1.方程的θ参数次数:d
High bias (underfitting): both J{train}(\Theta)_Jtrain(Θ) and J{CV}(\Theta)_JCV(Θ) will be high. Also, J{CV}(\Theta) \approx J{train}(\Theta)JCV(Θ)≈Jtrain(Θ).
High variance (overfitting): J{train}(\Theta)_Jtrain(Θ) will be low and J{CV}(\Theta)_JCV(Θ) will be much greater than J{train}(\Theta)_Jtrain(Θ).
2.方程的regulation参数λ


3.方程的训练数据数量m:learning curves
- As the training set gets larger, the error for a quadratic function increases.
- The error value will plateau out after a certain m, or training set size.
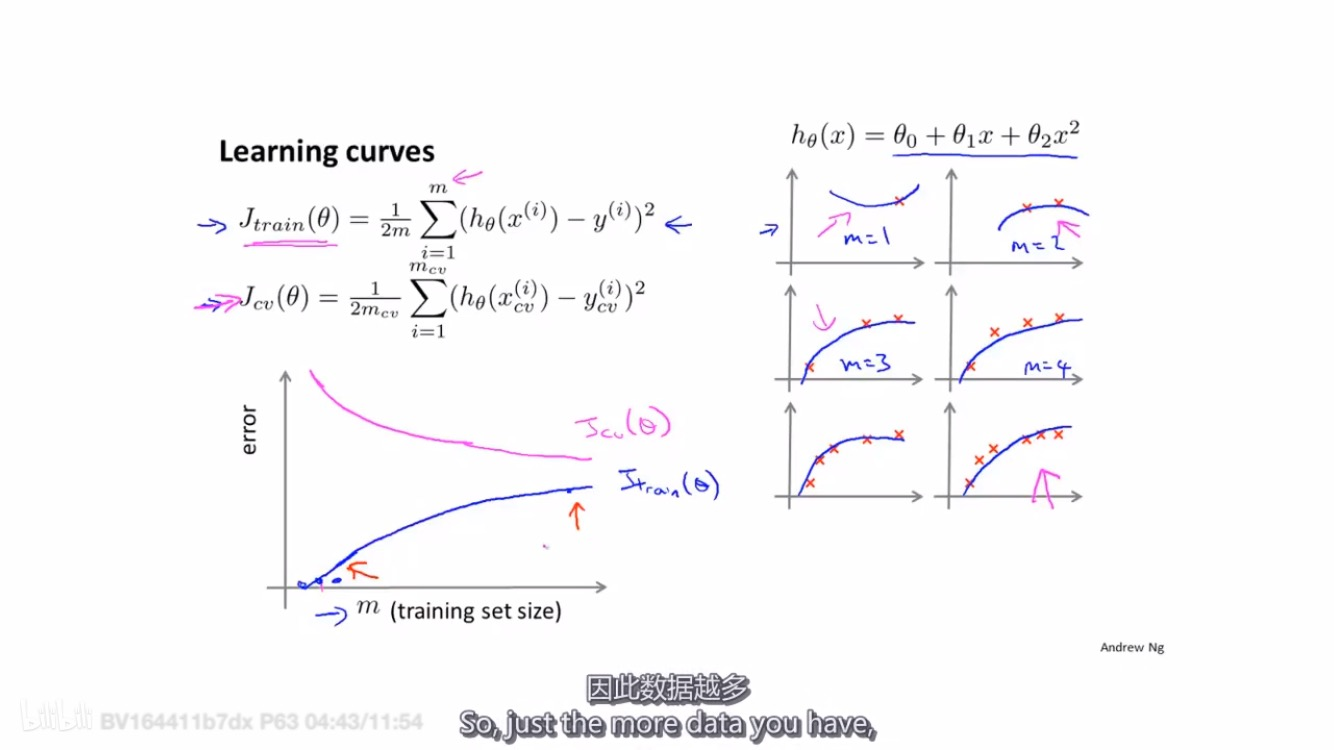
Experiencing high bias:
Low training set size: causes J{train}(\Theta)_Jtrain(Θ) to be low and J{CV}(\Theta)_JCV(Θ) to be high.
Large training set size: causes both J{train}(\Theta)_Jtrain(Θ) and J{CV}(\Theta)_JCV(Θ) to be high with J{train}(\Theta)_Jtrain(Θ)≈J{CV}(\Theta)_JCV(Θ).
If a learning algorithm is suffering from high bias, getting more training data will not (by itself) help much.
Experiencing high variance:
Low training set size: J{train}(\Theta)_Jtrain(Θ) will be low and J{CV}(\Theta)_JCV(Θ) will be high.
Large training set size: J{train}(\Theta)_Jtrain(Θ) increases with training set size and J{CV}(\Theta)_JCV(Θ) continues to decrease without leveling off. Also, J{train}(\Theta)_Jtrain(Θ) < J{CV}(\Theta)_JCV(Θ) but the difference between them remains significant.
If a learning algorithm is suffering from high variance, getting more training data is likely to help.
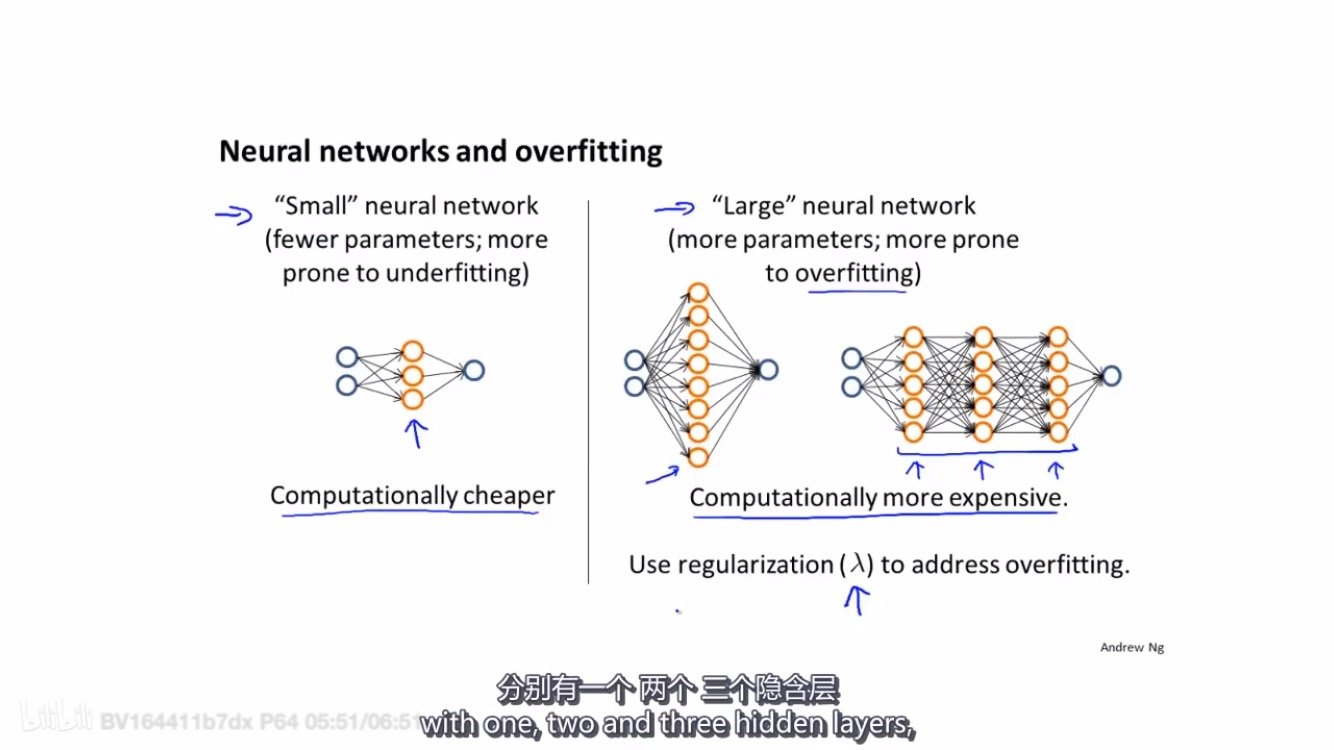
4.神经网络的大小神经元数量、层数
- A large neural network with more parameters is prone to overfitting. It is also computationally expensive. In this case you can use regularization (increase λ) to address the overfitting.
总结优化思路:

若有收获,就点个赞吧
0 人点赞
