- Buffer缓冲区
- Buffer让JavaScript可以操作二进制
- 二进制数据、流操作、Buffer
- Nodejs平台下JavaScript可实现IO行为操作(二进制数据)
- Steam流操作并非Nodejs独创
-
为什么有Buffer
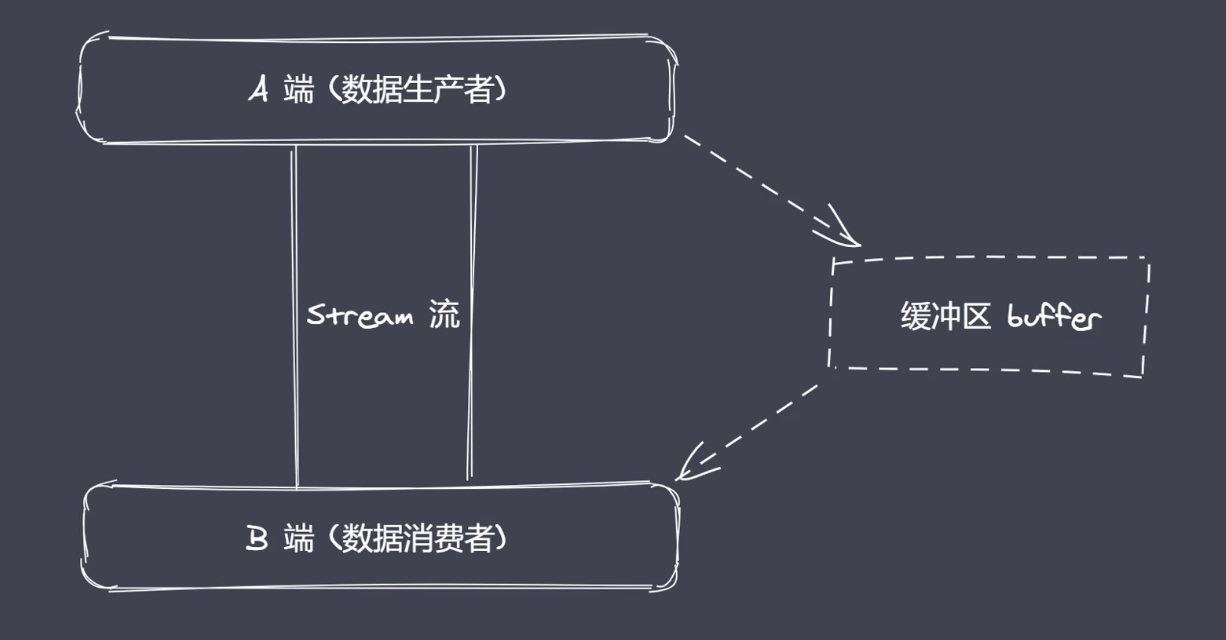
数据的端到端传输会有生产者和消费者,中间使用流+管道进行连接,实际工作中,数据的生产速度无法满足数据的消费速度,数据的消费速度比生产的速度慢许多,生产和消费的过程往往存在等待,产生等待时数据存放在哪?
Nodejs中Buffer是一片内存空间,代码由V8引擎执行,所有的内存消耗都是V8的堆内存,而Buffer是V8之外的空间,不占据V8内存,Buffer的申请不是node完成(C++空间分配),但是使用空间分配又是由编写的JS代码来控制的,因此在空间回收,还是由V8的gc管理和回收。Buffer总结
无须require的一个全局变量
- 实现Nodejs平台下的二进制数据操作
- 不占据V8堆内存大小的内存空间
- 内存的使用由Node来控制,由V8的GC回收
- 一般配合Steam流使用,充当数据缓冲区(文件读写操作)
了解如何创建Buffer实例
创建Buffer实例
- alloc 创建指定字节大小的buffer
- allocUnsafe 创建指定大小的buffer(不安全)
- from 接收数据,创建buffer对象的实例,默认有数据
Buffer本身是一个类,为什么不使用new操作呢? Nodejs V6版本之前是可以通过new操作实例化对象,但是这种方法给对象实例权限太大了,高版本中做了处理,不建议使用new实例化Buffer
// const b1 = Buffer.alloc(10) // <Buffer 00 00 00 00 00 00 00 00 00 00> 十六进制// 不安全的创建方法,在内存中只要有一个空闲的空间就会拿过来使用,// const b1 = Buffer.allocUnsafe(10)// from(加载数据类型,对应的编码(utf8)) 第一个参数可以是string或者数组 ,一个汉字占据3个字节const b1 =Buffer.from('琪') // <Buffer 31>// 如果传数组,想传中文的话,需要提前转成十六进制,不然无法识别// const b2 = Buffer.from([1,2,3,'中'],'utf8') // 中打印不出来// console.log(b2) // <Buffer 01 02 03 00>const b2 = Buffer.from([0xe4, 0xb8, 0xad], 'utf8')// 将中,转为十六进制使用toString就可以显示了console.log(b2); // <Buffer e4 b8 ad>console.log(b2.toString()); //toString 打印 中,把buffer十六进制转成中文const b3 = Buffer.from('中')console.log(b3); // <Buffer e4 b8 ad>console.log(b3.toString()); //打印 中,把buffer十六进制转成中文// a 和a1并不是共享空间,而是进行了拷贝,只是利用了老空间的大小长度,创建了一个新空间const a = Buffer.alloc(3)const a1 = Buffer.from(a)console.log(a); // <Buffer 00 00 00>console.log(a1); // <Buffer 00 00 00>a[0] = 1console.log(a); // <Buffer 00 00 00>console.log(a1); // <Buffer 01 00 00>
Buffer实例方法
- fill 使用数据填充buffer, 参数 (数据源,写入开始位置,结束位置取不到) 如果数据短,会重复写入
- write 向buffer中写入数据, write (‘123’,从哪个位置写入,写入长度) 不会重复写入
- toString 从buffer中提取数据 toString(开始截取位置,结束位置) 顾头不顾尾
- slice 截取buffer slice(开始截取位置,结束位置) 顾头不顾尾
- indexOf 在buffer中查找数据, indexOf(目标,开始查找位置),如果不存在返回-1
- copy 拷贝buffer中的数据 深拷贝 拷贝源.copy(拷贝至, 开始位置, 结束位置) ```javascript let buf = Buffer.alloc(6)
// fill填充数据(会重复写入) 6个字节,如果数据没有填满,将会反复填满,如果超出,最多写6个字节
// 第一个是填充数据,第二个参数是初始位置, 第三个参数是写入的结束位置(取不到)
buf.fill(‘123’, 1,3)
console.log(buf); //
// write (‘123’,从哪个位置写入,写入长度) 不会重复写入 buf.write(‘123’, 2, 3) console.log(buf); console.log(buf.toString());
// toString() 1个中文占3个字符,下面一共是12个字节 buf = Buffer.from(‘拉钩教育’) console.log(buf); console.log(buf.toString(‘utf-8’, 3, 9)); //钩教 3是指定开始位置,9是结束位置
// slice(开始截取位置,结束位置) 顾头不顾尾
buf = Buffer.from(‘拉勾教育’)
let a = buf.slice(-3)
console.log(a); //
// indexOf(目标,开始查找位置),如果不存在返回-1 console.log(buf); console.log(buf.indexOf(‘勾’));
let b1 = Buffer.alloc(6) let b2 = Buffer.from(‘拉钩111’)
// 将b2的数据拷贝到b1里面, 拷贝的时候也可以传入开始位置和结束位置 b2.copy(b1, 3, 4) console.log(b1.toString()); console.log(b2.toString());
<a name="gAx8g"></a>##### Buffer静态方法- concat 将多个buffer拼接成一个新的buffer- isBuffer 判断当前数据是否为buffer```javascriptconst b1 = Buffer.from('hello')const b2 = Buffer.from('world')// 第一个参数是个需要合并的数组,第二个参数可以限制字节let b = Buffer.concat([b1, b2])console.log(b);console.log(b.toString());// helloworld// Buffer.isBuffer判断是否是bufferconst b1 = Buffer.alloc(3)console.log(Buffer.isBuffer(b1)); // true
自定义Buffer 之 split
ArrayBuffer.prototype.split = function (sep) {// 放入当前分割符的长度let len = Buffer.from(sep).lengthlet ret = []// 默认从当前buffer第一个let start = 0// 偏移量let offset = 0// 通过循环,查找分割符,默认从0查找while (this.indexOf(sep, start) !== -1) {// 截取到offset位置,ret.push(this.slice(start, offset))// 更新开始位置start = offset + len}// 考虑到结尾满足条件ret.push(this.slice(start))return ret}let buf = '上海科技有限公司'let bufArr = buf.split('科')console.log(bufArr); // [ '上海', '技有限公司' ]

若有收获,就点个赞吧
0 人点赞
