1、缓存穿透
什么是缓存穿透:
缓存穿透是指查询一个一定不存在的数据。
即:大量请求的key,在缓存中根本不存在。这个时候由于缓存未命中,就导致请求直接到了数据库,根本没有经过缓存。这时数据库也没有这个记录,就不会在查询后向缓存中保存,就导致这个不存在的数据每次都要到数据库去查询,这就是缓存穿透。
风险:在流量大是时候,可能数据库压力过大,就挂掉了;如果有人利用不存在的key频繁攻击应用,这就是一种漏洞。
如何解决缓存穿透:
- 首先,最基本的是做好参数校验,一些不合法的参数请求直接在前端或者请求到后台的时候,抛出异常信息返回给客户端。比如查询数据id小于0,传入字段格式不对的数据等,这时直接返回错误信息,不走查询逻辑。
- 然后,可以缓存无效key,给他一个空结果(null,视具体业务存为null或者“”)。如果这个key的数据在redis和数据库中都查不到,那就缓存这个key,给他一个空结果(null,视具体业务存为null或者“”)。当然这个可能导致中缓存了大量无效的key,所以尽量设置一个比较短的过期时间,比如一分钟。 而且这种方式,遇到恶意攻击,可能将缓存空间打爆,影响范围更大。 所以,key的数据量级比较小,且完全可以预测,可以通过提前填充的方式将数据缓存。
- 通过布隆过滤器(BloomFilter)。
布隆过滤器是一种由一个很长的二进制向量和一系列随机映射函数构成的概率型数据结构,这种数据结构的空间效率非常高,可以用于检索集合中是否存在特定元素。
有点复杂,后续看看。
2、缓存击穿
什么是缓存击穿:
不要把缓存击穿和缓存穿透搞混了。
缓存击穿是指如果缓存内容因为各种原因失效,会发生缓存击穿。指的是访问这个key的数据,穿破了缓存,直接请求到数据库。 尤其是一个key非常热点,在被大并发访问,当这个key失效的瞬间,持续的大并发穿破缓存,直接请求到数据库了。好似大坝突然破了个口,大量洪水涌入。这时数据库了查询压力倍增,大量请求阻塞,甚至数据库挂掉。
如何解决:
- 异步构建缓存:
既然是热点key,我们不对这个key设置失效时间,如果数据需要更新,我们在后台开启一个异步线程,发现过期的key直接重写缓存。
或者当缓存失效时,不立刻去查询数据库,而是先创建缓存更新的异步任务,然后直接返回空值。
这么做牺牲了数据的一致性,可以在数据一致性要求不高的情况下使用。
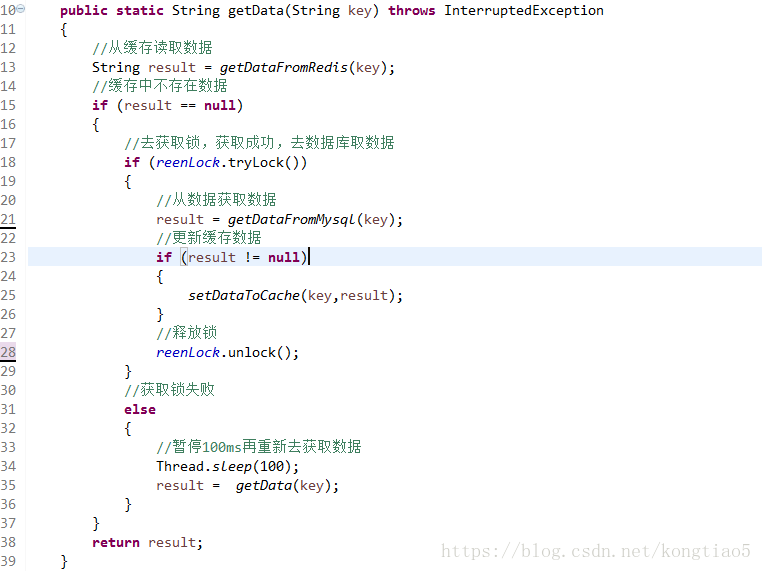
- 使用互斥锁(mutex key):
就是说,当key失效的时候,来读取到线程,只让一个线程读取数据并构建到缓存中,其他线程就先等待,直到缓存构建完成后读取缓存即可。
如果是单机系统,用 JDK 本身的同步工具 Synchronized 或 ReentrantLock 就可以实现,但一般来说,都达到防止缓存击穿的流量了谁还搞什么单机系统,肯定是分布式高大上点啊,这种情况我们就可以用分布式锁来做互斥效果。
伪代码:
try {Boolean snx =redisClient.setNX(redisKey, value);if (snx && timeout>0){boolean flag = redisClient.expire(redisKey, timeout, unit);if (!flag){redisClient.del(redisKey);}return flag;}} catch (Exception e) {LOG.error("setnx: key="+redisKey ,e);}return false;
3、缓存雪崩
缓存雪崩是什么:
缓存雪崩是指,缓存在同一时间大面积失效,而查询数量巨大,导致后面的请求都直接转发到数据库上,造成数据库短时间内承受大量的请求,瞬时压力过大,甚至宕机。
如何解决缓存雪崩:
- 可以给缓存,比如热点数据设置过期时间的时候,增加一个随机值。这样每个缓存的过期时间重复率就会降低,会比较难引发缓存大面积集体失效的情况。
- 当然也可以缓存用不失效。
- 针对Redis服务不可用的情况,采用Redis集群,避免单机Redis出现问题,导致整个缓存服务都不可用;同时采取限流措施,避免同时处理大量请求。

若有收获,就点个赞吧
0 人点赞
