1、数据一致性
先来看一下数据一致性。
数据一致性,就是数据保持一致。在分布式系统中,可以理解为多个节点中数据的值是一直到。一致性又分为三种:
- 强一致性:这种一致性级别是最符合用户直觉的。它要求系统写入什么,读出来的也会是什么,用户体验好,但是实现起来往往对系统的性能影响大。
- 弱一致性:这种一致性级别约束系统在写入成功后,不承诺立即可以读到写入到值,也不承诺多久之后数据能够达到一致,但会尽可能的保证到某个时间级别(比如秒级)后,数据能够达到一致。
- 最终一致性:最终一致性是弱一致性的一个特例。系统会保证在一定时间内,能够达到一个数据一致的状态。这也是业界咋大型分布式系统的数据一致性上比较推崇的模型。
2、保证缓存和DB数据一致性的方法
这里我们是在旁路缓存模式(Cache Aside Pattern)下来探讨。以为DB中的数据为准,适合读请求较多的场景。
2.1 先来看下双写和失效两种模式
2.1.1 使用双写模式
所谓双写模式,就是在数据库修改后,就跟着把缓存中的数据也做修改。
这种方式在大并发下会存在问题:会产生脏数据。如下图: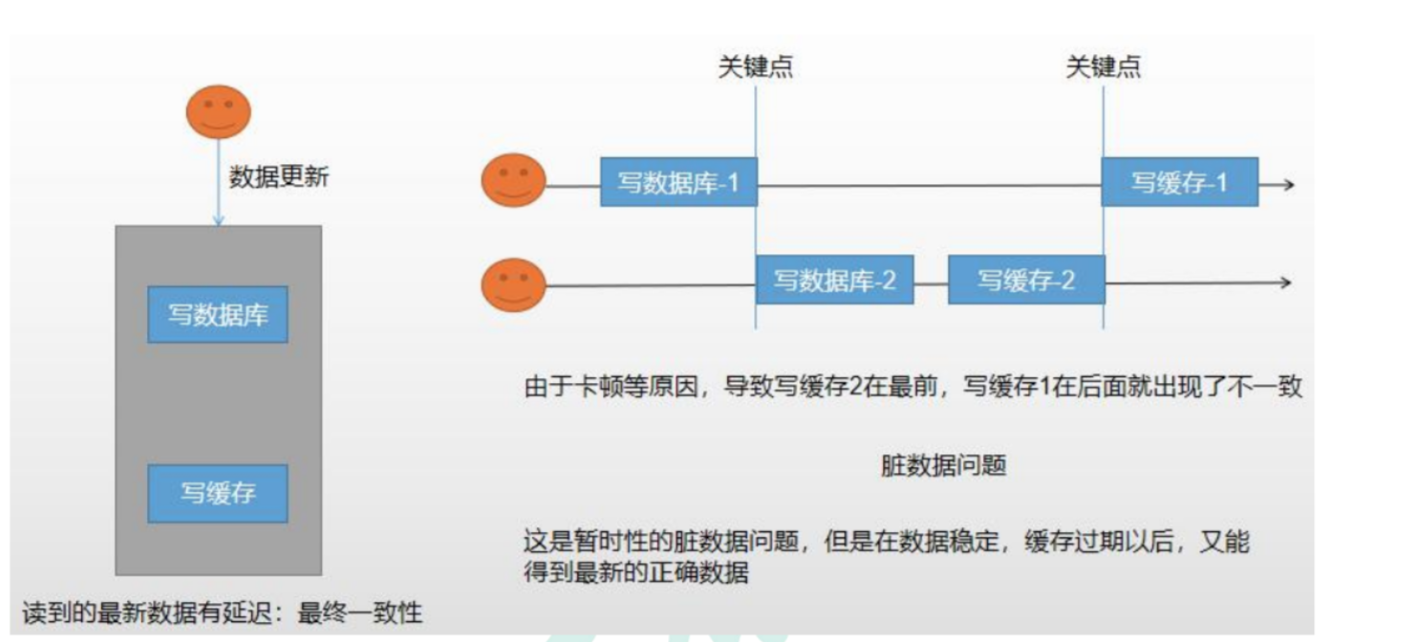
如何解决呢?
通过在更新数据时,加锁来解决。一个线程更新时,得到锁,等这个线程更新完了,释放了锁,其他线程才能得到锁。
或者,在对数据的准确性(一致性)要求不是特别高的情况下,可以在设计缓存时,就设置一个过期时间,等缓存过期后,重新写入缓存数据,以此来保证数据的最终一致性即可。
2.1.2 使用失效模式
所谓试下模式。就是在数据库修改后,直接将缓存删掉,等待下次来查询时,进行更新缓存。
当然,这也可能产生脏数据: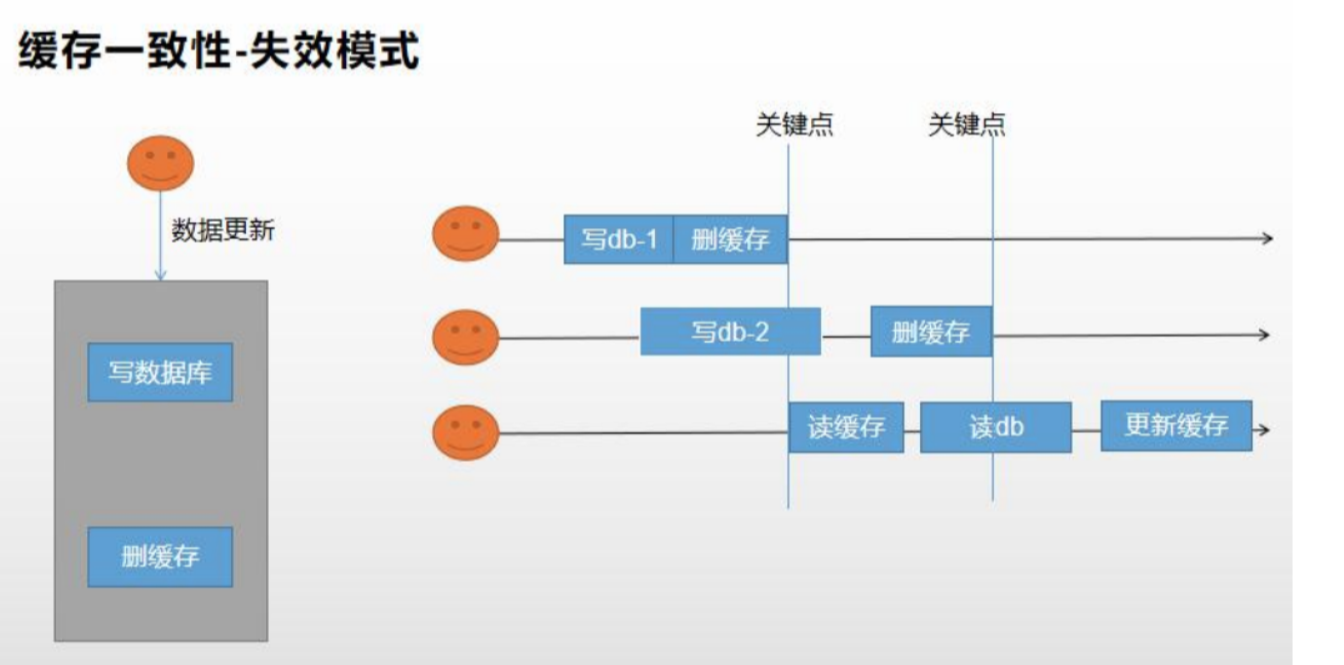
如何解决呢?
也可以通过加锁来解决,但是,加锁后的系统会比较笨重一些,也就是性能较低。
所以这里要注意一点,对于经常修改的数据,且对读的准确性要求很高的数据,就应该直接读取数据库。
2.2 延时双删
假设我们的写(写入/更新)操作此时是先写入DB,再写入redis,没有做其他;
此时读的流程是: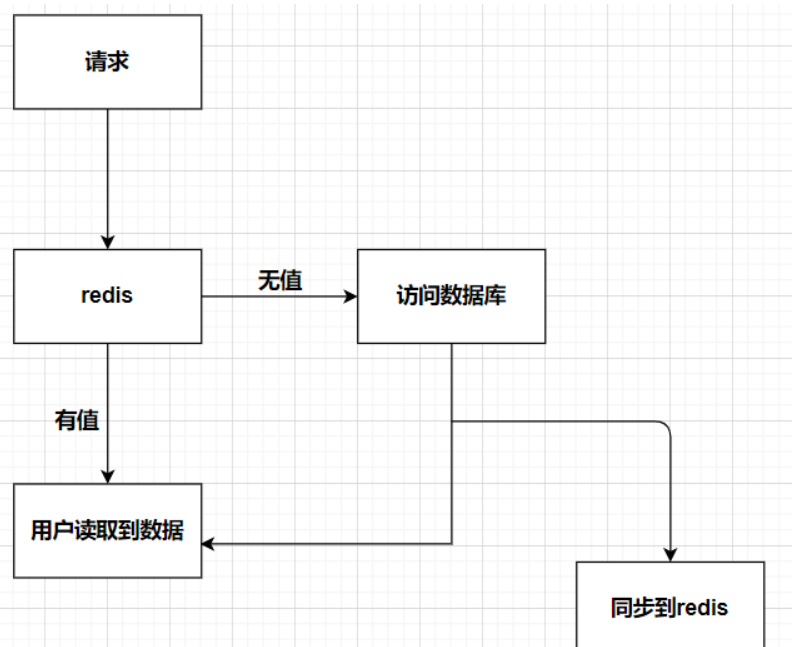
那么就会出现,db数据已更新,但是没有同步到redis中。
此时使用延迟双删:
- 在写操作中,先删除redis中的数据;
- 更新数据库
- 延迟500ms,这个延迟的时间,是依据业务读取数据均匀耗时,确保读请求能够完结。
- 删除redis。

2.3 保证缓存和DB数据一致性方法总结
- 如果是并发量很小的(如订单数据、用户数据)数据,不用考虑这个问题,缓存数据加上过期时间,每隔一段时间触发读的主动更新就好。
- 通过加锁保证并发读写,写写的时候按顺序排好队,读读无所谓。使用读写锁。
- 缓存数据+缓存key设置过期时间足够解决大部分对于缓存的要求。
- 也可以使用canal订阅binlog的方式。
面试版回答:
Redis和Mysql如何保证数据一致性?
首先,对于一个在缓存中的数据,应用程序需要去读取它的时候,首先会从缓存中读取,如果缓存命中了,则直接返回,缓存未命中,就回去数据库中查询,查询到数据后,再把数据放到redis里面。
这里就会面临一个问题,一份数据同时保存在Mysql和Redis里面,当数据发生改变时,需要同时改掉Mysql和Redis。由于更新操作是有先后顺序的,而且又不具备原子性,所以会出现一致性问题。
一般用这几种解决:
- 使用失效模式,在数据库修改后,直接将缓存删掉,等待下次主动查询进行更新。这是一种方案,但是数据库的修改和缓存的删除,不是原子操作,它保证的是最终一致性。在极端情况下,还是会有问题,可以通过加锁来解决。在写写的时候按顺序排队,读读无所谓,使用读写锁。
- 使用双写模式,在数据库修改后,就跟着也把缓存中的数据进行更改。当然,在大并发模式下也会有一定的漏洞,通过加锁来解决。
- 当然,如果是并发量不大的,可以直接给缓存加上过期时间,每隔一段时间时间触发读数据的主动获取数据就好。
- 也可以使用canal订阅binlog的方式。
- 使用延迟双删。
mysql与redis的数据一致性是一个复杂的客厅,通常是多策略同时使用。例如:延迟双删或者失效模式、配合redis设置key过期时间,分布式锁等等。

若有收获,就点个赞吧
0 人点赞
