内建常用数据类型
分类
- 数值型
- int、folat、complex、bool
- 序列sequence
- 字符串str、字节序列bytes、bytearray
键值对
- 集合set、字段dict
数值型
int、float、complex、bool都是class,1、5.0、2+3j都是对象即实例
int: python3de int就是长整型,且没有大小限制,受限于内存区域的大小
float: 由整数部分和小数部分组成。支持十进制和科学及算法表示。C的双精度型实现
complex: 有实数和虚数部分组成,实数和虚数部分都是浮点数,3+4.2j
bool: int的子类,仅有两个实例True、False对应1和0,可以和整数直接运算类型转换
int、floaat、complex、bool也可以当成内建函数对数据进行类型转换
int(x)返回一个整数
float(x)返回一个浮点数
complex(x)、complex(x,y)返回一个复数
bool(x)返回布尔型,False等价的对象取整
//: 向下整除
math.floor: 向下取整
math.ceil : 向上取整
int: 正数向下取整,负数向上取整(截取整数部分)
round: 四舍六入,五取最近偶数常用数值处理函数
- 集合set、字段dict
min()、max()
- abc()
- pow(x,y)等于x y
- math.sqrt() 等于x ** y
- 进制函数,返回值是字符串
- bin()、oct()、hex()
math模块
线性表(简称表),是一种抽象的数学概念,是一组元素的序列的抽象,他拥有无穷个元素组成(0个或任意个)
- 顺序表: 使用一大块连续的内存序列存储表中的元素,这样实现的表称为顺序表,或称为连续表。
- 在顺序表中,元素的关系使用顺序表的存储顺序自然地表示
- 链接表: 在存储空间中将分散存储地元素链接起来,这种实现称为链接表,简称链表
列表如同地铁站排好地队伍,有序,可以插队,离队,索引。
链表如同操场上手拉手地小朋友,有序但空间排列随意。或者可以想象成一串带线地珠子,随意盘放在桌上。也可以离队、插队、也可以索引。
对比体会一下,这两种数据结构地增删改查。
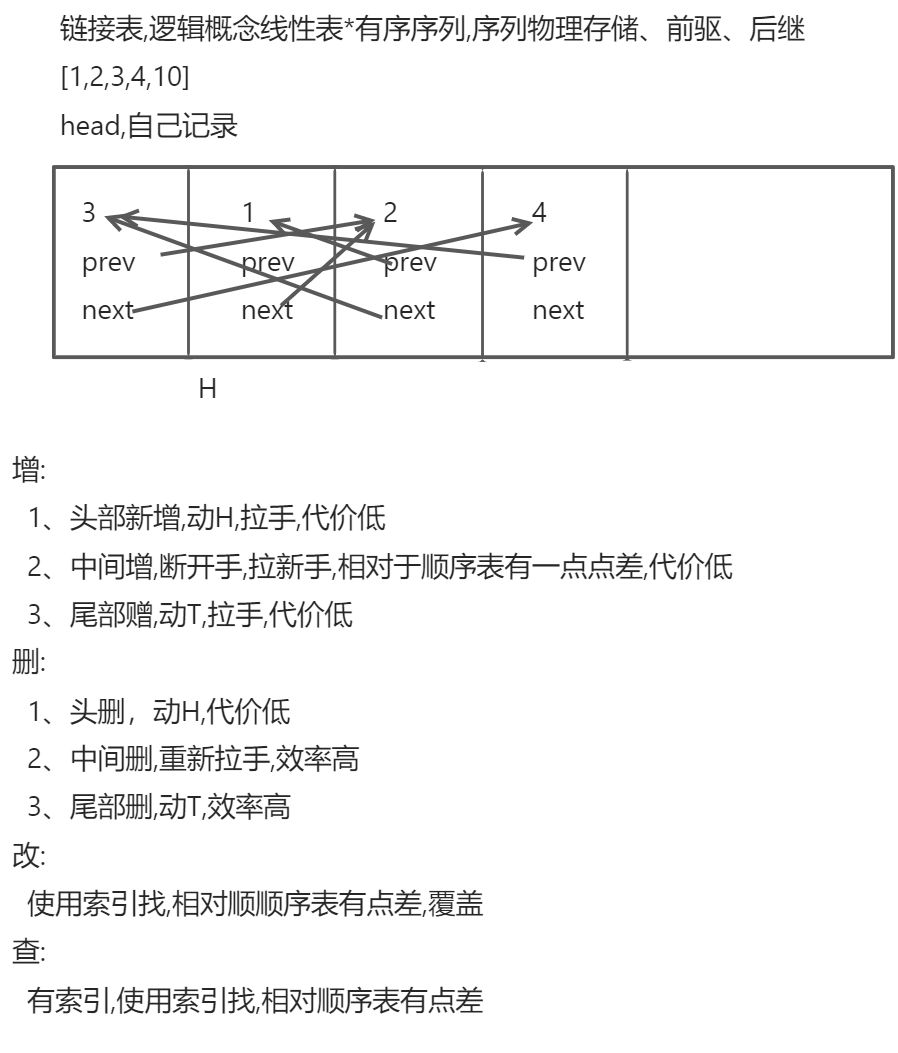

列表list
初始化
- list() —> new enpty list
- list(ieterable) —> new list initialized from iter able’s items
- []
列表不能一开始就定义大小
ls1 = []ls2 = list()ls3 = [2, 'ab', [3, 'abc'], (5, 30, 50)] #列表是要给容器,元素可以是其他类型ls4 = list(range(5)) #非常常用的构造方式,将一个可迭代对象转换为一个列表
索引
索引,也成为下标
- 正索引: 从左至右,从0开始,为列表中每一个元素标号
- 如果列表有元素,索引范围[0,长度-1]
- 负索引: 从右到左,从-1开始
- 如果列表有元素,索引范围[-长度,-1]
- 正、负索引不可以超界,否则引发异常IndexError
- 为了理解方便,可以认为列表是从左到右排列的,左边是头部,右边是尾部,左边是下界,右边是上界
- 列表通过索引访问,list[index],index就是索引,使用中括号访问呢
使用索引定位访问元素的使用复杂度为O(1),这是最快的方式,是列表最好的使用方式
查询
- index(value,[start,[stop]])
- 通过值value,从指定区间查找列表内的元素是否匹配
- 匹配第一个就立即返回索引
- 匹配不到,抛出异常ValueError
- count(value)
- 返回列表中匹配value次数
- 时间复杂度
- index和count方法都是O(n)
- 随着列表数数据规模的增大,而效率下降
如何返回列表元素的个数?如何遍历?如何设计高效?
append(object) -> None
- 列表尾部追加元素,返回None
- 返回None就以为着没有新的列表产生,就地修改
- 定位时间复杂度是O(1)
- insert(index,object) ->None
- 再指定的索引index处插入元素object
- 返回None就意味着没有新的列表产生,就地修改
- 定位时间复杂度是O(1)
索引能超上下界吗?
extend(iteratable) -> None
- 将可迭代对象的元素追加进来,返回None
- 就地修改,本列表自身扩展
- -> list
- 链接操作,将两个列表连接起来,产生新的列表,原列表不变
- 本质上调用的是魔术方法add()方法
- -> list
- -> list
- 重复操作,将本列表元素重复n次,返回新的列表
这个重复操作看似好用,如果原理掌握不好,非常危险ls1 = [1] * 5ls2 = [None] * 6ls3 = [1,2] * 3ls4 = [[1]] * 3
x = [1] * 3x[0] = 100print(x)
y = [[1]] * 3print(y)#下面会输出什么结果?x = [[1]]y = [x] * 3y[1][0] = 500y
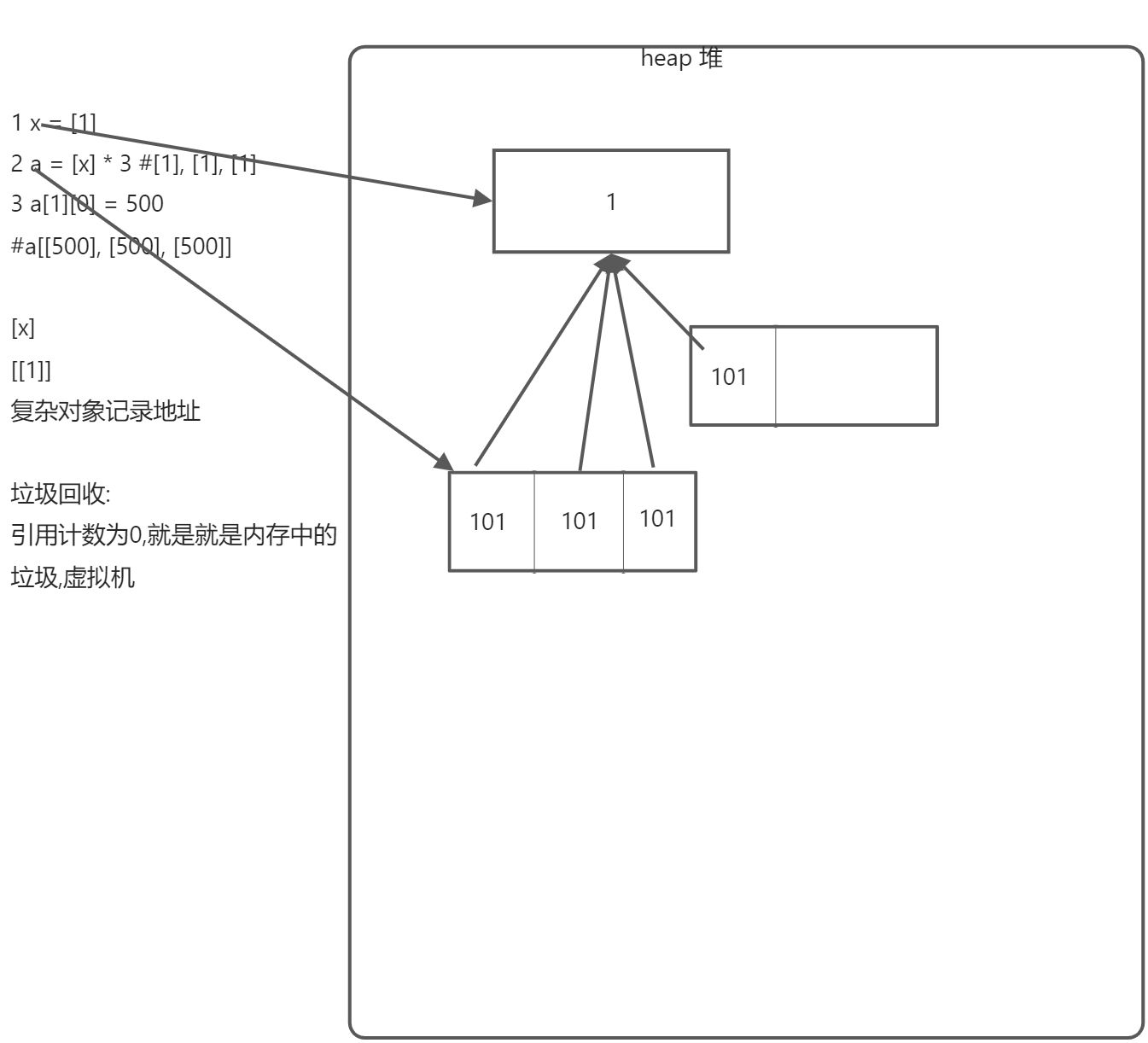
再Python中一切皆对象,而对象都是引用类型,可以理解为地址指针指向这个对象。
但是,字面常量字符串、数值等表现却步像引用类型,暂时可以成为简单类型。
而列表、元组、字典、包括学习的类和实例都是可以认为是引用类型。
可以认为简单类型直接存在列表中,而引入类型只是把引入地址存在了列表中。删除
- 重复操作,将本列表元素重复n次,返回新的列表
- -> list
remove(value) ->None
- 从左至右查找第一个匹配value的值,找到就移除该元素,并返回None,否则ValueError
- 就地修改
- 效率较低
- pop([index]) ->item
- 不指定索引index,就从列表尾部弹出一个元素
- 指定索引index,就从索引处弹出一个元素,索引超界抛出IndexError错误
- 效率? 指定索引的时间复杂度
clear() ->None
reverse() ->None
- 将列表元素反转,返回None
- 就地修改
这个方法最好不用,可以到这读取,都不要反转。 :::info print(list(reversed(a))) :::
排序
- sort(key=None,reverse=False) -> None
- 对列表元素进行排序,就地修改,默认升序
- reverse为True,反转,降序
- key一个函数,指定key如何排序,lst.sort(key=function)
如果排序是必须的,那么排序.排序效率高么?
:::info
vowels = [‘e’, ‘a’, ‘u’, ‘o’, ‘i’]
vowels.sort(reverse=True)
print(‘降序输出:’, vowels)
:::
in成员操作
'a' in ['a', 'b', 'c'][3, 4] in [1, 2, 3, [3,4]]for x in [1,2,3,4]:pass
列表复制
a = list(range(4))b = list(range(4))print (a == b)c = ac[2] = 10print(a)print(a == b)print(a == c)
问题:
1.最终a和b相等么? a和b分别存这什么元素
2.a和c相等么? 为什么? c = a 这一句有复制么
下面的程序a 和b相等么
a = list(range(4))b = a.copy()print(a == b)a[2] = 10print(a == b)
a = [1, [2, 3, 4], 5]b = a.copy()print(a == b)a[2] = 10print(a == b)a[2] = b[2]print(a === b)a[1][1] = 1--print(a == b)print(a)print(b)
列表的内存模型和深浅拷贝
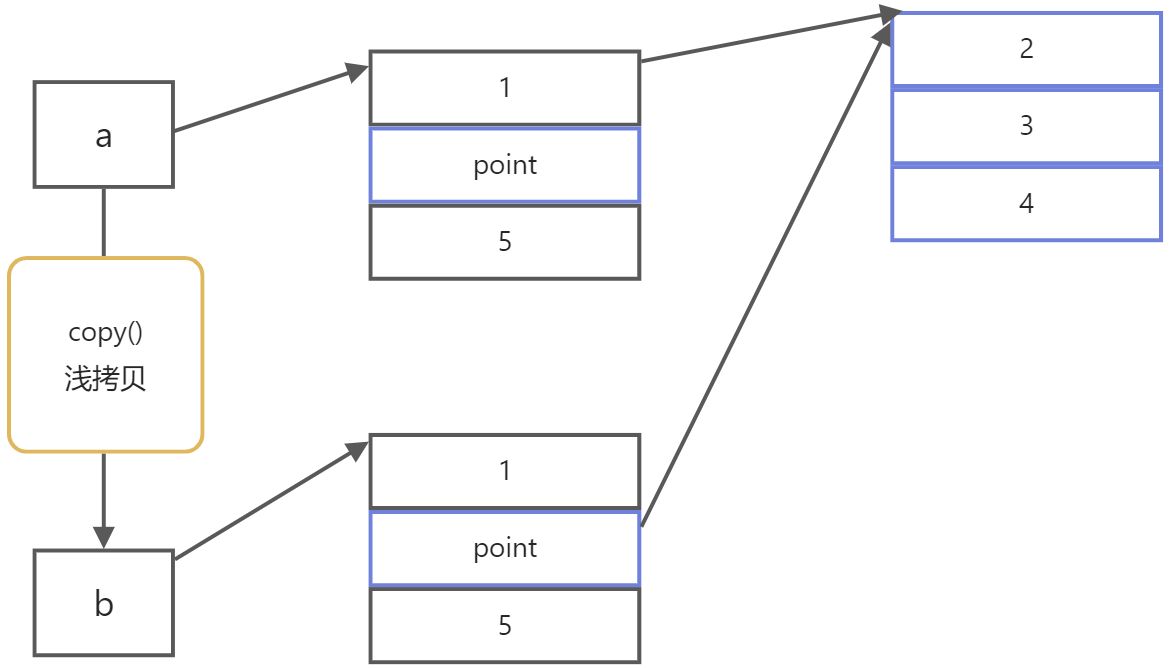
- shadow copy
- 影子拷贝,也叫浅拷贝。遇到引用类型数据,仅仅复制一个引用而已
- deep copy
- 深拷贝,往往会递归复制一定深度
import copya = [1, [2, 3], 4]b = copy.deepcopy(a)print(a == b)a[1][1] = 100print(a == b)print(a)print(b)
Python内建数据类型,内部都实现了==,他的意思是内容比较
- 深拷贝,往往会递归复制一定深度
作业一:
求100内奇数和
sum = 0for i in range(1,101):if bool(i & 1) == True:sum += iprint(sum)
作业二: 求100内斐波那契数列
a, b = 1, 1while a < 100:print(a, end=' ')a, b = b, a + b
作业三: 求斐波那契数列第101项目
#方法一a = 1b = 1for count in range(99):a, b = b, a + bprint(b)
打印如下菱形
*************************#方法一n = 7e = n // 2for i in range(-e , e + 1):if i < 0:print(" " * -i, end='')print('*' * (n - 2 * -i))else:print(' ' * i, end='')print('*' * (n - 2 *i))#方法二n = 15e = n // 2for i in range(-e ,e+1):print("{:^{}}".format('*' * (n - 2 * abs(i)), n))
随机数
- random模块
- random.randint(a,b)返回[a, b]之间的整数
- random.randrange([start,]stop,[,step])从指定范围内,按指定计数递增的集合中获取一个随机数,计数缺省值为1.random.randrage(1,7,2)
- random.choice(seq)从非空序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。random.choice([1,3,5,7])
- 3.6开始提供choices,一次从样本中随机选择几个,可重复选择,可以额指定权重
- random.shuffle(list) -> None就地打乱列表元素
- sample(population,k)从样本空间或总体(序列或者集合类型)中随机取出k个不同的元素,返回一个新的列表
- random.sample([‘a’, ‘b’, ‘c’, ‘d’],2)
- random.sample([‘a’, ‘a’], 2)会返回什么结果
- 每次冲样本空间采集,在这一次不可重复取同一个元素 ```python import random for i in range(10): print(random.randint(1, 5)) print(“-“ 30) for i in range(10): print(random.randrage(1, 5)) print(“-“ 30)
x = [1, 2 ,3, 4, 5] for i in range(10): print(random.choice(x)) print(“-“ * 30)
观察0和1的比例
for i in range(10): print(random.choices([0, 1], k=6)) print(“-“ * 30) for i in range(10): print(random.choices([0, 1], [10, 1],k=6))
x = [1, 2, 3, 4, 5] for i in range(5): print(random.samplle(x, 5l))
<a name="S6sJQ"></a># 元组- 一个有序的元素组成的集合- 使用小括号表示- 元组是不可变对象<a name="KaQfW"></a>## 初始化- tuple() ->empty tuple- tuple(iterable) -> tuple initialized from iterable's items```pythont1 = () # 空元组t2 = (1,) #必须有这个逗号t3 = (1,) * 5t4 = (1, 2, 3)t5 = 1, 'a't6 = (1, 2, 3, 1, 2, 3)t7 = tuple() #空元组t8 = tuple(range(5))t9 = tuple([1, 2, 3])
索引
查询
方法和列表一样,时间复杂度也一样. index、count、len等
增删改
元组元素在初始化的时候已经定义好了,所以不能为元素增加元素、也不能从中删除元素、也不能修改元素的内容。
但是要注意以下列子
t1 = ([1]) * 3t1[1] = 100 #?#注意下面的例子t2 = ([1],) * 3print(t2)t2[1] = 100t2[0][0] = 100print(t2)
字符串str
- 一个个字符串组成的有序的列表,是字符的集合
- 使用单引号、双引号、三引号引住的字符序列
- 字符串是不可变对象,是字面常量
初始化
s1 = 'String's2 = "String2"s3 = """this's a "String" """s4 = 'hello \n Wrod's5 = r"hello \n Wrod"s6 = 'C:\windows\nt's7 = R"C:\windows\nt"s8 = 'C:\windows\\nt'name = 'tom'; age = 20s9 = f'{name}, {age}'sql = """select * from user where name='tom' """
r前缀: 所有字符都是本来的意思,没有转义
f前缀: 3.6开始,使用变量插值
索引
字符串是序列,支持下标访问。但不可变,不可以修改元素。
sql = "select * from user where name='tom'"print(sql[4]) #字符串'c'sql[4] = 'o' #不可以
连接
+加号
- 将2个字符串连接起来
- 返回一个新的字符串
join方法
- sep.join(iterable)
- 使用指定字符串作为分隔符,将可迭代对象中字符串使用这个分隔符拼接起来
- 可迭代对象必须是字符串
返回一个新的字符串
x = 'ab'x = x + 'ca'print(','.join(x))print('\t'.join(x))print('\t'.join(x))
字符查找
find(sub[, start][, end]) ->int
- 在指定的区间[start, end], 从左至右,查找子串sub
- 找到返回正索引,没找到返回-1
- rfind(sub[, start][, end]) ->int
- 在指定的区间[start, end), 从右至左,查找子串sub
- 找到返回正索引,没找到返回-1 ```python s = ‘ztlinux.cn’ print(s.find(‘cn’)) print(s.find(‘cn’, 3)) print(s.find(‘cn’, 4)) print(s.find(‘cn’, 6, 9)) print(s.find(‘cn’, 7, 20)) print(s.find(‘cn’, 200))
s = ‘ztlinux.cn’ print(s.rfind(‘cn’)) print(s.rfind(‘cn’, 3)) print(s.rfind(‘cn’, 4)) print(s.rfind(‘cn’, 6, 9)) print(s.rfind(‘cn’, 7, 20)) print(s.rfind(‘cn’, 200))
这两个方法只是找字符串的方向不同,返回值一样。找到第一个满足要求的字串立即返回。特别注意返回值.找不到返回的是负数-1.<br />这两个方法效率不高,都是在字符串中遍历搜索,但是如果找到字串工作必不可少,那么必须这么做,能少做就少做- index(sub[, start[, end]]) -> int- 在指定区间[start,end),从左至右,查找子串sub- 找到返回正索引,没找到抛异常ValueError- rindex(sub[, start[ end ]]) - > int- 在指定的区间[start, end), 从左至右,查找子串sub- 找到返回正索引,没找到抛出异常ValueErrorindex和find方法很像,不好的地方在于找不到抛异常。推荐使用find方法。```pythons = 'ztlinux.tk'print(s.index('tk'))print(s.index('tk', 3))print(s.index('tk', 4))#print(s.index('tk', 6, 9)) 抛异常print(s.index('tk', 7, 20))#print(s.index('tk', 200)) #抛异常
count(sub[, start[, end]]) ->int
在指定的区间[start, end),从左至右,统计子串sub出现的次数
s = 'ztlinux.tk'print(s,count('tk'))print(s.count('tk', 4))
- 时间复杂度
- find、index和count方法都是O(n)
- 随着字符串数据规模的增大,而效率下降
len(String)
split(sep=None,maxsplit=-1) -> list of strings
- 从左至右
- sep指定分割字符串,缺省的情况下空白字符串作为分隔符
- maxsplit指定分割的次数, -1表示遍历整个字符串
- 立即返回列表
- rsplit(sep=None, maxsplit=-1) -> list of strings
- 从右向左开始切,到那时输出的字符串字符不会反
- sep指定分割字符串,缺省的情况下空白字符串作为分隔符
- maxsplit指定分割的次数, -1表示遍历整个字符串
- 立即返回列表
- splitlines([keepends]) -> list of strings
- 按照行来切分字符串
- keepends指的是是否保留行分隔符
- 行分隔符包括\n、\r\n、\r等 ```python s = ‘,’.join(‘abcd’) print(s.split(‘,’)) print(s.split()) print(s.split(‘,’, 2))
s1 =’\na b \tc\nd\n’ print(s1.split()) print(s1.split(‘ ‘)) print(s1.split(‘\n’)) print(s.split(‘b’))
print(s1.splitlines())
- partition(sep) ->(head,sep,tail)- 从左至右,遇到分隔符就把字符串分割成两部分,返回头、分隔符、尾三部分的三元组- 如果没有找到分隔符,就返回头、2个空元素的三元组- sep分割字符串,必须指定- rpartition(sep) ->(head, sep, tail)- 从右到左,遇到分隔符九八字符串分割成两部分,返回头、分隔符、尾三部分的三元组- 如果没有找到分割符,就返回2个空元素和尾的三元组```pythons = ','.join('abcd')print(s.partition(','))print(s.partition('.'))print(s.rpartition(','))print(s.rpartition('.'))
替换
- replace(old,new,[, count]) ->str
- 字符串中找到匹配替换为新子串,返回新字符串
- count表示替换几次,不指定就是全部替换 ```python s = ‘,’.join(‘abc’) print(s.replace(‘,’, ‘ ‘)) print(s.replace(‘,’,’ ‘, 2))
s1 = ‘www.ztlinux.tk’ print(s1.replace(‘w’, ‘a’)) print(s1.replace(‘ww’, ‘a’)) print(s1.replace(‘ww’, ‘w’)) print(s1.replace(‘www’, ‘a’))
<a name="E6PvX"></a>## 移除空白字符- strip([chars]) ->str- 在字符串两端去除指定的字符集charts中的所有字符- 如果charts没有指定,去除两端的空白字符- lstrip([chars])->str,去除左端空白字符- rstrip([chars]) ->str,去除右端空白字符```pythons = '\t\r\na b c,d\ne\n\t'print(s.strip())print('-' * 30)print(s.strip('\t\n'))print('-' * 30)print(s.strip('\t\ne\r'))
首尾判断
- endswith(suffix[, start[, end]]) ->bool
- 在指定的区间[start,end),字符串是否是suffix结尾
startswith(prefix[, start[,end]]) ->bool
upper()大写
- lower()小写
- swapcase()交换大小写
- isalnum() ->bool是否是字母和数字组合
- isalpha()是否是字母
- isdecimal()是否只包含十进制数字
- isdigit()是否全部数字(0~9)
- isidentifier(是不是字母和下划线开头),其他都是字母、数字、下划线
- islower()是否都是小写
- isupper()是否全部大写
-
格式化
简单的使用+或者join也可以拼接字符串,但是需要先转换数据到字符串后才能拼接。
C风格printf-style
占位符: 使用%喝格式字符,例如%s、%d
- 装饰符: 在占位符中还可以插入装饰符,例如%03d
- format % values
- format是格式字符串,values是被格式的值
- 格式字符串是被格式的值之间使用%
- values只能是一个对象,可以是一个值,可以是一个元素个数喝占位符数目相等的元组,也可以是一个字典 | 符 号 | 描述 | | —- | —- | | %c | 格式化字符及其ASCII码 | | %s | 格式化字符串 | | %d | 格式化整数 | | %u | 格式化无符号整型 | | %o | 格式化无符号八进制数 | | %x | 格式化无符号十六进制数 | | %X | 格式化无符号十六进制数(大写) | | %f | 格式化浮点数字,可指定小数点后的精度 | | %e | 用科学计数法格式化浮点数 | | %E | 作用同%e,用科学计数法格式化浮点数 | | %g | %f和%e的简写 | | %G | %f 和 %E 的简写 | | %p | 用十六进制数格式化变量的地址 |
"I am %03d % (20,)"'I like %s.' % ' Python'"%3.2f%% 0x%x %#x % (89.7654, 10, 256)" #宽度为3,小数点后2位"I am %-5d % (20,)""%(host)s.%(domain)s" % {'domain' : 'ztlinux.tk', 'host': 'www'}
format函数
Python2.5之后,字符串类型提供了format函数,功能更加强大,鼓励使用。 :::info “{} {xxx}”.format(args, *kwargs) ->str :::
- args是可变的位置参数
- kwargs是可变关键字参数,写作a=100
- 使用花括号作为占位符
- {}表示按照顺序匹配位置参数, {n}表示取位置参数索引位n的值
- {xxx}表示在关键字参数中搜索名称一致的
- {{}}表示打印花括号
# 位置对应"{}:{}".format('127.0.0.1', 8080)# 位置或关键字对应"{server} {1}:{0}".format(8080, '127.0.0.1', server='Web Server Info: ')#访问元素"{0[0]}.{0[1]}".format(('ztlinux', 'com'))#进制"{0:d} {0:b} {0:o} {0:x} {0:#X}".format(31)
# 浮点数print("{}".format(3**0.5)) #print("{:f}".format(3**5))print("{:10f}".format(3**5))print("{:2}".format(102.231)) #宽度为2print("{:2}".format(1)) #宽度为2print("{:.2}".format(3**0.5)) #宽度为2print("{:.2f}".format(3**0.5))print("{:3.2f}".format(3**0.5))print("{:20.3f}".format(0.2745))print("{:3.3%}".format(1/3))#注意宽度可以被撑破
| 符号 | 说明 | 示例 | | —- | —- | —- | | : | 插入对其,占位符等 | {:3} | | < | 左对齐 | print(“{}{}={:<10}”.format(5, 6, 56)) | | > | 右对齐 | | | ^ | 居中 | | | {:.2f} | 把输入内如改为浮点型,保留小数点两位。 | | | {:3.2} | 3为占位符。 | |# 对齐print("{}*{}={}".format(5, 6, 5*6))print("{}*{}={:2}".format(5, 6, 5*6))print("{1}*{0}={2:3}".format(5, 6, 5*6))print("{1}*{0}={2:0>3}".format(5, 6, 5*6))print("{}*{}={:#<3}".format(4, 5, 20))print("{:#^7}".format('*' * 3)) #占位7个,剧中对其,其他空白字符填充#
字节序列
Python3引入两个新的类型bytes、bytearray.
bytes不可变字节序列;bytearray是可变字节数组
编码与解码
编码: str — bytes,将字符串这个字符序列使用指定字符集encode编码为一个个字节组成的序列bytes
解码: bytes或bytearray — str,将一个个字节按照某种指定的字符集解码为一个个字符串组成字符串
print("abc".encode()) #缺省值为utf-8编码print("啊".encode('utf-8'))print("啊".encode('gbk'))print(b'abc'.decode('utf-8'))print(b'\xb0\xa1'.decode('gbk'))
ASCII
ASCII(American Standard Code for Information interchange,美国信息交换标准代码)是基于拉丁字母的一套单字节编码系统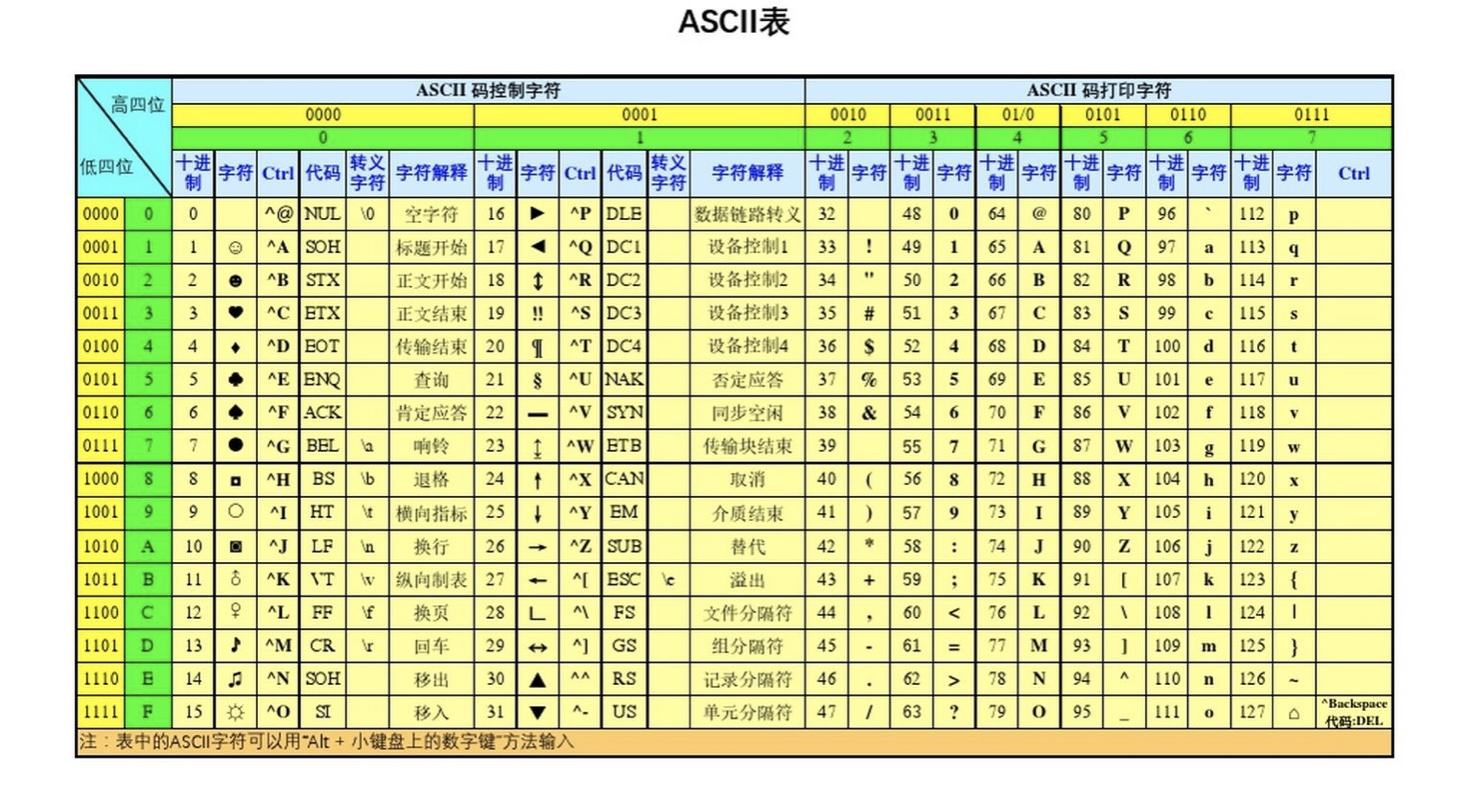
需要熟记:
:::info
\x00是ASCII表第一项,C语言种的字符串结束符
\t、\x09,表示tab字符
\r\n是\x0d\x0a
\x30~\x39字符0~9,\x31是字符1
\x41对应十进制65,表示A
\x61对应十进制97,表示a
:::
注意: 这里的1指定是字符1,不是数字1
UTF-8、GBK都兼容了ASCII
'\x09b\x0d\x0ac \x31\x41\x61' #表示什么?'A' > 'a' #谁大?
Bytes初始化
- bytes()空bytes
- bytes(int)指定字节的bytes,被0填充
- bytes(iterable_of_ints) bytes[0, 2555]的int组成的可迭代对象
- bytes(string, encoding[, errors]) bytes等价于string.encode()
- bytes(by_tesor_buffer) immutable copy of bytes_or_buffer从一个字节序列或者bufer复制出一个新的不可变的bytes对象
- 使用b前缀定义
- 只允许基本ASCII使用字符形式b’abc9’
- 使用16进制转义表示b”\x41\x61”
bytes类型和str类型类似,都是不可变类型,操作方法类似。
print(a'abcd'[2]) #返回int,指定本字节对应的十进制数x = b'\t\x09'print(x, len(x))y = br'\t\x09'print(y,len(y))
bytearray初始化
- bytearray()空bytearray
- bytearray(int)指定字节的bytearray,被0填充
- bytearray(iterable_of_ints) bytearray[0, 255]的int组成的可迭代对象
- bytearray(string, encoding,[,error]) bytearray近似string.encode,不过返回可变对象
- bytearray(bytes_or_buffer)从一个字节序列或者buffer复制出一个新的可变bytearray对象
b边前缀表示的是bytes,不是bytearray类型
由于bytearray类型是可变数组,所以,类似列表
- append(int)尾部追加一个元素
- insert(index,int)在指定索引位置插入元素
- exted(iterable_of_ints)将一个可迭代的证书集合追加到当前bytearray
- pop(index=-1)从指定索引上移除元素,默认尾部移除
- remove(value)找到第一个value移除,找不到抛ValueError异常
- 注意: 上述方法若需要使用int类型,值在[0,255]
- clear()清空bytearay
reverse()翻转bytearray,就地修改
b = bytearray()b.append(97)b.append(99)b.insert(1,98)b.extend([65, 66, 67])b.remove(66)b.pop()b.reverse()print(b)b.clear()
线性结构
线性结构特征:
可迭代for … in
- 有长度,通过len(x)获取,容器
- 通过整数下表可以访问元素。正索引、负索引
- 可以切片
本章学习的线性结构: list、tuple、str、bytes、bytearray
切片
sequence[start:stop]sequence[start:stop:seop]
通过给定的索引区间获得线性结构的一部分数据
- start、stop、setp为整数,可以是正整数、负整数、零
- start为0时,可以省略
- stop为末尾时,可以省略
- stop为1时,可以省略
- 切片时,索引超过上界(左边界),就取到末尾;超过下界(左边界),取到开头
在序列上使用切片[start:stop],子区间索引范围[start,stop),相当于start开始指向stop的方向上获取数据x = [0, 1, 2, 3, ,4 ,5 ,6, 7, 8, 9]print(x[:])print(x[:-1])print(x[0:])print(x[3:])print(x[3:-1)print(x[9:])print(x[:9])print(x[9:-1])print(x[:100])print(x[-100:])print(x[4:-2])print(x[-4:-2])print('0123456789'[-4:8])print(b'0123456789'[-4:8])print(bytearray(b'0123456789')[-10:5])#步长x = [0, 1, 2, 3, ,4 ,5 ,6, 7, 8, 9]print(x[::])print(x[::2])print(x[2:8:3])print(x[:9:3])print(x[1::3])print(x[-10:8:2])#起止和方向x = [0, 1, 2, 3, ,4 ,5 ,6, 7, 8, 9]print(x[-10:])print(x[-5:6])print(x[-6:-6])print(x[6:5])print(x[5:5])print(x[1:9:-2])print(x[::-2])print(x[8::-2])print(x[8:0:-2]) #表示索引8到左尽头,包含0print(x[8:0:02]) #表示索引8到索引1,不包含0print(x[8:-10:2])print(x[8:-10:-2])print(x[-5:4:-1])print(x[-5:5:-1])
默认step为1,表示向右;不长为负数,表示向左
如果子区间方向和不长不长方向不一致,直接返回当前类型的的”空对象”
如果子区间方向和不长一致,则从起点间隔步长取值
| 内建函数 | 函数签名 | 说明 |
|---|---|---|
| id | id(objcet) | CPython种返回对象的内存地址可以用来判断是不是同一个对象 |
#查看id看地址,要注意地址回收复用问题print(id([1, 2, 3]))print(id([4, 5, 6, 7]))#上面两句可能内存地址一样,但是上面那个[1, ,2 ,3]没有意义因为它用完之后,引用计数为0了,没人能再次访问到,释放了内存#如果2个存在在内存中的对象,地址一样一定是同一个对象
本质
x = [0, 1, 2]y = x[:]print(x, y)print(id(x), id(y))x[0] = 100print(x, y)x = [[1]]y = x[:]print(x, y)print(x == y)print(id(x), id(y), x is y)x[0][0] = 100print(x, y)print(x == y)print(x is y)x[0] = 200print(x == y)print(x, y)
实际上切面后得到一个全新的对象。[:]或[::]相当于copy方法。

若有收获,就点个赞吧
0 人点赞
