写操作事务:什么是 writeConcern ?
writeConcern决定一个写操作落到多少个节点上才算成功。writeConcern的取值包括:
- 0: 发起写操作,不关心是否成功;
- 1 ~ 集群最大数据节点数:写操作需要被复制到指定节点数才算成功;
- majority:写操作需要被复制到大多数节点上才算成功。
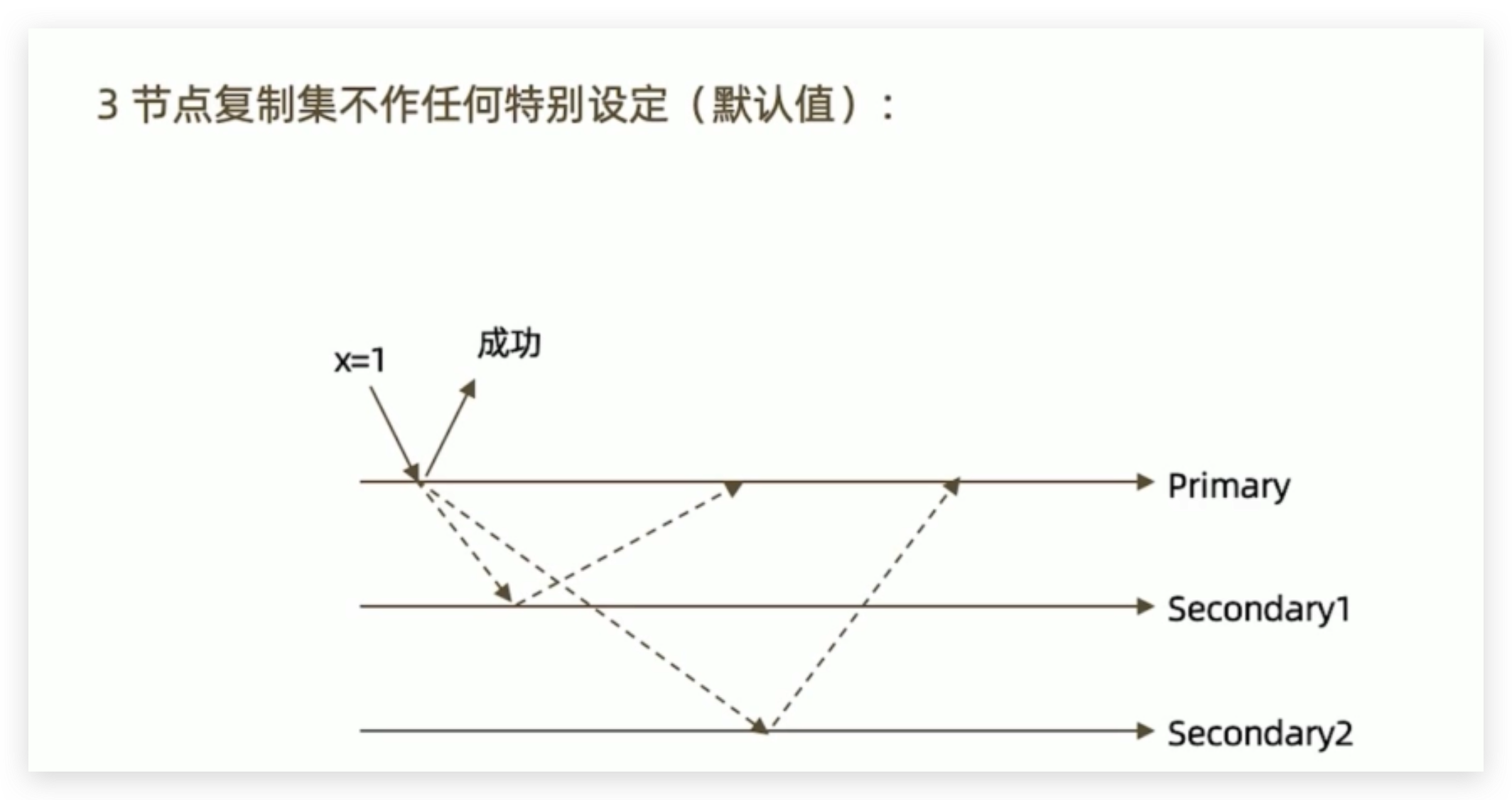
默认行为
x = 1写到primary内存中就响应成功,并没有写进盘里面
- 有可能写到这secondary1和secondary2中间失败了,就会丢失数据,(数据会保存到一个备份文件中)
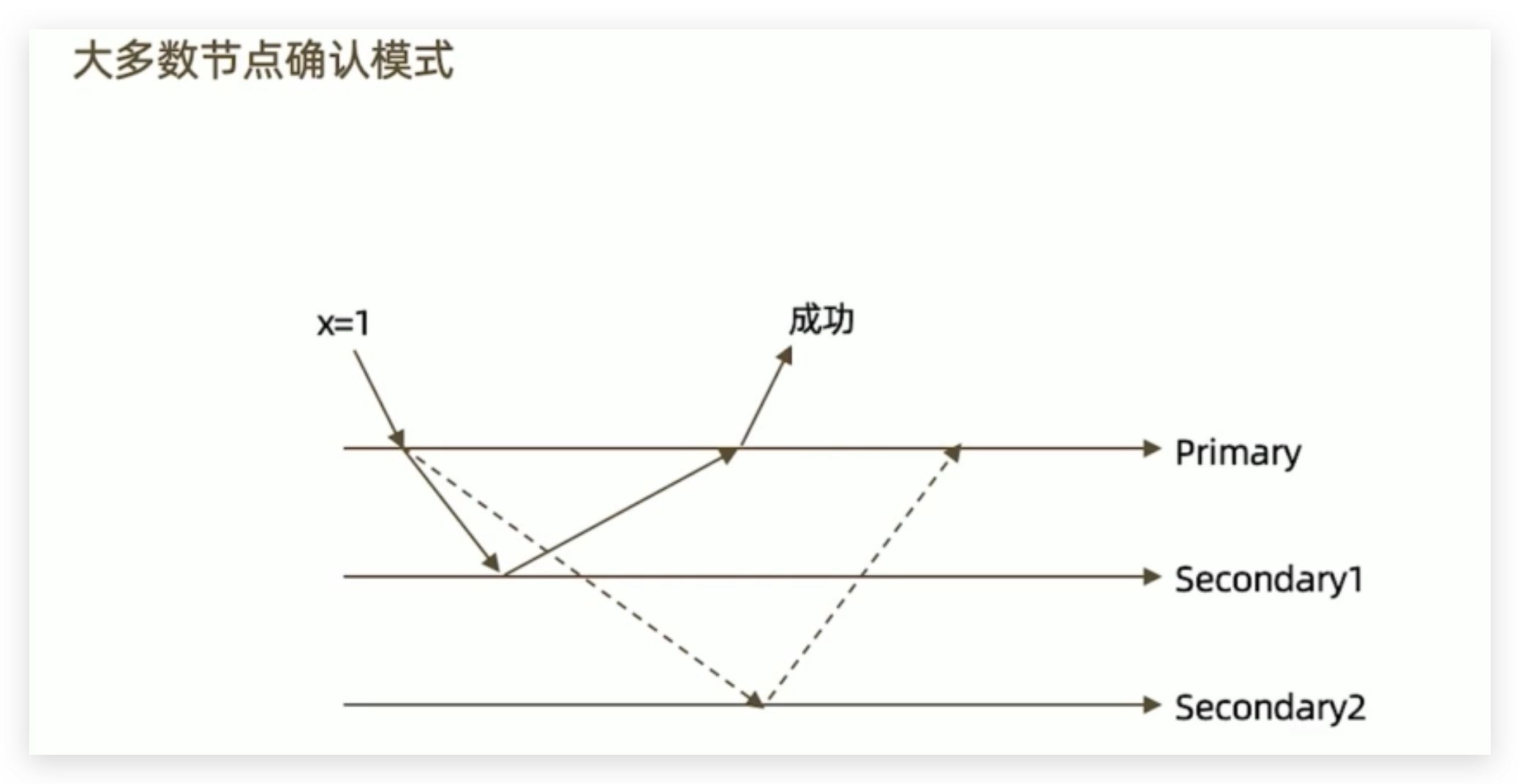
w: “majority”(推荐参数)
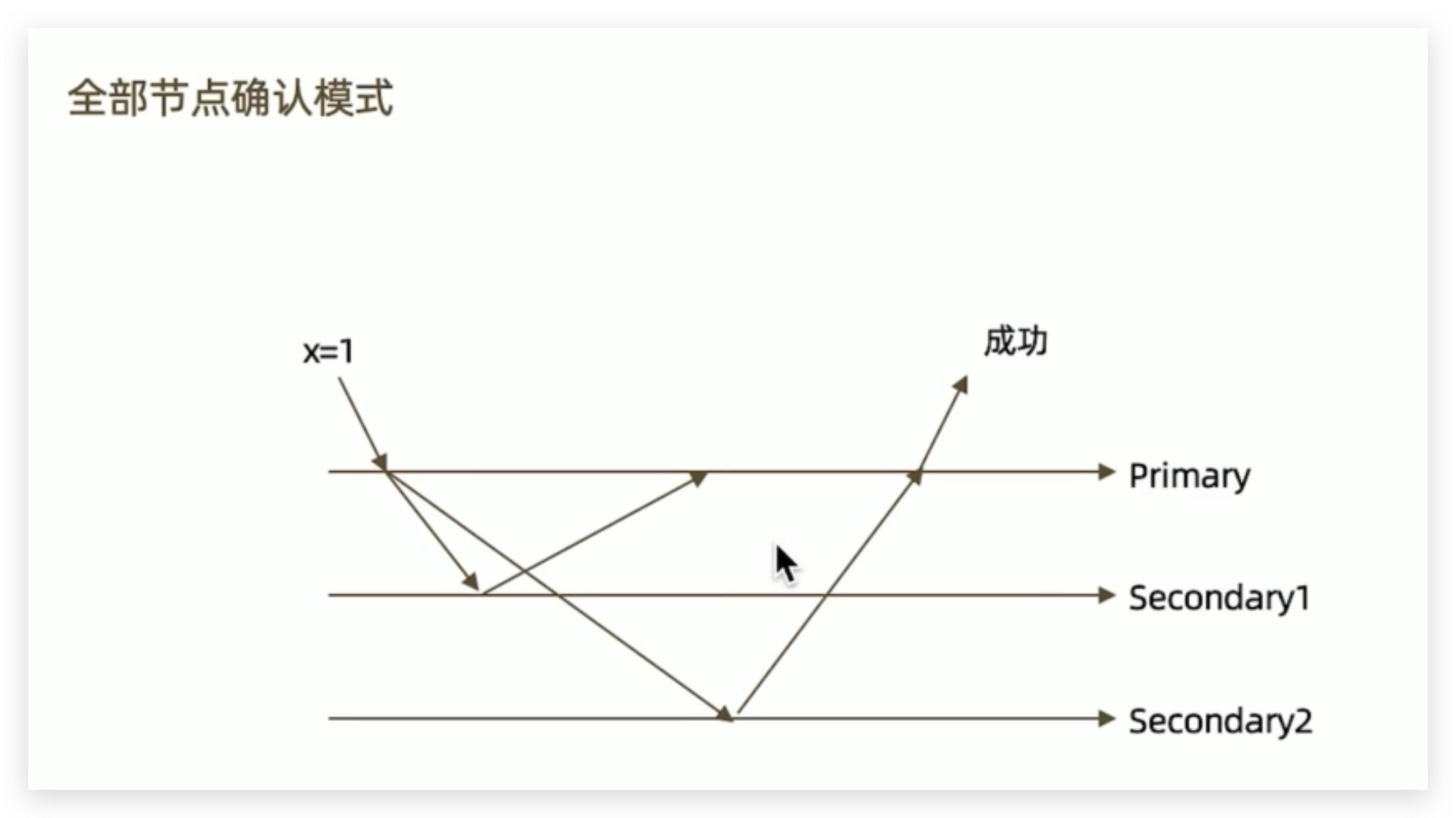
w: “all”
- 全部节点写操作完成之后再返回成功,但是缺点是如果有其中一个节点宕机,就会失败
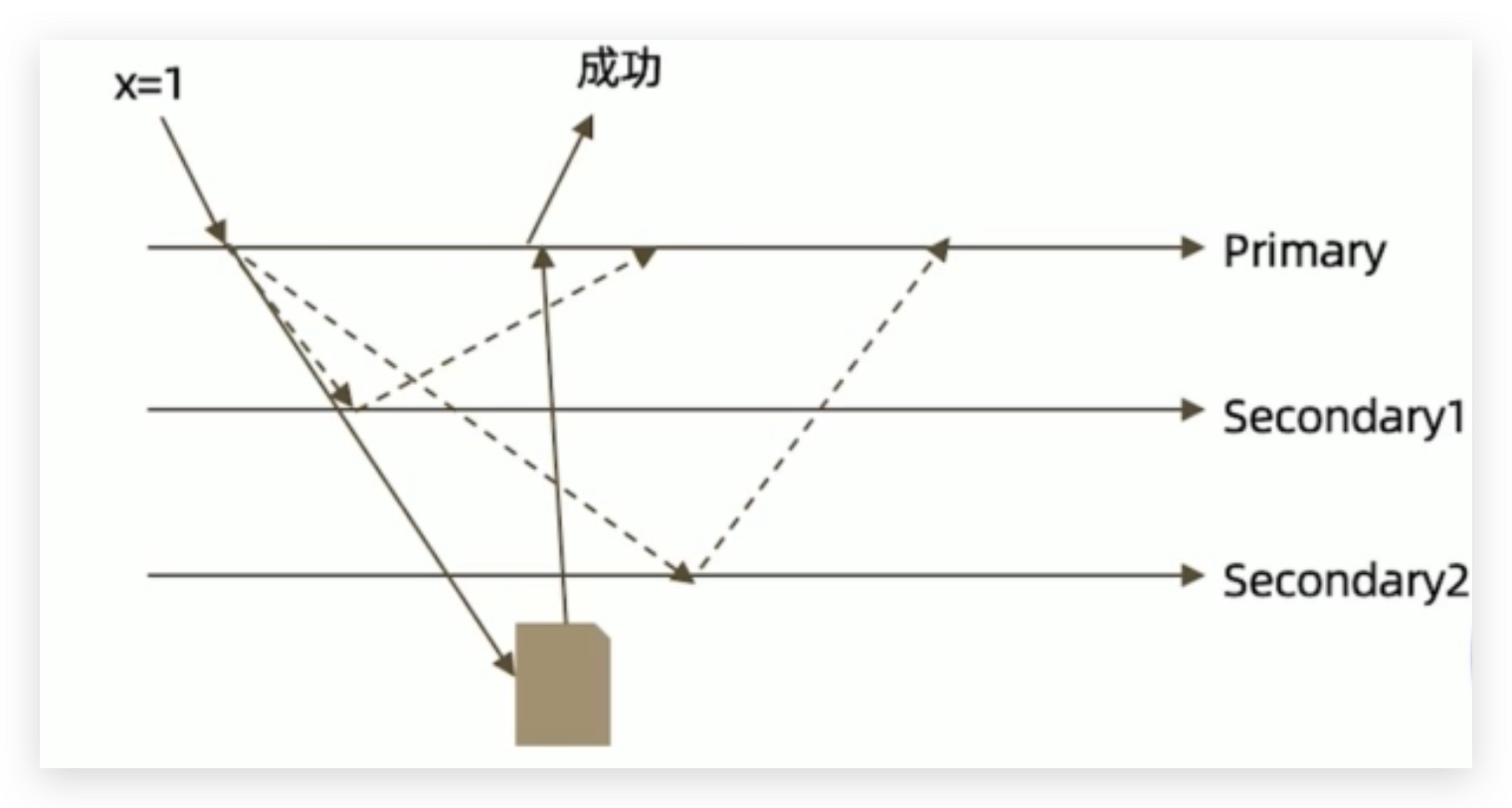
j:true(进一步增加安全性)
writeConcern可以决定写操作到达多少个节点才算成功,journal则定义如何才算成功。取值包括:
- true:写操作落到journal文件中才算成功
- false:写操作到达内存即算作成功
writeConcern的意义
对于5个节点的复制集来说,写操作落到多少个节点上才算是安全的?
- 1
- 2
- 3 (安全)
- 4 (安全)
- 5 (安全)
- majority (安全)
这几个设置都能保证数据安全写到MongoDB的集群里面,哪怕出现宕机,也不会丢失你的数据

注意事项
- 虽然多于半数的writeConcern都是安全的,但通常只会设置majority,因为这是等待写入延迟时间最短的选择
- 不要设置writeConcern等于总节点数,因为一旦有一个节点故障,所有写操作都将失败;
- writeConcern虽然会增加写操作延迟时间,但并不会显著增加集群压力,因此无论是否等待,写操作最终都会复制到所有节点上。设置writeConcern只是让写操作等待复制后再返回而已;
应对重要数据应用{ w: “majority” },普通数据可以应用{ w: 1 } 以确保最佳性能
读操作事务
在读取数据的过程中我们需要关注以下两个问题:
从哪里读?关注数据节点位置
- 什么样的数据可以读?关注数据的隔离性
第一个问题是由 readPreference 来解决
第二个问题则是由 readConcern 来解决
什么事readPreference?
readPreference决定使用哪一个节点来满足
正在发起的读请求。可选值包括:
- primary:只选择主节点;
- primaryPreferred:优先选择主节点,如果不可用则选择从节点;
- secondary:只选择从节点
- secondaryPreferred:优先选择从节点,如果从节点不可用则选择主节点
- nearest:选择最近的节点
readPreference场景举例
- 用户下订单后马上将用户转到订单详情页— primary / primaryPreferred。因为此时从节点可能还没复制到新订单;
- 用户查询自己下过的单— secondary / secondaryPreferred。查询历史订单对时效性通常没有太高的要求
- 生成报表— secondary。报表对时效性要求不高,但资源需求大,可以在从节点单独处理,避免对线上用户造成影响
将用户上传的图片分发到全世界,让各地用户能够就近读取 — nearest。每个地区的用户选择最近的节点读取数据
readPreference 与 Tag
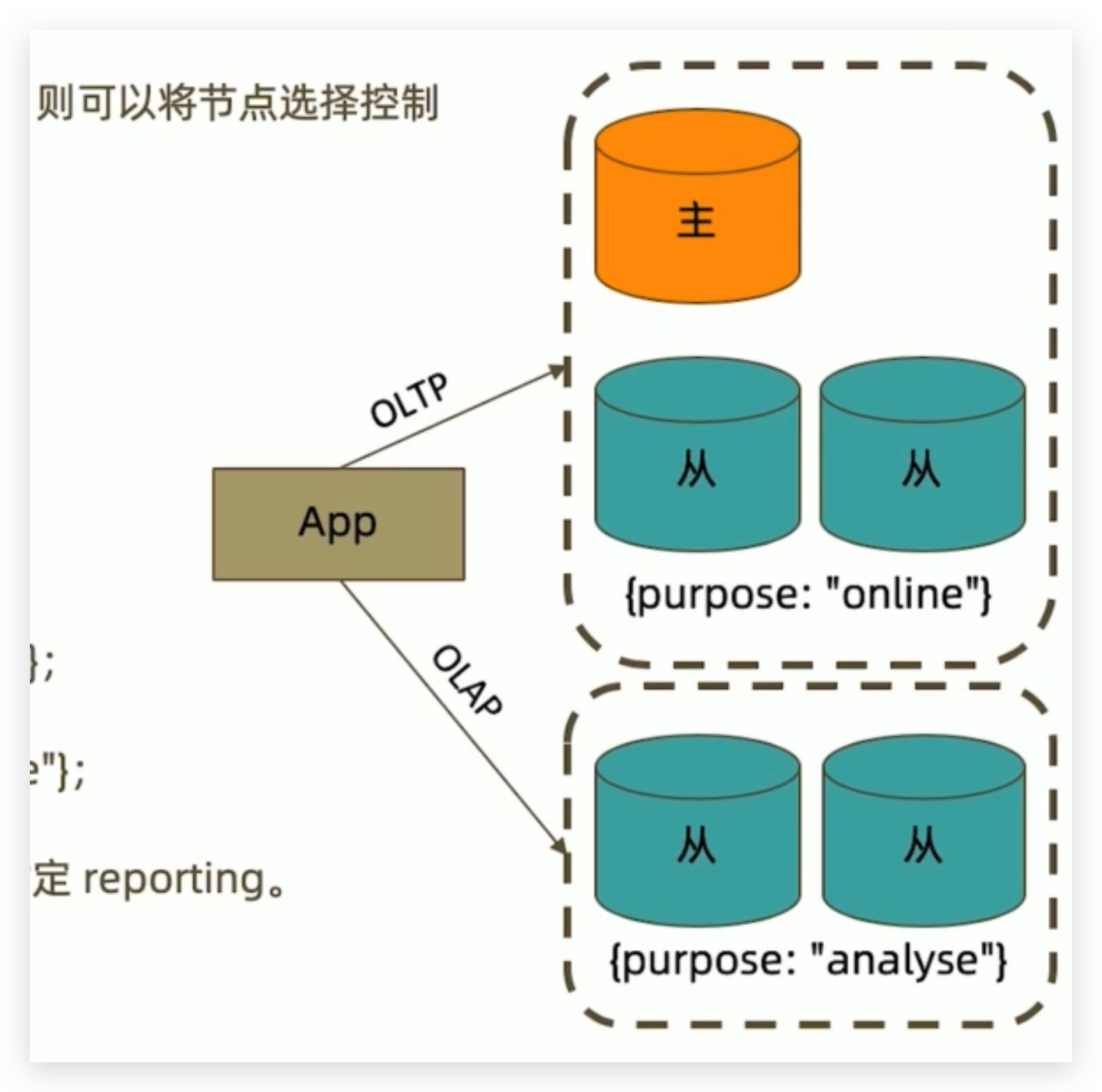
readPreference只能控制使用一类节点。Tag则可以将节点选择控制到一个或几个节点。考虑以下场景:
一个5个节点的复制集;
- 3个节点硬件较好,专用于服务线上客户;
- 2个节点硬件较差,专用于生成报表l
可以使用Tag来达到这样的控制目的:
- 为3个较好的节点打上{ purpose: “online” }
- 为2个较差的节点打上 { purpose: “analyse” }
- 在线应用读取时指定online,报表读取时指定reporting
readPreference配置

readPreference
- 主节点写入{ x: 1 },观察该条数据在各个节点均可见
- 在两个从节点分别执行 db.fsyncLock() 来锁定写入(同步)
- 主节点写入{ x: 2 }
- db.test.find({a:123})
- db.test.find({a:123}).readPref(“secondary”)œa
解除从节点锁定db.fsyncUnlock()
通常读写分离。
- 使用writeConcern + readConcern majority来解决




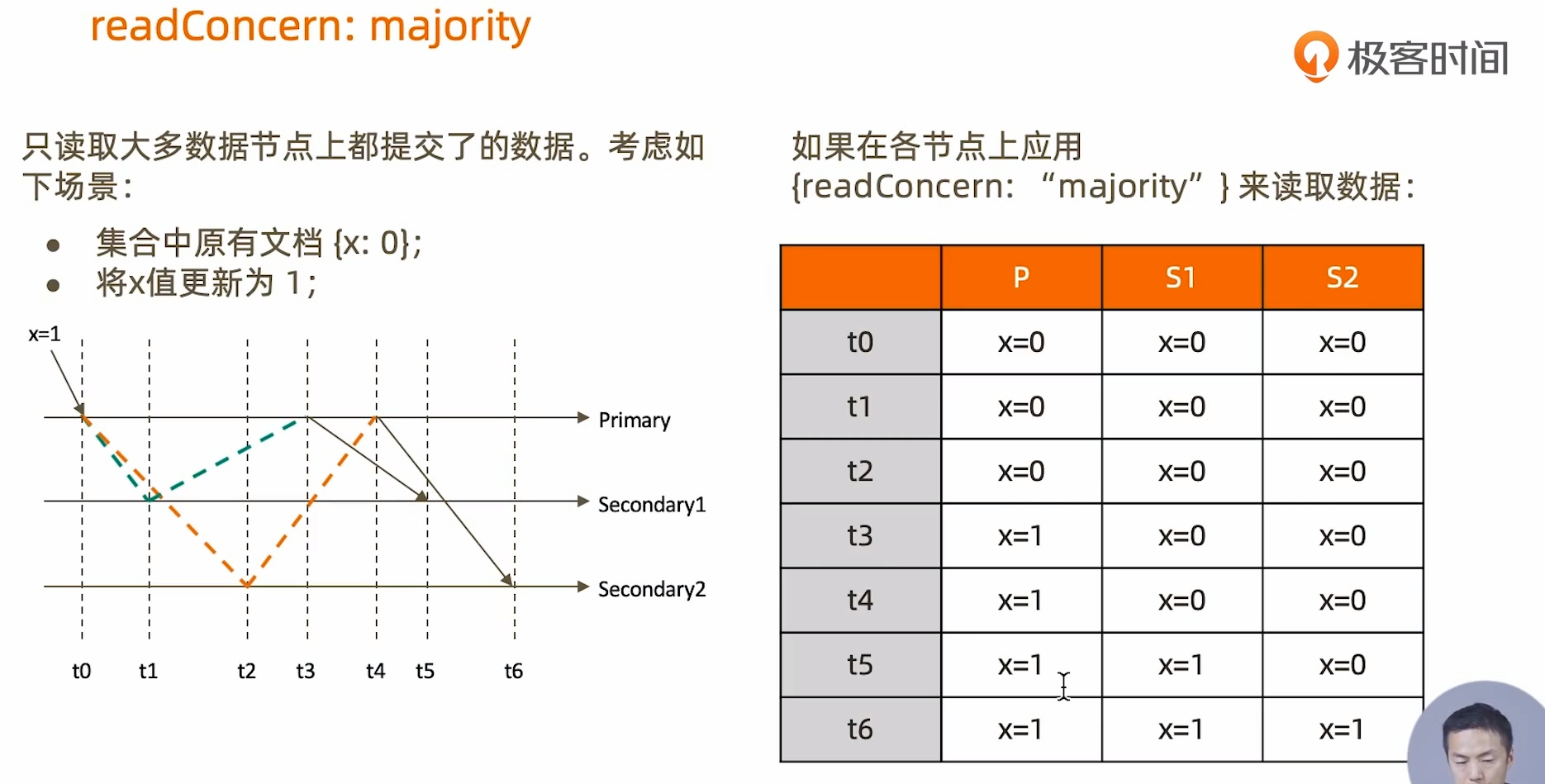




测试
- 脏读
- 可提交读 (对的)
- 可重复读
- 线性读

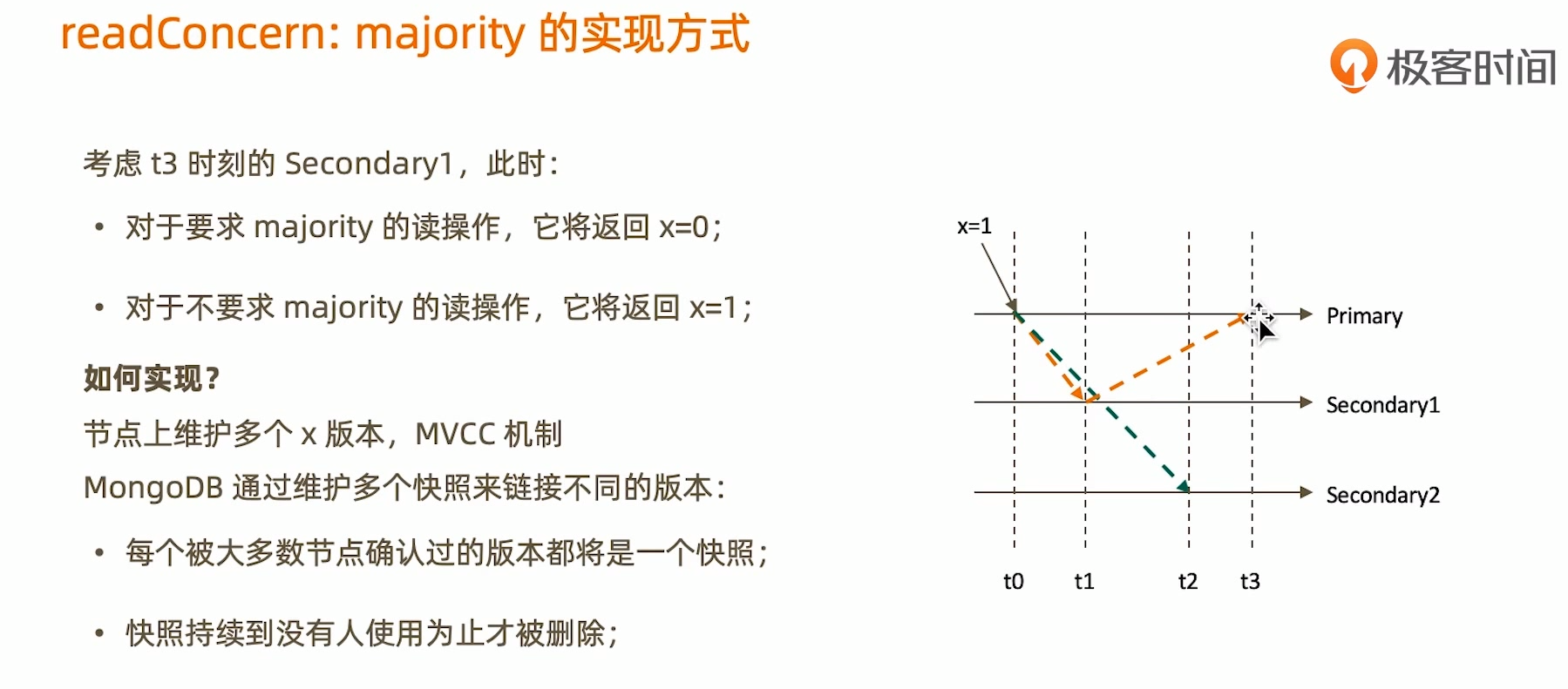
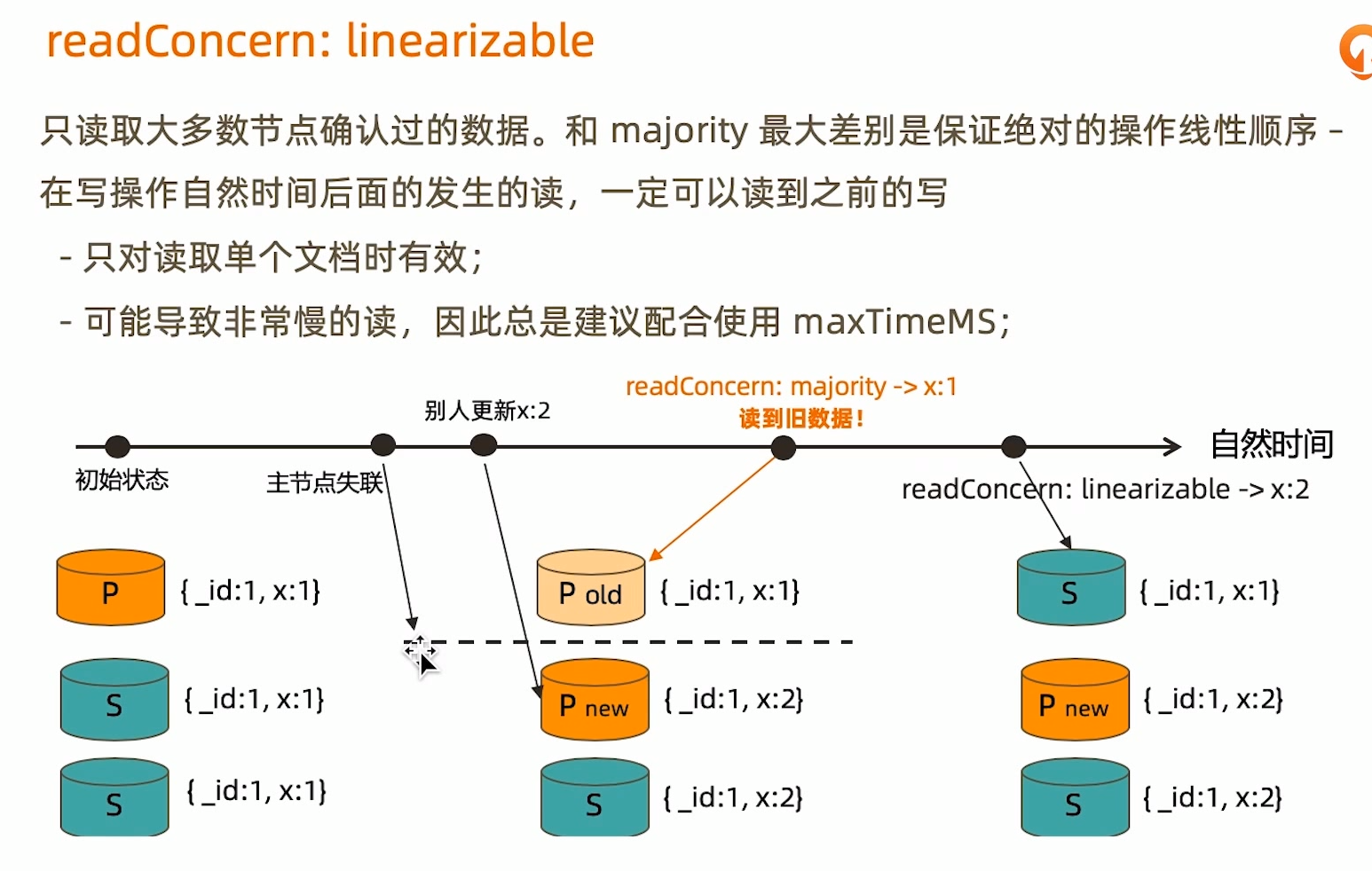
readConcern:linearizable


readConcern 小结
- MongoDB 的 readConcern 默认情况下是脏读(readConcer=local),例如,用户在主节点读取一条数据之后,该节点未将数据同步至其它从节点,就因为异常挂掉了,待主节点恢复之后,将未同步至其它节点的数据进行回滚,就出现了脏读。
- readConcern 级别的 majority 可以保证读到的数据已经落入到大多数节点。所以说保证了事务的隔离性的提交读,所谓隔离性也是指事务内的操作,事务外是看不见的,在事务隔离级别中为提交读(readConcer=majority)。
- readConcern 的 snapshot 属性对应事务隔离级别的可重复读,例如,当开启事务先读取一条数据,之后在事务外对该数据进行修改,如果此时事务内在查询一次该数据可保证重复读,也就是不会读取到事务外修改的数据,例如下例琐事
- readConcern 的 snapshot 是事务隔离级别中的最高级别,可以保证不会出现脏读、不可重复读、幻读,仅在多文档事务中生效。
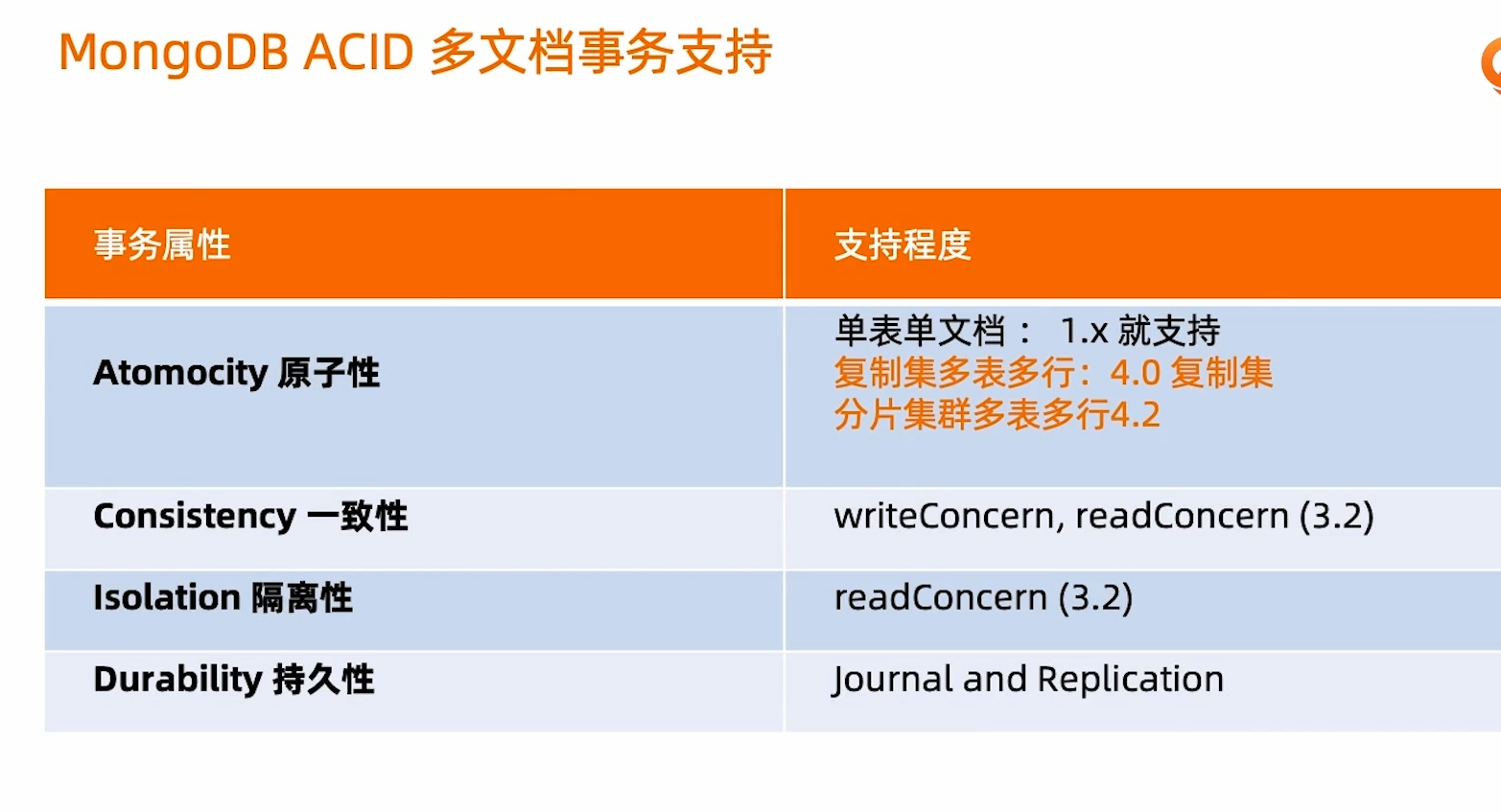
多文档事务
除非在核心的场景下少量的使用事务,大部分时候通过合理的设计文档模型,很大的规避事务场景的必要性的



若有收获,就点个赞吧
0 人点赞
