下载解压
下载地址在这,当前版本3.4.7,下载完后解压即可。
$ unzip apache-tinkerpop-gremlin-console-3.4.7-bin.zip$ cd apache-tinkerpop-gremlin-console-3.4.7$ bin/gremlin.sh\,,,/(o o)-----oOOo-(3)-oOOo-----plugin activated: tinkerpop.serverplugin activated: tinkerpop.utilitiesplugin activated: tinkerpop.tinkergraphgremlin>
控制台
现在我们进入了gremlin的控制台,我们从一个简单的“Modern”图开始。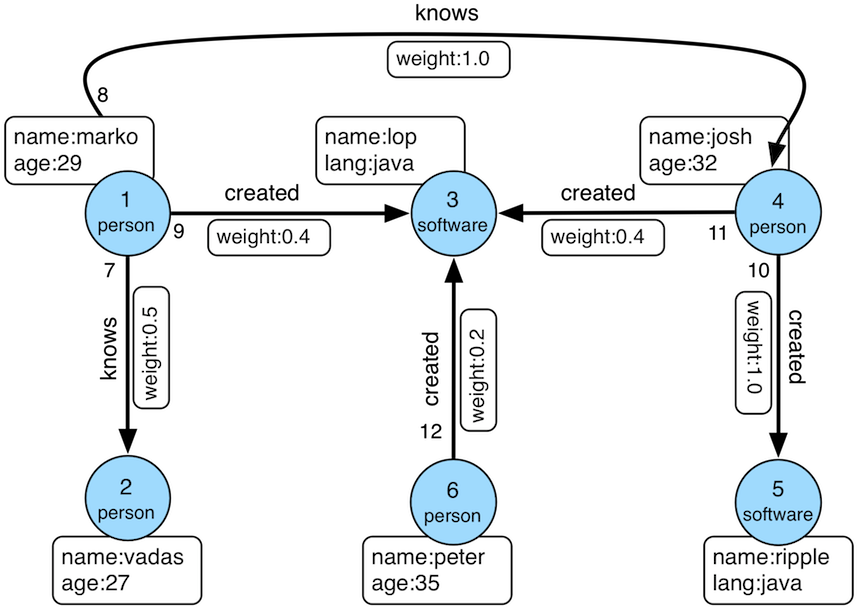
gremlin> graph = TinkerFactory.createModern()==>tinkergraph[vertices:6 edges:6]gremlin> g = graph.traversal()==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
第一个命令创建了一个名叫 graph 的 Graph 实例。而 TraversalSource 向 Gremlin 提供其他信息(例如要应用的遍历策略和要使用的遍历引擎)。
Gremlin支持各种连接,比如JAVA、Python等,这里不重要。
有了 TraversalSource 后,现在我们要求 Gremlin 遍历这个图:
gremlin> g.V() // 获取图中所有的节点==>v[1]==>v[2]==>v[3]==>v[4]==>v[5]==>v[6]
gremlin> g.V(1) // 获取id为1的节点==>v[1]
gremlin> g.V(1).values('name') // 获取id为1的节点的name属性==>marko
gremlin> g.V(1).outE('knows') // 获取 id 为1的节点的 label 为 "knows" 的边==>e[7][1-knows->2]==>e[8][1-knows->4]
gremlin> g.V(1).outE('knows').inV().values('name') // 获取节点1 'knows' 的节点的 'name'==>vadas==>josh
注意, outE().inV() 可以缩写为 out() ,如下:
gremlin> g.V(1).out('knows').values('name') // 上面一句的缩写==>vadas==>josh
gremlin> g.V(1).out('knows').has('age', gt(30)).values('name') // gt() 是大于的意思,这里大于30岁==>josh
注意,“遍历”的本质是一个迭代器。所以在控制台之外编写 Gremlin 的时候,需要将返回值手动遍历。这和控制台本身不太一样,控制台是自动进行了遍历的。
基本概念操作
图
我们大概了解了遍历图的一些基本知识。这里再简单说一下,图就是“顶点”和“边”的集合,其中顶点表示某个领域对象的实体,比如“人”或者“地点”。而边表示两个顶点之间的关系。
上图中有两个顶点,左边的唯一ID是1,右边的唯一ID是3,有一条唯一ID是9的边连接着。注意,需要考虑边的方向,该方向从 1 到 3。
标签
为了让结构更加明白,我们分别为节点和边指定“标签”(labels)。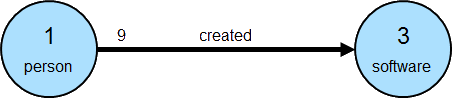
我们可以看到,顶点1的标签是“Person”,而顶点3的标签是Software”。而他们由“Create”这条边连接起来。
其中,标签和id是保留属性,你也可以往里面增加更多的属性:
新建一个图
以上面讨论的两个顶点一条边的图为例子,我们来创建这么一个图。
初始化图
gremlin> graph = TinkerGraph.open()==>tinkergraph[vertices:0 edges:0]
gremlin> g = graph.traversal()==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
新增顶点1
gremlin> v1 = g.addV("person").property(id, 1).property("name", "marko").property("age", 29).next()==>v[1]
新增顶点2
gremlin> v2 = g.addV("software").property(id, 3).property("name", "lop").property("lang", "java").next()==>v[3]
新增边9
gremlin> g.addE("created").from(v1).to(v2).property(id, 9).property("weight", 0.4)==>e[9][1-created->3]
图遍历
既然Gremlin知道图数据在哪里,那么我们就可以要求它用遍历的方法获取一些数据。比如,我们用英语提出一些问题,然后将其翻译为 Gremlin。比如上面的例子,我们就可以问:“What software has Marko created?”
一般来说,要回答这个问题,我们希望 Gremlin 要:
- 在图中找到 Marko;
- 沿着“Created”边走到“Software”顶点;
- 选择该“Software”顶点的“Name”属性。
这种基于英语的步骤很大程度上可以转化为我们需要 Gremlin 采取的步骤。让我们从查找“Marko”开始。此操作是筛选步骤,因为它会搜索整个顶点集以匹配具有“Marko”的“name”属性值的顶点。可以使用 has() 步骤完成此操作,如下所示:
gremlin> g.V().has('name','marko')==>v[1]
通过将顶点标签作为过滤器的一部分来确保“name”属性键引用“person”顶点,可以如下改进 Gremlin:
gremlin> g.V().has('person','name','marko')==>v[1]
⚠️重要 上面的查询迭代了图中的所有顶点以获取其答案。对于我们的小示例来说很好,但是对于数百万或十亿个边缘的图来说,这是个大问题。要解决此问题,您应该使用“索引”。 TinkerPop不提供索引管理的抽象。您应该查阅所选 graph 的文档,并利用其本机API创建索引,从而加快这些类型的查找。

现在,Gremlin 找到了 Marko,我们需要他继续沿着“Created”边走到“Software”顶点。注意,边是有方向的,所以我们需要告诉 Gremlin 需要遵循哪个方向。比如现在,我们希望他从 Marko 移出,所以这里使用 outE :
gremlin> g.V().has('person','name','marko').outE('created')==>e[9][1-created->3]

要到达边缘另一端的顶点,我们需要使用 inV() 告诉 Gremlin 从边缘移到传入的顶点:
gremlin> g.V().has('person','name','marko').out('created')==>v[3]

由于我们没有要求 Gremlin 对“Created”边的属性做任何事情,因此可以使用以下方法简化上面的语句:
gremlin> g.V().has('person','name','marko').out('created')==>v[3]
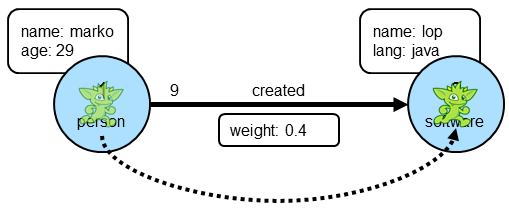
终于,Gremlin 到达了 Marko 创建的“Software”,他就可以访问“Software”顶点的属性,因此我们可以要求 Gremlin 提取“ name”属性的值,如下所示:
gremlin> g.V().has('person','name','marko').out('created').values('name')==>lop
现在我们应该基本明白 Gremlin 与图结构之间的联系,以及他是怎么从顶点走到边的。我们后面对此做的复杂操作都是基于对这些概念的理解的。
进一步操作
更复杂的图遍历
借助上一节的基本概念,我们现在要让 Gremlin 做一些更复杂的任务。现在我们回到之前的“Modern”图:
gremlin> graph = TinkerFactory.createModern()==>tinkergraph[vertices:6 edges:6]gremlin> g = graph.traversal()==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
之前,我们使用 has() 告诉 Gremlin 如何找到“marko”顶点。 让我们看看其他使用 has() 的方式。 如果我们希望 Gremlin 同时找到“vadas”和“marko”的“age”值,该怎么办? 在这种情况下,我们可以将内部比较器(within comparator)与 has() 一起使用,如下所示:
gremlin> g.V().has('person','name',within('vadas','marko')).values('age')==>29==>27
进一步,比如我们想知道他们的平均年龄,我们可以使用 mean() ,如下所示:
gremlin> g.V().has('person','name',within('vadas','marko')).values('age').mean()==>28.0
使用 where 可以看到另一种过滤方法。我们知道怎么找到“Marko”创造的“Software”:
gremlin> g.V().has('person','name','marko').out('created')==>v[3]
现在我们扩展这个查询,了解一下当“Marko”创建软件时,他在和谁合作。换句话说,我们现在要回答这样一个问题:“Who are the people that marko develops software with?”为此,我们为 Gremlin 描绘这么一个图,他站在“Software”顶点上。而为了找出是谁创建了这个软件,我们需要让他沿着“Created”边向后移动,然后找到相关人的顶点。
gremlin> g.V().has('person','name','marko').out('created').in('created').values('name')==>marko==>josh==>peter
很好,现在我们可以看见“peter”、“josh”和“marko”都参与创建了“v[3]”,也就是名为“lop”的“Software”顶点。当然我们知道“marko”已经参与了这个项目,所以我们在答案里面应该排除“marko”,如下:
gremlin> g.V().has('person','name','marko').as('exclude').out('created').in('created').where(neq('exclude')).values('name')==>josh==>peter
我们对遍历进行了两次添加,用以排除“marko”这个结果。具体说来,我们添加了 as() 步骤。在这里,我们用 as(exclude) 来标记 has() 步骤的结果,以备后用。在此,“marko”是唯一通过该点的顶点,所以这里它的值就保留在了“exclude”中。
另外一个步骤是 where() 步骤,这是一个类似于 has() 的过滤步骤。 where() 步骤位于存放“person”顶点的 in() 步骤之后,这意味着 where() 过滤器作用于“marko”协作者列表上。 where() 指定通过它的“Person”顶点不等于( neq() )“exclude”标签的内容。因为“exclude”仅包含“ marko”顶点,所以where() 过滤掉了我们在“Created”边上向后移动时得到的“marko”。
as 和 select 经常联用:
gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b','c')==>[a:v[1],b:v[4],c:v[5]]==>[a:v[1],b:v[4],c:v[3]]

若有收获,就点个赞吧
0 人点赞
