1.string类型的存储过程
在前面的文章我们说过,服务端启动后,客户端发起的一个set k v的命令最终会调用到t_string.c文件的setCommand函数。在这个方法里有两个很核心的操作:
- 将客户端传输过来的字符串对象进行编码
- 将kv键值对存储到数据库
/* SET key value [NX] [XX] [KEEPTTL] [GET] [EX <seconds>] [PX <milliseconds>] */void setCommand(client *c) {....c->argv[2] = tryObjectEncoding(c->argv[2]);setGenericCommand(c,flags,c->argv[1],c->argv[2],expire,unit,NULL,NULL);...}
我们重点来看一下字符串的编码过程。
- 首先会对数据进行检查,确保是一个字符串对象
- 判断是不是能存储为长整形(当字符串长度小于 20 并且可以被解析为 long 类型数据)
- 当字符串长度小于等于 OBJ_ENCODING_EMBSTR_SIZE_LIMIT 配置并且还是 raw 编码时,调用
createEmbeddedStringObject函数将其转化为 embstr 编码 - 如果这个字符串不能编码了,调用
trimStringObjectIfNeeded函数尝试从字符串对象中移除所有空余空间
/* 为了节省空间尝试对string类型编码*/robj *tryObjectEncoding(robj *o) {if (len <= 20 && string2l(s,len,&value)) {...}if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {...emb = createEmbeddedStringObject(s,sdslen(s));...}trimStringObjectIfNeeded(o);...}
我们看一下embstr的编码过程:
- 分配内存【需要存储的字符串的内存,redisObject 的内存,SDS 实现结构体之一 sdshdr8 的内存】
- 将redisObject对象的ptr指针指向sdshdr8 开始的内存地址
- 填充 sdshdr8 对象各个属性
RAW编码对象的创建过程其实和embstr差不多,区别是申请了两次内存。robj *createEmbeddedStringObject(const char *ptr, size_t len) {robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);struct sdshdr8 *sh = (void*)(o+1);o->type = OBJ_STRING;o->encoding = OBJ_ENCODING_EMBSTR;o->ptr = sh+1;...//此处省略填充 sdshdr8 对象各个属性}
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44robj *createStringObject(const char *ptr, size_t len) {if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)return createEmbeddedStringObject(ptr,len);elsereturn createRawStringObject(ptr,len);}
- sdsnewlen() 申请内存创建 SDS 对象
- createObject() 申请内存创建 redisObject 对象
robj *createRawStringObject(const char *ptr, size_t len) {return createObject(OBJ_STRING, sdsnewlen(ptr,len));}
注意,在t_string.c文件中有一个检查字符串长度的方法。
static int checkStringLength(client *c, long long size) {if (!(c->flags & CLIENT_MASTER) && size > server.proto_max_bulk_len) {...}return C_OK;}
我们继续跟踪这个proto_max_bulk_len属性,可以看到在config.c中对他进行了赋值,由此可见一个字符串最大的长度为512M。
createLongLongConfig("proto-max-bulk-len", NULL, MODIFIABLE_CONFIG, 1024*1024, LLONG_MAX, server.proto_max_bulk_len, 512ll*1024*1024, MEMORY_CONFIG, NULL, NULL)
2.字符串编码
上面再看server处理string命令的时候对字符串进行编码过程中,提到了三种编码,根据上面对源码的分析,我们来对三种编码进行一个总结。
int,存储 8 个字节的长整型(long,2^63-1)。
embstr, 代表 embstr 格式的 SDS(Simple Dynamic String 简单动态字符串),存储小于 44 个字节的字符串。
raw,存储大于 44 个字节的字符串(3.2 版本之前是 39 字节)。为什么是 39?
embstr 的使用只分配一次内存空间(因为 RedisObject 和 SDS 是连续的),而 raw需要分配两次内存空间(分别为 RedisObject 和 SDS 分配空间)。因此与 raw 相比,embstr 的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。而 embstr 的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个RedisObject 和 SDS 都需要重新分配空间,因此 Redis 中的 embstr 实现为只读。
当 int 数 据 不 再 是 整 数 , 或 大 小 超 过 了 long 的 范 围(2^63-1=9223372036854775807)时,自动转化为 embstr。
对于 embstr,由于其实现是只读的,因此在对 embstr 对象进行修改时,都会先转化为 raw 再进行修改。因此,只要是修改 embstr 对象,修改后的对象一定是 raw 的,无论是否达到了 44个字节。
关于 Redis 内部编码的转换,都符合以下规律:编码转换在 Redis 写入数据时完成,且转换过程不可逆,只能从小内存编码向大内存编码转换(但是不包括重新 set)。
为什么redis要对底层的数据结构进行一层封装?通过封装,可以根据对象的类型动态地选择存储结构和可以使用的命令,实现节省空间和优化查询速度。
3.SDS
3.1 什么是SDS
我们知道redis是kv的数据库,他是通过hashtable实现的(外哈希)。所以每个键值对都会有一个dictEntry(源码位置:dict.h),里面指向了key 和value的指针。next指向下一个dictEntry。
key 是字符串,但是 Redis 没有直接使用 C 的字符数组,而是存储在自定义的 SDS中。
value 既不是直接作为字符串存储,也不是直接存储在 SDS 中,而是存储在redisObject 中。实际上五种常用的数据类型的任何一种,都是通过 redisObject 来存储的。
根据上面的源码分析我们知道在RAW编码的时候,redisObject的ptr指针指向了sdshdr8的首个内存地址,接下来我们来看一看什么是SDS。
SDS是redis中字符串的实现。为什么Redis要用SDS来实现字符串?C 语言本身没有字符串类型(只能用字符数组 char[]实现)。
使用字符数组必须先给目标变量分配足够的空间,否则可能会溢出。
如果要获取字符长度,必须遍历字符数组,时间复杂度是 O(n)。
C 字符串长度的变更会对字符数组做内存重分配。
通过从字符串开始到结尾碰到的第一个’\0’来标记字符串的结束,因此不能保存图片、音频、视频、压缩文件等二进制(bytes)保存的内容,二进制不安全。
在 3.2 以后的版本中,SDS 又有多种结构(sds.h):sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64,用于存储不同的长度的字符串,分别代表 25=32byte,28=256byte,216=65536byte=64KB,232byte=4GB。
struct __attribute__ ((__packed__)) sdshdr8 {uint8_t len; /* 当前字符数组的长度 */uint8_t alloc; /*当前字符数组总共分配的内存大小 */unsigned char flags; /* 当前字符数组的属性、用来标识到底是 sdshdr8 还是 sdshdr16 等 */char buf[]; /* 字符串真正的值 */};
SDS的特点:
不用担心内存溢出问题,如果需要会对 SDS 进行扩容。
获取字符串长度时间复杂度为 O(1),因为定义了 len 属性。
通过“空间预分配”( sdsMakeRoomFor)和“惰性空间释放”,防止多次重分配内存。
判断是否结束的标志是 len 属性(它同样以’\0’结尾是因为这样就可以使用 C语言中函数库操作字符串的函数了),可以包含’\0’。
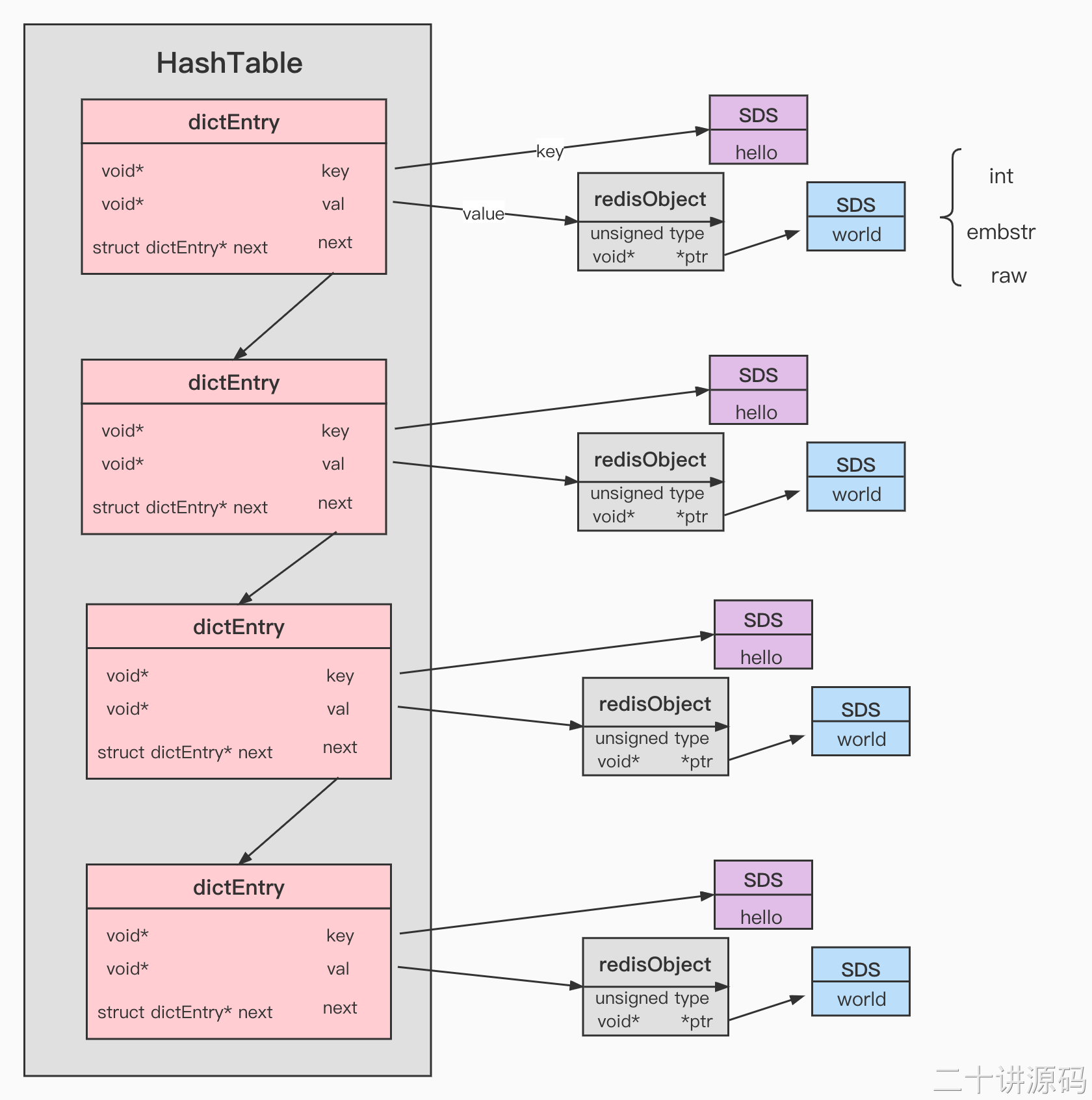
注意:其实key也是一个RedisObject对象里面的指针指向了SDS字符串,只不过考虑图片空间大小,以及观赏性,并没有画出来。
3.2 SDS的容量调整
append操作可能会触发字符串的扩容,所以我们直接来看append操作对应的函数appendCommand。这里的逻辑并不复杂,首先就是通过lookupKeyWrite函数去查找这个key是否已经存在,如果不存在就去创建,如果已经存在,经过一些判断之后就会去重新设置ptr指针所指向的sds字符串。我们接着往下看这里的逻辑。
void appendCommand(client *c) {o = lookupKeyWrite(c->db,c->argv[1]);if (o == NULL) {//省略创建新的kv的逻辑} else {...o->ptr = sdscatlen(o->ptr,append->ptr,sdslen(append->ptr));...}...}
这里通过sdsMakeRoomFor函数重新为sds对象分配内存,我们来具体看一下逻辑。
sds sdscatlen(sds s, const void *t, size_t len) {...s = sdsMakeRoomFor(s,len);...}
首先我们看SDS的扩容函数:当字符串长度小于1M,每次扩容一倍,否则每次扩容1M,防止浪费空间。
sds sdsMakeRoomFor(sds s, size_t addlen) {...newlen = (len+addlen);if (newlen < SDS_MAX_PREALLOC/*(1024 * 1024)*/)newlen *= 2;elsenewlen += SDS_MAX_PREALLOC;...}
�SDS的缩容实际上很简单:
- 重置 SDS 表头的 len 属性值为 0
- 将结束符放到 buf 数组最前面,相当于惰性地删除 buf 中的内容
由此可见,这是一种惰性删除或者惰性释放空间的删除。
void sdsclear(sds s) {sdssetlen(s, 0);s[0] = '\0';}
4.自增指令incrby
我们先来看一下自增指令incrby对应的操作函数incrbyCommand。
void incrbyCommand(client *c) {long long incr;if (getLongLongFromObjectOrReply(c, c->argv[2], &incr, NULL) != C_OK) return;incrDecrCommand(c,incr);}
可以看到这里面的核心操作其实就是incrDecrCommand函数,我们来看一下这个函数的逻辑。
void incrDecrCommand(client *c, long long incr) {...if (getLongLongFromObjectOrReply(c,o,&value,NULL) != C_OK) return;...value += incr;...}
如果对多线程有一些基础的了解,一定可以看出这个代码在多线程并发访问下是数据不安全的,那么Redis是如何保证这个命令的原子性呢?
首先在6.0版本以前,Redis采用的是单线程IO多路复用,因为是单线程的,所以不存在数据安全问题。而Redis6.0以后的多线程,仅仅是把对网络数据的读写交给子线程来完成,业务逻辑依然是主线程来处理,所以仍然不存在并发安全问题,正是因为Redis里面没有那么多的锁,再加上纯内存操作,所以Redis很快。
5.应用场景
接下来我们聊一聊string类型的应用场景
①缓存
热点数据缓存,对象缓存,全页缓存,提升热点数据的访问速度。
②分布式数据共享
Redis 是分布式的独立服务,可以在多个应用之间共享。
<dependency><groupId>org.springframework.session</groupId><artifactId>spring-session-data-redis</artifactId></dependency>
③分布式锁
STRING 类型 setnx 方法,只有不存在时才能添加成功,返回 true。
public Boolean getLock(Object lockObject){jedisUtil = getJedisConnetion();boolean flag = jedisUtil.setNX(lockObj, 1);if(flag){expire(locakObj,10);}return flag;}public void releaseLock(Object lockObject){del(lockObj);}
④全局ID
INT 类型,INCRBY,利用原子性。
incrby userid 1000
⑤计数器
INT 类型,INCR 方法。例如:文章的阅读量,微博点赞数,允许一定的延迟,先写入 Redis 再定时同步到数据库。
⑥限流
INT 类型,INCR 方法。以访问者的 IP 和其他信息作为 key,访问一次增加一次计数,超过次数则返回 false。
⑦位统计
String 类型的 BITCOUNT(1.6.6 的 bitmap 数据结构介绍)。字符是以 8 位二进制存储的。
set k1 asetbit k1 6 1setbit k1 7 0get k1
a 对应的 ASCII 码是 97,转换为二进制数据是 01100001
b 对应的 ASCII 码是 98,转换为二进制数据是 01100010
因为 bit 非常节省空间(1 MB=8388608 bit),可以用来做大数据量的统计。
例如:在线用户统计,留存用户统计。
最后,思考一下,如果一个对象的 value 有多个值的时候,怎么存储?
例如用一个 key 存储一张表的数据。序列化?例如 JSON/Protobuf/XML,会增加序列化和反序列化的开销,并且不能单独获取、修改一个值。其实可以通过 key 分层的方式来实现,例如:
mset student:1:sno GP16666 student:1:sname 沐风 student:1:company 腾讯
获取值的时候一次获取多个值:
mget student:1:sno student:1:sname student:1:company
缺点:key 太长,占用的空间太多。有没有更好的方式?那就是使用hash数据结构。我们将会在下一篇分析hash数据结构。

若有收获,就点个赞吧
0 人点赞
