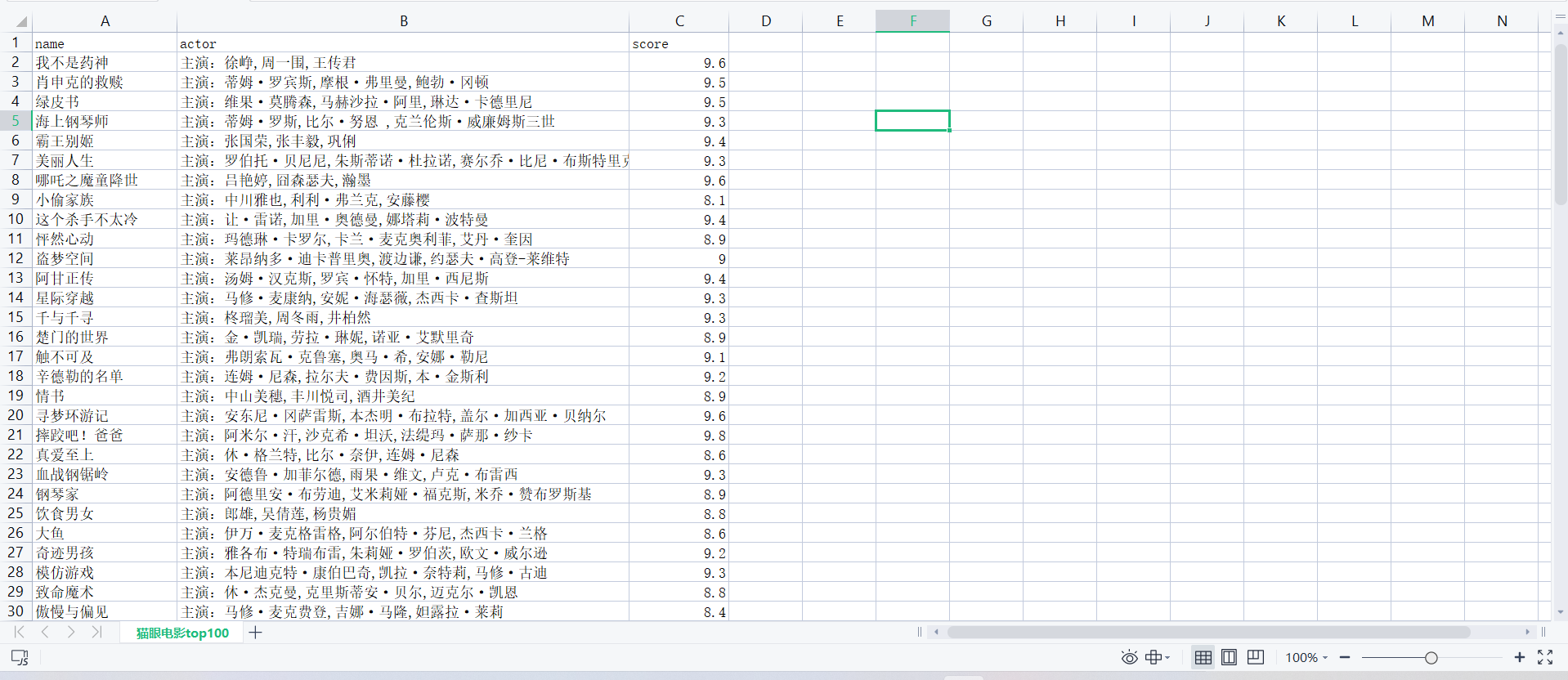
使用selenium爬取猫眼top100
代码
from selenium import webdriverfrom selenium.webdriver.common.by import Byimport csv# 爬取内容def parse_data(li):dd_tags = driver.find_elements(By.XPATH, '//*[@id="app"]/div/div/div[1]/dl//dd')for dd_tag in dd_tags:item = {}# 爬取影名item['name'] = dd_tag.find_element(By.XPATH, './/p[@class="name"]/a').text.strip()# 爬取主演item['actor'] = dd_tag.find_element(By.XPATH, './/p[@class="star"]').text.strip()# 爬取评分item['score'] = dd_tag.find_element(By.XPATH, './/p[@class="score"]').text.strip()li.append(item)# 保存数据def write_data(li):header = ['name', 'actor', 'score']with open('猫眼电影top100.csv', 'w', encoding='utf-8', newline='') as f:w = csv.DictWriter(f, header)w.writeheader()w.writerows(li)print("保存成功!")# 主函数if __name__ == '__main__':# 加载驱动driver = webdriver.Chrome()driver.get('https://www.maoyan.com/')# 点击重新加载driver.find_element(By.XPATH, '//*[@id="reload-button"]').click()# 隐式等待driver.implicitly_wait(2)# 点击top100榜单driver.find_element(By.XPATH, '/html/body/div[1]/div/div[2]/ul/li[5]/a').click()driver.implicitly_wait(2)driver.find_element(By.XPATH, '/html/body/div[3]/ul/li[5]/a').click()driver.implicitly_wait(2)li = []# 翻页操作for i in range(10):parse_data(li)driver.find_element(By.XPATH, '//*[@id="app"]/div/div/div[2]/ul/li[8]/a').click()# 保存数据write_data(li)
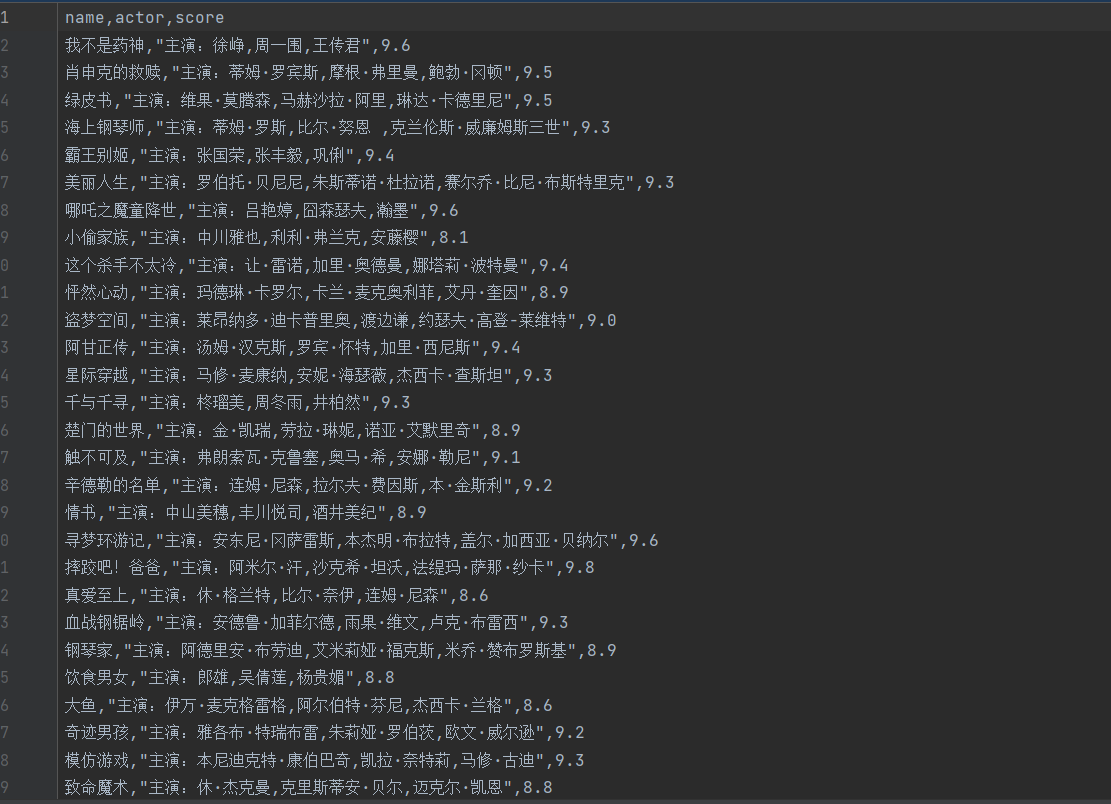
展示

若有收获,就点个赞吧
0 人点赞
