爬取豆瓣
代码
import requestsfrom bs4 import BeautifulSoupimport csv'''处理翻页操作,分析urlhttps://movie.douban.com/top250?start=0https://movie.douban.com/top250?start=25https://movie.douban.com/top250?start=50'''class DouBan:def __init__(self):self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'}self.url = 'https://movie.douban.com/top250?start={}'self.li = []self.header = ['name', 'score', 'review']def read_url(self, url):res = requests.get(url, headers=self.headers)html = res.content.decode('utf-8')# print(html)# print('-'*100)return htmldef parse_html(self, html):soup = BeautifulSoup(html, 'lxml')ol_tag = soup.find('ol', class_="grid_view")# print(ol_tag)li_tags = ol_tag.find_all('li')for li_tag in li_tags:item = {}div_hd_tag = li_tag.find('div', class_="hd")div_bd_tag = li_tag.find('div', class_="bd")name = div_hd_tag.find('span', class_="title").stringitem['name'] = namescore = div_bd_tag.find('span', class_="rating_num").stringitem['score'] = score# 处理没有影评的操作try:review = div_bd_tag.find('span', class_="inq").stringitem['review'] = reviewexcept:item['review'] = '无'self.li.append(item)def write_data(self):with open("豆瓣top250.csv", 'w', encoding='utf-8', newline='') as f:w = csv.DictWriter(f, self.header)w.writeheader()w.writerows(self.li)def main(self):num = int(input("请输入你要爬取的页数:(一共有十页)"))for i in range(num):url = self.url.format(i*25)html = self.read_url(url)self.parse_html(html)# print(self.li)self.write_data()if __name__ == '__main__':db = DouBan()db.main()
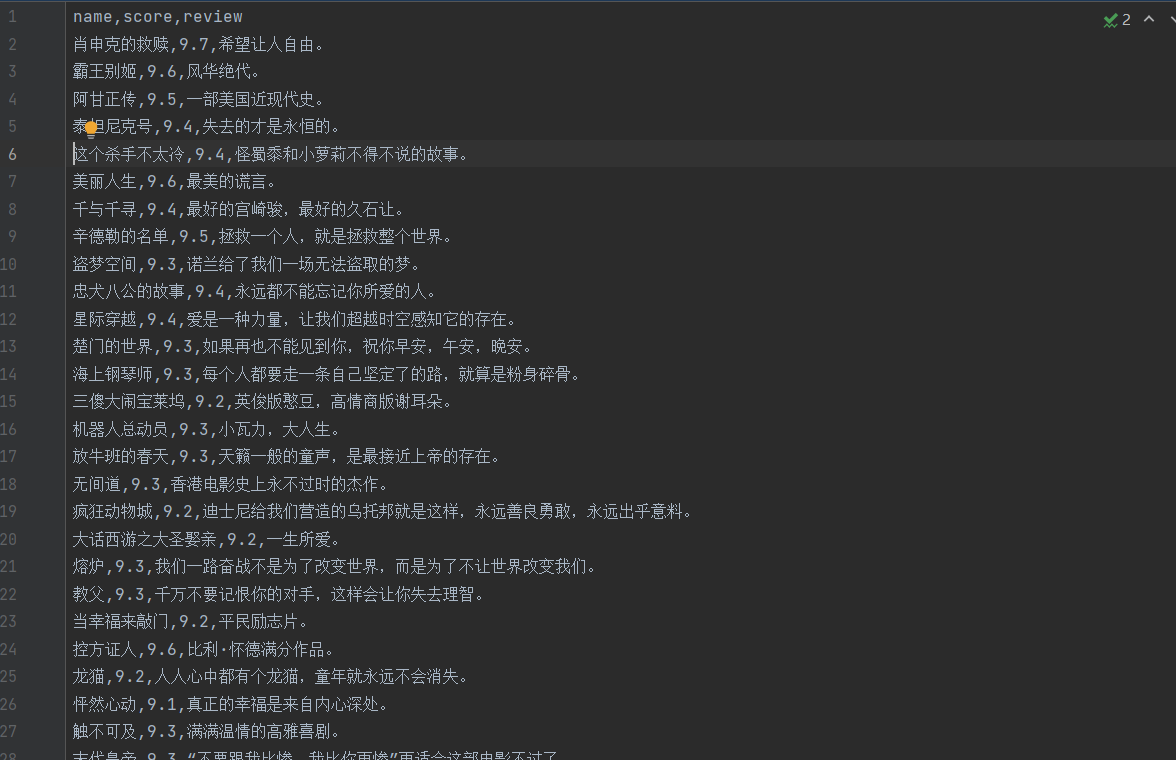
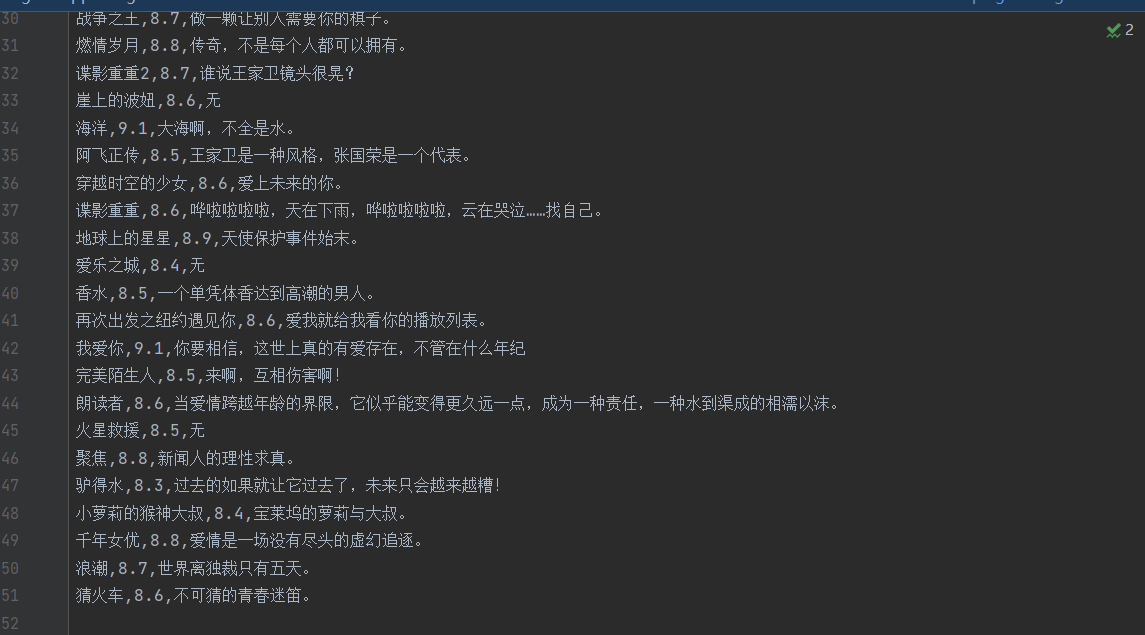
结果展示

若有收获,就点个赞吧
0 人点赞
