哈夫曼树(赫夫曼树):给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度(WPL)达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树。

路径:在一棵树中,从一个结点到另一个结点所经过的所有结点,被我们称为两个结点之间的路径。
路径长度:在一棵树中,从一个结点到另一个结点所经过的“边”的数量,被我们称为两个结点之间的路径长度。
结点的带权路径长度:树的每一个结点,都可以拥有自己的“权重”(Weight),权重在不同的算法当中可以起到不同的作用。结点的带权路径长度,是指树的根结点到该结点的路径长度和该结点权重的乘积。
树的带权路径长度:在一棵树中,所有叶子结点的带权路径长度之和,被称为树的带权路径长度,也被简称为WPL。
哈夫曼树构建步骤:
1、构建森林:把每一个叶子结点,都当做树一颗独立的树(只有根结点的树),这样就形成了一个森林,将全部叶子结点排序;
2、取出根结点权值最小的两颗二叉树;
3、组成一棵新的二叉树,该二叉树的根结点的权值是这两颗二叉树根结点权值之和;
4、再将这颗新的二叉树的根结点权值跟未处理的结点权值再次排序,不断重复1、2、3、4的步骤,直到数列中所有结点都被处理,就得到一棵哈夫曼树;
/*** 《哈夫曼树》*/public class HuffmanTree {/*** 根结点*/private TreeNode rootNode;/*** 结点类*/private class TreeNode implements Comparable<TreeNode>{private Integer value;private TreeNode left;private TreeNode right;public TreeNode(Integer value) {this.value = value;}public TreeNode(Integer value, TreeNode left, TreeNode right) {this.value = value;this.left = left;this.right = right;}/*** 前序遍历*/public void beforeOrder() {if (this == null) {return;}// 1、输出结点System.out.printf("%s ", this.value);// 2、前序遍历左子树if (this.left != null) {this.left.beforeOrder();}// 3、前序遍历右子树if (this.right != null) {this.right.beforeOrder();}}@Overridepublic int compareTo(TreeNode o) {return this.value - o.value;}}/*** 前序遍历*/public void beforeOrderPrint() {if (rootNode == null) {System.out.println("前序遍历为空");return;}rootNode.beforeOrder();}/*** 构建哈夫曼树*/public void buildHuffman(int arr[]) {// 创建存放结点的集合List<TreeNode> nodeList = new ArrayList<>();for (int v: arr) {nodeList.add(new TreeNode(v));}while (nodeList.size() > 1) {// 1、将集合按从小到大排序Collections.sort(nodeList);// 2、取出根结点权值最小的两颗二叉树TreeNode leftNode = nodeList.get(0);TreeNode rightNode = nodeList.get(1);// 3、组成一棵新的二叉树,该二叉树的根结点的权值是这两颗二叉树根结点权值之和TreeNode parentNode = new TreeNode((leftNode.value + rightNode.value), leftNode, rightNode);// 4、添加新的二叉树根结点nodeList.add(parentNode);// 5、移除刚刚处理过的两个二叉树根结点nodeList.remove(leftNode);nodeList.remove(rightNode);}rootNode = nodeList.get(0);}public static void main(String[] args) {int[] arr = new int[]{13, 7, 8, 3, 29, 6, 1};HuffmanTree binaryTree = new HuffmanTree();// 构建哈夫曼树binaryTree.buildHuffman(arr);System.out.print("前序遍历哈夫曼树:");binaryTree.beforeOrderPrint();}}
哈夫曼编码
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码(有时也称为霍夫曼编码)。<br /> 哈夫曼编码具有广泛的应用,利用哈夫曼树构造的用于通信的二进制编码称为哈夫曼编码。<br />例如: 有一段电文"CAST囗TAT囗A囗SA"( 其中,"囗"表示一个空格)。统计电文中字母的频度 f('C')=1,f('S')=2,f('T')=3,f('囗')=3,f('A')=4;用频度{ 1 , 2 , 3 , 3 , 4 } 为权值生成哈夫曼树,并在每个叶子上注明对应的字符。树中从根到每个叶子都有一条路径,对路径上的各分枝约定指向左子树根的分枝表示"0"码,指向右子树的分枝表示"1"码,取每条路径上的"0"或"1"的序列作为和各个叶子对应的字符的编码,这就是哈夫曼编码。对应下图的哈夫曼树,上述字符编码为:<br /> 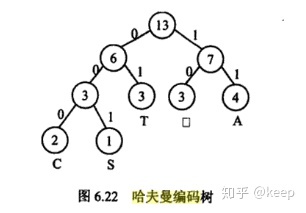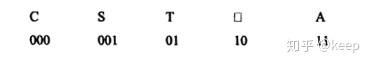
/*** 《哈夫曼编码》*/public class HuffmanCode {/*** 根结点*/private TreeNode rootNode;/*** 哈夫曼编码表存放集合*/private Map<Byte, String> huffmanCodeMap = new HashMap<>();/*** 暂存可能不足一个字节的字符编码*/private String lastByte = "";/*** 结点类*/private class TreeNode implements Comparable<TreeNode>{// 数据private Byte data;// 权重private Integer weight;// 左结点private TreeNode left;// 右结点private TreeNode right;public TreeNode(Byte data, Integer weight, TreeNode left, TreeNode right) {this.data = data;this.weight = weight;this.left = left;this.right = right;}@Overridepublic String toString() {return "TreeNode{" + "data=" + data + ", weight=" + weight + '}';}@Overridepublic int compareTo(TreeNode o) {return this.weight - o.weight;}}/*** 前序遍历*/public void beforeOrderPrint() {if (rootNode == null) {System.out.println("前序遍历为空");return;}beforeOrderPrint(rootNode);}private void beforeOrderPrint(TreeNode node) {if (node == null) {return;}// 1、输出结点System.out.println(node);// 2、前序遍历左子树beforeOrderPrint(node.left);// 3、前序遍历右子树beforeOrderPrint(node.right);}/*** 生成哈夫曼编码表*/private void createHuffmanCode(){if (rootNode == null) {System.out.println("根结点为空!");return;}getNodeCode(rootNode, null);}/*** 获取结点对应的编码* @param node 结点* @param code 编码*/private void getNodeCode(TreeNode node, String code) {if (code == null) {code = "";}// 如果当前结点是非子结点时,继续往下if (node.data == null) {if (node.left != null) {getNodeCode(node.left, code + "0");}if (node.right != null) {getNodeCode(node.right, code + "1");}} else {huffmanCodeMap.put(node.data, code);}}/*** 构建哈夫曼树*/private void buildHuffmanTree(byte[] bytes) {// 统计编码的频度Map<Byte, Integer> collectMap = getCollectMap(bytes);if (collectMap == null || collectMap.isEmpty()) {return;}// 创建存放结点的集合List<TreeNode> nodeList = new ArrayList<>();collectMap.forEach((k, v) -> {nodeList.add(new TreeNode(k, v, null, null));});while (nodeList.size() > 1) {// 1、将集合按从小到大排序Collections.sort(nodeList);// 2、取出根结点权值最小的两颗二叉树TreeNode leftNode = nodeList.get(0);TreeNode rightNode = nodeList.get(1);// 3、组成一棵新的二叉树,该二叉树的根结点的权值是这两颗二叉树根结点权值之和TreeNode parentNode = new TreeNode(null, (leftNode.weight + rightNode.weight), leftNode, rightNode);// 4、添加新的二叉树根结点nodeList.add(parentNode);// 5、移除刚刚处理过的两个二叉树根结点nodeList.remove(leftNode);nodeList.remove(rightNode);}rootNode = nodeList.get(0);}/*** 统计编码的频度* @return*/private Map<Byte, Integer> getCollectMap(byte[] bytes) {if (bytes == null || bytes.length == 0) {return Collections.EMPTY_MAP;}Map<Byte, Integer> collectMap = new HashMap<>();for (Byte b : bytes) {Integer count = collectMap.get(b);if (count == null) {collectMap.put(b, 1);} else {collectMap.put(b, count + 1);}}return collectMap;}/*** 获取哈夫曼编码* @return*/private String getHuffmanCode(byte[] bytes) {if (bytes == null || bytes.length == 0) {return null;}// 1、构建哈夫曼树buildHuffmanTree(bytes);// 2、生成哈夫曼编码表createHuffmanCode();// 3、获取待编码字符对应的哈夫曼编码StringBuilder sb = new StringBuilder();for (byte b : bytes) {sb.append(huffmanCodeMap.get(b));}return sb.toString();}/*** byte转成二进制字符串(按补码返回)* @return*/private String byteToBitString(byte b) {int temp = b;// 如果是正数需要补高位,按位与256(1 0000 0000)temp |= 256;String str = Integer.toBinaryString(temp);return str.substring(str.length() - 8);}/*** 哈夫曼编码压缩* 1、获取待编码字符对应的哈夫曼编码(01字符串)* 2、遍历哈夫曼编码,每8位(一个字节)转换成byte类型,压缩成byte数组* @return*/public byte[] huffmanZip(byte[] bytes) {// 1、获取待编码字符对应的哈夫曼编码String code = getHuffmanCode(bytes);// System.out.println("哈夫曼编码:" + code);// 2、将哈夫曼编码压缩成byte数组// 压缩数组的长度int len = code.length() / 8;if (code.length() % 8 != 0) {// 编码长度不能被8整除,保存多余的不足8位的部分lastByte = code.substring(len * 8);}System.out.println("lastByte: " + lastByte);// 存储压缩的byte数组byte[] huffmanCodeBytes = new byte[len];for (int i = 0; i < len; i++) {huffmanCodeBytes[i] = (byte)Integer.parseInt(code.substring(i * 8, i * 8 + 8), 2);}return huffmanCodeBytes;}/*** 哈夫曼编码解压* 1、逐个遍历压缩后的byte数组,将每个byte元素转换成8位二进制字符串,得到哈夫曼编码字符串* 2、根据哈夫曼编码表,将哈夫曼编码字符串转化成对应的字节数组* @return*/public byte[] huffmanUnZip(byte[] bytes, Map<Byte, String> codeTable) {// 1、先得到压缩后的字节数组对应的二进制字符串StringBuffer sb = new StringBuffer();for(int i = 0; i < bytes.length; i++) {sb.append(byteToBitString(bytes[i]));}// 拼接最后不足一个字节的字符编码sb.append(lastByte);// 2、根据哈夫曼编码表,将二进制字符串转化成对应的字节// 将哈夫曼编码表key和value反转Map<String, Byte> codeMap = new HashMap<>();codeTable.forEach((k, v) -> {codeMap.put(v, k);});List<Byte> byteList = new ArrayList<>();for (int i = 0; i < sb.length(); ) {int count = 1;while (true) {String str = sb.substring(i, i+count);if (codeMap.containsKey(str)) {byteList.add(codeMap.get(str));i += count;break;}count++;}}// 转成字节数组byte[] byteArr = new byte[byteList.size()];for (int i = 0; i < byteArr.length; i++) {byteArr[i] = byteList.get(i);}return byteArr;}/*** 哈夫曼编码压缩文件*/public void zipFile(String srcFile, String dstFile) {InputStream is = null;ObjectOutputStream os = null;try {is = new FileInputStream(srcFile);os = new ObjectOutputStream(new FileOutputStream(dstFile));// 创建一个源文件一样大小的byte数组byte[] b = new byte[is.available()];// 1、读取来源文件is.read(b);// 2、压缩源文件byte[] huffmanBytes = huffmanZip(b);// 3、写入压缩后的文件到目标文件os.writeObject(huffmanBytes);// 同时也要写入哈夫曼编码表,便于解压os.writeObject(huffmanCodeMap);} catch (Exception e) {e.printStackTrace();} finally {try {if (os != null) {os.close();}if (is != null) {is.close();}} catch (IOException e) {e.printStackTrace();}}}/*** 哈夫曼编码解压文件*/public void unZipFile(String srcFile, String dstFile) {ObjectInputStream is = null;OutputStream os = null;try {is = new ObjectInputStream(new FileInputStream(srcFile));os = new FileOutputStream(dstFile);// 1、读取压缩文件// 读取压缩byte数组byte[] huffmanBytes = (byte[])is.readObject();// 读取哈夫曼编码表Map<Byte, String> huffmanCodeTable = (Map<Byte, String>)is.readObject();// 2、解压源文件byte[] bytes = huffmanUnZip(huffmanBytes, huffmanCodeTable);// 3、写入目标文件os.write(bytes);} catch (Exception e) {e.printStackTrace();} finally {try {if (os != null) {os.close();}if (is != null) {is.close();}} catch (IOException e) {e.printStackTrace();}}}public static void main(String[] args) {String str = "CAST&TAT&A&SAT&AA&";System.out.println("原数据:" + str);HuffmanCode binaryCode = new HuffmanCode();byte[] bytes = binaryCode.huffmanZip(str.getBytes());System.out.println("压缩:" + Arrays.toString(bytes));System.out.println("解压:" + new String(binaryCode.huffmanUnZip(bytes, binaryCode.huffmanCodeMap)));System.out.println("测试文件压缩测试");binaryCode.zipFile("/Users/yupan/Desktop/123.txt", "/Users/yupan/Desktop/456.txt");System.out.println("文件压缩成功!");binaryCode.unZipFile("/Users/yupan/Desktop/456.txt", "/Users/yupan/Desktop/789.txt");System.out.println("文件解压成功!");}}

若有收获,就点个赞吧
0 人点赞
