一,大key热key问题
Redis的大key和热key实际上就是经常被访问的key或者占用空间比较大的key,比如说某个明星出轨了,这个明星的搜索量就会暴增,对redis造成很大的冲击。
Redis本身提供了命令来查看这两种key:
#redis查看大key命令redis-cli --bigkeys#redis查看热key命令redis-cli --hotkeys
对于大key,热key的处理:
首先业务测redis写数据的时候自己去预估一下这个写入会不会有可能变成一个大key,有这种可能的话就要提前做出处理,存monogo或者拆分。
根据业务经验判断,比如大促之前,提前判断热点商品,但不是所有的业务场景都能判断。
通过一些Redis的监控插件进行监控,一旦发现大key,热key,移动到专门的集群。
利用多级缓存,提前预热。
如何设计一个简单的Redis大key&热key的监控系统?
- 通过crontab任务调度shell脚本,每天凌晨通过redis-rdb-tool工具解析Redis的rdb文件,过滤rdb文件中的大key导出为csv文件,然后使用SQL导入csv文件存储MySQL。
- 同时使用canal监听MySQL的binlog日志,发送增量数据到rocketmq,rocketmq的消费者进行消费。
- 消息中包含的大key的db索引,key的名称,大小,类型等信息,消费者将大key的信息进行展示或者通知。
为什么要把大key的csv文件导入到MySQL进行存储,而不是直接监听大key的csv文件?
- 如果不导入MySQL,就无法使用canal监听,这样就要开发一个程序,定时去扫redis节点下解析出来的csv文件,如果redis集群有多个节点,那么每一个节点都要去扫描;而现在将csv文件导入到MySQL之后,只需要使用canal去监听同一个MySQL表的binlog,就可以把增量数据同步到rocketmq中,由消费者统一进行处理。
- 解析csv文件比直接从MySQL中查询复杂得多,尤其是带有多种查询条件的信息过滤,导入到MySQL后可以通过SQL轻松的对大key的记录进行条件过滤选择,并且可以对每天产生的大key进行存储分析。
二,MySQL&Redis双写一致性
实现双写一致性的目的就是为了达到最终一致性,如果不能接受中间的状态,那就只能抛弃缓存。给缓存设置过期时间,是保证最终一致性的解决方案。
我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存,达到一致性,切记以mysql的数据库写入库为准。
1.先更新MySQL再更新Redis
先更新mysql的某商品的库存,当前商品的库存是100,更新为99个。
mysql修改为99成功,然后更新redis。
此时假设异常出现,更新redis失败了,这导致mysql里面的库存是99而redis里面的还是100 。
上述发生,会让数据库里面和缓存redis里面数据不一致,读到脏数据
2.先删除Redis,在更新MySQL
请求A进行写操作,删除缓存,正在进行中……
请求B开工,查询发现缓存不存在
请求B继续,去数据库查询得到旧值
请求B将旧值写入缓存
请求A将新值写入数据库
上述情况就会导致不一致的情形出现,而且,如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。接下来我们分析下这种情况下的解决方案。
2.1 延时双删
线程A先成功删除缓存
线程A在更新mysql
暂停一段时间(等待业务逻辑的执行)
再删除缓存
①双删方案的休眠时间如何确定?
自行评估自己的项目的读数据业务逻辑的耗时。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上,加几百ms即可。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
②当前是mysql单机模式,如果是读写分离结构应该怎么办?
请求A进行写操作,删除缓存
请求A将数据写入数据库了
请求B查询缓存发现,缓存没有值
请求B去从库查询,这时,还没有完成主从同步,因此查询到的是旧值
请求B将旧值写入缓存
数据库完成主从同步,从库变为新值
上述情形,就是数据不一致的原因。还是使用双删延时策略。只是,睡眠时间修改为在主从同步的延时时间基础上,加几百ms。
③这种同步淘汰策略,吞吐量降低怎么办?
利用CompletableFuture将第二次删除作为异步删除,单独起一个线程,这样,写的请求就不用sleep一段时间在返回了,这么做加大了吞吐量。
2.2 兜底方案
更新数据库数据
缓存因为种种问题删除失败
将需要删除的key发送至消息队列
自己消费消息,获得需要删除的key
继续重试删除操作,直到成功
3.基于MySQL的binlog异步更新
整体思路
涉及到更新的数据操作,利用Mysql binlog 进行增量订阅消费
将消息发送到消息队列
通过消息队列消费将增量数据更新到Redis上
操作情况
读取Redis缓存:热数据都在Redis上
写Mysql:增删改都是在Mysql进行操作
更新Redis数据:Mysql的数据操作都记录到binlog,通过消息队列及时更新到Redis上
Redis更新过程
- 数据操作主要分为两种:
一种是全量(将所有数据一次性写入Redis),一种是增量(实时更新)
这里说的是增量,指的是mysql的update、insert、delate变更数据。
- 读取binlog后分析 ,利用消息队列,推送更新各台的redis缓存数据
这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新,其实这种机制,很类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致性。
这里的消息推送工具也可以采用别的第三方:kafka、rabbitMQ等来实现推送更新Redis!
在高并发应用场景下,如果是对数据一致性要求高的情况下,要定位好导致数据和缓存不一致的原因。解决高并发场景下数据一致性的方案有两种,分别是延时双删策略和异步更新缓存两种方案。另外,设置缓存的过期时间是保证数据保持一致性的关键操作,需要结合业务进行合理的设置。
4.先更新Redis,在更新MySQL
尽量不要这么做。
Canal用于Mysql数据库增量日志数据的订阅,消费和解析,是阿里巴巴开发并开源的。直白点说canal是基于Mysql变更日志增量订阅和消费的组件。主要应用于:
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引,倒排索引等)
- 业务cache刷新
- 带业务逻辑的增量数据处理
工作原理:canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议,MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal ),canal 解析 binary log 对象(原始为 byte 流)。
三,布隆过滤器
通常我们在实际项目中使用mysql来存储数据,随着数据量的增大,我们通常会将一些不经常改变的,将常被查询的数据放到redis来提高查询效率,提高响应速度。但是随着redis的引入也会产生一系列的问题。
1.缓存击穿
当我们在redis设置了一个带有过期时间的key,此时当大量请求来查询则这个key的时候,这个key刚好过期,就会导致这些请求全部打到数据库,瞬间对数据库造成巨大压力,导致mysql宕机。
2.缓存穿透
当我们去redis查询一个不存在的key,redis里面没有,于是去查数据库,数据库也没有,当下次再有大量请求过来的时候,就会全部打到数据库,造成mysql宕机。
3.缓存雪崩
大量的key同一时间失效。缓存雪崩有两种情况:
过期时间设置的有问题导致。
Redis集群宕机了,并且后续没有熔断,限流,降级的规则。
4.布隆过滤器
使用布隆过滤器解决缓存穿透问题:把已经存在数据的key放到布隆过滤器,相当于redis前面挡着一个布隆过滤器。当有新的请求时,先到布隆过滤器中查询是否存在:如果布隆过滤器不存在这条数据直接返回;如果布隆过滤器已经存在这条数据,才去查询缓存redis,如果redis里没查询到则穿透到mysql数据库。
4.1 原理
高效的插入和查询,占用空间少,返回的结果是不确定的。一个元素如果判断结果未存在的时候元素不一定存在,但是判断结果未不存在的时候,就是一定不存在。简单点说:有是可能有,无是一定无。布隆过滤器可以添加元素,但是不能删除元素。因为删除元素会导致误判率增加。误判只会发生在过滤器没有添加过的元素,对于添加过的元素不会发生误判。
每个布隆过滤器对应到redis的数据结构中就是一个大型位数组,和几个分布均匀的hash函数。添加key的时候,使用多个hash函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,每个hash函数都会得到一个不同的位置,将这几个位置都置1就完成了add操作。查询key的时候,只要其中有一位时0就表示这个key不存在,但如果都是1,却不一定存在对应的key。
布隆过滤器的误判是指多个输入经过hash之后在相同的bit位置1了,这样就无法判断究竟是哪个输入产生的,因此误判的根源在于相同的bit位被多次映射且置1。这种情况也造成了布隆过滤器的删除问题,因为他的每一个并不是独占的,很有可能多个元素共享了某一位。如果我们直接删除这一位的话,会影响其他的元素。如果非要删除元素,可以考虑使用布谷鸟过滤器。
4.2 自定义布隆过滤器
/**
* @author yhd
* @createtime 2020/11/11 10:17
* @param BitSet 线程不安全的位数组,初始只有一个long,会自动扩容,值只存0 1。
*/
public class MyBloomFilter {
//位数组的大小
private static final int DEFAULT_SIZE = 2 << 24;
//通过这个数组可以创建5个不同的hash函数
private static final int[] FUNCTIONS = new int[]{3, 13, 46, 71, 91};
//位数组:数组中的元素只能是0 或者 1
private BitSet bits = new BitSet(DEFAULT_SIZE);
//存放包含hash函数的类的数组
private MyHash[] fun = new MyHash[FUNCTIONS.length];
//初始化多个包含hash函数的类的数组,每个类中的hash函数都不一样
public MyBloomFilter() {
//初始化多个不同的hash函数
for (int i = 0; i < FUNCTIONS.length; i++) {
fun[i] = new MyHash(DEFAULT_SIZE, FUNCTIONS[i]);
}
}
//用于判断指定元素是否存在于位数组
public boolean contains(Object value) {
boolean flag = true;
for (MyHash hash : fun)
flag = flag && bits.get(hash.hash(value));
return flag;
}
//添加元素到位数组
public void add(Object value) {
for (MyHash hash : fun)
bits.set(hash.hash(value), true);
}
//用于hash操作的静态内部类
public static class MyHash {
private Integer yhd;
private Integer var;
public MyHash(Integer yhd, Integer var) {
this.yhd = yhd;
this.var = var;
}
//计算hash值
public Integer hash(Object value) {
int temp;
return (value == null) ? 0 : Math.abs(var * (yhd - 1) & ((temp = value.hashCode()) ^ (temp >>> 16)));
}
}
}
这里因为是在模拟思想,所以并没有考虑bitSet的线程安全问题,实际上在并发访问过程中,应该考虑使用线程安全的二进制集合替代bitSet。
4.3 应用场景
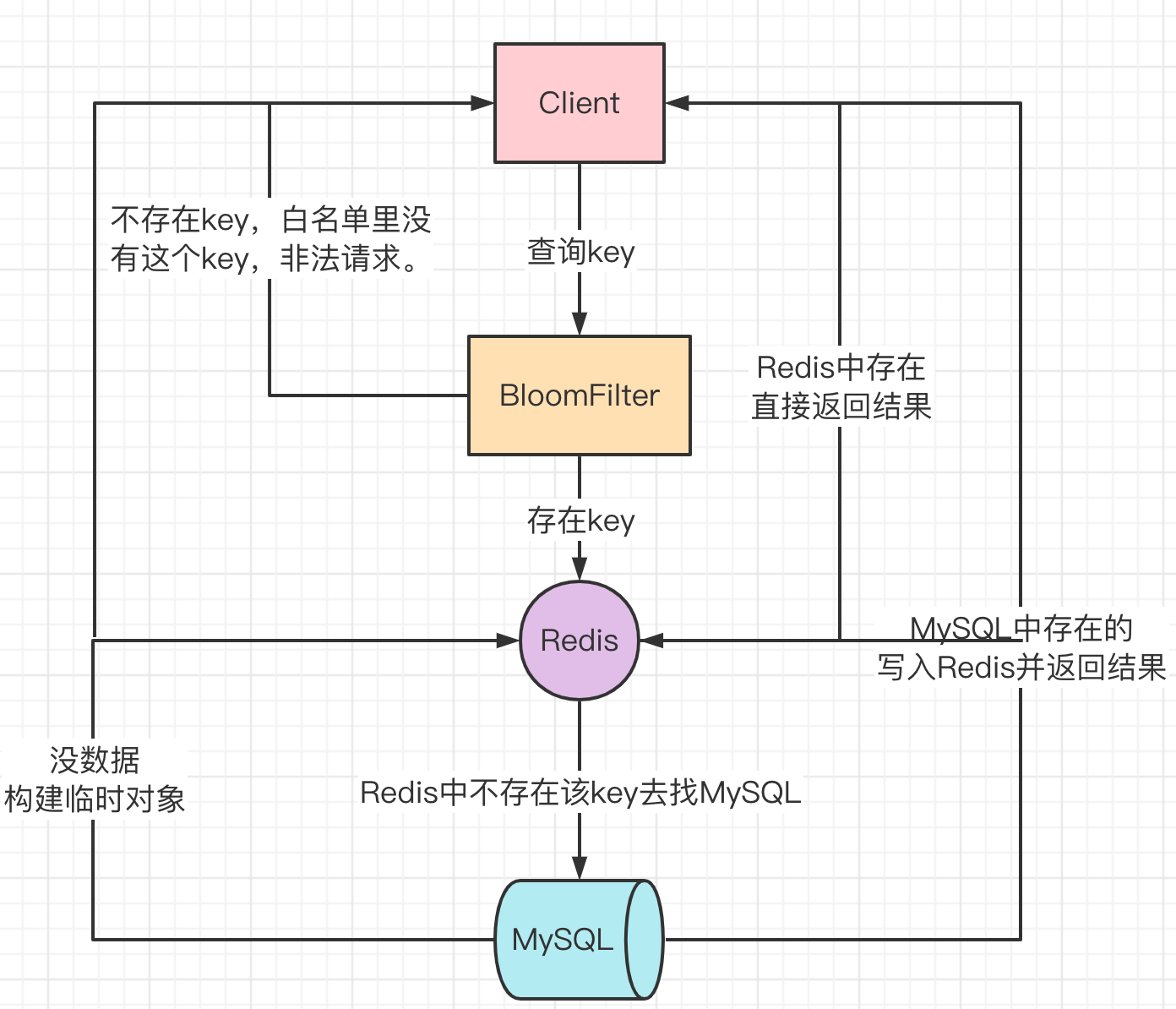
①白名单
当布隆过滤器作为白名单使用的时候,白名单里面有的才让通过,没有直接返回。但是存在误判,由于误判率很小,1%-3%的打到MySQL,可以接受。
所有key都需要往Redis & BloomFilter 里面放入。
②黑名单
布隆过滤器作为黑名单使用:
- 抖音防止推荐重复视频
- 饿了么防止推荐重复优惠券
推荐前先判断布隆过滤器该用户有没有被推荐过该视频,如果存在说明已经推荐过,不再重复推荐,否则就是新视频,推荐给用户并更新进布隆过滤器,防止下次重复推荐。
四,分布式锁
随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的Java API并不能提供分布式锁的能力,本地锁只能锁住同一个JVM内的资源,在分布式系统中存在局限性。为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
分布式锁主流的实现方案:
- 基于数据库实现分布式锁
- 基于缓存(Redis等)
- 基于Zookeeper
每一种分布式锁解决方案都有各自的优缺点:
- 性能:redis最高
- 可靠性:zookeeper最高
这里,我们就基于redis实现分布式锁。
# set k1 v1 NX PX 10000
- EX second :设置键的过期时间为 second 秒。 SET key value EX second 效果等同于 SETEX key second value 。
- PX millisecond :设置键的过期时间为 millisecond 毫秒。 SET key value PX millisecond 效果等同于 PSETEX key millisecond value 。
- NX :只在键不存在时,才对键进行设置操作。 SET key value NX 效果等同于 SETNX key value 。
- XX :只在键已经存在时,才对键进行设置操作。
1.原生setnx
此种实现方式下,多个客户端同时通过setnx命令获取锁,获取锁成功的线程执行业务逻辑,执行完成释放锁,没获取到锁的线程等待重试。
假如线程刚刚获取到锁,业务逻辑出现了异常,就会导致锁无法释放,可以通过设置过期时间来解决,达到过期时间自动释放锁。
public void testLock() {
// 1. 从redis中获取锁,setnx
Boolean lock = this.redisTemplate.opsForValue().setIfAbsent("lock", "111");
if (lock) {
// 查询redis中的num值
String value = (String)this.redisTemplate.opsForValue().get("num");
// 没有该值return
if (StringUtils.isBlank(value)){
return ;
}
// 有值就转成成int
int num = Integer.parseInt(value);
// 把redis中的num值+1
this.redisTemplate.opsForValue().set("num", String.valueOf(++num));
// 2. 释放锁 del
this.redisTemplate.delete("lock");
} else {
// 3. 每隔1秒钟回调一次,再次尝试获取锁
try {
Thread.sleep(1000);
testLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
2.给锁设置过期时间
用set k1 v1 NX PX 10000代替setnx k1 v1,在set的时候指定过期时间。但是这种处理方式下,一个线程可能会释放其他线程持有的锁。
假如业务的执行时间是5s,锁的超时时间为3s,线程A拿到锁之后执行3秒后,锁被释放,此时A的业务继续执行,但是假如释放的锁被线程B拿到去执行任务,当B执行到2s时,A线程的业务执行完了,删除锁,实际上删除的是线程B的锁。最终等于没锁的情况。
可以在setnx获取锁的时候,设置一个唯一值,释放锁之前获取这个值,判断是不是当前线程持有的锁。
3.添加唯一标识防错删
public void testLock() {
String uuid = UUID.randomUUID().toString();
// 1. 从redis中获取锁,setnx
Boolean lock = this.redisTemplate.opsForValue().setIfAbsent("lock", uuid,2,TimeUnit.SECOND);
if (lock) {
// 查询redis中的num值
String value = (String)this.redisTemplate.opsForValue().get("num");
// 没有该值return
if (StringUtils.isBlank(value)){
return ;
}
// 有值就转成成int
int num = Integer.parseInt(value);
// 把redis中的num值+1
this.redisTemplate.opsForValue().set("num", String.valueOf(++num));
// 2. 释放锁 del
if(uuid.equals(redisTemplate.opsForValue().get("lock")){
this.redisTemplate.delete("lock");
}
} else {
// 3. 每隔1秒钟回调一次,再次尝试获取锁
try {
Thread.sleep(1000);
testLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
这次我们在删除锁的时候提前判断锁是否是当前线程的,如果是再删除。但是这样的删除缺乏原子性。
线程A执行删除操作时,查询到的value确实和uuid相等,在线程A比较完之后执行删除前,lock刚好过期时间已经到了,被redis自动释放。这个时候线程B刚好拿到了锁,线程A这个时候执行删除会删除掉线程B的锁。
我们可以通过Redis的事务或者lua脚本来保证删除操作的原子性。
4.Lua脚本保证删除的原子性
public void testLock() {
// 声明一个uuid ,将做为一个value 放入我们的key所对应的值中
String uuid = UUID.randomUUID().toString();
// 定义一个锁:lua 脚本可以使用同一把锁,来实现删除!
String skuId = "25"; // 访问skuId 为25号的商品 100008348542
String locKey ="lock:"+skuId; // 锁住的是每个商品的数据
Boolean lock = redisTemplate.opsForValue().setIfAbsent(locKey, uuid,3,TimeUnit.SECONDS);
// 第一种: lock 与过期时间中间不写任何的代码。
// redisTemplate.expire("lock",10, TimeUnit.SECONDS);//设置过期时间
// 如果true
if (lock){
// 执行的业务逻辑开始
// 获取缓存中的num 数据
String value = redisTemplate.opsForValue().get("num");
// 如果是空直接返回
if (StringUtils.isBlank(value)){
return;
}
// 不是空 如果说在这出现了异常! 那么delete 就删除失败! 也就是说锁永远存在!
int num = Integer.parseInt(value);
// 使num 每次+1 放入缓存
redisTemplate.opsForValue().set("num",String.valueOf(++num));
// 定义lua 脚本
String script="if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 使用redis执行lua执行
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
// 设置一下返回值类型 为Long
// 因为删除判断的时候,返回的0,给其封装为数据类型。如果不封装那么默认返回String 类型,那么返回字符串与0 会有发生错误。
redisScript.setResultType(Long.class);
// 第一个要是script 脚本 ,第二个需要判断的key,第三个就是key所对应的值。
redisTemplate.execute(redisScript, Arrays.asList(locKey),uuid);
}else {
// 其他线程等待
try {
// 睡眠
Thread.sleep(1000);
// 睡醒了之后,调用方法。
testLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
- 互斥性。在任意时刻,只有一个客户端能持有锁。
- 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
- 加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
- 加锁和解锁必须具有原子性。
redis集群状态下的问题:客户端A从master获取到锁,在master将锁同步到slave之前,master宕掉了。 slave节点被晋级为master节点 ,客户端B取得了同一个资源被客户端A已经获取到的另外一个锁。 此时安全失效!
解决方案:redlock,为了解决故障转移情况下的缺陷,产生了红锁算法。使用红锁算法,需要多台redis实例,加锁的时候,他会像多半节点发送setnx mykey myvalue命令,只要过半节点成功了,那么就算加锁成功了。释放锁的时候,需要向所有节点发送del命令。这是一种基于大多数都同意的机制。红锁解决问题的同时,也带来了代价。需要多个redis实例,代码和性能上会有一定影响。
5.Redisson
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。其中包括(BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service)Redisson提供了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
基于Redis的Redisson分布式可重入锁RLock Java对象实现了java.util.concurrent.locks.Lock接口。如果负责储存这个分布式锁的Redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是30秒钟,也可以通过修改Config.lockWatchdogTimeout来另行指定。另外Redisson还通过加锁的方法提供了leaseTime的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
RLock lock = redisson.getLock("anyLock");
// 最常使用
lock.lock();
// 加锁以后10秒钟自动解锁
// 无需调用unlock方法手动解锁
lock.lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}
基于Redis的Redisson分布式可重入读写锁RReadWriteLock Java对象实现了java.util.concurrent.locks.ReadWriteLock接口。其中读锁和写锁都继承了RLock接口。分布式可重入读写锁允许同时有多个读锁和一个写锁处于加锁状态。
RReadWriteLock rwlock = redisson.getReadWriteLock("anyRWLock");
// 最常见的使用方法
rwlock.readLock().lock();
// 或
rwlock.writeLock().lock();
// 10秒钟以后自动解锁
// 无需调用unlock方法手动解锁
rwlock.readLock().lock(10, TimeUnit.SECONDS);
// 或
rwlock.writeLock().lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = rwlock.readLock().tryLock(100, 10, TimeUnit.SECONDS);
// 或
boolean res = rwlock.writeLock().tryLock(100, 10, TimeUnit.SECONDS);
...
lock.unlock();

若有收获,就点个赞吧
0 人点赞
