并发场景下,常见的设计模式可能存在线程安全问题,比如单例模式就是一个典型。另外,为了充分发挥多核的优势,高并发程序通常会将大的任务分割成一些规模比较小的任务,分而治之,这就出现了高并发下特有的一些设计模式,比如ForkJoin模式等等。
一,线程安全的单例模式
1.双重检查锁
public class SingletonTestA {private static volatile SingletonTestA instance;private SingletonTestA() {}public static SingletonTestA getInstance() {/**判断对象是否已经初始化,如果已经初始化,直接返回。如果尚未初始化,加锁*/if (instance == null)synchronized (SingletonTestA.class) {/**再次判断是否已经初始化,通过第一层判断的线程可能有很多,但是能够获得锁的线程只有一个。*/if (instance == null)/*分配一块内存M在内存M上初始化Singleton对象M的地址赋值给instance变量指令重排后可能会出现问题*/instance = new SingletonTestA();}return instance;}}
2.静态内部类
public class SingletonTestA {private static class LazyHolder{private static final SingletonTestA instance = new SingletonTestA();}private SingletonTestA() {}/*** 只有在方法被调用的时候,才会去加载内部类并且初始化单例。* @return*/public static SingletonTestA getInstance() {return LazyHolder.instance;}}
二,Master-Worder模式
Master-Worker模式是一种常见的高并发模式,它的核心思想是任务的调度和执行分离,调度任务的角包五为Master,执行任务的角色为 Worker,Master负责接收、分配任务务和合并(Merge)任务结果, Worker负责执行任务。Master-Work er模式是一种归并类型的模式。
举一个例子,在TCP服务端的请青求处理过程中,大量的客户端连接相当于大量的任务,Master需要将这些任务存储在一个任务队列中,然后分发给各个Worker,每个Worker是一个工作线程,负责完成连接的传输处理。
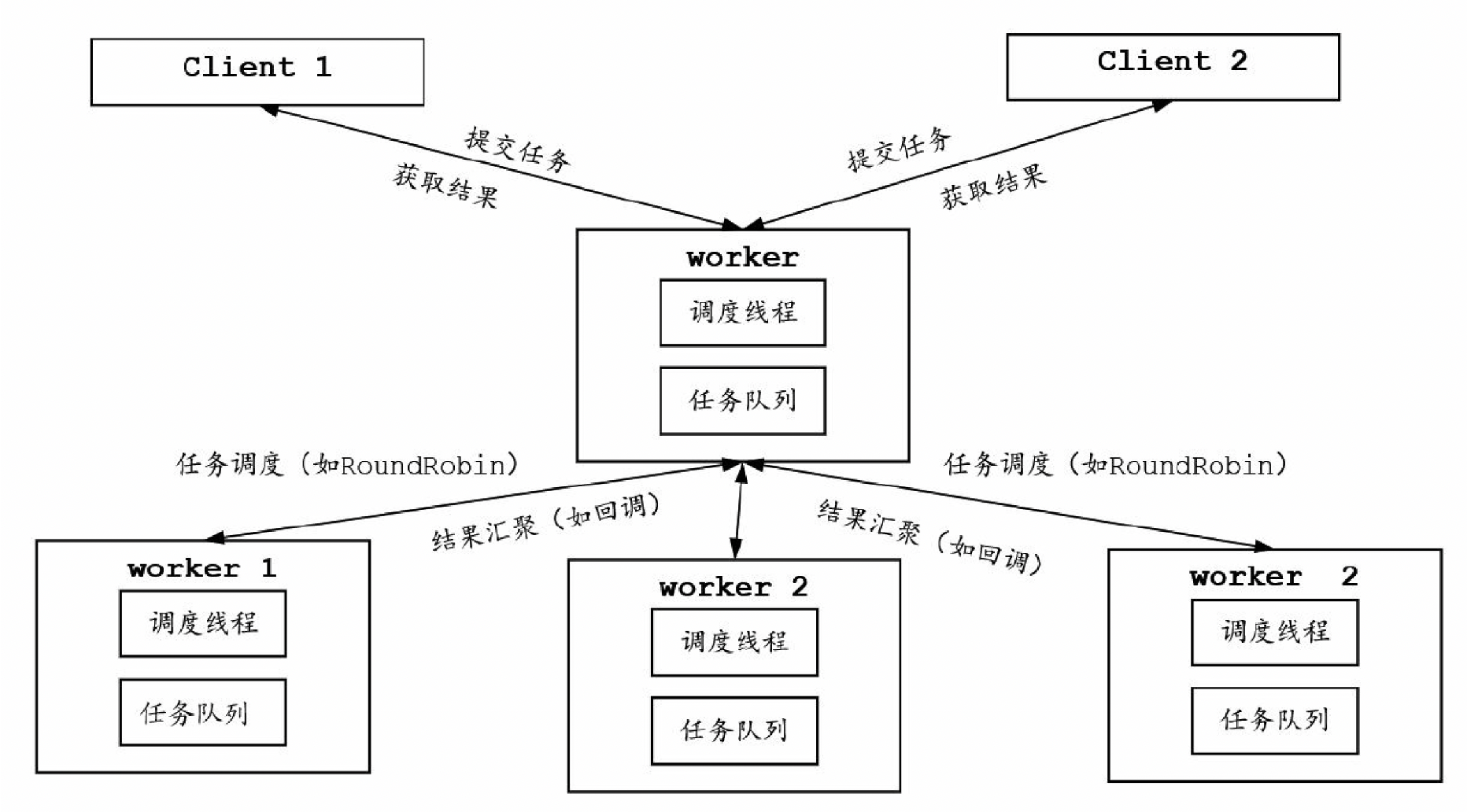
假设一个场景,需要执行N个任务,将这些任务的结果进行累加求和,如果任务太多,就可以采用Master-Worker模式来实现。Master持有workerCount个Worker,并且负责接收任务,然后分发给Worker,最后在回调函数中对Worker的结果进行归并求和。
1.代码实现
/*** @author 二十* @since 2021/9/14 9:52 下午*/public class MasterWorkerTest {static class SimpleTask extends Task<Integer> {@Overrideprotected Integer doExecute() {System.out.println("task " + getId() + " is done !");return getId();}}public static void main(String[] args) {//创建master,包含4个worker,并启动master的执行线程Master<SimpleTask, Integer> master = new Master<>(4);//定期向master提交任务ScheduledExecutorService executorService = Executors.newScheduledThreadPool(10);executorService.scheduleAtFixedRate(() -> master.submit(new SimpleTask()), 2L, 2L, TimeUnit.SECONDS);//定期从master提取结果executorService.scheduleAtFixedRate(() -> master.printResult(), 5, 2, TimeUnit.SECONDS);}}/*** 异步任务类在执行子类任务的doExecute()之后,* 回调一下Master传递过来的回调函数,* 将执行完成后的任务进行回填。** @param <R>*/@Dataclass Task<R> {static AtomicInteger index = new AtomicInteger(1);//任务的回调函数public Consumer<Task<R>> resultAction;//任务的idprivate int id;//worker idprivate int workerId;//计算结果R result = null;public Task() {this.id = index.getAndIncrement();}public void execute() {this.result = this.doExecute();resultAction.accept(this);}//钩子方法,交给子类实现protected R doExecute() {return null;}}/*** Master 负责接收客户端提交额任务,然后通过阻塞队列对任务进行缓存。* Master所拥有的线程作为阻塞队列的消费者,不断从阻塞队列获取任务并轮流分给Worker。** @param <T>* @param <R>*/class Master<T extends Task, R> {//worker集合private Map<String, Worker<T, R>> workers = new HashMap<>();//任务集合protected LinkedBlockingQueue<T> taskQueue = new LinkedBlockingQueue<>();//任务处理结果集合protected Map<String, R> resultMap = new ConcurrentHashMap<>();//Master的任务调度线程private Thread thread = null;//保持最终的和private AtomicLong sum = new AtomicLong(0);public Master(int workerCount) {//每一个worker对象都需要持有队列的引用,用于领取任务和提交结果for (int i = 0; i < workerCount; i++) {Worker<T, R> worker = new Worker<>();workers.put("子节点:" + i, worker);}thread = new Thread(() -> this.execute());thread.start();}//提交任务public void submit(T task) {taskQueue.add(task);}//获取worker结果处理的回调函数private void resultCallback(Object o) {Task<R> task = (Task<R>) o;String taskName = "Worker:" + task.getWorkerId() + "-" + "Task:" + task.getId();R result = task.getResult();resultMap.put(taskName, result);sum.getAndAdd((Integer) result);}//启动所有的子任务public void execute() {for (; ; ) {for (Map.Entry<String, Worker<T, R>> entry : workers.entrySet()) {T task = null;try {//获取任务task = this.taskQueue.take();//获取节点Worker worker = entry.getValue();//分配任务worker.submit(task, this::resultCallback);} catch (Exception e) {e.printStackTrace();}}}}//获取最终结果public void printResult() {System.out.println("sum is : " + sum.get());for (Map.Entry<String, R> entry : resultMap.entrySet())System.out.println(entry.getKey() + " : " + entry.getValue());}}/*** Worker接收Master分配的任务,同样也通过阻塞队列对局部任务进行缓存。* Worker所拥有的的线程作为拒不任务的阻塞队列的消费者,* 不断从阻塞队列获取任务并执行,执行完成后回调Master传递过来的回调函数。** @param <T>* @param <R>*/class Worker<T extends Task, R> {//接受任务的阻塞队列private LinkedBlockingQueue<T> taskQueue = new LinkedBlockingQueue<>();//Worker的编号private static AtomicInteger index = new AtomicInteger(1);private int workerId;//执行任务的线程private Thread thread = null;public Worker() {this.workerId = index.getAndIncrement();thread = new Thread(() -> this.run());thread.start();}//轮训执行任务public void run() {//轮训启动任务for (; ; ) {try {//从阻塞队列提取任务T task = this.taskQueue.take();task.setWorkerId(workerId);task.execute();} catch (Exception e) {e.printStackTrace();}}}//接收任务到异步队列public void submit(T task, Consumer<R> action) {//设置任务的回调方法task.resultAction = action;try {this.taskQueue.put(task);} catch (Exception e) {e.printStackTrace();}}}
2.Netty中Master-Worker模式的实现
Master-Worker模式的核心思想是分而治之,Master角色负责接收和分配任务,Worker角色负责执行任务和结果回填。
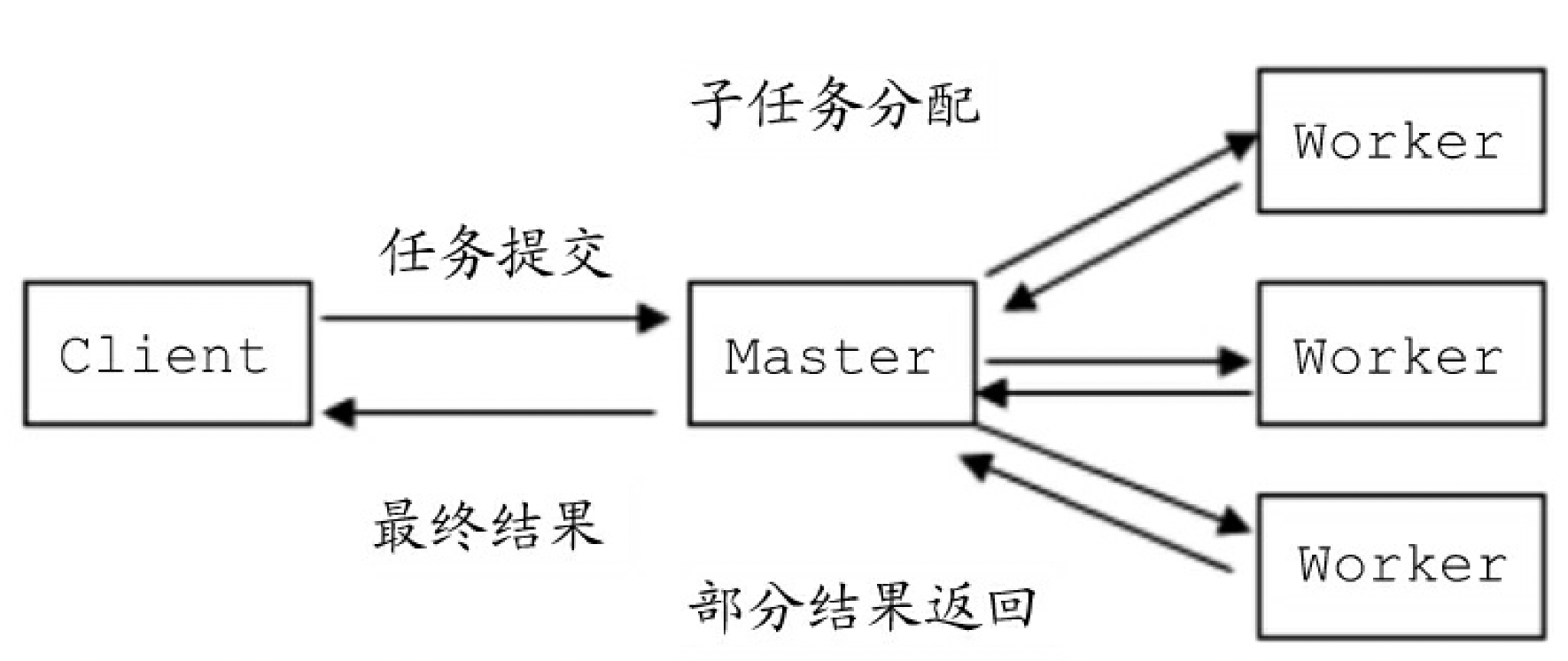
实际上,高性能传输模式Reactor模式就是Master-Worker模式在传输领域的一种应用。基于Java的NIO技术,Nettv设计了一套优秀的、高性能Reactor(反应器)模式的具体实现。在Netty中,EventLoop反应器内部有一个线程负责JavaNIO选择器的事件轮询,然后进行对应的事件分发。事件分发的目标就是Netty的Handler处理程序(含用户定义的业务处理程序)。
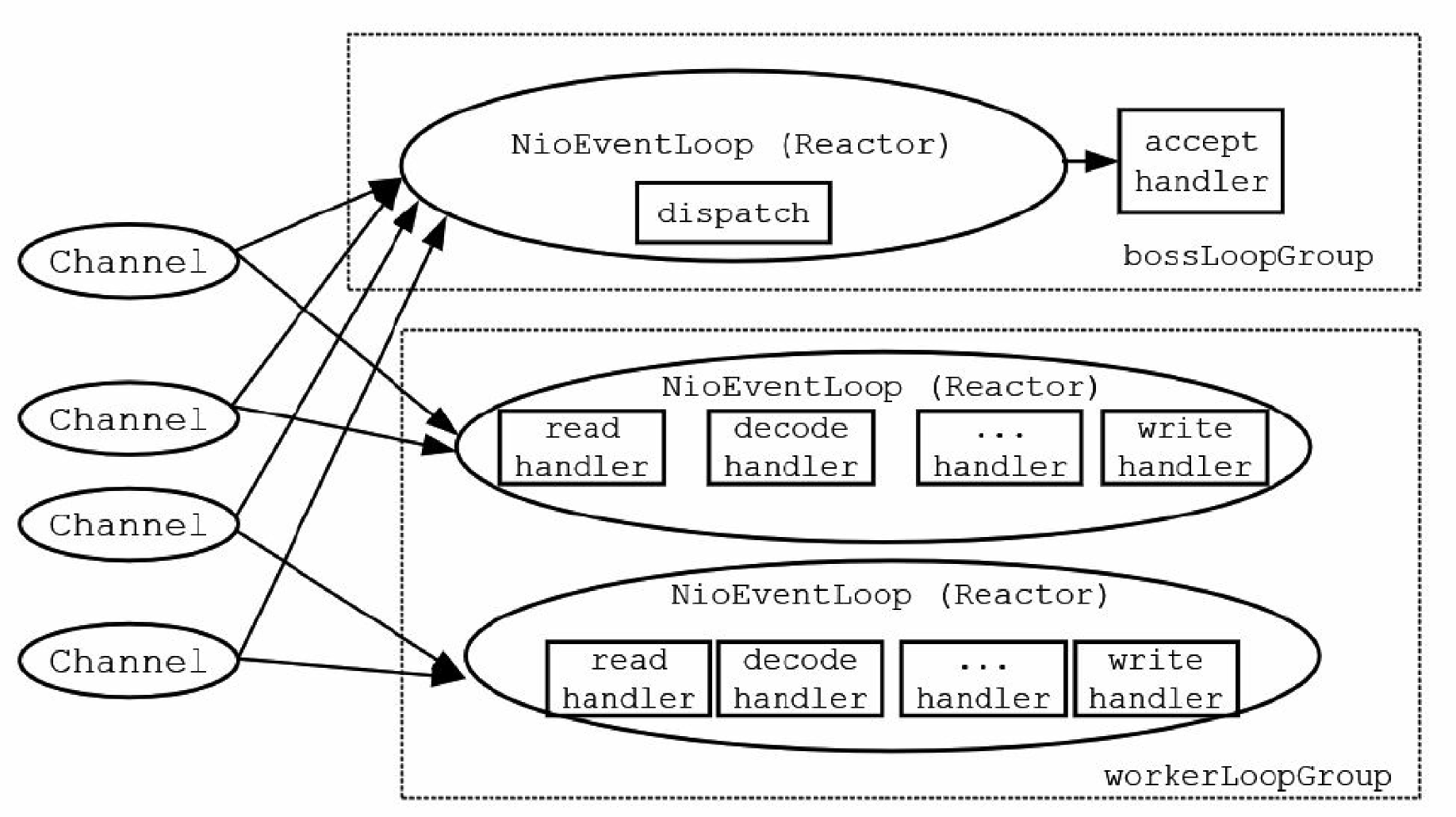
Netty服务器程序中需要设置两个EventLoopGroup轮询组,一个组负责新连接的监听和接收,另一个组负责IO传输事件的轮询与分发,两个轮询组的职责具体如下:
(1)负责新连接的监听和接收的EventLoopGroup轮询组中的反应器完成查询通道的新连接IO事件查询,这些反应器有点像负责招工的包工头,因此该轮询组可以形象地称为“包工头”(Boss)轮询组。
(2)另一个轮询组中的反应器完成查询所有子通道的IO事件,并且执行对应的Handler处理程序完成I0处理,例如数据的输入和输出(有点像搬砖),这个轮询组可以形象地称为“工人”(Worker)轮询组。
Netty是基于Reactor模式的具体实现,体现了Master-Worker模式的思想。Netty的EventLoop(Reactor角色)可以对应到Master-Worker模式的Worker角色,而Netty的EventLoopGroup轮询组则可以对应到Master-Worker模式的Master角色。
3.Nginx中Master-Worker模式的实现
大名鼎鼎的Nginx服务器是Master-Worker模式(更准确地说是Reactor模式)在高性能服务器领域的一种应用。Nginx是一个高性能的 HTTP和反向代理Web服务器,是由伊戈尔·赛索耶夫为俄罗斯访问量第二的Ramblerru站点开发的Web服务器。Nginx源代码以类BSD许可证的形式发布,它的第一个公开版本010发布于2004年10月4日,2011年6月1日发布了1.0.4版本。Nginx因其高稳定性、丰富的功能集、内存消耗少、并发能力强而闻名全球,目前得到非常广泛的使用,比如百度、京东、新浪、网易、腾讯、淘宝等都是它的用户。
Nginx在启动后会以daemon方式在后台运行,它的后台进程有两类:一类称为Master进程(相当于管理进程),另一类称为Worker进程(工作进程)。Nginx的进程结构图如图。
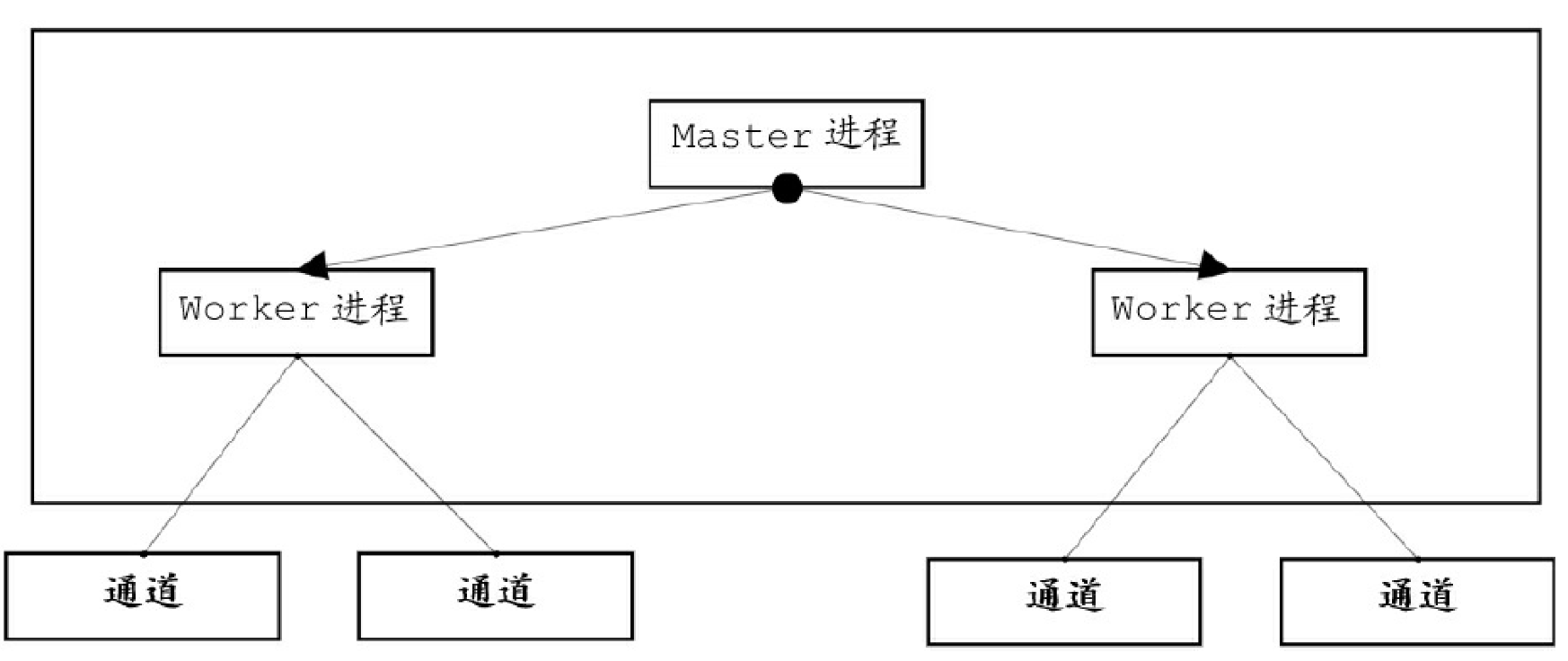
Nginx的Master进程主要负责调度Worker进程,比如加载配置、启动工作进程、接收来自外界的信号、向各Worker进程发送信号、监控 Worker进程的运行状态等。Master进程负责创建监听套接口,交由Worker进程进行连接监听。Worker进程主要用来处理网络事件,当一个 Worker进程在接收一条连接通道之后,就开始读取请求、解析请求、处理请求,处理完成产生的数据后,再返回给客户端,最后断开连接通道。
Nginx的架构非常直观地体现了Master-Worker模式的思想。Nginx的 Master进程可以对应到Master-Worker模式的Master角色,Nginx的 Worker进程可以对应到Master-Worker模式的Worker角色。
三,ForkJoin模式
“分而治之”是一种思想,所谓“分而治之”,就是把一个复杂的算法问题按一定的“分解”方法分为规模较小的若干部分,然后逐个解决,分别找出各部分的解,最后把各部分的解组成整个问题的解。“分而治之”思想在软件体系结构设计、模块化设计、基础算法中得到了非常广泛的应用。许多基础算法都运用了“分而治之”的思想,比如二分查找、快速排序等。
Master-Worker模式是“分而治之”思想的一种应用,ForkJoin模式则是“分而治之”思想的另一种应用。与Master-Worker模式不同,ForkJoin模式没有Master角色,其所有的角色都是Worker,ForkJoin模式中的Worker将大的任务分割成小的任务,一直到任务的规模足够小,可以使用很简单、直接的方式来完成。
1.ForkJoin模式的原理
ForkJoin模式先把一个大任务分解成许多个独立的子任务,然后开启多个线程并行去处理这些子任务。有可能子任务还是很大而需要进一步分解,最终得到足够小的任务。ForkJoin模式的任务分解和执行过程如下:
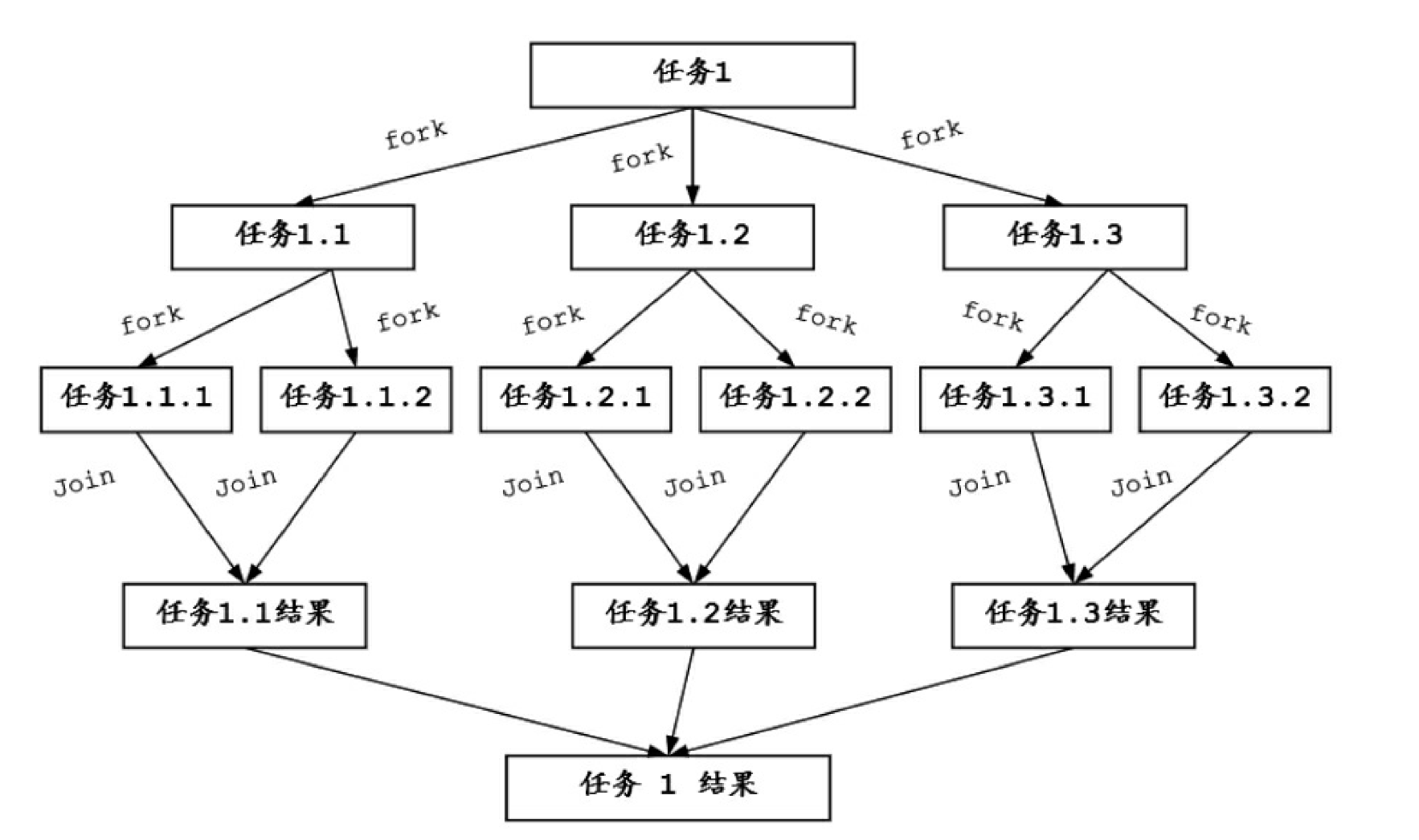
ForkJoin模式借助了现代计算机多核的优势并行处理数据。通常情况下,ForkJoin模式将分解出来的子任务放入双端队列中,然后几个启动线程从双端队列中获取任务并执行。子任务执行的结果放到一个队列中,各个线程从队列中获取数据,然后进行局部结果的合并,得到最终结果。
2.ForkJoin框架
JUC包提供了一套ForkJoin框架的实现,具体以ForkJoinPool线程池的形式提供,并且该线程池在Java8的Lambda并行流框架中充当着底层框架的角色。JUC包的ForkJoin框架包含如下组件:
(1)ForkJoinPool:执行任务的线程池,继承了 AbstractExecutorService类。
(2)ForkJoinWorkerThread:执行任务的工作线程(ForkJoinPool线程池中的线程)。每个线程都维护着一个内部队列,用于存放“内部任务”该类继承了Thread类。
(3)ForkJoinTask:用于ForkJoinPool的任务抽象类,实现了Future接口。
(4)RecursiveTask:带返回结果的递归执行任务,是ForkJoinTask的子类,在子任务带返回结果时使用。
(5)RecursiveAction:不返回结果的递归执行任务,是 ForkJoinTask的子类,在子任务不带返回结果时使用。
因为ForkJoinTask比较复杂,并日其抽象方法比较多,故在日常使用时一般不会直接继承ForkJoinTask来实现自定义的任务类,而是通过继承ForkJoinTask两个子类RecursiveTask或者RecursiveAction之一趋势线自定义任务类,自定义任务类需要实现这些子类的compute(),改方法的执行流程一般如下:
if 任务足够小直接返回结果else分割成N个子任务依次调用每个子任务的fork方法执行子任务依次调用每个子任务的join方法,等待子任务完成,然后合并执行结果
3.ForkJoin框架使用
假设需要计算0-100的累加求和,可以使用ForkJoin框架完成。首先需要设计一个可以递归执行的异步任务子类。
3.1 可递归执行的异步任务类AccumulateTask
public class AccumulateTask extends RecursiveTask<Integer> {private static final int threshold = 2;private int start;private int end;public AccumulateTask(int start, int end) {this.start = start;this.end = end;}@Overrideprotected Integer compute() {int sum = 0;//判断任务的规模:若规模小可以直接计算boolean canCompute = (end - start) <= threshold;//若任务已经足够小,则可以直接计算if (canCompute) {//直接计算并返回结果,Recursive结束for (int i = start; i <= end; i++) sum += i;System.out.println("执行任务,计算:" + start + "到" + end + "的和,结果是: " + sum);} else {//任务过大,需要切割,Recursive 递归计算System.out.println("切割任务:将" + start + "到" + end + "的和一分为二");int mid = (start + end) / 2;//切割成2个子任务AccumulateTask lTask = new AccumulateTask(start, mid);AccumulateTask rTask = new AccumulateTask(mid + 1, end);//依次调用每个子任务的fork方法执行子任务lTask.fork();rTask.fork();//等待子任务完成,依次调用每个子任务的join()合并执行结果int lResult = lTask.join();int rResult = rTask.join();//合并子任务的执行结果sum = lResult + rResult;}return sum;}}
自定义的异步任务子类AccumulateTask继承自RecursiveTask,每一次执行可以携带返回值。AccumulateTask通过THRESHOLD常量设置子任务分解的阈值,并在它的computeO方法中进行阈值判断,判断的逻辑如下:
(1)若当前的计算规模(这里为求和的数字个数)大于THRESHOLD,就当前子任务需要进一步分解,若当前的计算规模没有大于THRESHOLD,则直接计算(这里为求和)。
(2)如果子任务可以直接执行,就进行求和操作,并返回结果。如果任务进行了分解,就需要等待所有的子任务执行完毕、然后对各个分解结果求和。如果一个任务分解为多个子任务(含两个),就依次调用每个子任务的fork方法执行子任务,然后依次调用每个子任务的join方法合并执行结果。
3.2 使用ForkJoinPool调度AccmulateTask()
@Testpublic void testAccumulateTask()throws Exception{ForkJoinPool forkJoinPool = new ForkJoinPool();//创建一个累加任务,计算从1 到 10AccumulateTask countTask = new AccumulateTask(1,100);Future<Integer> future = forkJoinPool.submit(countTask);Integer sum = future.get(1, TimeUnit.SECONDS);System.out.println("最终计算结果是:"+sum);Assert.assertTrue(sum==5050);}
切割任务:将1到100的和一分为二 切割任务:将51到100的和一分为二 切割任务:将1到50的和一分为二 切割任务:将1到25的和一分为二 切割任务:将1到13的和一分为二 切割任务:将1到7的和一分为二 切割任务:将1到4的和一分为二 执行任务,计算:1到2的和,结果是: 3 执行任务,计算:3到4的和,结果是: 7 执行任务,计算:5到7的和,结果是: 18 切割任务:将8到13的和一分为二 执行任务,计算:8到10的和,结果是: 27 执行任务,计算:11到13的和,结果是: 36 切割任务:将26到50的和一分为二 切割任务:将26到38的和一分为二 切割任务:将26到32的和一分为二 切割任务:将26到29的和一分为二 执行任务,计算:26到27的和,结果是: 53 执行任务,计算:28到29的和,结果是: 57 执行任务,计算:30到32的和,结果是: 93 切割任务:将33到38的和一分为二 执行任务,计算:33到35的和,结果是: 102 执行任务,计算:36到38的和,结果是: 111 切割任务:将39到50的和一分为二 切割任务:将39到44的和一分为二 执行任务,计算:39到41的和,结果是: 120 执行任务,计算:42到44的和,结果是: 129 切割任务:将45到50的和一分为二 执行任务,计算:45到47的和,结果是: 138 执行任务,计算:48到50的和,结果是: 147 切割任务:将76到100的和一分为二 切割任务:将76到88的和一分为二 切割任务:将76到82的和一分为二 切割任务:将76到79的和一分为二 执行任务,计算:76到77的和,结果是: 153 执行任务,计算:78到79的和,结果是: 157 执行任务,计算:80到82的和,结果是: 243 切割任务:将83到88的和一分为二 执行任务,计算:83到85的和,结果是: 252 执行任务,计算:86到88的和,结果是: 261 切割任务:将89到100的和一分为二 切割任务:将89到94的和一分为二 执行任务,计算:89到91的和,结果是: 270 执行任务,计算:92到94的和,结果是: 279 切割任务:将95到100的和一分为二 执行任务,计算:95到97的和,结果是: 288 执行任务,计算:98到100的和,结果是: 297 切割任务:将51到75的和一分为二 切割任务:将51到63的和一分为二 切割任务:将51到57的和一分为二 切割任务:将51到54的和一分为二 执行任务,计算:51到52的和,结果是: 103 执行任务,计算:53到54的和,结果是: 107 执行任务,计算:55到57的和,结果是: 168 切割任务:将58到63的和一分为二 执行任务,计算:58到60的和,结果是: 177 执行任务,计算:61到63的和,结果是: 186 切割任务:将64到75的和一分为二 切割任务:将64到69的和一分为二 执行任务,计算:64到66的和,结果是: 195 执行任务,计算:67到69的和,结果是: 204 切割任务:将70到75的和一分为二 执行任务,计算:70到72的和,结果是: 213 执行任务,计算:73到75的和,结果是: 222 切割任务:将14到25的和一分为二 切割任务:将14到19的和一分为二 执行任务,计算:14到16的和,结果是: 45 执行任务,计算:17到19的和,结果是: 54 切割任务:将20到25的和一分为二 执行任务,计算:20到22的和,结果是: 63 执行任务,计算:23到25的和,结果是: 72 最终计算结果是:5050
4.ForkJoin框架的核心API
ForkJoin框架的核心是ForkJoinPool线程池。该线程池使用一个无锁的栈来管理空闲线程,如果一个工作线程暂时取不到可用的任务,则可能被挂起,而挂起的线程将被压入由ForkJoinPool维护的栈中,等到有新的任务到来的时候,再从栈中唤醒这些线程。
4.1 构造器
private ForkJoinPool(int parallelism, //并行度,默认为cpu数,最小为1ForkJoinWorkerThreadFactory factory, //线程创建工厂UncaughtExceptionHandler handler, //异常处理程序int mode,String workerNamePrefix) {this.workerNamePrefix = workerNamePrefix;this.factory = factory;this.ueh = handler;this.config = (parallelism & SMASK) | mode;long np = (long)(-parallelism); // offset ctl countsthis.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);}
(1) parallelism:可并行级别
ForkJoin框架将依据parallelism设定的级别决定框架内并行执行的线程数量。并行的每一个任务都会有一个线程进行处理,但parallelism属性并不是ForkJoin框架中最大的线程数量,该属性和ThreadPoolExecutor线程池中的corePoolSize、maximumPoolSize属性有区别,因为 ForkJoinPool的结构和工作方式与ThreadPoolExecutor完全不一样。
ForkJoin框架中可存在的线程数量和parallelism参数值并不是绝对关联的。
(2)factory:线程创建工厂
当ForkJoin框架创建一个新的线程时,同样会用到线程创建工厂。只不过这个线程工厂不再需要实现ThreadFactorv接口,而是需要实现ForkJoinWorkerThreadFactory接口。后者是一个函数式接口,只需要实现一个名叫newThreadO的方法。在ForkJoin框架中有一个默认的ForkJoinWorkerThreadFactory接口实现 DefaultForkJoinWorkerThreadFactory。
(3)handler:异常捕获处理程序
当执行的任务中出现异常,并从任务中被抛出时,就会被handler捕获。
(4)asyncMode:异步模式
asyncMode参数表示任务是否为异步模式,其默认值为false。如果 asyncMode为true,就表示子任务的执行遵循FIFO(先进先出)顺序,并且子任务不能被合并;如果asyncMode为false,就表示子任务的执行遵循FIFO(后进先!)顺序,并日子任务可以被合并。虽然从字面意思来看asyncMode是指异步模式,它并不是指ForkJoin框架的调度模式采用是同步模式还是异步模式工作,仅仅指任务的调度方式。ForkJoin框架中为每一个独立工作的线程准备了对应的待执行任务队列,这个任务队列是使用数组进行组合的双向队列。asyncMode模式的主要意思指的是待执行任务可以使用FIFO(先进先出)的工作模式,也可以使用 FIFO(后进先出)的工作模式,工作模式为FIFO(先进先出)的任务适用于工作线程只负责运行异步事件,不需要合并结果的异步任务。
ForkJoinPool无参数的,默认的构造器如下:
static final int MAX_CAP = 0x7fff; // max #workers - 1public ForkJoinPool() {this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),defaultForkJoinWorkerThreadFactory, null, false);}
该构造器的parallelism值为CPU核心数,factory值为defaultForkJoinWorkerThreadFactory默认的线程工厂,异常捕获处理程序handler值为null;表示不进行异常处理;异步模式asyncMode值为false,使用LIFO的,可以合并子任务的模式。
4.2 common通用池
很多场景可以直接使用ForkJoinPool定义的common通用池,调用ForkJoinPool.commonPool()可以获取该ForkJoin线程池,该线程池通过makeCommonPool()来构造。
private static ForkJoinPool makeCommonPool() {int parallelism = -1;ForkJoinWorkerThreadFactory factory = null;UncaughtExceptionHandler handler = null;try { //并行度String pp = System.getProperty("java.util.concurrent.ForkJoinPool.common.parallelism");//线程工厂String fp = System.getProperty("java.util.concurrent.ForkJoinPool.common.threadFactory");//异常处理类String hp = System.getProperty("java.util.concurrent.ForkJoinPool.common.exceptionHandler");if (pp != null)parallelism = Integer.parseInt(pp);if (fp != null)factory = ((ForkJoinWorkerThreadFactory)ClassLoader.getSystemClassLoader().loadClass(fp).newInstance());if (hp != null)handler = ((UncaughtExceptionHandler)ClassLoader.getSystemClassLoader().loadClass(hp).newInstance());} catch (Exception ignore) {}if (factory == null) {if (System.getSecurityManager() == null)factory = new DefaultCommonPoolForkJoinWorkerThreadFactory();else // use security-managed defaultfactory = new InnocuousForkJoinWorkerThreadFactory();}//默认并行度为cores-1if (parallelism < 0 && // default 1 less than #cores(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)parallelism = 1;if (parallelism > MAX_CAP)parallelism = MAX_CAP;return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,"ForkJoinPool.commonPool-worker-");}
使用common池子的优点是可以通过指定系统属性的方式定义”并行度,线程工厂和异常处理类“,并且common池使用的是同步模式,也就是说可以支持任务合并。
通过系统属性的方式指定parallellism的值得示例如下:
System.setPropert("java.util.concurrent.ForkJoinPool.common.parallelism","8");
除此之外,还可以通过Java指令的选项的方式指定parallellism值,具体的选项为:
-Djava.util.concurrent.ForkJoinPool.common.parallelism=8
其他的参数值如异常处理程序handler,都可以通过以上两种方式指定。
4.3 向线程池提交任务的方式
可以向ForkJoinPool线程池提交一下两类任务:
- 外部任务(External/Submissions Task)
向ForkJoinPool提交外部任务有三种方式:方式一是调用invoke()方法,该方法提交任务后线程会等待,等到任务计算完毕返回结果;方式二是调用execute方法提交一个任务来异步执行,无返回结果;方式三是调用submit方法提交一个任务,并且会返回一个ForkJoinTask实例,之后适当的时候可通过ForkJoinTask实例获取执行结果。
- 子任务(Worker Task)提交
向ForkJoinPool提交子任务的方法相对比较简单,由任务实例的 fork方法完成。当任务被分割之后,内部会调用ForkJoinPool.WorkQueuepush()方法直接把任务放到内部队列中等待被执行。
5.工作窃取算法
ForkJoinPool线程池的任务分为“外部任务”和“内部任务”,两种任务的存放位置不同:
(1)外部任务存放在ForkJoinPool的全局队列中。
(2)子任务会作为“内部任务”放到内部队列中,ForkJoinPool池中的每个线程都维护着一个内部队列,用于存放这些“内部任务”。
由于ForkJoinPool线程池通常有多个工作线程,与之相对应的就会有多个任务队列,这就会出现任务分配不均衡的问题:有的队列任务多,忙得不停,有的队列没有任务,一直空闲。那么有没有一种机制帮忙将任务从繁忙的线程分摊给空闲的线程呢?答案是使用工作窃取算法。
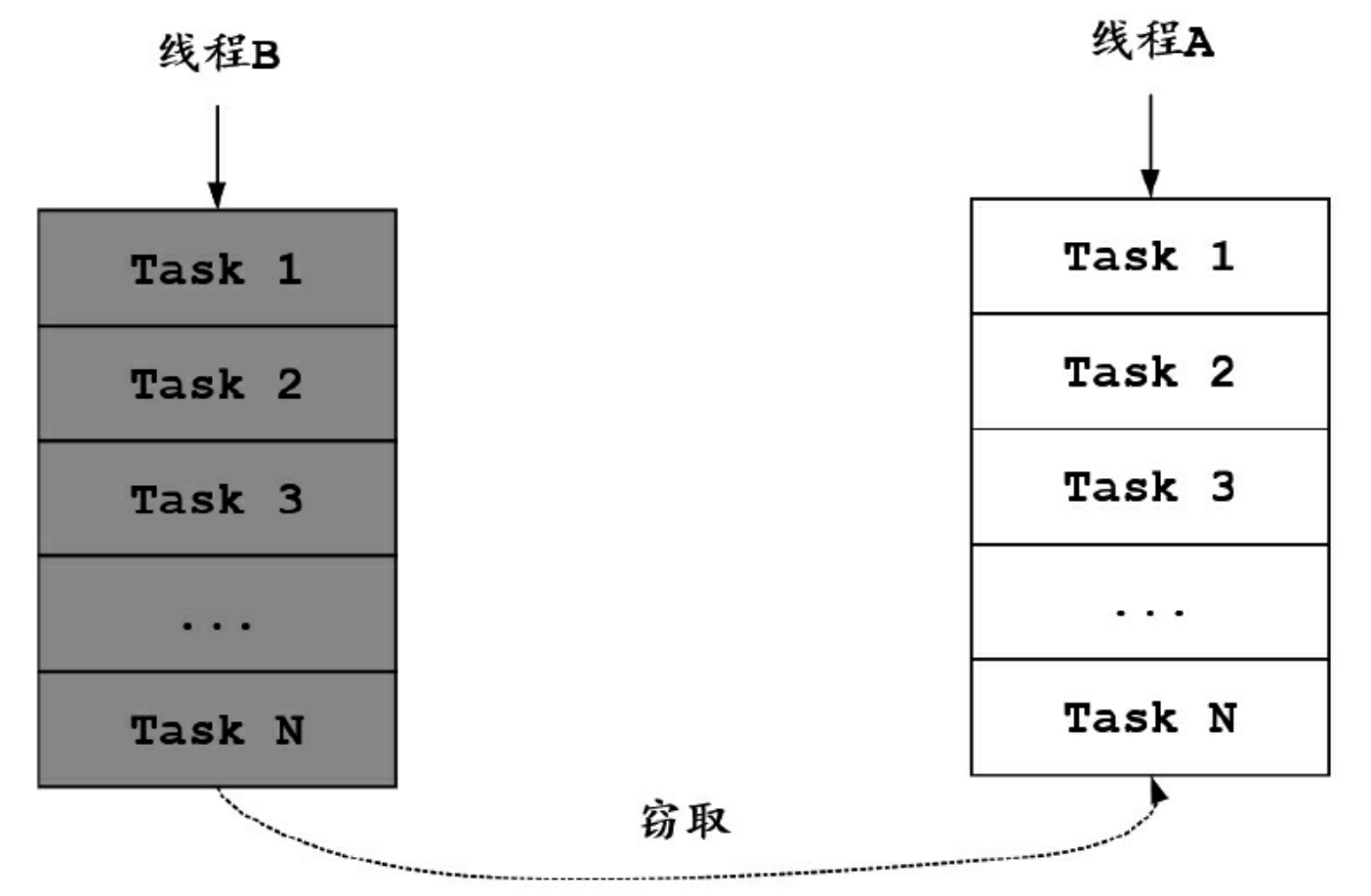
工作窃取算法的核心思想是:工作线程自己的活干完了之后,会去看看别人有没有没干完的活,如果有就拿过来帮忙干。工作窃取算法的主要逻辑:每个线程拥有一个双端队列(本地队列),用于存放需要执行的任务,当自己的队列没有任务时,可以从其他线程的任务队列中获得一个任务继续执行。
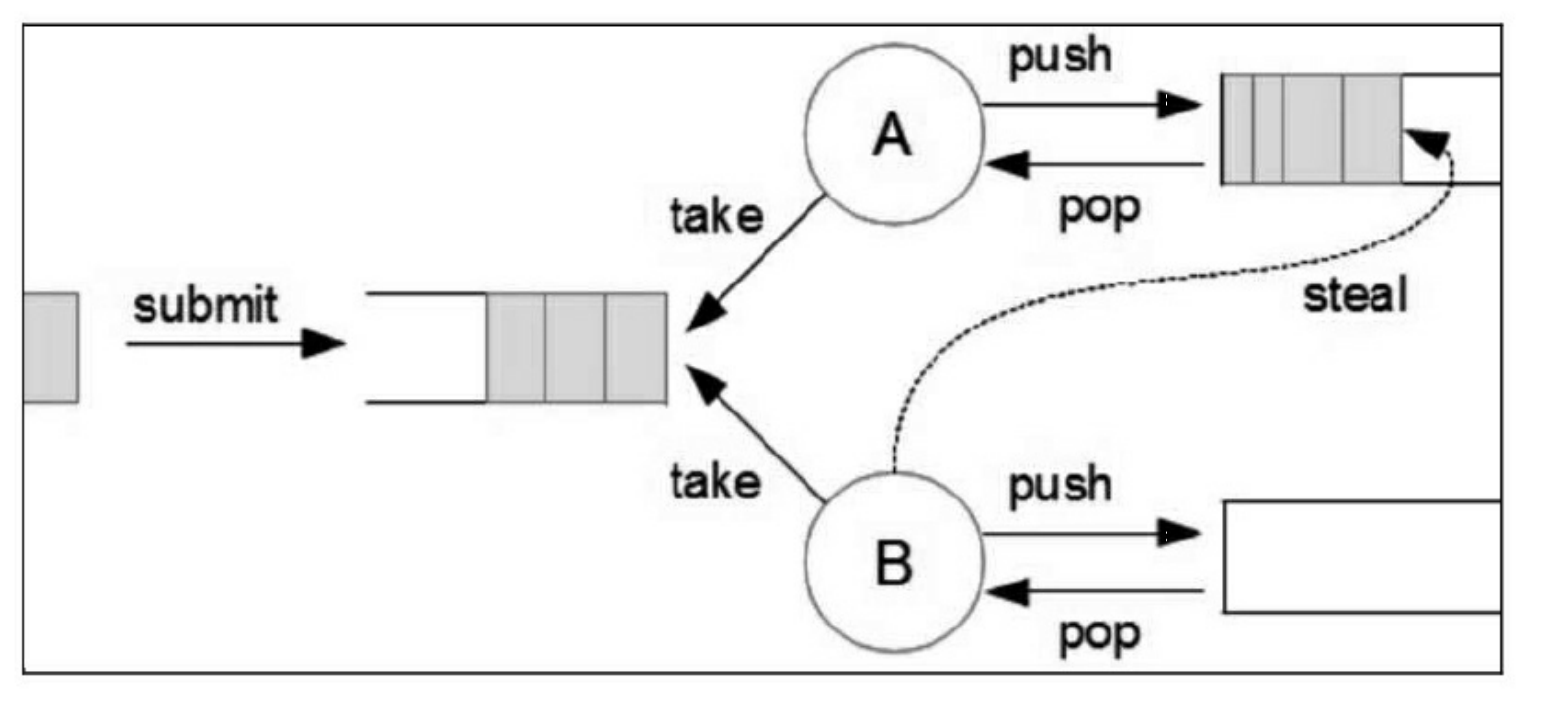
在实际进行任务窃取操作的时候,操作线程会进行其他线程的任务队列的扫描和任务的出队尝试。为什么说是尝试?因为完全有可能操作失败,主要原因是并行执行肯定涉及线程安全的问题,假如在窃取过程中该任务已经开始执行,那么任务的窃取操作就会失败。
如何尽量避免在任务窃取中发生的线程安全问题呢?一种简单的优化方法是:在线程自己的本地队列采取LIFO(后进先出)策略,窃取其他任务队列的任务时采用FIFO(先进先出)策略。简单来说,获取自己队列的任务时从头开始,窃取其他队列的任务时从尾开始。由于窃取的动作十分快速,会大量降低这种冲突,也是一种优化方式。
6.ForkJoin框架的原理
核心原理大致如下:
(1)ForkJoin框架的线程池ForkJoinPool的任务分为“外部任务”和“内部任务”。
(2)“外部任务”放在ForkJoinPool的全局队列中。
(3)ForkJoinPool池中的每个线程都维护着一个任务队列,用于存放“内部任务”,线程切割任务得到的子任务会作为“内部任务”放到内部队列中。
(4)当工作线程想要拿到子任务的计算结果时,先判断子任务有没有完成,如果没有完成,再判断子任务有没有被其他线程“窃取”,如果子任务没有被窃取,就由本线程来完成;一旦子任务被窃取了,就去执行本线程“内部队列”的其他任务,或者扫描其他的任务队列并窃取任务。
(5)当工作线程完成其“内部任务”,处于空闲状态时,就会扫描其他的任务队列窃取任务,尽可能不会阻塞等待。
总之,ForkJoin线程在等待一个任务完成时,要么自己来完成这个任务,要么在其他线程窃取了这个任务的情况下,去执行其他任务,是不会阻塞等待的,从而避免资源浪费,除非所有任务队列都为空。
工作窃取算法的优点:
(1)线程是不会因为等待某个子任务的执行或者没有内部任务要执行而被阻塞等待、挂起的,而是会扫描所有的队列窃取任务,直到所有队列都为空时才会被挂起。
(2)ForkJoin框架为每个线程维护着一个内部任务队列以及一个全局的任务队列,而且任务队列都是双向队列,可从首尾两端来获取任务,极大地减少了竞争的可能性,提高并行的性能。
ForkJoinPool适合需要“分而治之”的场景,特别是分治之后递归调用的函数,例如快速排序、二分搜索、大整数乘法、矩阵乘法、棋盘覆盖、归并排序、线性时间选择、汉诺塔问题等。ForkJoinPool适合调度的任务为CPU密集型任务,如果任务存在I/0操作、线程同步操作、sleep睡眠等较长时间阻塞的情况,最好配合使用ManagedBlocker进行阻塞管理。总体来说,ForkJoinPool不适合进行I0密集型、混合型的任务调度。
四,生产者-消费者模式
生产者-消费者模式是一个经典的多线程设计模式,它为多线程间的协作提供了良好的解决方案,是高并发编程过程中常用的一种设计模式。
在实际的软件开发过程中,经常会碰到如下场景:某些模块负责产生数据,另一些模块负责消费数据(此处的模块可以是类、承数、线程、进程等)。产生数据的模块可以形象地称为生产者,而消费数据的模块可以称为消费者。然而,仅仅抽象出来生产者和消费者还不够,该模式还需要有一个数据缓冲区作为生产者和消费者之间的中介:生产者把数据放入缓冲区,而消费者从缓冲区取出数据。

数据缓冲区的作用主要在于能使生产者和消费者解耦。如果没有数据缓冲区,让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。将来如果消费者的代码发生变化,可能会影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。
生产者-消费者模式天生就是用来处理并发问题的。生产者和消费者是两个独立的并发主体,生产者把制造出来的数据往缓冲区一放,就可以再去生产下一个数据了。生产者基本上不用依赖消费者的处理速度。尤其是在生成者的速度时快时慢时,生产者-消费者模式的好处就体现出来了。当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。等生产者的制造速度慢下来,消费者再慢慢处理掉。
在生产者-消费者模式中,缓冲区是性能的关键,缓冲区可以基于 ArrayList、LinkedList、BlockingQueue、环形队列等各种不同的数据存储组件去设计,所使用的组件不同,生产者-消费者模式实现的性能当然也就不同。
五,Future模式
Future模式是高并发设计与开发过程中常见的设计模式,它的核心思想是异步调用。对于Future模式来说,它不是立即返回我们所需要的数据,但是它会返回一个契约(或异步任务),将来我们可以凭借这个契约(或异步任务)获取需要的结果。
在进行传统的RPC(远程调用)时,同步调用RPC是一段耗时的过程。当客户端发出RPC请求后,服务端完成请求处理需要很长的一段时间才会返回,这个过程中客户端一直在等待,直到数据返回后,再进行其他任务的处理。现有一个Client同步对三个Server分别进行一次RPC调用。
假设一次远程调用的时间为500毫秒,则一个Client同步对三个Server分别进行一次RPC调用的总时间需要耗费1500毫秒。如果要节省这个总时间,可以使用Future模式对其进行改造,将同步的RPC调用改为异步并发的RPC调用,一个Client异步并发对三个Server分别进行一次 RPC调用。
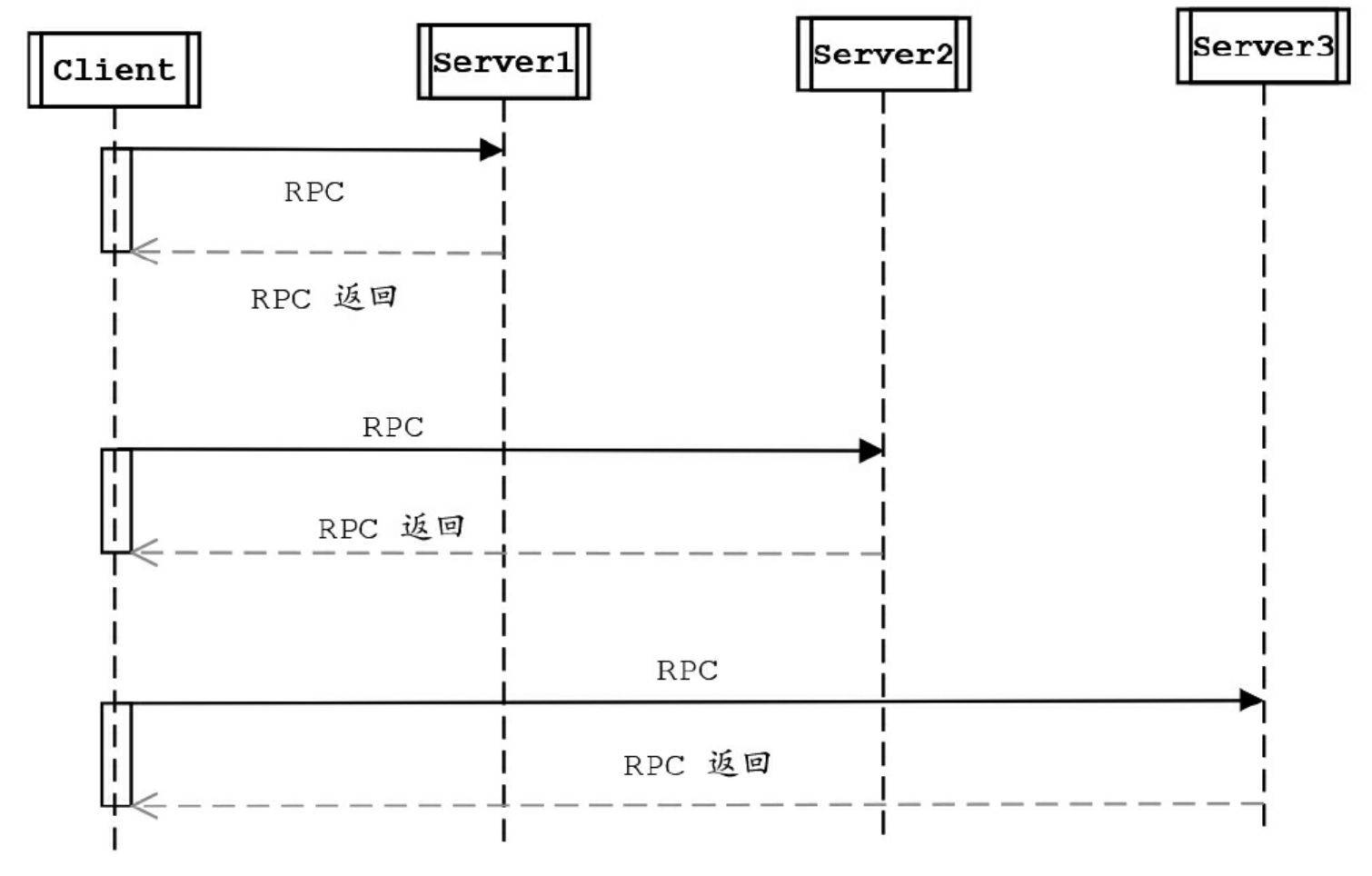
一个Client同步对三个Server分别进行一次RPC调用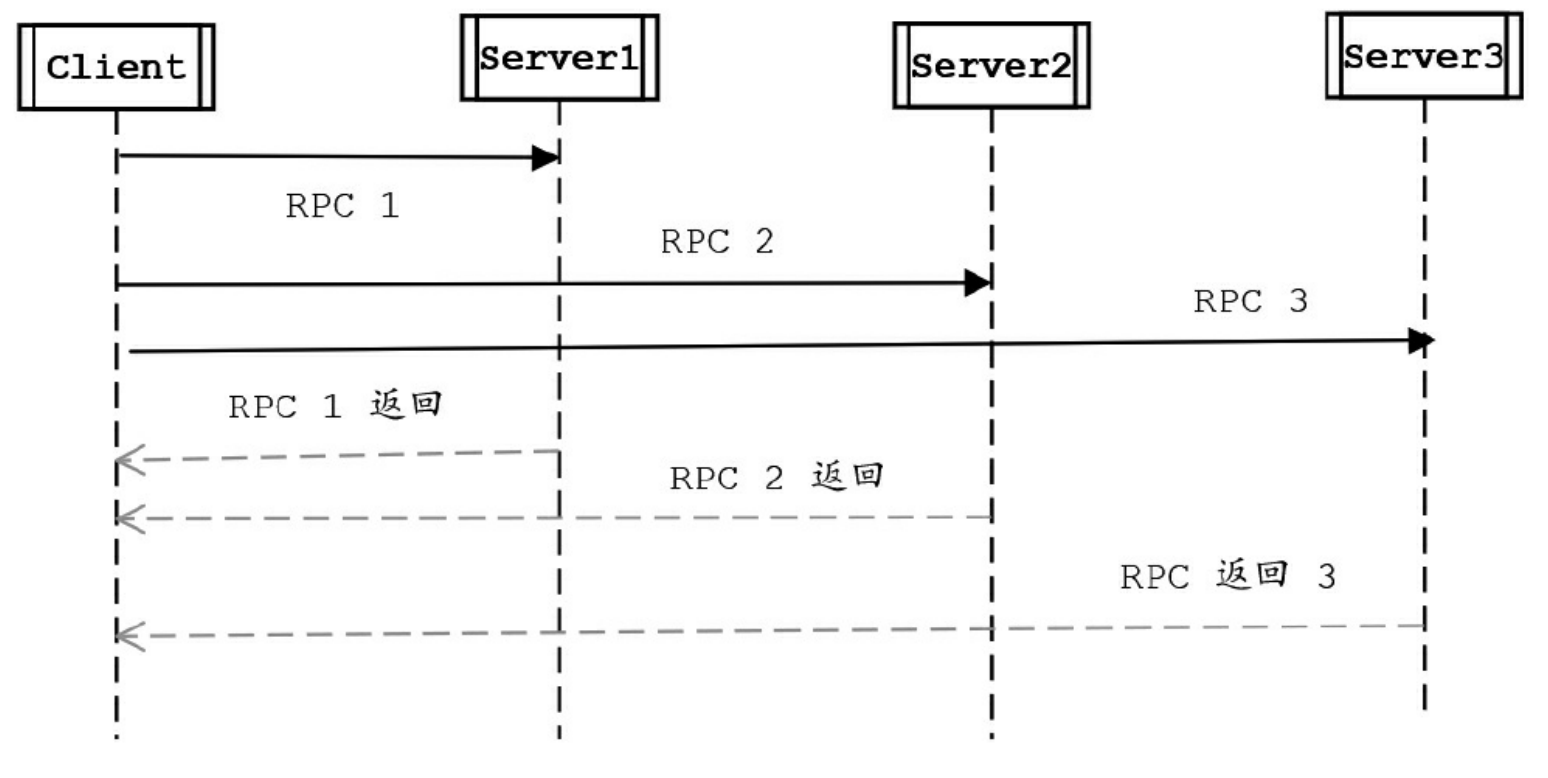
一个Client异步并发对三个Server分别进行一次RPC调用
假设一次远程调用的时间为500毫秒,则一个Client异步并发对三个 Server分别进行一次RPC调用的总时间只要耗费500毫秒。使用Future模式异步并发地进行RPC调用,客户端在得到一个RPC的返回结果前并不急于获取该结果,而是充分利用等待时间去执行其他的耗时操作(如其他RPC调用),这就是Future模式的核心所在。
Future模式的核心思想是异步调用,有点类似于异步的Ajax请求。当调用某个耗时方法时,可以不急于立刻获取结果,而是让被调用者立刻返回一个契约(或异步任务),并且将耗时的方法放到另外的线程中执行,后续凭契约再去获取异步执行的结果。
在具体的实现上,Future模式和异步回调模式既有区别,又有联系。Java的Future实现类并没有支持异步回调,仍然需要主动获取耗时任务的结果;而Java8中的CompletableFuture组件实现了异步回调模式。

若有收获,就点个赞吧
0 人点赞
