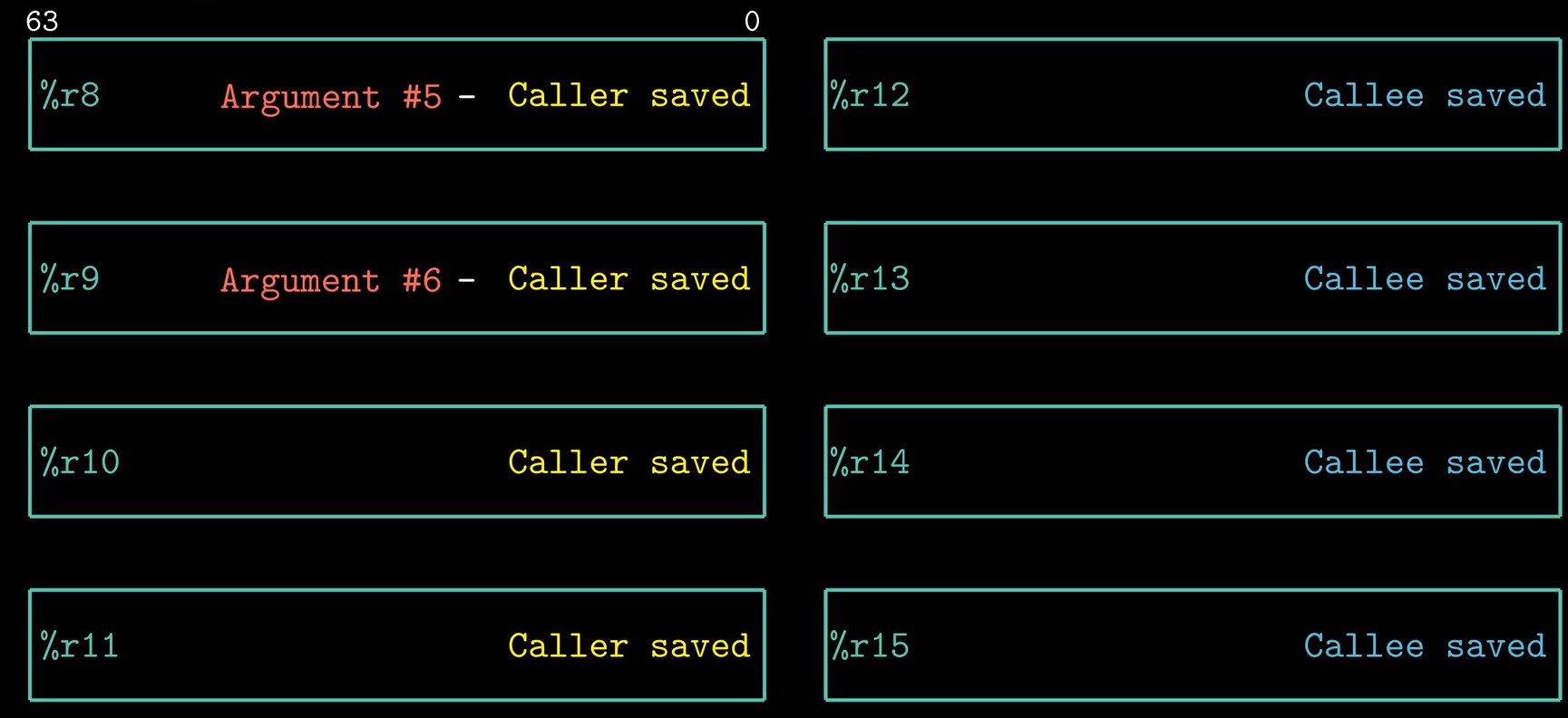
前六个寄存器(%rax, %rbx, %rcx, %rdx, %rsi, %rdi)称为通用寄存器,有其『特定』的用途:
- %rax(%eax) 用于做累加
- %rcx(%ecx) 用于计数
- %rdx(%edx) 用于保存数据
- %rbx(%ebx) 用于做内存查找的基础地址
- %rsi(%esi) 用于保存源索引值
- %rdi(%edi) 用于保存目标索引值
而 %rsp(%esp) 和 %rbp(%ebp) 则是作为栈指针和基指针来使用的。
汇编指令的操作数
操作数有三种基本类型:立即数(Imm)、寄存器值(Reg)和内存值(Mem)。
- 目的操作数不能是一个立即数
寄存器计算
- x86-64 的虚拟地址是由 64 位的字来表示的。在目前的实现中, 这些地址的高 16 位必须设置为 0
当汇编指令以寄存器作为目标时,对于生成小于8字节结果的指令,寄存器中剩下的字节会怎么样,对此有两条规则(记住就行):
- 生成1字节和2字节数字的指令会保持剩下的字节不变;
- 生成4字节数字的指令会把高位4个字节置为0。

当汇编指令以立即数作为源操作数时,该立即数只能是32位的补码表示(然后对该数值进行符号位扩展),且目的操作数只能是寄存器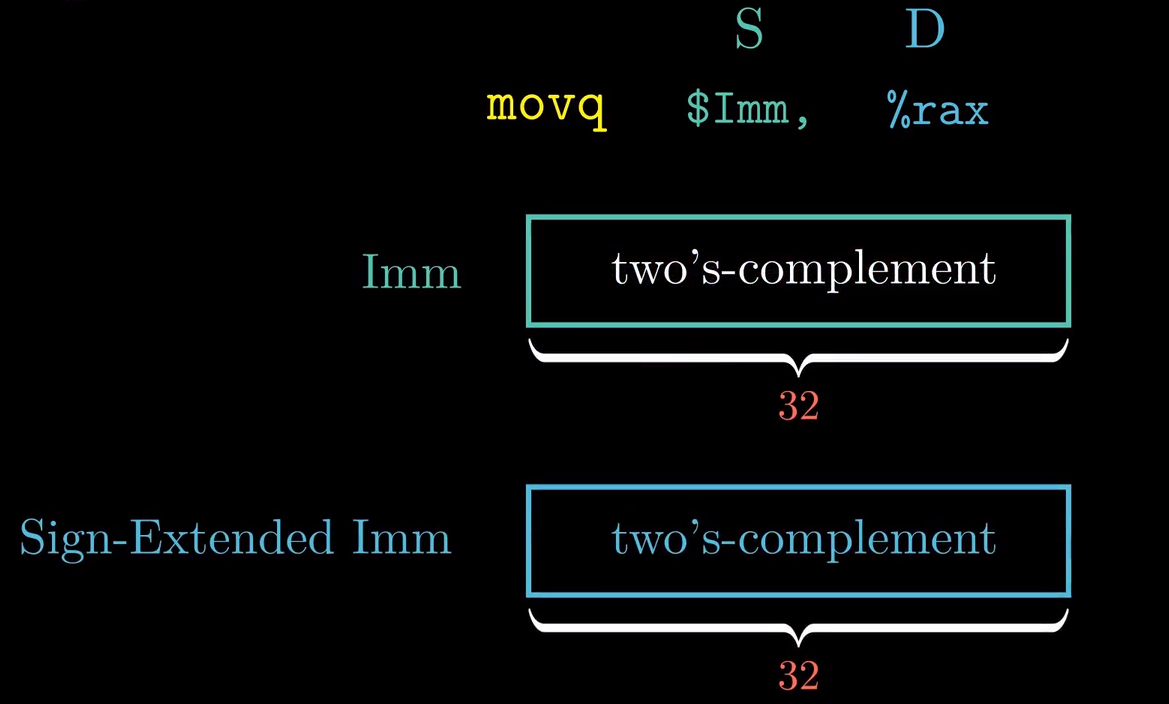
- 当立即数本来就是64位时,会使用movsbsq指令
指令操作
首先看看处理器是如何配合内存进行计算的: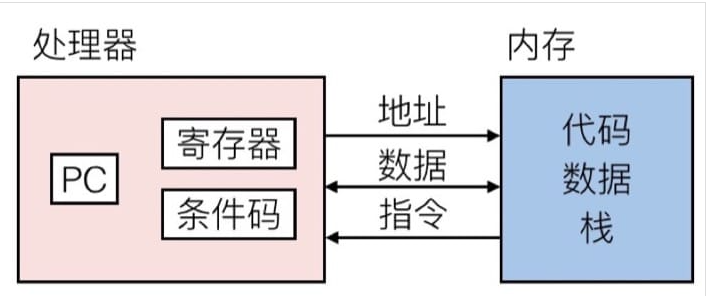
- 程序计数器(PC, Program counter) - 存着下一条指令的地址,在 x86-64 中称为 RIP
- 寄存器(Register) - 用来存储数据以便操作
- 条件代码(Codition codes) - 通常保存最近的算术或逻辑操作的信息,如
进位,也可以用来做条件跳转
汇编代码有固定的指令:
比如这样的形式: movq %rax, (%rbx)
指令语法
Windows用的是Intel格式的汇编 Linux用的是AT&T格式的汇编。
所以之前看到别人在讨论,其实他们都是对的,只是使用的机器不同罢了:
- 在本门课,格式是这样的:操作指令:源:目的
指令寻址
指令寻址分两种情况:
- 普通模式,(R),相当于 Mem[Reg[R]],也就是说寄存器 R 指定内存地址,类似于 C 语言中的指针,语法为:movq (%rcx), %rax 也就是说以 %rcx 寄存器中存储的地址去内存里找对应的数据,存到寄存器 %rax 中
- 移位模式,D(R),相当于 Mem[Reg[R]+D],寄存器 R 给出起始的内存地址,然后 D 是偏移量,语法为:movq 8(%rbp),%rdx 也就是说以 %rbp 寄存器中存储的地址再加上 8 个偏移量去内存里找对应的数据,存到寄存器 %rdx 中
- 完全寻址:D(Rb, Ri, S) -> Mem[Reg[Rb]+S*Reg[Ri]+D],S为系数
lea指令
lea是比较特殊的指令,但也类似于mov指令
因为lea指令将有效地址写入到目的操作数,也就是说:lea的作用是直接操作地址,没有引用内存
- 他的第一个操作数看上去是一个内存引用,但该指令并不是从指定的位置读入数据,而是将有效地址写入到目的操作数
- 他的第二个操作数必须是一个寄存器
主要用法是计算栈顶指针偏移量,leaq 8(%rsp), %rsi 就是把栈顶指针加上 8 得到一个新地址值,然后把这个地址值存到寄存器 %rsi 中
指令汇总

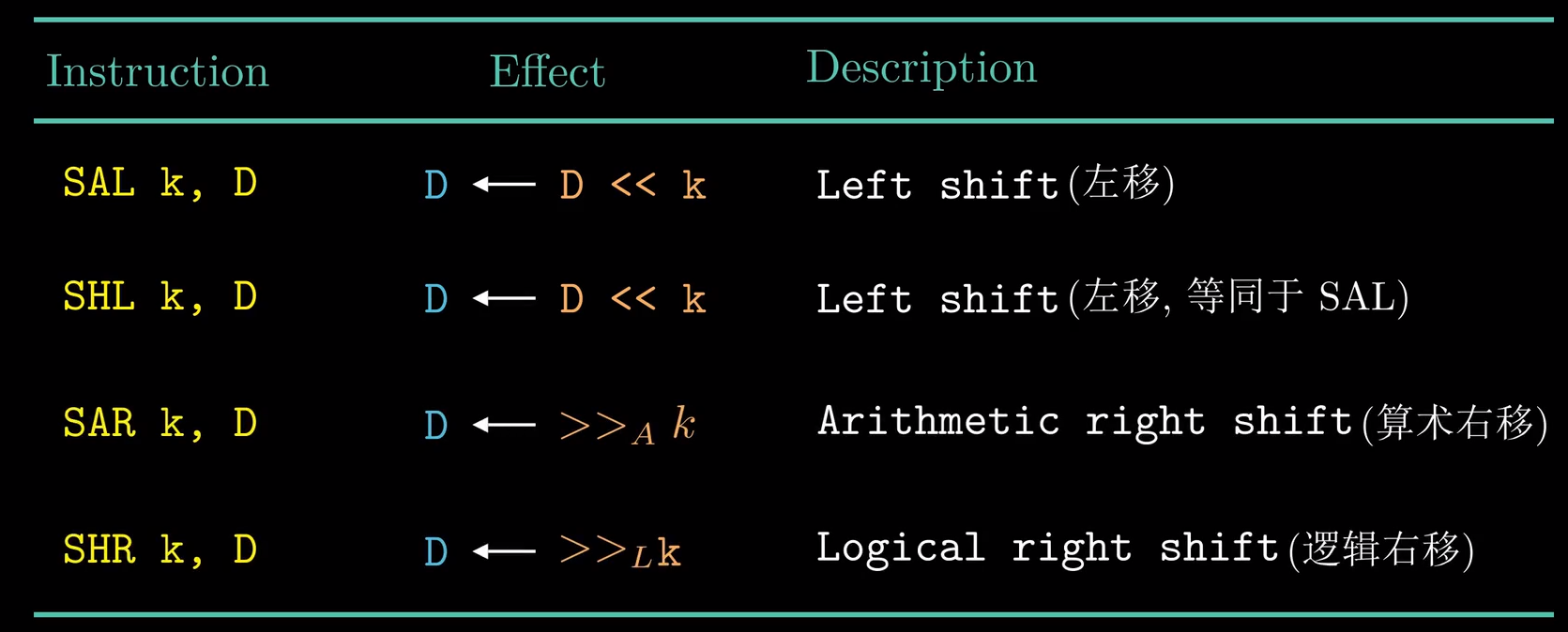
移位指令
流程控制
条件代码与跳转
汇编中用四个标识位用来辅助程序的流程控制的,分别是:
- CF: Carry Flag (针对无符号数)
- ZF: Zero Flag
- SF: Sign Flag (针对有符号数)
- OF: Overflow Flag (针对有符号数)
可以看到以上这四个标识位,表示四种不同的状态。
举个例子,假如我们有一条诸如 t = a + b 的语句,汇编之后假设用的是 addq Src, Dest,那么根据这个操作结果的不同,会相应设置上面提到的四个标识位,而因为这个是执行类似操作时顺带尽心设置的,称为隐式设置,例如:
- 如果两个数相加,在最高位还需要进位(也就是溢出了),那么 CF 标识位就会被置1
- 如果 t 等于 0,那么 ZF 标识位会被置1
- 如果 t 小于 0,那么 SF 标识位会被置1
- 如果发生正溢出和负溢出,那么 OF 标识位会被置 1
这四个条件代码,是用来标记上一条命令的结果的各种可能的,是自动会进行设置的。
跳转指令

过程调用
过程调用(也就是调用函数)具体在 CPU 和内存中是怎么实现的。理解之后,对于递归会有更加清晰的认识。
- 传递控制:调用执行过程代码(call),以及返回调用函数的位置(ret)
- 传递数据:包括过程需要的参数以及过程的返回值
- 内存管理:如何在过程执行的时候分配内存,以及在返回之后释放内存
栈帧
当函数执行所需要的存储空间超出寄存器能够存放的大小时,
就会借助栈上的存储空间,我们把这部分存储空间称为函数的栈帧
运行时栈
所谓的栈,实际上一块内存区域,可以看做是一块连续的大数组
下图中箭头所指的就是寄存器 %rsp 的值,这个寄存器是栈指针,用来记录栈顶的位置。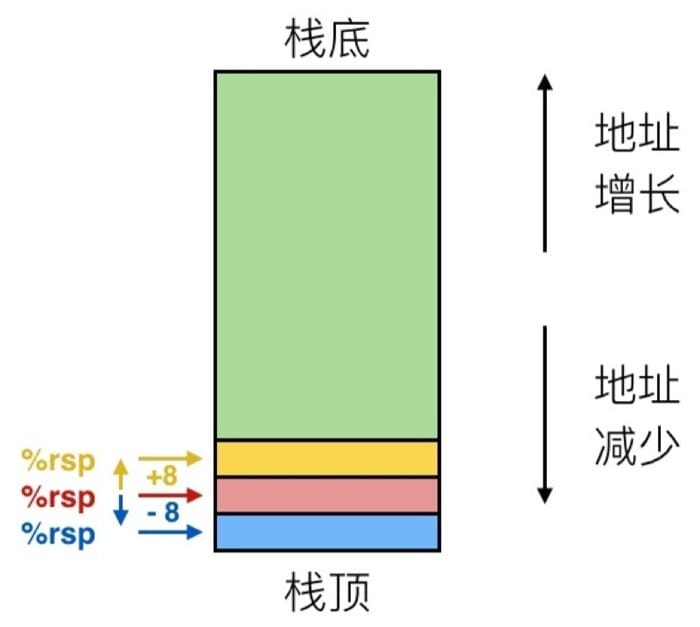
- 往栈内添加数据,其地址是递减的
- 栈底存储的是最先放入栈中的数据,满足先进后出的原则。
- 因此栈顶的地址是最小的。
弹栈压栈
push操作(压栈):对应两个操作 -> %rsp地址-8,将操作数的值写入到栈中对应的位置
pop操作(弹栈):也对应两个操作 -> %rsp地址+8,将栈中位置的数据返回(对象是一个寄存器)
对于pop操作,其实只是移动了栈指针的位置,并不意味着内存上数据的”消除”,这是那块数据不再是栈的一部分了
call指令与ret指令
指令call要做两件事:
- 将函数的第一条指令的地址写入到程序指令寄存器rip中,以此实现函数调用。
- 同时还要将返回地址压入栈中。
这个返回地址就是函数调用执行完毕后,下一条指令的地址。
- 当函数执行完毕,指令ret从栈中将返回地址弹出,写入到程序指令寄存器rip中。
- 函数返回,继续执行main函数中相关的操作。以上整个过程就是函数调用与返回所涉及的操作。
[
](https://blog.csdn.net/qq_29051413/article/details/116542014)
参数的传递
过程调用的参数会放在哪里呢?如果参数没有超过六个,那么会以下6个(%rdi - %r9)中。
如果超过了,会放在自己的栈帧中。
而返回值会放在%rax 中。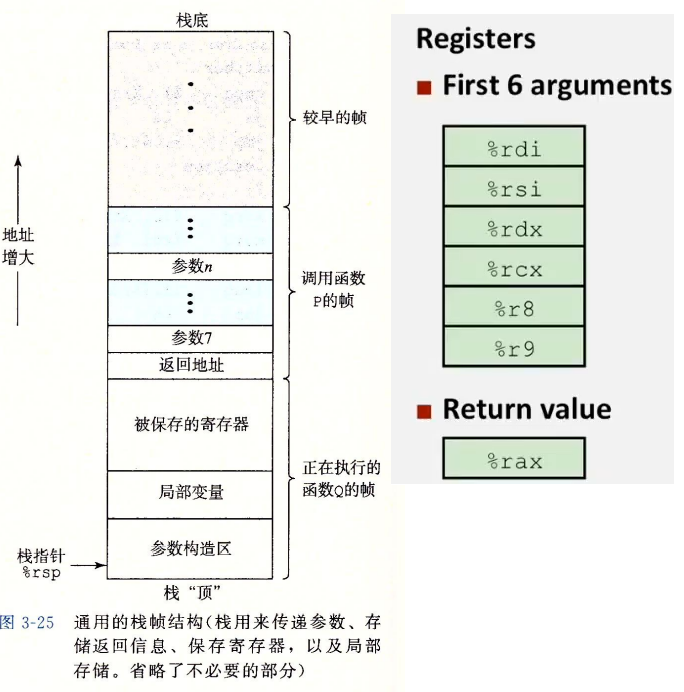
- 这里要求传递的参数是整数或者指针类型(浮点数是另一组寄存器)
被调用者保存寄存器
当需要确保一个过程(调用者)调用另一个过程(被调用者)时,被调用者不会覆盖调用者稍后会使用的寄存器值。
这时候,就会用到被调用者保存寄存器
寄存器 %rbx %rbp %r12~%r15 被划分为被调用者保存寄存器。 它是通过先把原始值压入栈中,期间可以改变寄存器的值,最后在返回前从栈中弹出旧值这一系列做到”保存”的
调用者保存寄存器
除去“被调用者寄存器”所使用的寄存器,剩余的都可以用作“调用者保存寄存器”
可以这样来理解“调用者保存”这个名字:
假设寄存器在函数调用过程会被修改,所以在调用之前首先保存好这个数据是 p( 调用者)的责任。
当函数返回后,又重新覆盖此寄存器的值

数据存储
数据大小的不同: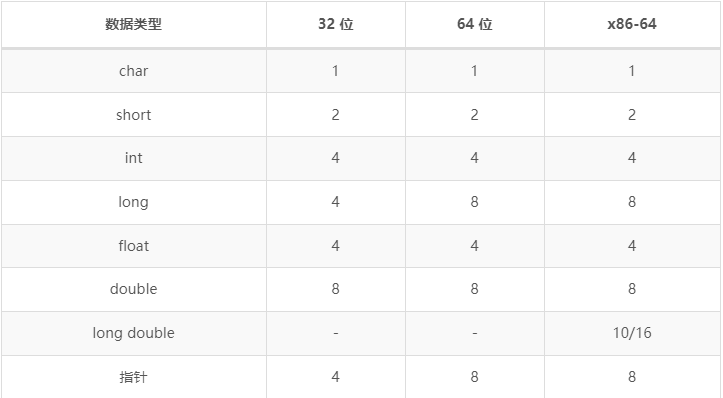
在内存上的体现: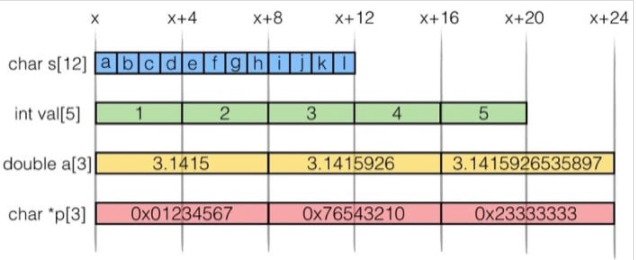
既然是连续的地址空间,就有很多不同的访问方式,比方对于 int val[5] 来说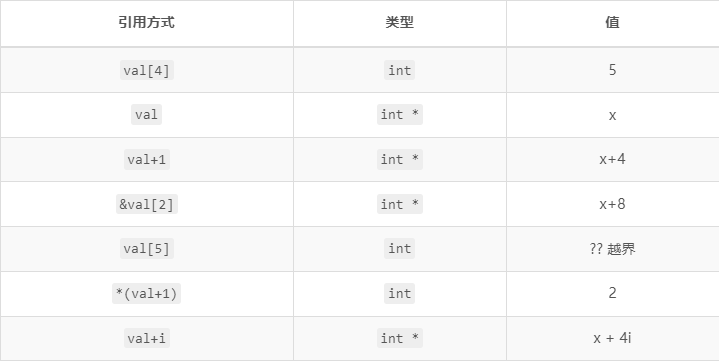
多维数组
对于多维的数组,基本形式是 T A[R][C],R 是行,C 是列,如果类型 T 占 K 个字节的话,那么数组所需要的内存是 R*C*K字节。
多维数组在内存中,是这样存放的:
对齐
对于图中的结构体,它包含两个int类型的变量和一个char类型的变量。
根据前面的知识,我们会直观的认为该结构体占用9个字节的存储空间
但是当使用sizeof函数对该结构体的大小进行求值时,得到的结果却是12个字节。
原因是为了提高内存系统的性能,系统对于数据存储的合法地址做出了一些限制(对齐)。
[
](https://blog.csdn.net/qq_29051413/article/details/116542014)
因此,编译器会在结构体的末端增加3个字节的填充,这样一来,所有的对齐限制都满足了。
对于不同的数据类型,地址对齐的原则是任何K字节的基本对象的地址必须是K的倍数。
悟出两个道理:
- 结构体中数据类型的声明顺序都会影响实际内存分配的大小,而这一点,不学汇编的人是不知道的。
- 根据这种特点,在设计结构体的时候要把大的数据类型放到前面。
联合体:
联合( union),用关键字 union来声明,允许用几种不同的类型来引用一个对象。
其结构的内存大小取决于最大的数据类型。
缓冲区溢出
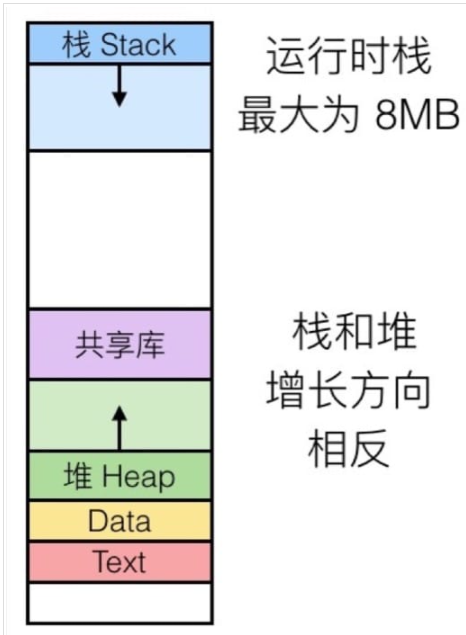
最上面是运行时栈,有 8MB 的大小限制(视操作系统而变化),一般用来保存局部变量。
然后是堆,动态的内存分配会在这里处理,例如 malloc(), calloc(), new() 等。
然后是数据,指的是静态分配的数据,比如说全局变量,静态变量,常量字符串。
最后是共享库等可执行的机器指令,这一部分是只读的。
当我们输入的内容大小超出分配的”运行时栈”时,就会发生段错误: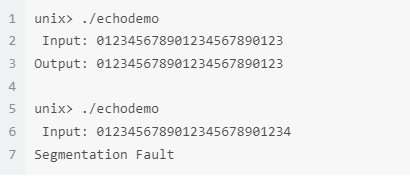
其原理是:c语言没对边界进行限制的,当我们使用的函数也没对用户输入的内容进行限制时,就容易覆盖其他数据
例如函数的返回地址,这时候函数就无法正确执行。 这种恶意覆盖的行为就称为缓冲区溢出。

若有收获,就点个赞吧
0 人点赞
