一. 倒排索引概念
将各个文档中的内容进行分词,形成词条。然后记录词条和数据唯一标识(id)的对应关系形成的产物。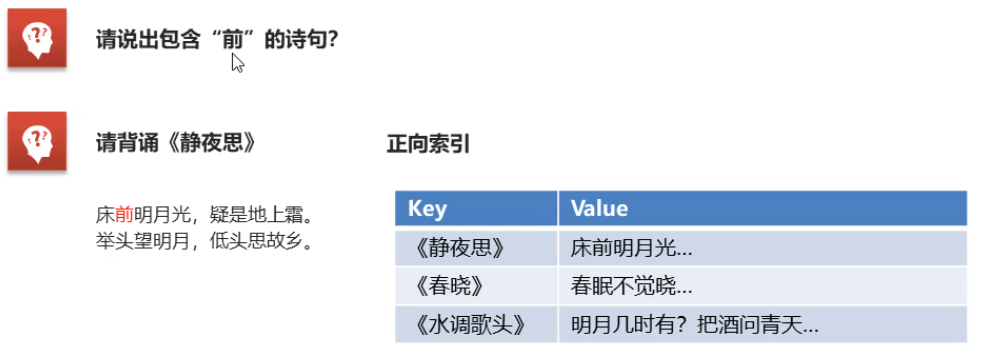
备注:生成倒排索引中,词条会进行排序,形成树形结构,提高词条的查询速度。
二. ElasticSearch入门
1. ES存储和查询原理
2. Elastic Search概念
2.1 概念
- es是基于lucene的搜索服务器;
- 是一个分布式,高扩展,高实时的搜索与数据分析引擎;
- 基于Restful web接口;
- 是Java语言开发,是apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎;
- 官网:https://www.elactic.co/
2.2 应用场景:
- 海量数据的查询
- 日志数据的分析
-
2.3 Elastic search与MySQL的区别:
MySQL有事务性,ES没有事务性,所以,ES当你删除了数据是无法恢复的。
- ES没有物理外键的特性,如果数据的强一致性要求较高,那么慎用。
总之:ES和MySQL分工不同,MySQL负责储存数据,ES负责搜索数据。
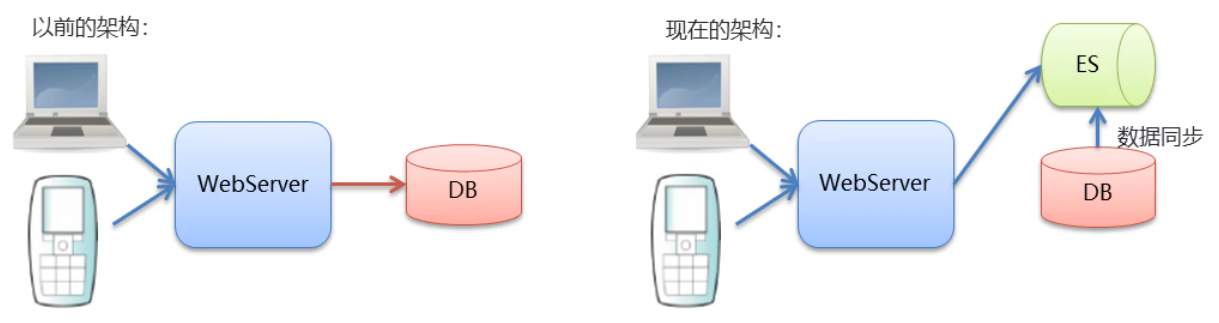
3. ElasticSearch和kibana安装
4. ElasticSearch核心概念
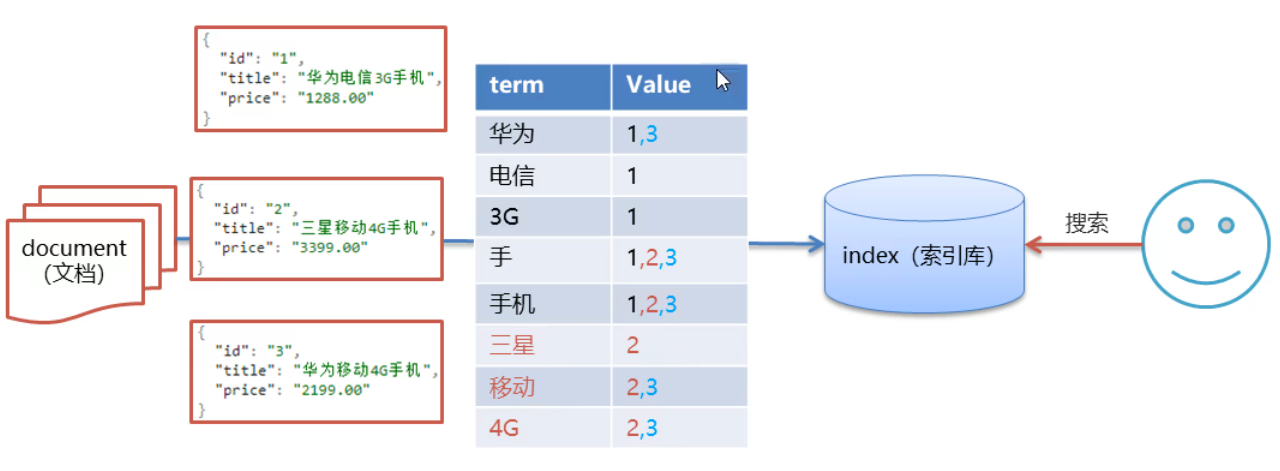
- 索引(index):ES存储数据的地方,可以理解成关系数据库中的数据库概念。
- 映射(mapping):mapping定义了每个字段的类型、字段所使用的分词器等。相当于关系型数据库中的表结构。
- 文档(document):ES中的最小数据单元,常以json格式显示。一个document相当于关系型数据库中的一行数据。
- 倒排索引:一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,对应一个包含它的文档id列表。
三. IK分词器
概念:将一段文本,按照一定逻辑,分析成多个词语的一种工具。
IK分词器安装
四. spring boot整合ES
4.1 引入maven坐标
<!-- 引入es --><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.9.2</version></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.9.2</version></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId><version>7.9.2</version></dependency>
4.2 将ES托管spring boot
@Configurationpublic class ESConfig {@Beanpublic RestHighLevelClient client(){return new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.233.128",9200,"http")));}}
备注:可以专门设一个config包,专门用来放置配置类。需要使用client对象只需要:
@Autowiredprivate RestHighLevelClient client;
即可。
五. ES基本增删改查操作
首先要创建一个索引还有映射。可以使用Java创建,也可以使用kibana创建,这里使用kinaba创建。
PUT /索引名/_mappings{"properties": {"id":{"type": "integer"},"title":{"type": "text"},"money":{"type": "float"},"num":{"type": "integer"}}}
备注:es7.x以前和以后不一样,7.x以后没有type了。
5.1 添加文档
//添加文档Goods goods = new Goods();goods.setId(1);goods.setMoney(666);goods.setNum(555);goods.setTitle("iphone手机");String s = new Gson().toJson(goods);IndexRequest indexRequest = new IndexRequest("study").id(String.valueOf(goods.getId())).source(s, XContentType.JSON);IndexResponse index = client.index(indexRequest, RequestOptions.DEFAULT);System.out.println(index.getId());
5.2 查询文档
GetRequest study = new GetRequest("study", "1");GetResponse documentFields = client.get(study, RequestOptions.DEFAULT);System.out.println(documentFields.getSourceAsString());
5.3 删除文档
DeleteRequest study = new DeleteRequest("study", "1");DeleteResponse delete = client.delete(study, RequestOptions.DEFAULT);System.out.println(delete.getId());
备注:如若修改文档,id一样,执行添加操作即可覆盖原文档。
六. ES高级操作
6.1 批量操作
//创建bulkrequest对象,整合所有操作BulkRequest bulkRequest = new BulkRequest();/*# 1. 删除1号记录# 2. 添加6号记录# 3. 修改3号记录 名称为 “三号”*///添加对应操作//1. 删除1号记录DeleteRequest deleteRequest = new DeleteRequest("person","1");bulkRequest.add(deleteRequest);//2. 添加6号记录Map map = new HashMap();map.put("name","六号");IndexRequest indexRequest = new IndexRequest("person").id("6").source(map);bulkRequest.add(indexRequest);Map map2 = new HashMap();map2.put("name","三号");//3. 修改3号记录 名称为 “三号”UpdateRequest updateReqeust = new UpdateRequest("person","3").doc(map2);bulkRequest.add(updateReqeust);//执行批量操作BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);RestStatus status = response.status();System.out.println(status);
6.2 批量导入
//1.查询所有数据,mysqlList<Goods> goodsList = goodsMapper.findAll();//System.out.println(goodsList.size());//2.bulk导入BulkRequest bulkRequest = new BulkRequest();//2.1 循环goodsList,创建IndexRequest添加数据for (Goods goods : goodsList) {//2.2 设置spec规格信息 Map的数据 specStr:{}//goods.setSpec(JSON.parseObject(goods.getSpecStr(),Map.class));String specStr = goods.getSpecStr();//将json格式字符串转为Map集合Map map = JSON.parseObject(specStr, Map.class);//设置spec mapgoods.setSpec(map);//将goods对象转换为json字符串String data = JSON.toJSONString(goods);//map --> {}IndexRequest indexRequest = new IndexRequest("goods");indexRequest.id(goods.getId()+"").source(data, XContentType.JSON);bulkRequest.add(indexRequest);}BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);System.out.println(response.status());
6.3 matchAll查询
matchAll查询:查询所有文档
/*** 查询所有* 1. matchAll* 2. 将查询结果封装为Goods对象,装载到List中* 3. 分页。默认显示10条*/@Testpublic void testMatchAll() throws IOException {//2. 构建查询请求对象,指定查询的索引名称SearchRequest searchRequest = new SearchRequest("goods");//4. 创建查询条件构建器SearchSourceBuilderSearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//6. 查询条件QueryBuilder query = QueryBuilders.matchAllQuery();//查询所有文档//5. 指定查询条件sourceBuilder.query(query);//3. 添加查询条件构建器 SearchSourceBuildersearchRequest.source(sourceBuilder);// 8 . 添加分页信息sourceBuilder.from(0);sourceBuilder.size(100);//1. 查询,获取查询结果SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);//7. 获取命中对象 SearchHitsSearchHits searchHits = searchResponse.getHits();//7.1 获取总记录数long value = searchHits.getTotalHits().value;System.out.println("总记录数:"+value);List<Goods> goodsList = new ArrayList<>();//7.2 获取Hits数据 数组SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {//获取json字符串格式的数据String sourceAsString = hit.getSourceAsString();//转为java对象Goods goods = JSON.parseObject(sourceAsString, Goods.class);goodsList.add(goods);}for (Goods goods : goodsList) {System.out.println(goods);}}
6.4 term查询
term查询:不会对查询条件进行分词。
/*** termQuery:词条查询*/@Testpublic void testTermQuery() throws IOException {SearchRequest searchRequest = new SearchRequest("goods");SearchSourceBuilder sourceBulider = new SearchSourceBuilder();QueryBuilder query = QueryBuilders.termQuery("title","华为");//term词条查询sourceBulider.query(query);searchRequest.source(sourceBulider);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();//获取记录数long value = searchHits.getTotalHits().value;System.out.println("总记录数:"+value);List<Goods> goodsList = new ArrayList<>();SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();//转为javaGoods goods = JSON.parseObject(sourceAsString, Goods.class);goodsList.add(goods);}for (Goods goods : goodsList) {System.out.println(goods);}}
6.5 match查询
match查询:
• 会对查询条件进行分词。
• 然后将分词后的查询条件和词条进行等值匹配
• 默认取并集(OR)
/*** matchQuery:词条分词查询*/@Testpublic void testMatchQuery() throws IOException {SearchRequest searchRequest = new SearchRequest("goods");SearchSourceBuilder sourceBulider = new SearchSourceBuilder();MatchQueryBuilder query = QueryBuilders.matchQuery("title", "华为手机");query.operator(Operator.AND);//求并集sourceBulider.query(query);searchRequest.source(sourceBulider);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();//获取记录数long value = searchHits.getTotalHits().value;System.out.println("总记录数:"+value);List<Goods> goodsList = new ArrayList<>();SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();//转为javaGoods goods = JSON.parseObject(sourceAsString, Goods.class);goodsList.add(goods);}for (Goods goods : goodsList) {System.out.println(goods);}}
6.6 模糊查询
- wildcard查询:会对查询条件进行分词。还可以使用通配符 ?(任意单个字符) 和 * (0个或多个字符)
- regexp查询:正则查询
- prefix查询:前缀查询
```java
/**
- 模糊查询:WildcardQuery */ @Test public void testWildcardQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");SearchSourceBuilder sourceBulider = new SearchSourceBuilder();WildcardQueryBuilder query = QueryBuilders.wildcardQuery("title", "华*");sourceBulider.query(query);searchRequest.source(sourceBulider);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();//获取记录数long value = searchHits.getTotalHits().value;System.out.println("总记录数:"+value);List<Goods> goodsList = new ArrayList<>();SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();//转为javaGoods goods = JSON.parseObject(sourceAsString, Goods.class);goodsList.add(goods);}for (Goods goods : goodsList) {System.out.println(goods);}}/*** 模糊查询:regexpQuery*/@Testpublic void testRegexpQuery() throws IOException {SearchRequest searchRequest = new SearchRequest("goods");SearchSourceBuilder sourceBulider = new SearchSourceBuilder();RegexpQueryBuilder query = QueryBuilders.regexpQuery("title", "\\w+(.)*");sourceBulider.query(query);searchRequest.source(sourceBulider);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();//获取记录数long value = searchHits.getTotalHits().value;System.out.println("总记录数:"+value);List<Goods> goodsList = new ArrayList<>();SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();//转为javaGoods goods = JSON.parseObject(sourceAsString, Goods.class);goodsList.add(goods);}for (Goods goods : goodsList) {System.out.println(goods);}}/*** 模糊查询:perfixQuery*/@Testpublic void testPrefixQuery() throws IOException {SearchRequest searchRequest = new SearchRequest("goods");SearchSourceBuilder sourceBulider = new SearchSourceBuilder();PrefixQueryBuilder query = QueryBuilders.prefixQuery("brandName", "三");sourceBulider.query(query);searchRequest.source(sourceBulider);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();//获取记录数long value = searchHits.getTotalHits().value;System.out.println("总记录数:"+value);List<Goods> goodsList = new ArrayList<>();SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();//转为javaGoods goods = JSON.parseObject(sourceAsString, Goods.class);goodsList.add(goods);}for (Goods goods : goodsList) {System.out.println(goods);}}
<a name="bTgz9"></a>## 6.7 范围查询range 范围查询:查找指定字段在指定范围内包含值```java/*** 1. 范围查询:rangeQuery* 2. 排序*/@Testpublic void testRangeQuery() throws IOException {SearchRequest searchRequest = new SearchRequest("goods");SearchSourceBuilder sourceBulider = new SearchSourceBuilder();//范围查询RangeQueryBuilder query = QueryBuilders.rangeQuery("price");//指定下限query.gte(2000);//指定上限query.lte(3000);sourceBulider.query(query);//排序sourceBulider.sort("price", SortOrder.DESC);searchRequest.source(sourceBulider);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();//获取记录数long value = searchHits.getTotalHits().value;System.out.println("总记录数:"+value);List<Goods> goodsList = new ArrayList<>();SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();//转为javaGoods goods = JSON.parseObject(sourceAsString, Goods.class);goodsList.add(goods);}for (Goods goods : goodsList) {System.out.println(goods);}}
6.8 queryString查询
queryString:
• 会对查询条件进行分词。
• 然后将分词后的查询条件和词条进行等值匹配
• 默认取并集(OR)
• 可以指定多个查询字段
/*** queryString*/@Testpublic void testQueryStringQuery() throws IOException {SearchRequest searchRequest = new SearchRequest("goods");SearchSourceBuilder sourceBulider = new SearchSourceBuilder();//queryStringQueryStringQueryBuilder query = QueryBuilders.queryStringQuery("华为手机").field("title").field("categoryName").field("brandName").defaultOperator(Operator.AND);sourceBulider.query(query);searchRequest.source(sourceBulider);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();//获取记录数long value = searchHits.getTotalHits().value;System.out.println("总记录数:"+value);List<Goods> goodsList = new ArrayList<>();SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();//转为javaGoods goods = JSON.parseObject(sourceAsString, Goods.class);goodsList.add(goods);}for (Goods goods : goodsList) {System.out.println(goods);}}
6.9 布尔查询
boolQuery:对多个查询条件连接。连接方式:
• must(and):条件必须成立
• must_not(not):条件必须不成立
• should(or):条件可以成立
• filter:条件必须成立,性能比must高。不会计算得分
/*** 布尔查询:boolQuery* 1. 查询品牌名称为:华为* 2. 查询标题包含:手机* 3. 查询价格在:2000-3000*/@Testpublic void testBoolQuery() throws IOException {SearchRequest searchRequest = new SearchRequest("goods");SearchSourceBuilder sourceBulider = new SearchSourceBuilder();//1.构建boolQueryBoolQueryBuilder query = QueryBuilders.boolQuery();//2.构建各个查询条件//2.1 查询品牌名称为:华为QueryBuilder termQuery = QueryBuilders.termQuery("brandName","华为");query.must(termQuery);//2.2. 查询标题包含:手机QueryBuilder matchQuery = QueryBuilders.matchQuery("title","手机");query.filter(matchQuery);//2.3 查询价格在:2000-3000QueryBuilder rangeQuery = QueryBuilders.rangeQuery("price");((RangeQueryBuilder) rangeQuery).gte(2000);((RangeQueryBuilder) rangeQuery).lte(3000);query.filter(rangeQuery);//3.使用boolQuery连接sourceBulider.query(query);searchRequest.source(sourceBulider);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();//获取记录数long value = searchHits.getTotalHits().value;System.out.println("总记录数:"+value);List<Goods> goodsList = new ArrayList<>();SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();//转为javaGoods goods = JSON.parseObject(sourceAsString, Goods.class);goodsList.add(goods);}for (Goods goods : goodsList) {System.out.println(goods);}}
6.10 聚合查询
• 指标聚合:相当于MySQL的聚合函数。max、min、avg、sum等
• 桶聚合:相当于MySQL的 group by 操作。不要对text类型的数据进行分组,会失败
/*** 聚合查询:桶聚合,分组查询* 1. 查询title包含手机的数据* 2. 查询品牌列表*/@Testpublic void testAggQuery() throws IOException {SearchRequest searchRequest = new SearchRequest("goods");SearchSourceBuilder sourceBulider = new SearchSourceBuilder();// 1. 查询title包含手机的数据MatchQueryBuilder query = QueryBuilders.matchQuery("title", "手机");sourceBulider.query(query);// 2. 查询品牌列表/*参数:1. 自定义的名称,将来用于获取数据2. 分组的字段*/AggregationBuilder agg = AggregationBuilders.terms("goods_brands").field("brandName").size(100);sourceBulider.aggregation(agg);searchRequest.source(sourceBulider);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();//获取记录数long value = searchHits.getTotalHits().value;System.out.println("总记录数:"+value);List<Goods> goodsList = new ArrayList<>();SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();//转为javaGoods goods = JSON.parseObject(sourceAsString, Goods.class);goodsList.add(goods);}for (Goods goods : goodsList) {System.out.println(goods);}// 获取聚合结果Aggregations aggregations = searchResponse.getAggregations();Map<String, Aggregation> aggregationMap = aggregations.asMap();//System.out.println(aggregationMap);Terms goods_brands = (Terms) aggregationMap.get("goods_brands");List<? extends Terms.Bucket> buckets = goods_brands.getBuckets();List brands = new ArrayList();for (Terms.Bucket bucket : buckets) {Object key = bucket.getKey();brands.add(key);}for (Object brand : brands) {System.out.println(brand);}}
6.11 高亮查询
高亮三要素:高亮字段,前缀,后缀
/**** 高亮查询:* 1. 设置高亮* * 高亮字段* * 前缀* * 后缀* 2. 将高亮了的字段数据,替换原有数据*/@Testpublic void testHighLightQuery() throws IOException {SearchRequest searchRequest = new SearchRequest("goods");SearchSourceBuilder sourceBulider = new SearchSourceBuilder();// 1. 查询title包含手机的数据MatchQueryBuilder query = QueryBuilders.matchQuery("title", "手机");sourceBulider.query(query);//设置高亮HighlightBuilder highlighter = new HighlightBuilder();//设置三要素highlighter.field("title");highlighter.preTags("<font color='red'>");highlighter.postTags("</font>");sourceBulider.highlighter(highlighter);// 2. 查询品牌列表/*参数:1. 自定义的名称,将来用于获取数据2. 分组的字段*/AggregationBuilder agg = AggregationBuilders.terms("goods_brands").field("brandName").size(100);sourceBulider.aggregation(agg);searchRequest.source(sourceBulider);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();//获取记录数long value = searchHits.getTotalHits().value;System.out.println("总记录数:"+value);List<Goods> goodsList = new ArrayList<>();SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();//转为javaGoods goods = JSON.parseObject(sourceAsString, Goods.class);// 获取高亮结果,替换goods中的titleMap<String, HighlightField> highlightFields = hit.getHighlightFields();HighlightField HighlightField = highlightFields.get("title");Text[] fragments = HighlightField.fragments();//替换goods.setTitle(fragments[0].toString());goodsList.add(goods);}for (Goods goods : goodsList) {System.out.println(goods);}// 获取聚合结果Aggregations aggregations = searchResponse.getAggregations();Map<String, Aggregation> aggregationMap = aggregations.asMap();//System.out.println(aggregationMap);Terms goods_brands = (Terms) aggregationMap.get("goods_brands");List<? extends Terms.Bucket> buckets = goods_brands.getBuckets();List brands = new ArrayList();for (Terms.Bucket bucket : buckets) {Object key = bucket.getKey();brands.add(key);}for (Object brand : brands) {System.out.println(brand);}}
6.12 重建索引&索引别名
重建索引:ElasticSearch的索引一旦创建,只允许添加字段,不允许改变字段。因为改变字段,需要重建倒排索引,影响内部缓存结构,性能太低。那么此时,就需要重建一个新的索引,并将原有索引的数据导入到新索引中。
索引别名:重建索引后,代码中还是使用的老索引在操作ElasticSearch,那么有两种方式解决:
1. 改代码(不推荐);
2. 使用别名(推荐):就是将重建得索引起一个别名,这个别名和原索引一致即可,但是创建别名之前需要删除原索引。
拷贝数据:
POST _reindex
{
“source”:{
“index”:”原索引”
},
“dest”:{
“index”:”新索引”
}
}
起别名:POST 新别名/_alias/原索引
七. ES集群

若有收获,就点个赞吧
0 人点赞
