数据模型介绍和对比
数据模型
数据模型是一组由符号、文本组成的集合,用以准确的表达信息,达到有效交流、沟通的目的。 —-Steve Hoberman 霍伯曼.数据建模经典教程作者
数据模型设计的元素
实体 Entity
- 描述业务的主要数据集合
-
属性 Attribute
-
关系 Relationship
描述实体与实体之间的数据规则
- 结构规则:1 - N, N - 1,N - N。(一对多、多对一、多对多)
- 引用规则:电话号码不能单独存在
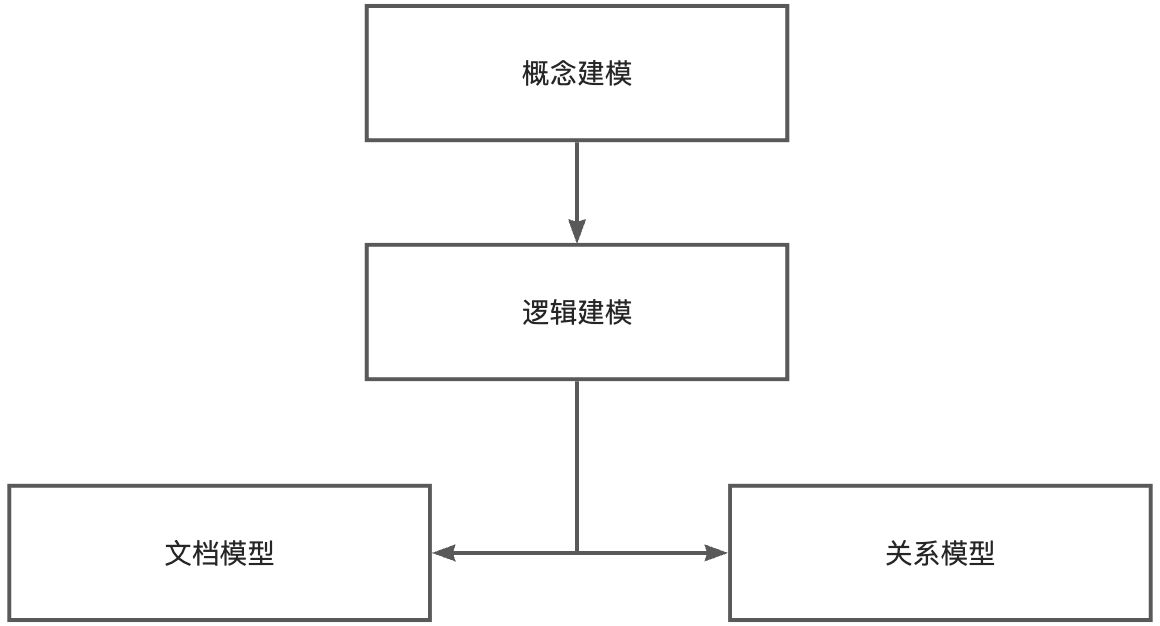
传统模型设计:从概念到逻辑到物理
开发者视角:
- 概念模型:有哪些实体,比如 内容、组…
- 逻辑模型:这些实体具体有哪些特征,比如 联系人有姓名、性别、电话。。。。
- 第三范式下的物理模型:原则是数据在库里尽量不可能存在冗余
|
| 概念模型CDM | 逻辑模型LDM | 物理模型PDM | | —- | —- | —- | —- | | 目的 | 描述业务系统要管理的对象 | 基于概念模型,详细列出所有实体、实体的属性以及关系 | 根据逻辑模型,结合数据库的物理结构,设计具体的表结构,字段列表及主外键 | | 特点 | 用概念名词来描述现实中的实体以及业务规则,如‘联系人’ | 基于业务的描述和数据库无关 | 技术实现细节和具体的数据库类型相关 | | 主要使用者 | 用户需求分析师 | 需求分析师、架构师及开发者 | 开发者、DBA |
模式设计小结
数据模型的三要素:
- 实体
- 属性
- 关系
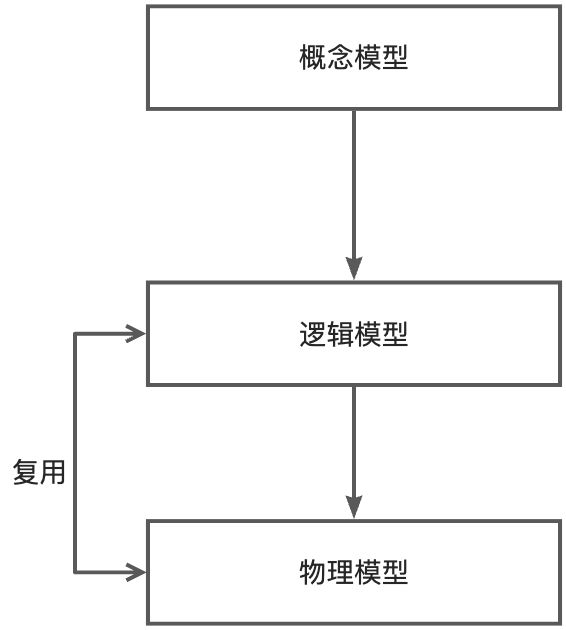
数据模型的三层深度
为什么人们都说MongoDB是无模式?
严格来说,MongoDB同样需要概念/逻辑建模
文档模型设计的物理层结构可以和逻辑层类似
MongoDB无模式由来:
- 可以省略物理建模的具体过程
文档模型的设计原则:性能和易用
- 性能:Performance
- 开发易用:Ease of Development
关系模型 VS 文档模型
|
| 关系数据库 | JSON文档模型 | | —- | —- | —- | | 模型设计层次 | 概念模型
逻辑模型
物理模型 | 概念模型
逻辑模型 | | 模型实体 | 表 | 集合 | | 模型属性 | 列 | 字段 | | 模型关系 | 关联关系、主外键 | 内嵌数组、引用字段 |
MongoDB文档模型设计的误区
- 不需要模型设计 ❌
- mongodb应该用一个超级大文档来组织所有数据 ❌
MongoDB不支持关联(从3.2版本支持关联,$lookup)或者事务 ❌
文档模型设计
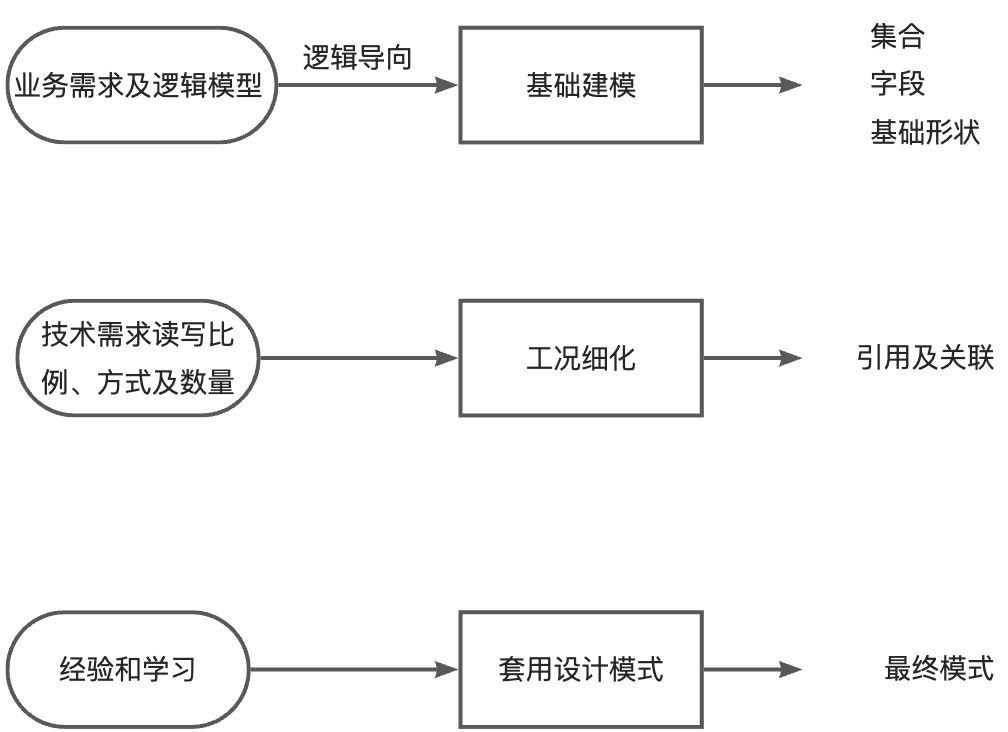
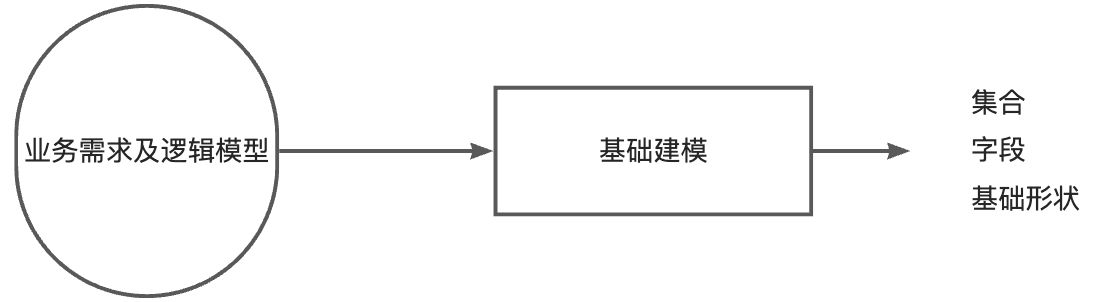
第一步:建立基础文档模型
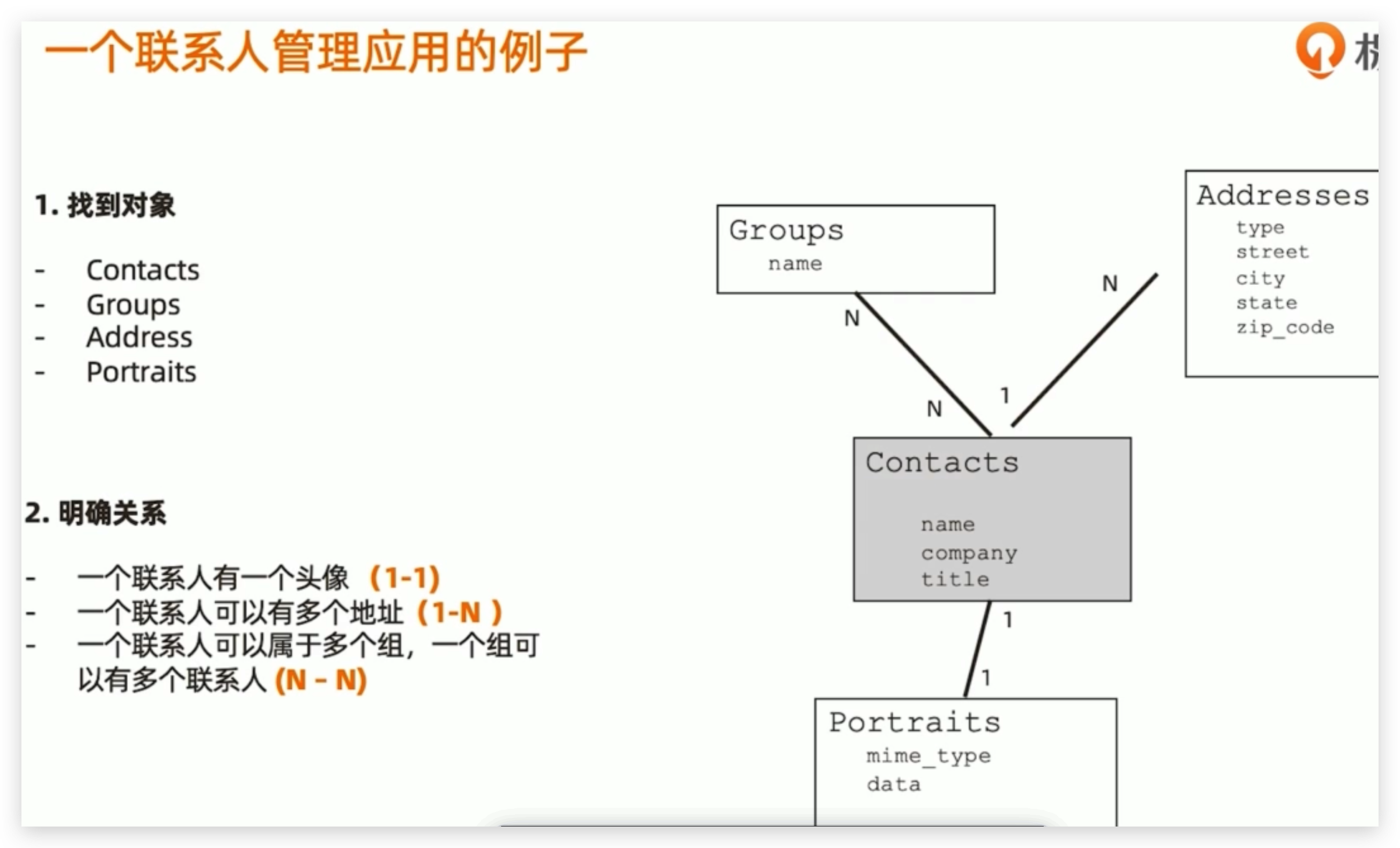
根据概念模型或者业务需求推导出逻辑模型 -找到对象
- 列出实体之间的关系(及基数) -明确关系
- 套用逻辑设计原则来决定内嵌方式 -进行建模
- 完成基础模型构建
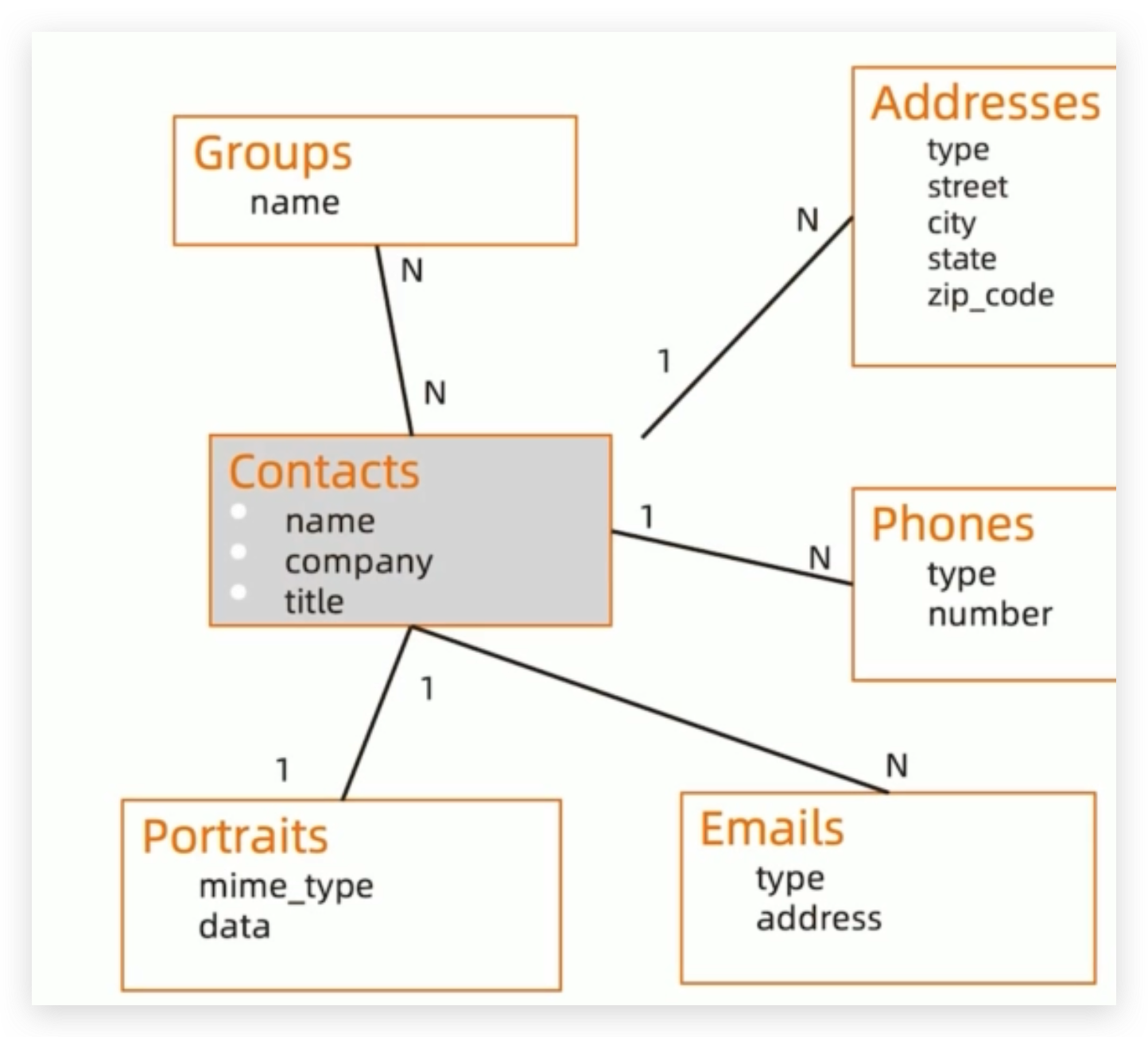
一个联系人管理应用的例子
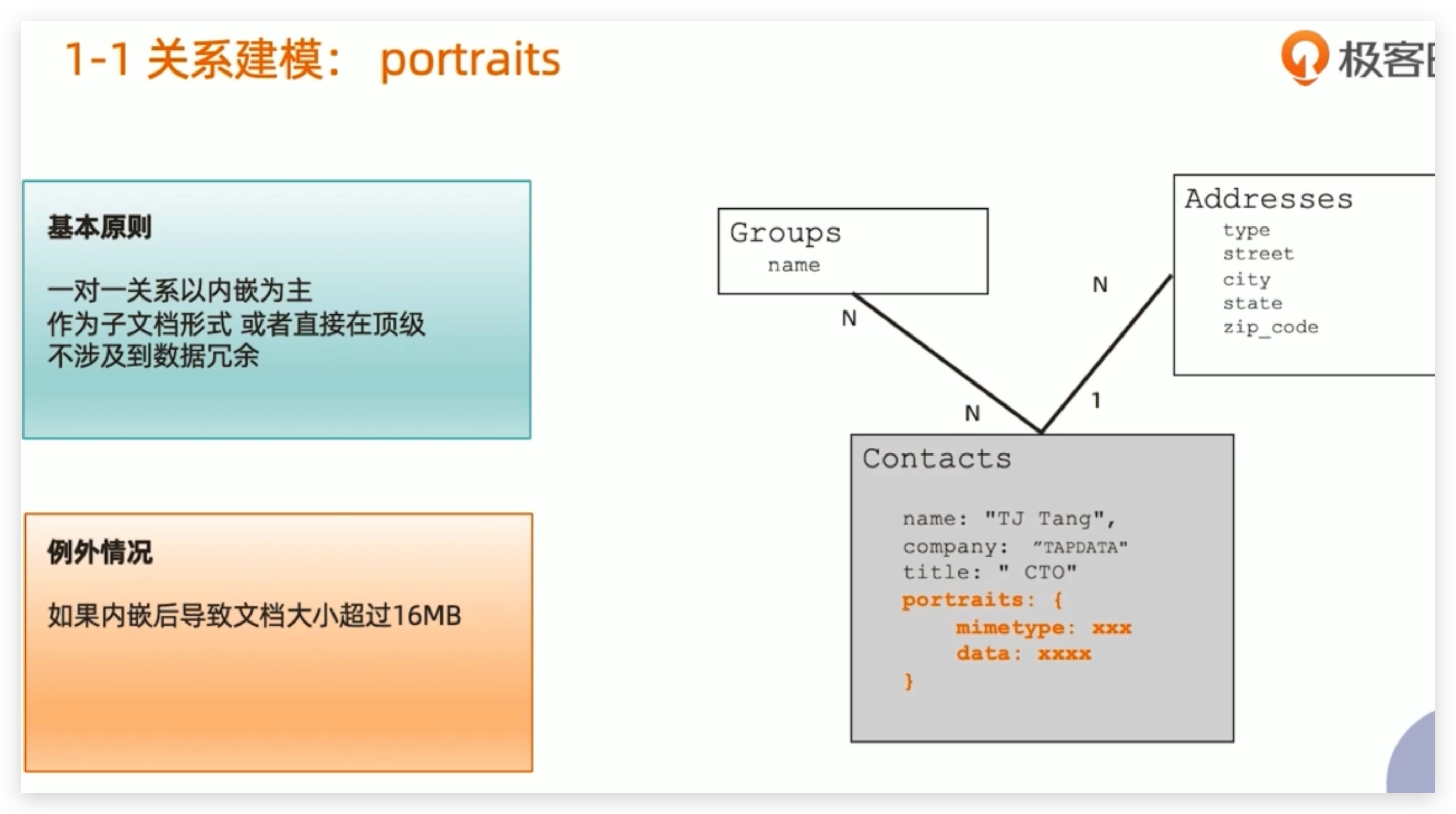
1-1关系建模:portraits
- 基本原则:
- 一对一关系以内嵌为主(把信息作为子文档,总结放入)mongodb支持直接把二进制放在文档中的,不涉及到数据冗余
- 例外情况
- 如果内嵌后导致文档大小超过16MB(一个文档不能超过16MB)
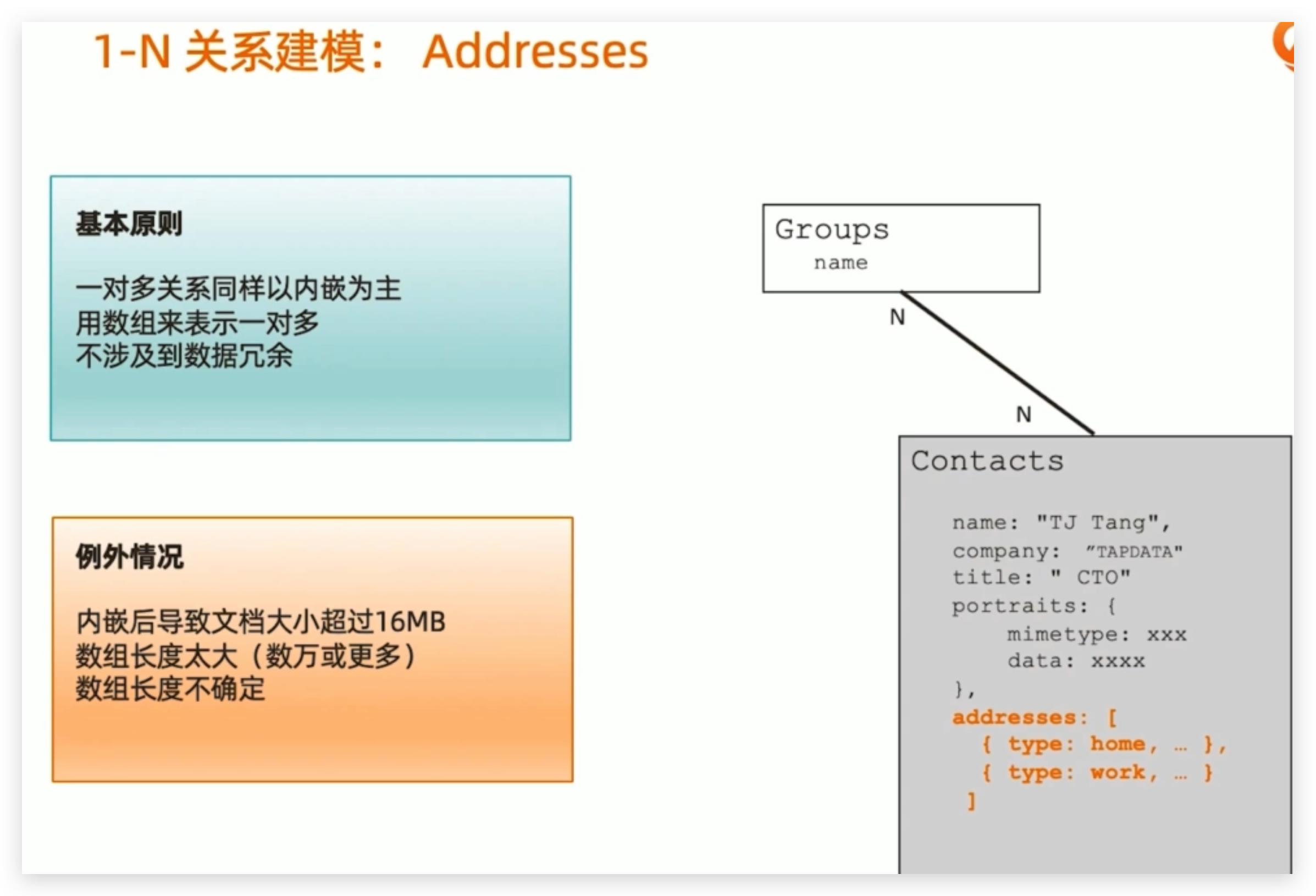
1-N 关系建模:Addresses
- 基本原则:一对多关系同样是以内嵌为主,用数组来表示一对多,不涉及到数据冗余
- 例外情况:内嵌后导致文档大小超过16MB,数组长度太大(数万或者更多),数组长度不确定。
N-N 关系建模:内嵌数组模式
- 基本原则:不需要映射表,一般用内嵌数组来表示一对多,通过冗余来实现N-N
- 例外情况:内嵌后导致文档大小超过16MB,数组长度太大(数万或者更多)数组长度不确定

第二步:根据读写工况细化

- 最频繁的数据查询模式
- 最常用的查询参数
- 最频繁的数据写入模式
- 读写操作的比例
- 数据量的大小
基于内嵌的文档模型
根据业务需求
使用引用来避免性能瓶颈
使用冗余来优化访问性能
联系人管理应用的分组需求
- 用于客户营销
- 有千万级别联系人
- 需要频繁变动分组(group)的信息,如增加分组及修改名称及描述以及营销状态
- 一个分组可以有百万级联系人

解决方案:Group使用单独的集合
- 类似于关系型设计
- 用id或者唯一键关联
- 使用$lookup来提供一次查询多表的能力(类似关联)
$lookup
- form: 指定同一数据库中的集合以执行联接。from集合不能分片
- localField: 本文档中的聚合的数组
- foreignField:groups文档的字段
- as:输出的名字


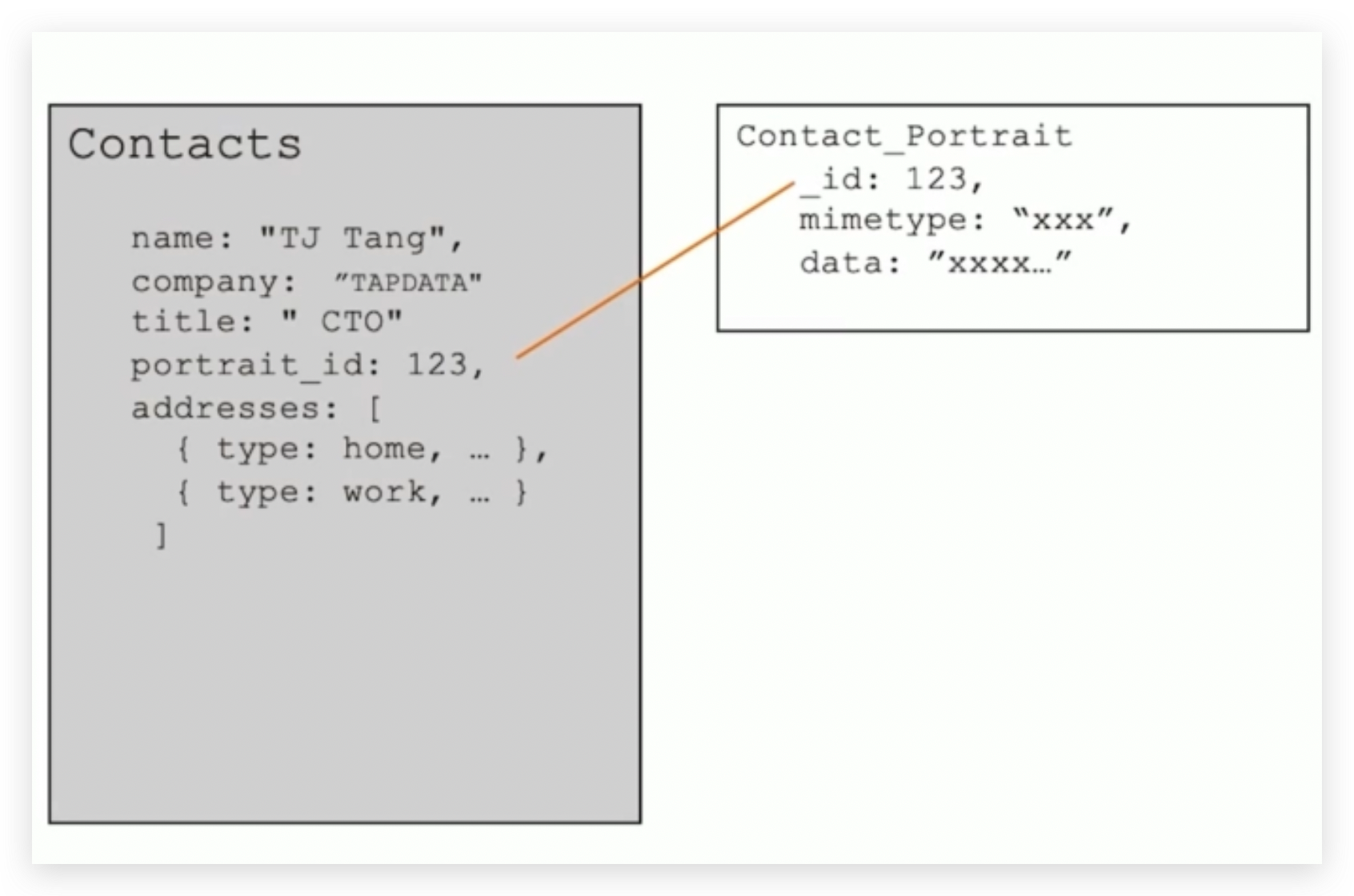
联系人的头像:引用模式
- 头像使用高保真,大小中5MB - 10MB
- 头像一旦上传,一个月不可更换
- 基础信息查询(不含头像)和头像查询的比例为9 : 1
- 建议:使用引用方式,把头像数据放到另外一个集合,可以显著提升90的查询效率
* 什么时候该使用引用方式?
- 内嵌文档太大,数MB或者超过16MB
- 内嵌文档或数组元素会频繁修改(比如头像,签名等等)
-
MongoDB引用设计的限制
MongoDB对使用引用的集合之间并无主外键检查
- MongoDB使用聚合框架的$lookup来模仿关联查询
- $lookup只支持left outer join (太复杂的关联是没办法完成的)
- $lookup的关联目标(from)不能是分片表

第三步:套用设计模式
文档模式:无范式,无思维定式,充分发挥想象力
设计模式:实战过屡试不爽的设计技巧,快速应用
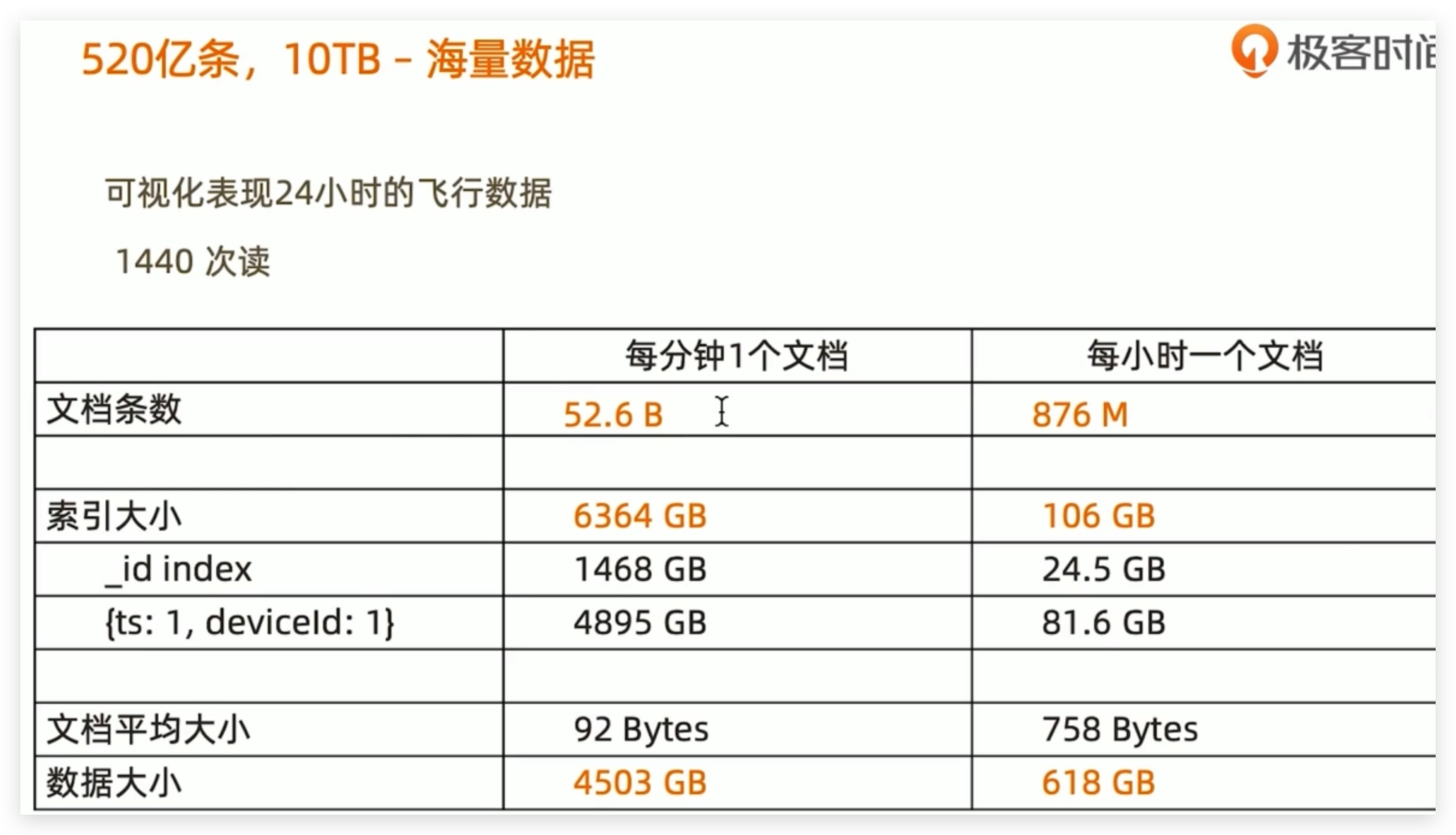
举例: 一个IoT场景的分桶设计模式,可以帮助把存储空间降低10倍,并且查询效率提升数十倍
问题:物联网场景下的海量数据处理 - 飞机监控数据
- 实时对飞机的信息一个记录(航班号、时间戳、位置。。。)


解决方案:分桶设计
- 一个文档:一架飞机一个小时的数据,每一小时存一条


小结:
一个好的设计模式可以显著地:
- 提升数据读写的效率
- 降低资源的需求

设计模式
问题:大文档,很多字段,很多索引


问题;模型灵活了,如何管理文档不同版本?
- 增加一个版本字段



问题:统计网页点击流量

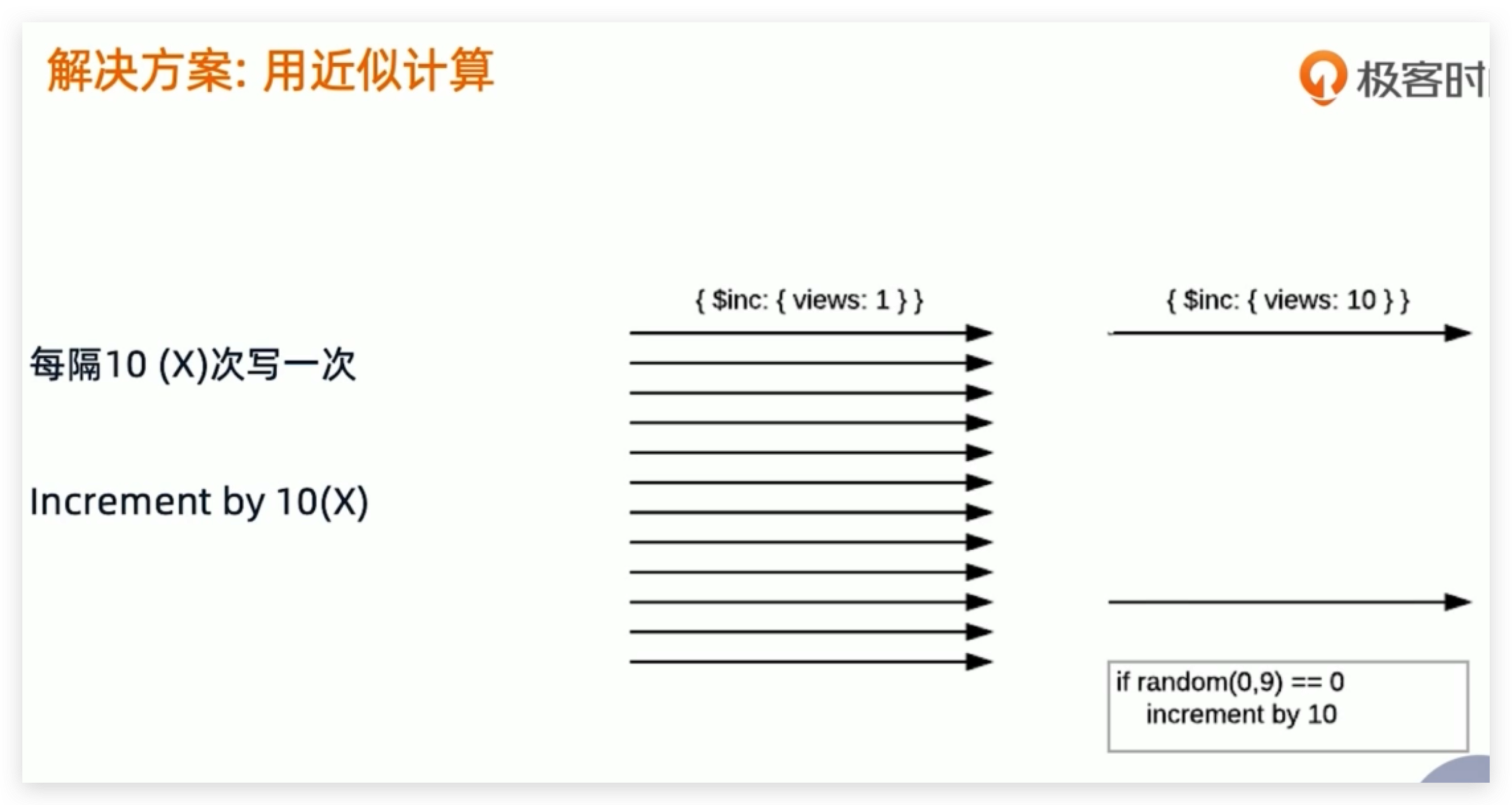

问题:业绩排名,游戏排名,商品统计等精确统计



MongoDB相关链接
官方文档:https://docs.mongodb.com/manual/mongo/
中文社区:https://mongoing.com
官方中文文档:https://docs.mongoing.com
中文文档:https://www.runoob.com/mongodb/mongodb-databases-documents-collections.html

若有收获,就点个赞吧
0 人点赞
