上一篇补充了一下Spring的组件,注解和扩展点,在开发中如果清楚的了解这些东西,会对你的案例设计,产生意想不到的效果。我呢,只是对这些组件注解扩展点进行一个介绍分析,具体的如何为业务赋能还需要结合实际的开发场景。
- 什么是循环依赖?
- 有几种循环依赖?
- Spring是如何解决循环依赖的?
- Spring为什么用三级缓存解决循环依赖,用二级可不可以?
- 当目标对象产生代理对象时,Spring容器中(第一级缓存)到底存储的是谁?
一,问题&答案
1.什么是循环依赖
类和类之间的依赖关系形成了闭环,就叫做循环依赖。
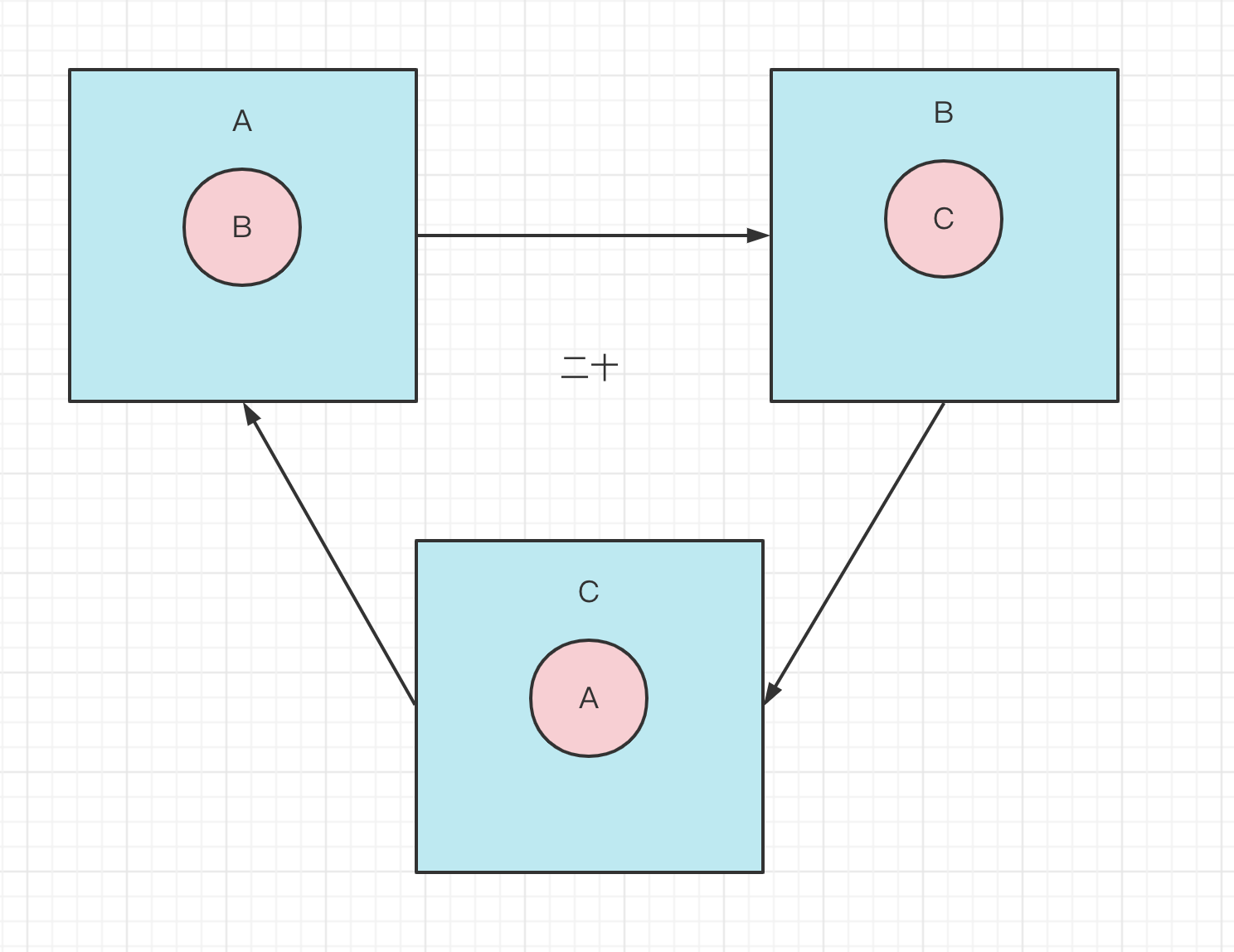
2.有几种循环依赖
- 通过构造方法进行依赖注入时产生的循环依赖问题。
- 通过setter方法进行依赖注入且是在多例(原型)模式下产生的循环依赖问题。
- 通过setter方法进行依赖注入且是在单例模式下产生的循环依赖问题。
注意:在Spring中,只有【第三种方式】的循环依赖问题被解决了,其他两种方式在遇到循环依赖问题时都会产生异常。
- 第一种构造方法注入的情况下,在new对象的时候就会堵塞住了,其实也就是”先有鸡还是先有蛋“的历史难题。
- 第二种setter方法&&多例的情况下,每一次getBean()时,都会产生一个新的Bean,如此反复下去就会有无穷无尽的Bean产生了,最终就会导致OOM问题的出现。
回顾一下单实例bean创建的过程

3.Spring是如何解决循环依赖的?

1.A创建过程中需要B,于是A将自己放到三级缓存去实例化B
2.B实例化的时候发现需要A,于是B先查一级缓存,没有,再查二级缓存,没有,再查三级缓存,找到了A,然后把三级缓存里面的A放到二级缓存里面,并删除三级缓存里面的A。
3.B顺利初始化完毕,将自己放到一级缓存里面(此时B里面的A还未创建完),然后接着回来创建A,此时B已经创建结束,直接从一级缓存里面拿到B,然后完成创建,并将A自己放到一级缓存里面。
spring解决循环依赖依靠的是Bean的中间态这个概念,而这个中间态指的是已经实例化但还没初始化的状态——->半成品。
//DefaultSingletonBeanRegistry
//一级缓存:实例化完的bean
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
//三级缓存:单例bean工厂
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
//二级缓存:早期暴露的bean
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
4.Spring为什么用三级缓存解决循环依赖,用二级可不可以?
为什么第三级缓存要使用ObjectFactory?需要提前产生代理对象。
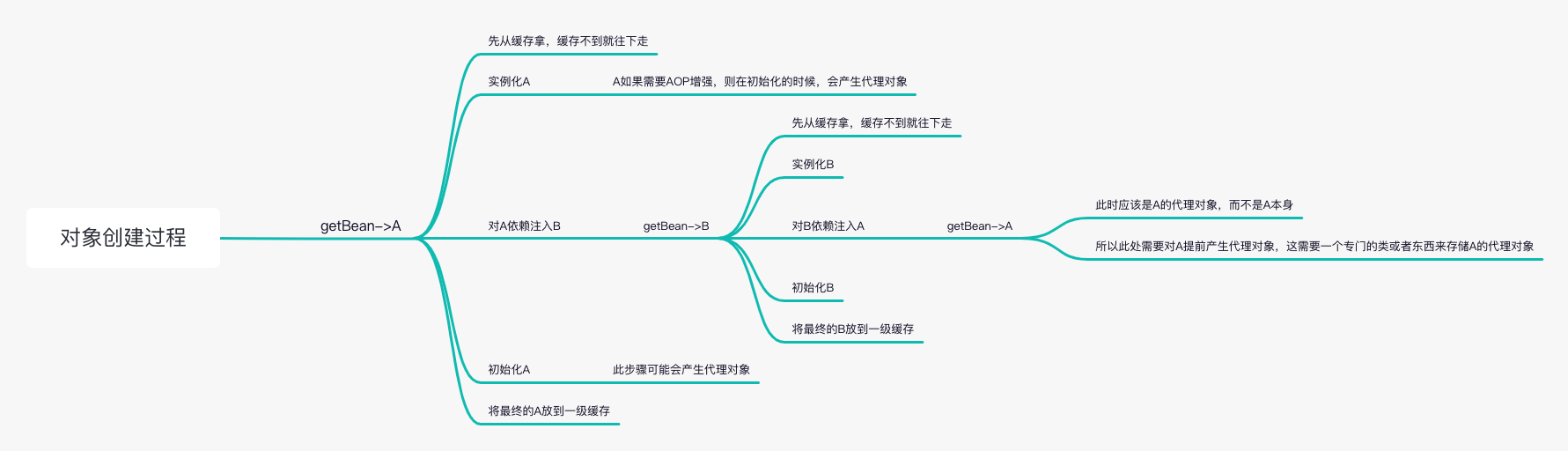
什么时候将Bean的引用提前暴露给第三级缓存的ObjectFactory持有?时机就是在第一步实例化之后,第二步依赖注入之前,完成此操作。

至此,我就解释清楚了整个三级缓存和循环依赖。不得不感慨,在我大三的时候,这道题还号称是阿里P7的面试题,大四的时候,我就连续四场面试被问到,行业内卷啊。

若有收获,就点个赞吧
0 人点赞
