什么是Yarn
YARN是Hadoop集群的资源管理系统。Yarn的出现就是为了更好的管理集群,当然不只是包括Hadoop。Yarn实现了集群资源统一管理,Yarn可以对同一个集群中的不同计算框架进行资源的统一管理,也就包括了Flink。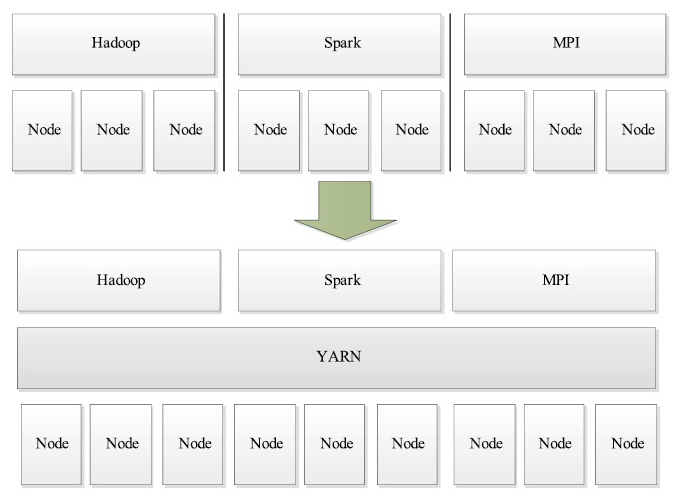
Flink-Hadoop
Flink与Hadoop的关系其实在Flink的官网也就有描述:
Flink 与 Hadoop 软件栈是什么关系?
Flink 独立于Apache Hadoop,且能在没有任何 Hadoop 依赖的情况下运行。 但是,Flink 可以很好的集成很多 Hadoop 组件,例如 HDFS、YARN 或 HBase。 当与这些组件一起运行时,Flink 可以从 HDFS 读取数据,或写入结果和检查点(checkpoint)/快照(snapshot)数据到 HDFS 。 Flink 还可以通过 YARN 轻松部署,并与 YARN 和 HDFS Kerberos 安全模块集成。
所以,Flink on Hadoop是为了使用Hadoop的相关组件,同时和使用Hadoop的数据类型。这一点在Flink官方文档的Hadoop兼容性中有明确的说明。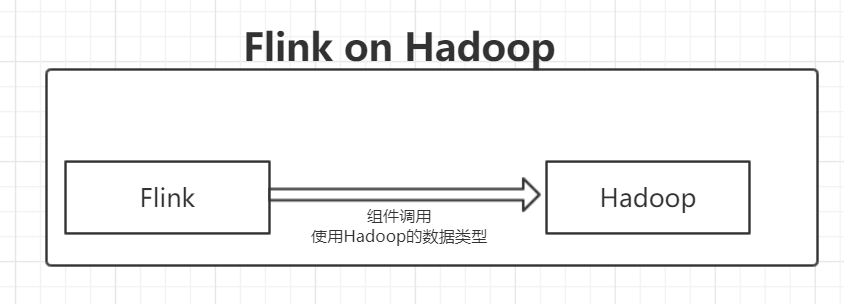
这样部署的好处就是操作相对简单,但是坏处就是集群的管理难度上升,相当于要管理好Flink集群和Hadoop集群,比如当你在Flink中指定数据来源是Hadoop的文件系统HDFS中的文件,那么你需要将相应的Hadoop集群启动并且保证可用。所以为了管理方便和集群之间数据更好的交换,有一种新的方式来部署Flink:Flink on Yarn。
Flink-Yarn
在最开始就介绍了Yarn是什么,使用Yarn是为了在同一个集群中更好的管理分配资源和任务调度。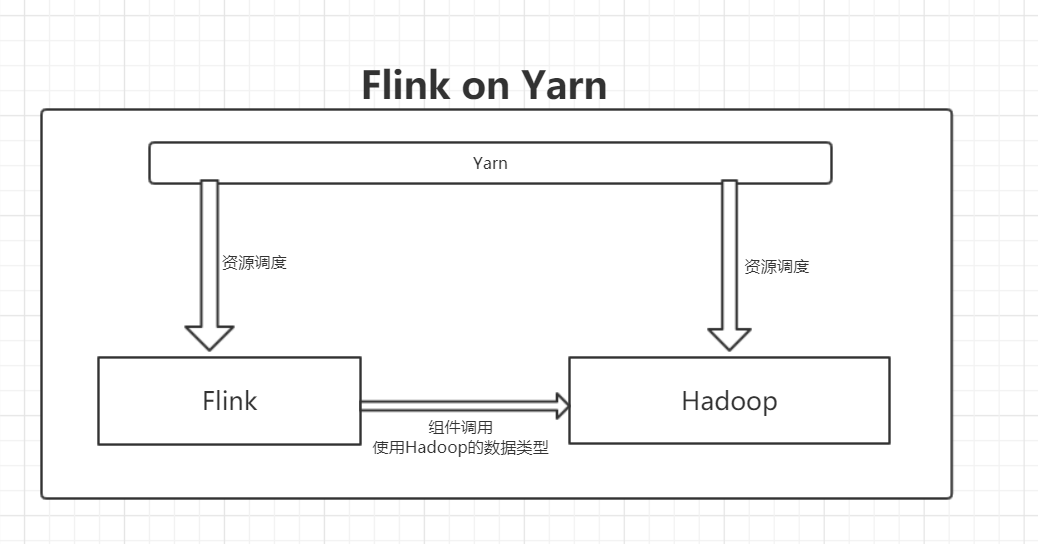
其实Flink是可以不和Hadoop交互的,但是为什么在使用yarn部署Flink的时候还是需要安装Hadoop呢?因为Hadoop是依赖。在后续的Flink中无需特意下载Hadoop部署和安装,因为Flink将Hadoop一起整合在了安装包内:

若有收获,就点个赞吧
0 人点赞
