本篇我们开始分析Spring的事务,在看源码之前,我们先来做一些铺垫。
1.JDBC&Spring事务
@Testpublic void test() {Connection co = null;try {co = JDBCUtils.getConnection();co.setAutoCommit(false);String sql1 = "update user_table set balance=balance-? where user=?";String sql2 = "update user_table set balance=balance+? where user=?";update(co,sql1,100,"AA");//System.out.println(10/0);update(co,sql2,100,"BB");co.commit();System.out.println("转账成功!");} catch (SQLException e) {try {co.rollback();System.out.println("转账失败!");} catch (SQLException e1) {e1.printStackTrace();}} finally {JDBCUtils.closeResource(co,null,null);}}
public static int update(Connection co, String sql, Object... args) {PreparedStatement ps = null;try {ps = co.prepareStatement(sql);for (int i = 0; i < args.length; i++) {ps.setObject(i + 1, args[i]);}return ps.executeUpdate();} catch (SQLException e) {e.printStackTrace();} finally {JDBCUtils.closeResource(null, ps, null);}return 0;}
接下来看一下Spring事务。
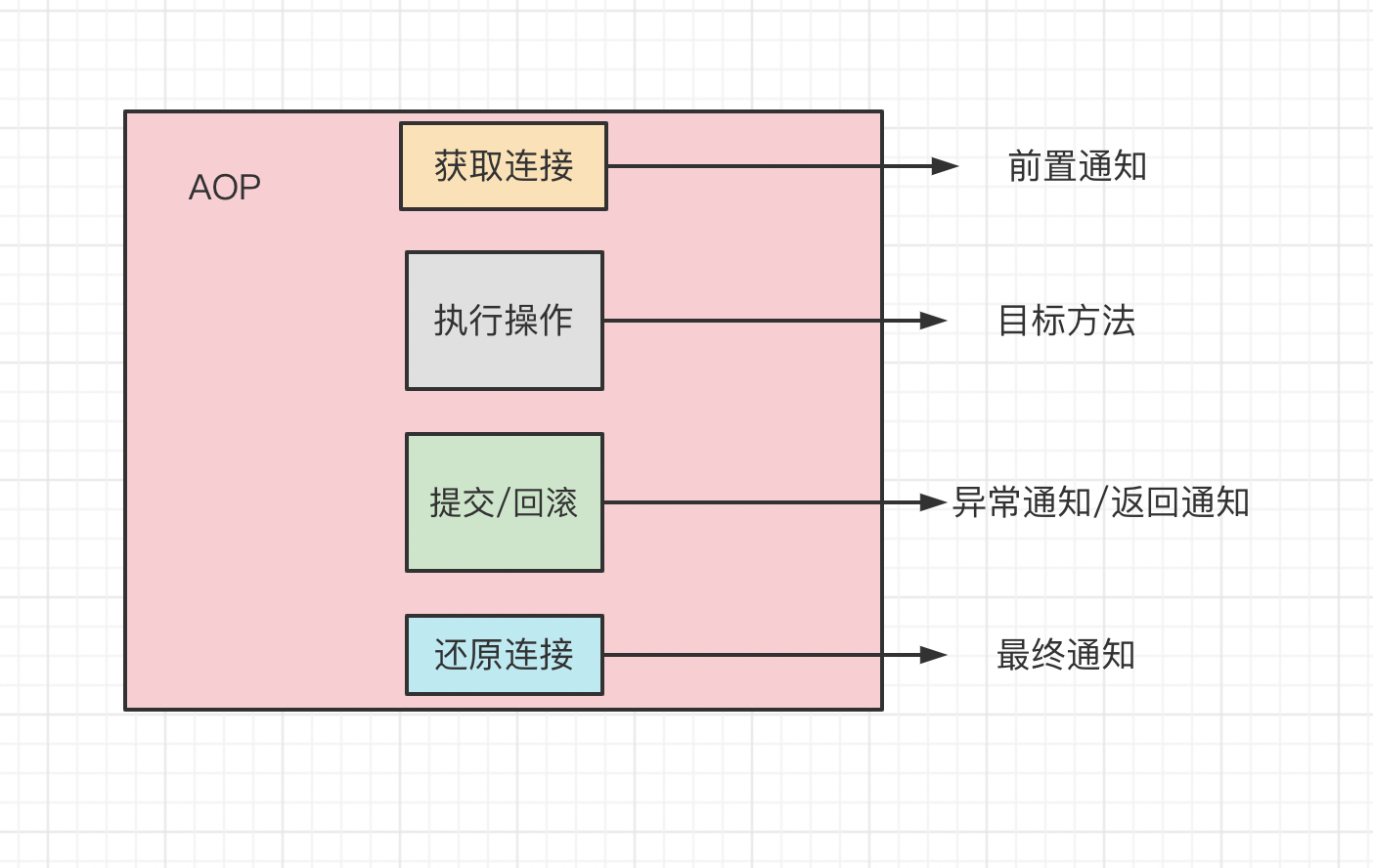
2.事务传播行为
所谓 spring 事务的传播属性,就是定义在存在多个事务同时存在的时候,spring 应该如何处理这些事务的行为。这些属性在 TransactionDefinition 中定义。
| 常量名称 | 常量解释 |
|---|---|
| PROPAGATION_REQUIRED | 支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择,也是 Spring默认的事务的传播。 |
| PROPAGATION_REQUIRES_NEW | 新建事务,如果当前存在事务,把当前事务挂起。新建的事务将和被挂起的事务没有任何关系,是两个独立的事务,外层事务失败回滚之后,不能回滚内层事务执行的结果,内层事务失败抛出异常,外层事务捕获,也可以不处理回滚操作 |
| PROPAGATION_SUPPORTS | 支持当前事务,如果当前没有事务,就以非事务方式执行。 |
| PROPAGATION_MANDATORY | 支持当前事务,如果当前没有事务,就抛出异常。 |
| PROPAGATION_NOT_SUPPORTED | 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。 |
| PROPAGATION_NEVER | 以非事务方式执行,如果当前存在事务,则抛出异常。 |
| PROPAGATION_NESTED | 如果一个活动的事务存在,则运行在一个嵌套的事务中。如果没有活动事务,则按REQUIRED 属性执行。它使用了一个单独的事务,这个事务拥有多个可以回滚的保存点。内部事务的回滚不会对外部事务造成影响。它只对DataSourceTransactionManager 事务管理器起效。 |
PROPAGATION_REQUIREDclass ServiceA {@AutowiredServiceB serviceB;@Transactionalvoid a() {....serviceB.b();....}}class ServiceB {@Transactionalvoid b() {......}}
- 线程执行到serviceA.a() 方法时,其实是执行的 代理serviceA对象的a方法。
- 执行代理serviceA对象的a方法
- 执行a方法的增强逻辑-> 事务增强器 (环绕增强)
- 事务增强器会做什么事? 提取事务标签属性
- 检查当前线程有没有绑定 conn 数据库连接 资源? 发现当前线程未绑定(TransactionSync…Manager#resources 是 ThreadLocal
- 因为未绑定conn资源,所以线程下一步就是 到 datasource.getConnection() 获取一个conn资源
- 因为新获取的conn资源的autocommit是true,所以这一步 修改 autocommit 为false,表示手动提交事务,这一步也表示 开启事务(修改conn其它 属性..)
- 绑定conn资源到 TransactionSync…Manager#resources,key:datasource
- 执行事务增强器后面的增强器..
- 最后一个advice调用 target的目标方法 a() 方法
- 假设target a方法 需要访问数据库 执行SQL 的话,程序需要获取一个 conn 资源,到哪拿? DataSourceUtils.getConnection(datasource) 这一步最终会拿到 事务增强器 前置增强逻辑 存放在 TransactionSync..Manager#resources 内的conn 资源
- 执行方法a逻辑…可能会执行一些 SQL 语句…
- 线程执行到这样一行代码:serviceB.b()
- serviceB 它是一个代理对象,因为它也使用了 @Transactional 注解了,Spring 会为它创建代理的。
- 执行代理serviceB对象的b方法
- 执行b方法的增强逻辑-> 事务增强器(环绕增强)
- 事务增强器会做什么事? 提取事务标签属性
- 检查当前线程有没有绑定 conn 数据库连接 资源?发现当前线程已经绑定了 conn 数据库连接资源了
- 检查事务注解属性,发现自己打的propagation == REQUIRED,所以继续共享 conn 数据库链接资源
- 执行事务增强器后面的增强器..
- 最后一个device调用 target (serviceB)的目标方法 b() 方法
- 假设target b方法 需要访问数据库 执行SQL 的话,程序需要获取一个 conn 资源,到哪拿? DataSourceUtils.getConnection(datasource) 这一步最终会拿到 代理serviceA对象存放在 TransactionSync..Manager#resources 内的conn 资源
- 执行方法b逻辑…可能会执行一些 SQL 语句…
- 线程继续执行 事务增强器 环绕增强的后置逻辑 (代理serviceB.b() 方法的 后置增强)
- 检查发现,serviceB.b() 事务并不是 当前 b方法开启的,所以 基本不做什么事情..
- 线程继续回到 目标 serviceA.a() 方法内,继续执行
- 执行方法a逻辑…可能会执行一些 SQL 语句…
- 线程继续回到 代理 serviceA.a() 方法内,继续执行
- 执行a方法的增强逻辑-> 事务增强器 (环绕增强-后置增强逻辑)
- 提交事务/回滚事务
- 恢复连接状态 (将conn的autocommit 设置回 true…等等)
- 清理工作(将绑定的conn资源从TransactionSync…Manager#resources移除)
- conn 连接关闭 (归还连接到datasource)
PROPAGATION_SUPPORTSclass ServiceA {@AutowiredServiceB serviceB;@Transactionalvoid a() {....serviceB.b();....}}class ServiceB {@Transactional(propagation = SUPPORTS)void b() {......}}
逻辑和上面完全一致。
class ServiceA {@Transactional(Propagation = SUPPORTS)void a() {........}}
线程在未绑定事务的情况下,去调用serviceA.a() 方法会发生什么呢?
- 线程执行到serviceA.a() 方法时,其实是执行的 代理serviceA对象的a方法。
- 执行代理serviceA对象的a方法
- 执行a方法的增强逻辑-> 事务增强器 (环绕增强)
- 事务增强器会做什么事? 提取事务标签属性
- 检查当前线程有没有绑定 conn 数据库连接 资源? 发现当前线程未绑定(TransactionSync…Manager#resources 是 ThreadLocal
- 啥也不用做..
- 执行事务增强器后面的增强器..
- 最后一个advice调用 target的目标方法 a() 方法
- 假设target a方法 需要访问数据库 执行SQL 的话,程序需要获取一个 conn 资源,到哪拿? DataSourceUtils.getConnection(datasource) ,因为事务增强器前置增强逻辑 并没有 向TransactionSync..Manager#resources 内绑定conn资源
- 因为 上一步未拿到 conn资源,所以 DataSourceUtils 通过 datasource.getConnection() 获取了一个全新的 conn 资源(注意:conn.autocommit == true,执行的每一条sql 都是一个 独立事务!!)
- 执行方法a逻辑…可能会执行一些 SQL 语句…
- 线程继续执行到代理serviceA对象的a方法 (事务增强器-后置增强逻辑)
- 检查发现 TrasactionSync..Manager#resources 并未绑定任何 conn 资源,所以 这一步啥也不做了…
PROPAGATION_MANDATORY 很少使用..class ServiceA {@AutowiredServiceB serviceB;@Transactionalvoid a() {....serviceB.b();....}}class ServiceB {@Transactional(propagation = MANDATORY)void b() {......}}
如果是这样的话,情况和 PROPAGATION_REQUIRED 案例分析 完全一致。
class ServiceA {@Transactional(Propagation = MANDATORY)void a() {........}}
线程在未绑定事务的情况下,去调用serviceA.a() 方法会发生什么呢?
- 线程执行到serviceA.a() 方法时,其实是执行的 代理serviceA对象的a方法。
- 执行代理serviceA对象的a方法
- 执行a方法的增强逻辑-> 事务增强器 (环绕增强)
- 事务增强器会做什么事? 提取事务标签属性
- 检查当前线程有没有绑定 conn 数据库连接 资源? 发现当前线程未绑定(TransactionSync…Manager#resources 是 ThreadLocal
- 直接抛出异常…
- …
PROPAGATION_REQUIRES_NEWclass ServiceA {@AutowiredServiceB serviceB;@Transactionalvoid a() {....serviceB.b();....}}class ServiceB {@Transactional(propagation = REQUIRES_NEW)void b() {......}}
- 线程执行到serviceA.a() 方法时,其实是执行的 代理serviceA对象的a方法。
- 执行代理serviceA对象的a方法
- 执行a方法的增强逻辑-> 事务增强器 (环绕增强)
- 事务增强器会做什么事? 提取事务标签属性
- 检查当前线程有没有绑定 conn 数据库连接 资源? 发现当前线程未绑定(TransactionSync…Manager#resources 是 ThreadLocal
- 因为未绑定conn资源,所以线程下一步就是 到 datasource.getConnection() 获取一个conn资源
- 因为新获取的conn资源的autocommit是true,所以这一步 修改 autocommit 为false,表示手动提交事务,这一步也表示 开启事务(修改conn其它 属性..)
- 绑定conn资源到 TransactionSync…Manager#resources,key:datasource
- 执行事务增强器后面的增强器..
- 最后一个advice调用 target的目标方法 a() 方法
- 假设target a方法 需要访问数据库 执行SQL 的话,程序需要获取一个 conn 资源,到哪拿? DataSourceUtils.getConnection(datasource) 这一步最终会拿到 事务增强器 前置增强逻辑 存放在 TransactionSync..Manager#resources 内的conn 资源
- 执行方法a逻辑…可能会执行一些 SQL 语句…
- 线程执行到这样一行代码:serviceB.b()
- serviceB 它是一个代理对象,因为它也使用了 @Transactional 注解了,Spring 会为它创建代理的。
- 执行代理serviceB对象的b方法
- 执行b方法的增强逻辑-> 事务增强器(环绕增强)
- 事务增强器会做什么事? 提取事务标签属性
- 检查发现当前线程已经绑定了conn资源(并且手动开启了事务..),又发现 当前方法的 传播行为:REQUIRES_NEW ,需要开启一个新的事务..
- 将已经绑定的conn资源 保存到 suspand 变量内
- 因为 REQUIRES_NEW 不会和上层共享同一个事务,所以这一步 又到 datasource.getConnection() 获取了一个全新的 conn 数据库连接资源
- 因为新获取的conn资源的autocommit是true,所以这一步 修改 autocommit 为false,表示手动提交事务,这一步也表示 开启事务(修改conn其它 属性..)
- 绑定conn资源到 TransactionSync…Manager#resources,key:datasource
- 执行事务增强器后面的增强器..
- 最后一个advice调用 target (serviceB)的目标方法 b() 方法
- 假设target b方法 需要访问数据库 执行SQL 的话,程序需要获取一个 conn 资源,到哪拿? DataSourceUtils.getConnection(datasource) 这一步最终会拿到 事务增强器 前置增强逻辑 存放在 TransactionSync..Manager#resources 内的
conn 资源 - 执行方法a逻辑…可能会执行一些 SQL 语句…
- 假设target b方法 需要访问数据库 执行SQL 的话,程序需要获取一个 conn 资源,到哪拿? DataSourceUtils.getConnection(datasource) 这一步最终会拿到 事务增强器 前置增强逻辑 存放在 TransactionSync..Manager#resources 内的
- 线程继续执行 事务增强器 环绕增强的后置逻辑 (代理serviceB.b() 方法的 后置增强)
- 检查发现,serviceB.b() 事务是 b方法开启的,所以 需要做一些事情了
- 执行b方法的增强逻辑-> 事务增强器 (环绕增强-后置增强逻辑)
- 提交事务/回滚事务
- 恢复连接状态 (将conn的autocommit 设置回 true…等等)
- 清理工作(将绑定的conn资源从TransactionSync…Manager#resources移除)
- conn 连接关闭 (归还连接到datasource)
- 检查suspand 发现 该变量有值,需要执行 恢复现场的工作 resume()
- 恢复现场
- 将suspand 挂起的 conn 资源再次 绑定到 TransactionSync…Manager#resources 内,方便 serviceA 继续使用它的conn资源 (它自己的事务)
- 线程继续回到 serviceA.a() 方法内
- 继续执行一些sql …注意 这里它使用的 conn 是 serviceA 申请的 conn
- 线程继续执行 事务增强器 环绕增强的后置逻辑 (代理serviceA.a() 方法的 后置增强)
- 检查发现,serviceA.a() 事务是 a方法开启的,所以 需要做一些事情了
- 执行a方法的增强逻辑-> 事务增强器 (环绕增强-后置增强逻辑)
- 提交事务/回滚事务
- 恢复连接状态 (将conn的autocommit 设置回 true…等等)
- 清理工作(将绑定的conn资源从TransactionSync…Manager#resources移除)
- conn 连接关闭 (归还连接到datasource)
3.隔离级别
3.1 Mysql
| 隔离级别 | 隔离级别的值 | 导致的问题 |
|---|---|---|
| Read-Uncommitted | 0 | 导致脏读 |
| Read-Committed | 1 | 避免脏读,允许不可重复读和幻读 |
| Repeatable-Read | 2 | 避免脏读,不可重复读,允许幻读 |
| Serializable | 3 | 串行化读,事务只能一个一个执行,避免了脏读、不可重复读、幻读。执行效率慢,使用时慎重 |
脏读:一事务对数据进行了增删改,但未提交,另一事务可以读取到未提交的数据。如果第一个事务这时候回滚了,那么第二个事务就读到了脏数据。
不可重复读:一个事务中发生了两次读操作,第一次读操作和第二次操作之间,另外一个事务对数据进行了修改,这时候两次读取的数据是不一致的。
幻读:第一个事务对一定范围的数据进行批量修改,第二个事务在这个范围增加一条数据,这时候第一个事务就会丢失对新增数据的修改。
隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。大多数的数据库默认隔离级别为 Read Commited,比如 SqlServer、Oracle少数数据库默认隔离级别为:Repeatable Read 比如: MySQL InnoDB。
3.2 Spring
| 常量 | 解释 |
|---|---|
| ISOLATION_DEFAULT | 这是个 PlatfromTransactionManager 默认的隔离级别,使用数据库默认的事务隔离级别。另外四个与 JDBC 的隔离级别相对应。 |
| ISOLATION_READ_UNCOMMITTED | 这是事务最低的隔离级别,它允许另外一个事务可以看到这个事务未提交的数据。这种隔离级别会产生脏读,不可重复读和幻像读。 |
| ISOLATION_READ_COMMITTED | 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据。 |
| ISOLATION_REPEATABLE_READ | 这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻像读。 |
| ISOLATION_SERIALIZABLE | 这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。 |
4.事务嵌套
这里内容在实际开发中比较重要,因此我们再来做一下简单的回顾。
假设外层事务 Service A 的 Method A() 调用 内层 Service B 的 Method B()
PROPAGATION_REQUIRED(Spring 默认)
如果 ServiceB.MethodB() 的事务级别定义为 PROPAGATION_REQUIRED,那么执行ServiceA.MethodA() 的时候 Spring 已经起了事务,这时调用 ServiceB.MethodB(),ServiceB.MethodB() 看到自己已经运行在 ServiceA.MethodA() 的事务内部,就不再起新的事务。
假如 ServiceB.MethodB() 运行的时候发现自己没有在事务中,他就会为自己分配一个事务。
这样,在 ServiceA.MethodA() 或者在 ServiceB.MethodB() 内的任何地方出现异常,事务都会被回滚。
PROPAGATION_REQUIRES_NEW
比如我们设计 ServiceA.MethodA() 的事务级别为 PROPAGATION_REQUIRED,ServiceB.MethodB() 的事务级别为 PROPAGATION_REQUIRES_NEW。那么当执行到 ServiceB.MethodB() 的时候,ServiceA.MethodA() 所在的事务就会挂起,ServiceB.MethodB() 会起一个新的事务,等待 ServiceB.MethodB() 的事务完成以后,它才继续执行。
他 与 PROPAGATION_REQUIRED 的 事 务 区 别 在 于 事 务 的 回 滚 程 度 了 。 因 为ServiceB.MethodB() 是新起一个事务,那么就是存在两个不同的事务。如果ServiceB.MethodB() 已 经 提 交 , 那 么 ServiceA.MethodA() 失 败 回 滚 ,ServiceB.MethodB() 是不会回滚的。如果 ServiceB.MethodB() 失败回滚,如果他抛出的异常被 ServiceA.MethodA() 捕获,ServiceA.MethodA() 事务仍然可能提交(主要看 B 抛出的异常是不是 A 会回滚的异常)。
PROPAGATION_SUPPORTS
假设 ServiceB.MethodB() 的事务级别为 PROPAGATION_SUPPORTS,那么当执行到ServiceB.MethodB()时,如果发现 ServiceA.MethodA()已经开启了一个事务,则加入当前的事务,如果发现 ServiceA.MethodA()没有开启事务,则自己也不开启事务。这种时候,内部方法的事务性完全依赖于最外层的事务。
PROPAGATION_NESTED
现 在 的 情 况 就 变 得 比 较 复 杂 了 , ServiceB.MethodB() 的 事 务 属 性 被 配 置 为PROPAGATION_NESTED, 此时两者之间又将如何协作呢?
ServiceB.MethodB() 如果 rollback, 那么内部事务(即 ServiceB.MethodB()) 将回滚到它执行前的 SavePoint而外部事务(即 ServiceA.MethodA()) 可以有以下两种处理方式:
- 捕获异常,执行异常分支逻辑
void MethodA() {try {ServiceB.MethodB();} catch (SomeException) {// 执行其他业务, 如 ServiceC.MethodC();}}
这 种 方 式 也 是 嵌 套 事 务 最 有 价 值 的 地 方 , 它 起 到 了 分 支 执 行 的 效 果 , 如 果ServiceB.MethodB()失败, 那么执行 ServiceC.MethodC(), 而 ServiceB.MethodB()已经回滚到它执行之前的 SavePoint, 所以不会产生脏数据(相当于此方法从未执行过),这 种 特 性 可 以 用 在 某 些 特 殊 的 业 务 中 , 而 PROPAGATION_REQUIRED 和PROPAGATION_REQUIRES_NEW 都没有办法做到这一点。
- 外部事务回滚/提交 代码不做任何修改, 那么如果内部事务(ServiceB.MethodB())rollback, 那么首先 ServiceB.MethodB() 回滚到它执行之前的 SavePoint(在任何情况下都会如此), 外部事务(即 ServiceA.MethodA()) 将根据具体的配置决定自己是commit 还是 rollback。
接下来我们来看事务的源码。
5.Spring事务标签解析
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"><property name="driverClassName" value="${driverClassName}"></property><property name="url" value="${url}"></property><property name="username" value="${jdbc.username}"></property><property name="password" value="${jdbc.password}"></property></bean><!-- spring中基于注解 的声明式事务控制配置步骤1、配置事务管理器2、开启spring对注解事务的支持3、在需要事务支持的地方使用@Transactional注解--><!-- 配置事务管理器 --><bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"><property name="dataSource" ref="dataSource"></property></bean><!-- 开启spring对注解事务的支持--><tx:annotation-driven></tx:annotation-driven>
这是开启Spring事务需要在配置文件写的一些配置标签,主要就是最后一行,开启事务功能。
这个标签不是Spring的原生标签,所以需要额外的解析器来解析。在spring-tx包下的META-INF目录下,有一个spring.handlers配置文件,里面注册了事务标签的解析器。
我们来看下这个解析器。
/*** 这个类就是事务标签解析器,注意这里有一个init方法,加载一些当前解析器能够解析的bean标签,给解析器赋能。*/public class TxNamespaceHandler extends NamespaceHandlerSupport {static final String TRANSACTION_MANAGER_ATTRIBUTE = "transaction-manager";static final String DEFAULT_TRANSACTION_MANAGER_BEAN_NAME = "transactionManager";static String getTransactionManagerName(Element element) {return (element.hasAttribute(TRANSACTION_MANAGER_ATTRIBUTE) ?element.getAttribute(TRANSACTION_MANAGER_ATTRIBUTE) : DEFAULT_TRANSACTION_MANAGER_BEAN_NAME);}@Overridepublic void init() {registerBeanDefinitionParser("advice", new TxAdviceBeanDefinitionParser());//拉看这个标签的解析逻辑registerBeanDefinitionParser("annotation-driven", new AnnotationDrivenBeanDefinitionParser());registerBeanDefinitionParser("jta-transaction-manager", new JtaTransactionManagerBeanDefinitionParser());}}
主要来看下**AnnotationDrivenBeanDefinitionParser**解析器的解析标签逻辑。
@Override@Nullablepublic BeanDefinition parse(Element element, ParserContext parserContext) {//向Spring容器注册一个BD:TransactionalEventListenerFactoryregisterTransactionalEventListenerFactory(parserContext);//从标签里面获取mode属性,一般我们不配置这个属性,所以走else的逻辑String mode = element.getAttribute("mode");if ("aspectj".equals(mode)) {// mode="aspectj"registerTransactionAspect(element, parserContext);if (ClassUtils.isPresent("jakarta.transaction.Transactional", getClass().getClassLoader())) {registerJtaTransactionAspect(element, parserContext);}}else {// mode="proxy" 往下走AopAutoProxyConfigurer.configureAutoProxyCreator(element, parserContext);}return null;}
继续往下走。
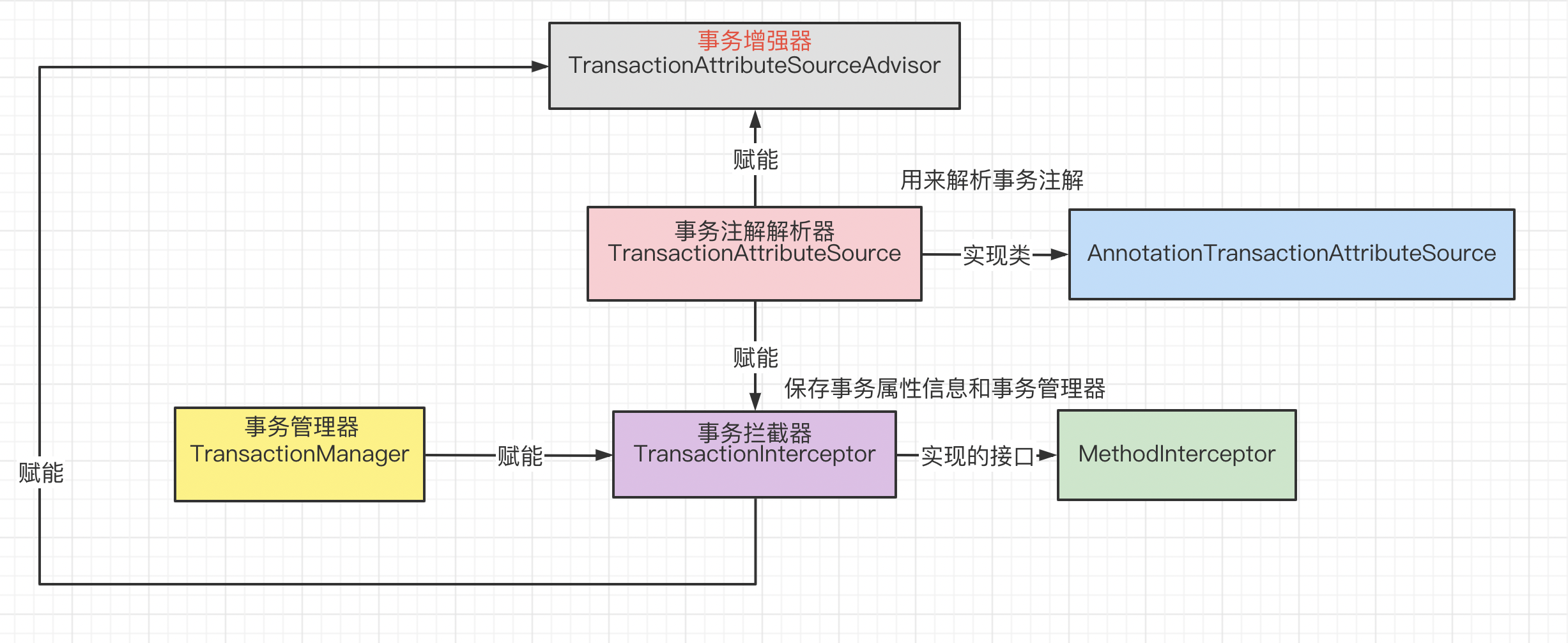
public static void configureAutoProxyCreator(Element element, ParserContext parserContext) {//向Spring容器中注册BD -> InfrastructureAdvisorAutoProxyCreator//BD的名称:internalAutoProxyCreator ,相当于往容器中加入了AOP的组件AopNamespaceUtils.registerAutoProxyCreatorIfNecessary(parserContext, element);//事务切面的名称 :org.springframework.transaction.config.internalTransactionAdvisorString txAdvisorBeanName = TransactionManagementConfigUtils.TRANSACTION_ADVISOR_BEAN_NAME;//如果容器中没有事务切面,就往容器中注册一个事务切面if (!parserContext.getRegistry().containsBeanDefinition(txAdvisorBeanName)) {//把标签包装成一个对象Object eleSource = parserContext.extractSource(element);// Create the TransactionAttributeSource definition.RootBeanDefinition sourceDef = new RootBeanDefinition("org.springframework.transaction.annotation.AnnotationTransactionAttributeSource");sourceDef.setSource(eleSource);sourceDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);String sourceName = parserContext.getReaderContext().registerWithGeneratedName(sourceDef);// Create the TransactionInterceptor definition. 事务增强器RootBeanDefinition interceptorDef = new RootBeanDefinition(TransactionInterceptor.class);interceptorDef.setSource(eleSource);interceptorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);//往bd中注册信息 事务管理器registerTransactionManager(element, interceptorDef);//往bd里面注册事务属性信息interceptorDef.getPropertyValues().add("transactionAttributeSource", new RuntimeBeanReference(sourceName));String interceptorName = parserContext.getReaderContext().registerWithGeneratedName(interceptorDef);// Create the TransactionAttributeSourceAdvisor definition.RootBeanDefinition advisorDef = new RootBeanDefinition(BeanFactoryTransactionAttributeSourceAdvisor.class);advisorDef.setSource(eleSource);advisorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);advisorDef.getPropertyValues().add("transactionAttributeSource", new RuntimeBeanReference(sourceName));advisorDef.getPropertyValues().add("adviceBeanName", interceptorName);if (element.hasAttribute("order")) {advisorDef.getPropertyValues().add("order", element.getAttribute("order"));}parserContext.getRegistry().registerBeanDefinition(txAdvisorBeanName, advisorDef);CompositeComponentDefinition compositeDef = new CompositeComponentDefinition(element.getTagName(), eleSource);compositeDef.addNestedComponent(new BeanComponentDefinition(sourceDef, sourceName));compositeDef.addNestedComponent(new BeanComponentDefinition(interceptorDef, interceptorName));compositeDef.addNestedComponent(new BeanComponentDefinition(advisorDef, txAdvisorBeanName));parserContext.registerComponent(compositeDef);}}
主要就是往容器中注册了几个bean。我们通过一张图来看一下。
6.创建代理对象
上面说到,解析事务标签的时候会往Spring容器中注入一个类**InfrastructureAdvisorAutoProxyCreator**。我们来看一下这个类的继承关系。
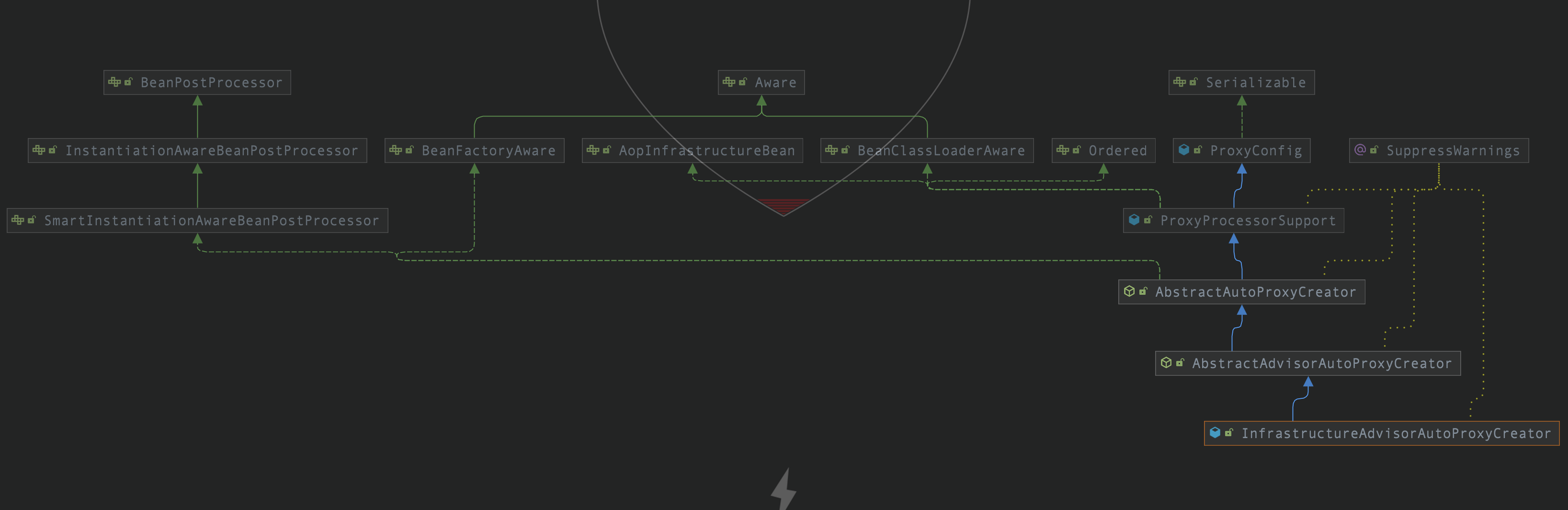
�这个是是一个抽象自动代理创建器,也是一个后置处理器。这里就和AOP的逻辑关联起来了。我们直接看AOP创建代理对象的后置处理器的方法。
@Override
public Object postProcessAfterInitialization(@Nullable Object bean/*spring容器完全初始化完毕的对象*/, String beanName/*bean名称*/) {
if (bean != null) {
/*获取缓存建:大部分情况下都是beanName,如果是工厂bean对象,也有可能是 & */
Object cacheKey = getCacheKey(bean.getClass(), beanName);
/*防止重复代理某个bean实例*/
if (this.earlyProxyReferences.remove(cacheKey) != bean) {
/*判断是否需要包装 AOP操作的入口*/
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}
这里的逻辑前面已经解释过,直接往下走。
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
/*条件一般不成立,因为正常情况下很少使用TargetSourceCreator 去创建对象。BeforeInstantiation阶段*/
if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) {
return bean;
}
/*
* 如果当前bean对象不需要增强处理
* 判断是在BeforeInstantiation阶段阶段做的
*/
if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {
return bean;
}
/*
* 条件一:判断当前bean类型是否是基础框架类型的实例,不能被增强
* 条件二:判断当前beanname是否是是忽略的bean,不需要被增强
*/
if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {
//进入这里表示不需要增强
this.advisedBeans.put(cacheKey, Boolean.FALSE);
//直接返回上层
return bean;
}
//查找适合当前类的通知 非常重要 !!!
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
//判断当前查询出来的通知是不是空,如果不是空,说明走增强逻辑
if (specificInterceptors != DO_NOT_PROXY) {
//记得放在缓存true
this.advisedBeans.put(cacheKey, Boolean.TRUE);
/*真正去创建代理对象*/
Object proxy = createProxy(
bean.getClass()/*目标对象*/, beanName/*beanName*/, specificInterceptors/*匹配当前目标对象class的拦截器*/,
new SingletonTargetSource(bean)/*把当前bean进行了一个封装*/);
//保存代理对象类型
this.proxyTypes.put(cacheKey, proxy.getClass());
//返回代理对象
return proxy;
}
//执行到这里说明没查到这个类相关的通知,没法增强,直接返回
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
看一下**getAdvicesAndAdvisorsForBean()**。
@Override
@Nullable
protected Object[] getAdvicesAndAdvisorsForBean(
Class<?> beanClass, String beanName, @Nullable TargetSource targetSource) {
//查询合适当前类型的通知
List<Advisor> advisors = findEligibleAdvisors(beanClass, beanName);
//通知为空返回空
if (advisors.isEmpty()) {
return DO_NOT_PROXY;
}
//否则转成一个数组返回
return advisors.toArray();
}
继续往下。
protected List<Advisor> findEligibleAdvisors(Class<?> beanClass, String beanName) {
/*获取到当前项目里面所有可以使用的增强器*/
List<Advisor> candidateAdvisors = findCandidateAdvisors();
/*将上一步获取到的全部增强器进行过滤,留下适合当前类的*/
List<Advisor> eligibleAdvisors = findAdvisorsThatCanApply(candidateAdvisors, beanClass, beanName);
/*在这一步,会在index为0 的位置添加一个增强器*/
extendAdvisors(eligibleAdvisors);
if (!eligibleAdvisors.isEmpty()) {
eligibleAdvisors = sortAdvisors(eligibleAdvisors);
}
return eligibleAdvisors;
}
继续往下看过滤增强器的逻辑。
public static List<Advisor> findAdvisorsThatCanApply(List<Advisor> candidateAdvisors, Class<?> clazz) {
/*如果这个类全部可用的增强器为空,直接返回*/
if (candidateAdvisors.isEmpty()) {
return candidateAdvisors;
}
//匹配当前class 的 advisor 信息
List<Advisor> eligibleAdvisors = new ArrayList<>();
//不考虑音阶增强
for (Advisor candidate : candidateAdvisors) {
if (candidate instanceof IntroductionAdvisor && canApply(candidate, clazz)) {
eligibleAdvisors.add(candidate);
}
}
//假设 值为false
boolean hasIntroductions = !eligibleAdvisors.isEmpty();
for (Advisor candidate : candidateAdvisors) {
if (candidate instanceof IntroductionAdvisor) {
// already processed
continue;
}
//判断当前增强器是否匹配class
if (canApply(candidate, clazz, hasIntroductions)) {
eligibleAdvisors.add(candidate);
}
}
//返回的都是匹配当前class的advisor
return eligibleAdvisors;
}
看这个重载的方法**canApply()**。
public static boolean canApply(Advisor advisor, Class<?> targetClass, boolean hasIntroductions) {
if (advisor instanceof IntroductionAdvisor) {
return ((IntroductionAdvisor) advisor).getClassFilter().matches(targetClass);
}
//大多数情况下是走这里,因为创建的增强器是 InstantiationModelAwarePointcutAdvisorImpl
else if (advisor instanceof PointcutAdvisor) {
PointcutAdvisor pca = (PointcutAdvisor) advisor;
//方法重载
return canApply(pca.getPointcut(), targetClass, hasIntroductions);
}
else {
// It doesn't have a pointcut so we assume it applies.
return true;
}
}
Spring事务导入到容器中的增强器是哪一个呢?回顾一下上面的图,**BeanFactoryTransactionAttributeSourceAdvisor**。
我们直接来到这个bean。
这个时候我们在来看**canApply()**。
/*判断当前切点是否匹配当前class*/
public static boolean canApply(Pointcut pc, Class<?> targetClass, boolean hasIntroductions) {
Assert.notNull(pc, "Pointcut must not be null");
//条件成立:说明当前class就不满足切点的定义 ,直接返回,因为后面是判断方法匹配的逻辑,直接返回
if (!pc.getClassFilter().matches(targetClass)) {
return false;
}
//事务逻辑:BeanFactoryTransactionAttributeSourceAdvisor 里面有一个连接点。这个时候获取到的实际上就是事务增强器里面的连接点的方法匹配器。
//其他逻辑不用管,我们直接跳到方法匹配的逻辑。
//获取方法匹配器
MethodMatcher methodMatcher = pc.getMethodMatcher();
//如果是true,直接返回true,因为true不做判断,直接匹配所有方法
if (methodMatcher == MethodMatcher.TRUE) {
// No need to iterate the methods if we're matching any method anyway...
return true;
}
//skip
IntroductionAwareMethodMatcher introductionAwareMethodMatcher = null;
if (methodMatcher instanceof IntroductionAwareMethodMatcher) {
introductionAwareMethodMatcher = (IntroductionAwareMethodMatcher) methodMatcher;
}
//保存当前目标对象clazz + 目标对象 父类 爷爷类 ... 的接口 + 自身实现的接口
Set<Class<?>> classes = new LinkedHashSet<>();
//判断目标对象是不是代理对象,确保classes内存储的数据包括目标对象的class,而不是代理类class
if (!Proxy.isProxyClass(targetClass)) {
classes.add(ClassUtils.getUserClass(targetClass));
}
classes.addAll(ClassUtils.getAllInterfacesForClassAsSet(targetClass));
//遍历classes,获取当前class定义的method,整个for循环会检查当前目标clazz 上级接口的所有方法
//看看是否会被方法匹配器匹配,如果有一个方法匹配成功,就说明目标class需要被AOP代理增强
for (Class<?> clazz : classes) {
Method[] methods = ReflectionUtils.getAllDeclaredMethods(clazz);
for (Method method : methods) {
//事务注释:方法匹配:TransactionAttributeSourcePointcut 的 方法实现。
if (introductionAwareMethodMatcher != null ?
introductionAwareMethodMatcher.matches(method, targetClass, hasIntroductions) :
methodMatcher.matches(method, targetClass)) {
return true;
}
}
}
//执行到这里,说明当前类的所有方法都没有匹配成功,当前类不需要AOP的增强。
return false;
}
�这里会调用到**TransactionAttributeSourcePointcut**类的**matches()**。我们来看一下。
@Override
public boolean matches(Method method, Class<?> targetClass) {
TransactionAttributeSource tas = getTransactionAttributeSource();
return (tas == null || tas.getTransactionAttribute(method, targetClass) != null);
}
继续往下看 **getTransactionAttribute()**, 来到了 **AbstractFallbackTransactionAttributeSource**。
�
@Override
@Nullable
public TransactionAttribute getTransactionAttribute(Method method, @Nullable Class<?> targetClass) {
if (method.getDeclaringClass() == Object.class) {
return null;
}
//缓存的逻辑
// First, see if we have a cached value.
Object cacheKey = getCacheKey(method, targetClass);
TransactionAttribute cached = this.attributeCache.get(cacheKey);
if (cached != null) {
// Value will either be canonical value indicating there is no transaction attribute,
// or an actual transaction attribute.
if (cached == NULL_TRANSACTION_ATTRIBUTE) {
return null;
}
else {
return cached;
}
}
else {
//真正去执行的逻辑。
// We need to work it out. 解析事务属性注解,获取事务属性信息。
TransactionAttribute txAttr = computeTransactionAttribute(method, targetClass);
// Put it in the cache. 加缓存。
if (txAttr == null) {
this.attributeCache.put(cacheKey, NULL_TRANSACTION_ATTRIBUTE);
}
else {
String methodIdentification = ClassUtils.getQualifiedMethodName(method, targetClass);
if (txAttr instanceof DefaultTransactionAttribute) {
DefaultTransactionAttribute dta = (DefaultTransactionAttribute) txAttr;
dta.setDescriptor(methodIdentification);
dta.resolveAttributeStrings(this.embeddedValueResolver);
}
if (logger.isTraceEnabled()) {
logger.trace("Adding transactional method '" + methodIdentification + "' with attribute: " + txAttr);
}
this.attributeCache.put(cacheKey, txAttr);
}
return txAttr;
}
}
查找事物注解信息并加缓存。
**computeTransactionAttribute()**
�
@Nullable
protected TransactionAttribute computeTransactionAttribute(Method method, @Nullable Class<?> targetClass) {
// Don't allow no-public methods as required.
if (allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) {
return null;
}
//获取目标类上的method,因为@Transactional注解可能是标记在接口上的
// The method may be on an interface, but we need attributes from the target class.
// If the target class is null, the method will be unchanged.
Method specificMethod = AopUtils.getMostSpecificMethod(method, targetClass);
//获取目标类上的方法的注解信息。
// First try is the method in the target class.
TransactionAttribute txAttr = findTransactionAttribute(specificMethod);
if (txAttr != null) {
//获取到了就返回
return txAttr;
}
// Second try is the transaction attribute on the target class.
//到实现类的方法上去找
txAttr = findTransactionAttribute(specificMethod.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
//找到则返回
return txAttr;
}
//此时说明注解是打在了接口上,到目标接口上提取method信息
if (specificMethod != method) {
// Fallback is to look at the original method.
txAttr = findTransactionAttribute(method);
if (txAttr != null) {
//找到则返回
return txAttr;
}
//此时说明注解可能打在了目标接口的方法上,到接口的方法上提取注解信息
// Last fallback is the class of the original method.
txAttr = findTransactionAttribute(method.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
}
//说明method并没有定义事务注解信息,不需要事务支持。
return null;
}
这个方法的主要逻辑就是获取到类,接口或者方法上的事务注解信息。我们来看一下具体的解析事务注解的逻辑。**findTransactionAttribute()**。
@Override
@Nullable
protected TransactionAttribute findTransactionAttribute(Method method) {
return determineTransactionAttribute(method);
}
我们先来看这个类的属性,有一个事务注解解析器集合,这个集合是何时赋值的呢?
是在创建这个类的时候,看构造器,我们只需要关注 **SpringTransactionAnnotationParser** 整一个解析器即可。
private final Set<TransactionAnnotationParser> annotationParsers;
public AnnotationTransactionAttributeSource(boolean publicMethodsOnly) {
this.publicMethodsOnly = publicMethodsOnly;
if (jta12Present || ejb3Present) {
this.annotationParsers = new LinkedHashSet<>(4);
this.annotationParsers.add(new SpringTransactionAnnotationParser());
if (jta12Present) {
this.annotationParsers.add(new JtaTransactionAnnotationParser());
}
if (ejb3Present) {
this.annotationParsers.add(new Ejb3TransactionAnnotationParser());
}
}
else {
this.annotationParsers = Collections.singleton(new SpringTransactionAnnotationParser());
}
}
我们再回到提取事务注解信息的逻辑。**determineTransactionAttribute()**
@Nullable
protected TransactionAttribute determineTransactionAttribute(AnnotatedElement element) {
for (TransactionAnnotationParser parser : this.annotationParsers) {
//我们来看 SpringTransactionAnnotationParser 里面的逻辑
TransactionAttribute attr = parser.parseTransactionAnnotation(element);
if (attr != null) {
return attr;
}
}
return null;
}
这里是循环所有的解析器,提取解析事务注解信息,我们来看 **SpringTransactionAnnotationParser** 里面的逻辑。
@Override
@Nullable
public TransactionAttribute parseTransactionAnnotation(AnnotatedElement element) {
//从类或者方法上查找@Transactional这个注解
AnnotationAttributes attributes = AnnotatedElementUtils.findMergedAnnotationAttributes(
element, Transactional.class, false, false);
if (attributes != null) {
//解析注解阶段为事务属性TransactionAttribute
return parseTransactionAnnotation(attributes);
}
else {
return null;
}
}
首先是从类或者方法上查找到注解,然后通过**parseTransactionAnnotation()**解析注解为**TransactionAttribute**。
/**
* 解析事务注解
* @param attributes
* @return
*/
protected TransactionAttribute parseTransactionAnnotation(AnnotationAttributes attributes) {
RuleBasedTransactionAttribute rbta = new RuleBasedTransactionAttribute();
Propagation propagation = attributes.getEnum("propagation");
rbta.setPropagationBehavior(propagation.value());
Isolation isolation = attributes.getEnum("isolation");
rbta.setIsolationLevel(isolation.value());
rbta.setTimeout(attributes.getNumber("timeout").intValue());
String timeoutString = attributes.getString("timeoutString");
Assert.isTrue(!StringUtils.hasText(timeoutString) || rbta.getTimeout() < 0,
"Specify 'timeout' or 'timeoutString', not both");
rbta.setTimeoutString(timeoutString);
rbta.setReadOnly(attributes.getBoolean("readOnly"));
rbta.setQualifier(attributes.getString("value"));
rbta.setLabels(Arrays.asList(attributes.getStringArray("label")));
List<RollbackRuleAttribute> rollbackRules = new ArrayList<>();
for (Class<?> rbRule : attributes.getClassArray("rollbackFor")) {
rollbackRules.add(new RollbackRuleAttribute(rbRule));
}
for (String rbRule : attributes.getStringArray("rollbackForClassName")) {
rollbackRules.add(new RollbackRuleAttribute(rbRule));
}
for (Class<?> rbRule : attributes.getClassArray("noRollbackFor")) {
rollbackRules.add(new NoRollbackRuleAttribute(rbRule));
}
for (String rbRule : attributes.getStringArray("noRollbackForClassName")) {
rollbackRules.add(new NoRollbackRuleAttribute(rbRule));
}
rbta.setRollbackRules(rollbackRules);
return rbta;
}
这里就是具体解析事务注解信息的逻辑。
阶段性梳理一下,这里我们匹配到了事务相关的增强器,接下来我们要去为当前加了Transaction注解的bean创建代理对象。
至此,我们分析完了解析事务标签,创建打了Transaction注解的bean创建代理对象的源码流程分析,接下来就是分析,需要被事务增强的目标方法执行过程中,事务增强器是如何对目标方法加上事务的。

若有收获,就点个赞吧
0 人点赞
