最近看了一篇文章,娄杰关于信息抽取(IE)的比赛经验《信息抽取竞赛夺冠经验分享》,故作此摘录总结。
今天跟娄杰微信聊了一下,他现在在北京的 LinkDoc,主要做自然语言处理相关工作。这是他的 Gtihub 开源项目:DeepIE,里面有各种中文信息抽取源代码。项目的主要框架是 PyTorch 和 Transformers,写得很不错,值得借鉴。
这篇文章其实有很多关系抽取的部分,这里为了方便起见,我就只摘录NER的部分。
标注框架
序列标注
每个序列位置都被标注为一个标签,比如按照BILOU(BIOES)标注,我们常用 MLP 或 CRF 解码。
序列标注在面临嵌套实体问题的时候,一般有两种方法:
- 多标签分类:将 token 的多分类转换为多种标签的分类,也就是多个模型,然后使用 sigmoid 设定相关阈值进行解码。这种方法难度较大,也会导致不同种类的 label 直接的依赖关系缺失。比如部位就是部位,症状就是症状,两种标签之间没有信息关联互补的关系。

- 合并标签层:解码方式采用 CRF ,但是设置多个标签层。对于每一个 token 给出所有的 label,然后对标签层合并。这种方式指数级增加了标签,对于多层嵌套,稀疏问题较为棘手。对简单问题还行,复杂嵌套不建议使用。

指针标注
对每个 span 的 start 和 end 进行标记,对于多片段抽取问题转化为 N 个2分类( N 为序列长度),如果涉及多类别可以转化为层叠式指针标注(C 个指针网络,C 为类别总数)。指针标注已经成为统一实体、关系、事件抽取的一个“大杀器”。
- 层叠式指针标注:设置 C 个指针网络,如下图所示。症状一个,部位一个。

- MRC-QA + 指针标注:构建 query 问题指代所要抽取的实体类型,同时也引入了先验语义知识,如下图所示。在文献中就对不同实体类型构建query,并采取指针标注,此外也构建了
 矩阵来判断 span 是否构成一个实体。
矩阵来判断 span 是否构成一个实体。

多头标注
娄杰说这是他自己叫的名字,实际上也是构建一个矩阵。和 TPlinker 那篇文章的标记方法用的是同类型的。
- 构建 Span 矩阵:如下图所示,
 ,代表「呼吸中枢」是一个部位实体;
,代表「呼吸中枢」是一个部位实体; ,代表「呼吸中枢受累」是一个症状实体;对于多头标注的一个重点就是如何构造 Span 矩阵、以及解决 0-1 标签稀疏问题。
,代表「呼吸中枢受累」是一个症状实体;对于多头标注的一个重点就是如何构造 Span 矩阵、以及解决 0-1 标签稀疏问题。

- 参考文章:嵌套实体的2篇SOTA之作
- ACL20的《Named Entity Recognition as Dependency Parsing》采取 Biaffine 机制构造 Span 矩阵;
- EMNLP20的 HIT(HIT: Nested Named Entity Recognition via Head-Tail Pair and Token Interaction)则通过Biaffine机制专门捕获边界信息,并采取传统的序列标注任务强化嵌套结构的内部信息交互,同时采取 focal loss 来解决0-1标签不平衡问题。
片段排列
简单粗暴的方法,对于总共有  个 token 的文本,理论上共有
个 token 的文本,理论上共有  种片段排列。如果文本太长,那么负样本也太多,实际中应该对 span 长度加以限制。
种片段排列。如果文本太长,那么负样本也太多,实际中应该对 span 长度加以限制。
简单对比
作者对四种常见策略进行了对比,多头标注的效果最佳。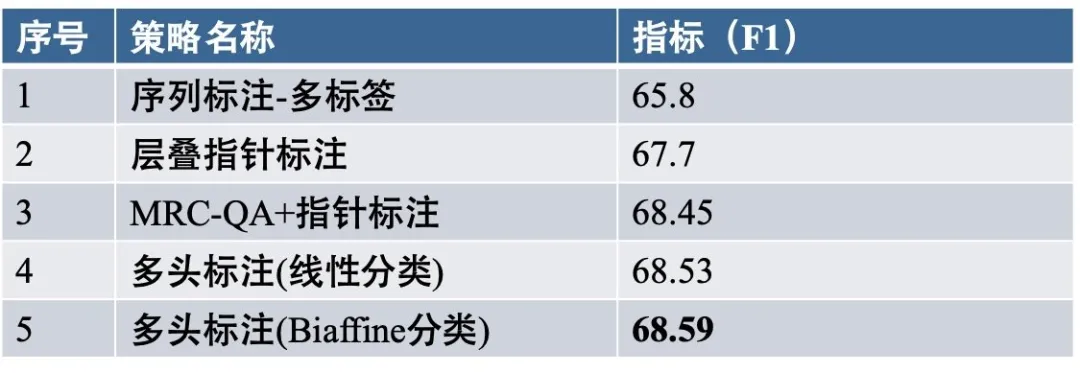
Baseline选择
作者在对比多种方法之后,认为 融合BERT与多头选择 机制是比较好的方法,说白了就是TPLinke用的r那一套标注方法的后半截。
每个三元组的实体 pair ,只选择当前实体 span 的最后一个字符进行关系预测。
- 多头选择机制的关键是在于如何更好地构造关系分类矩阵;
- BERT等预训练语言模型,如何更好地适配于多头选择机制。
词汇增强
由于这里只提NER相关任务,所以可以考虑做一些词汇增强。
词汇增强:即引入词汇信息,并适配于所对应的标注策略;这种词汇增强的方式常见于NER问题中,具体可参见娄杰之前的推文《JayLou娄杰:中文NER的正确打开方式: 词汇增强方法总结 (从Lattice LSTM到FLAT)》。这种方式的关键在于如何引入具体的知识库信息(实体信息)。
实体标准化
不仅是在医疗,在我们当前的裁判文书等当事人抽取领域,一样会存在实体标准化的问题,所以有一定的参考价值。
实体的标准化,这与实体链接较为类似,本质上是一个rank排序问题。
原文采用了医疗行业举例:
在医疗电子病历中,关于同一种诊断、手术、药品、检查、化验、症状等往往会有成百上千种不同的写法。在chip20评测中,医疗术语标准化就是针对「诊断」术语的标准化, 如下图所示,需要将「诊断原词」对应到「诊断标准词」,而诊断标准词来源于医疗专业知识库ICD-10.
第一步:多路召回
- 标准词查询:将当前查询的诊断原词,通过与ICD-10标准词库(可以理解为我们的企业、产品、行业标准词库之类的)进行TF-IDF相似度计算;
- 历史查询:将当前查询的诊断原词,通过与训练集的诊断原词进⾏TF-IDF相似度计算,返回诊断原词所对应的标准词(已标注);
- 硬匹配查询:如果标准词存在于当前查询的诊断原词中,那么返回这个标准词;
通过对比不同相似度计算(如下图),最终选取TF-IDF,召回 TOP100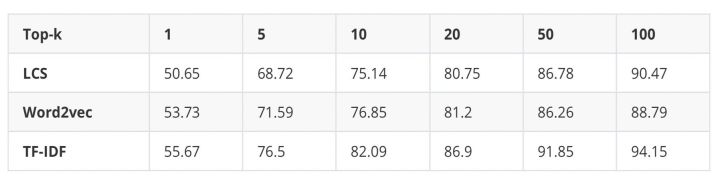
第二步:rank匹配计算
采取常见的文本匹配计算,基于BERT,拼接「诊断原词+候选标准词」(备注:考虑原生segment_id),增加两个pooling层,进行0-1分类。
对于rank匹配最重要的一步就是负样本构造,JayJay采取以下方式进行:
- 与召回方式类似,通过TF-IDF进行相似度计算,选取TOP20;
- 增加hard negative sample数量 ,诊断原词与标准词库直接进行相似度计算;
-
第三步:个数预测
为了解决对应关系存在“一对多”的问题,很简单的一种方式就是:基于BERT,对「诊断原词」对应的标准词数⽬进⾏构建多分类模型,共设置为3个类别:0-1个;1-2个;2-大于2个;
基于以上三步,最终解码分两种情况进行: 个数预测<=2:直接返回top-k;
- 个数预测>2: 按照得分排序,选择阈值>0.5的标准词;
在最终的排名中,比第2名高了近3.7%: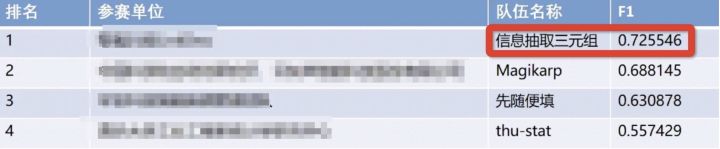

若有收获,就点个赞吧
0 人点赞
