AlertManager介绍
概述
- Prometheus对指标的收集、存储同告警能力分属于Prometheus Server和AlertManager两个独立的组件组成,前者仅仅负责基于告警规则生成告警通知,具体的告警操作则由后者完成
- AlertManager负责处理由客户端发来的告警通知
- 客户端通常是Prometheus Server,但也支持来自其他工具的告警
- AlertManageer对告警通知进行分组、去重后根据路由规则将其路由到不同的receiver,如email、企业微信、钉钉等
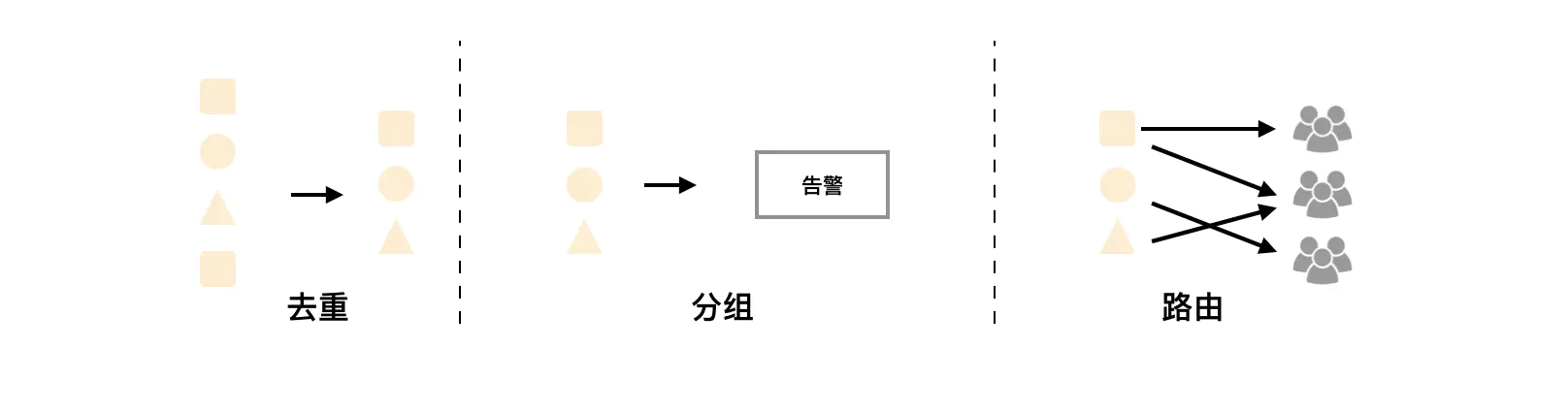
AlertManager机制
分组(Grouping)
分组机制可以将详细的告警信息合并成一个通知,这样的话假如系统宕机导致大量的告警被同时触发,那么就可以将这些被处罚的告警合并为一个告警通知,避免一次性接受大量的告警通知,而无法对问题进行快速定位
例如,当集群中有数百个正在运行的服务实例,并且为每一个实例设置了告警规则,假如此时发生了网络故障,可能导致大量的服务实例无法连接到数据库,那么这些数百个告警就都会发送到Altermanger,但是用户只希望在一个通知中就能看到是哪些服务实例受到了影响,这时候就可以按照服务所在的集群或者告警名称对告警进行分组,而将这些告警内聚在一起成为一个通知
告警分组,告警时间,以及告警的接受方式可以通过Alertmanager的配置文件进行配置
抑制(Inhibition)
抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其他告警的机制
例如,当集群不可访问时触发了一次告警,通过配置Alertmanager可以忽略与集群有关的其他所有告警,这样可以避免接收到大量与实际问题无关的告警通知
抑制机制同样通过Alertmanager的配置文件进行设置
静默(Silences)
在一个特定的时间窗口内,接收到告警通知,Alertmanager也不会真正向用户发送告警行为,静默提供了一个简单的机制可以快速根据标签对告警进行静默处理,如果接收到的告警符合静默的配置,则Altermanager就不会发送告警通知
静默设置需要再Altermanager的Web页面上进行设置
告警过程
在Prometheus上定义告警规则生成告警通知
在AlertManager上定义路由规则,将收到的告警通知按需分别进行处理
在AlertManger上定义receiver,他们是能够基于某个媒介接收告警信息的特定用户
- 使用Prometheus Server端通过静态或者动态配置去拉取(pull)被监控主机上的监控指标数据
- 基于
PromQL对这些已经存储在本地存储HDD/SSD的TSDB中的指标定义阈值警报规则(Rules) - Prometheus根据配置的参数周期性的对警报规则进行计算, 如果满足警报条件,生产一条警报信息
- 将报警信息推送到 Alertmanager 组件
- Alertmanager 收到警报信息之后,会对警告信息进行处理,进行分组(Group)并将它们通过定义好的路由(Routing)规则转到正确的接收器(receiver), 比如
Email、Slack、钉钉、企业微信等 - 最终异常事件
Warning、Error通知给定义好的接收人
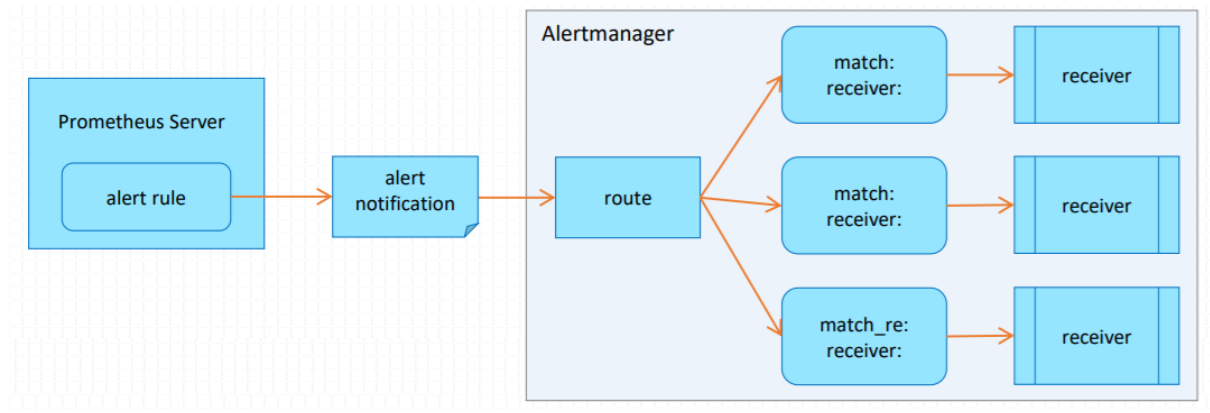
AlertManger部署
- 下载二进制包并解压
[root@server1 ~]# wget https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz[root@server1 ~]# tar -zxvf alertmanager-0.21.0.linux-amd64.tar.gz -C /data/[root@server1 ~]# cd /data/[root@server1 data]# ln -sv alertmanager-0.21.0.linux-amd64 alertmanager[root@server1 data]# chown -R root:root alertmanager-0.21.0.linux-amd64
- 默认配置文件介绍
[root@server1 alertmanager]# vim alertmanager.ymlglobal: # 全局配置模块resolve_timeout: 5m # 用于设置处理超时时间,默认五分钟route: # 路由配置模块group_by: ['alertname'] # 告警分组group_wait: 10s # 10s内收到的同组告警在同一条告警通知中发送出去group_interval: 10s # 同组之间发送告警通知的时间间隔repeat_interval: 1h # 如果指定时间内没有修复,发送重复告警receiver: 'web.hook' # 使用的接收器名称receivers: # 接收器配置模块- name: 'web.hook' # 定义接收器名称webhook_configs: # 设置webhook地址- url: 'http://127.0.0.1:5001/'inhibit_rules: # 告警抑制功能模块- source_match: # 源severity: 'critical' # 当存在源标签告警触发时,含有目标标签的告警就不会触发target_match: # 目标severity: 'warning'equal: ['alertname', 'dev', 'instance'] # 保证该配置下标签内容相同才会被抑制
QQ邮箱告警
- 修改alertmanager配置文件,启动服务
[root@server1 alertmanager]# vim alertmanager.ymlglobal:resolve_timeout: 5msmtp_from: '453048472@qq.com' # 邮件发送方smtp_smarthost: 'smtp.qq.com:465'smtp_auth_username: '453048472@qq.com'smtp_auth_password: 'imimsnfnhxlzbgfa'smtp_require_tls: falsesmtp_hello: 'qq.com'route:group_by: ['alertname']group_wait: 5sgroup_interval: 5srepeat_interval: 5mreceiver: 'email'receivers:- name: 'email'email_configs:- to: '3519713648@qq.com' # 邮件接收方send_resolved: true # 是否故障恢复后发送邮件inhibit_rules:- source_match:severity: 'critical'target_match:severity: 'warning'equal: ['alertname', 'dev', 'instance'][root@server1 alertmanager]# ./alertmanager
- 修改Prometheus配置文件
[root@server1 prometheus]# vim prometheus.ymlglobal:scrape_interval: 15sevaluation_interval: 15salerting: # 告警配置alertmanagers:- static_configs:- targets:- 192.168.31.10:9093 # 配置IP地址rule_files:- "/data/prometheus/rules/*.yml" # 设置规则文件的路径scrape_configs:- job_name: 'prometheus'static_configs:- targets: ['localhost:9090']- job_name: 'node_exporter'static_configs:- targets: ['192.168.31.20:9100']- job_name: 'mysqld_exporter'scrape_interval: 10sstatic_configs:- targets: ['192.168.31.20:9104']- job_name: 'Alertmanager' # 新增一个Alertmanager静态Job配置static_configs:- targets: ['192.168.31.10:9093'] # Alertmanager组件的端口号是9093
- 创建告警规则文件
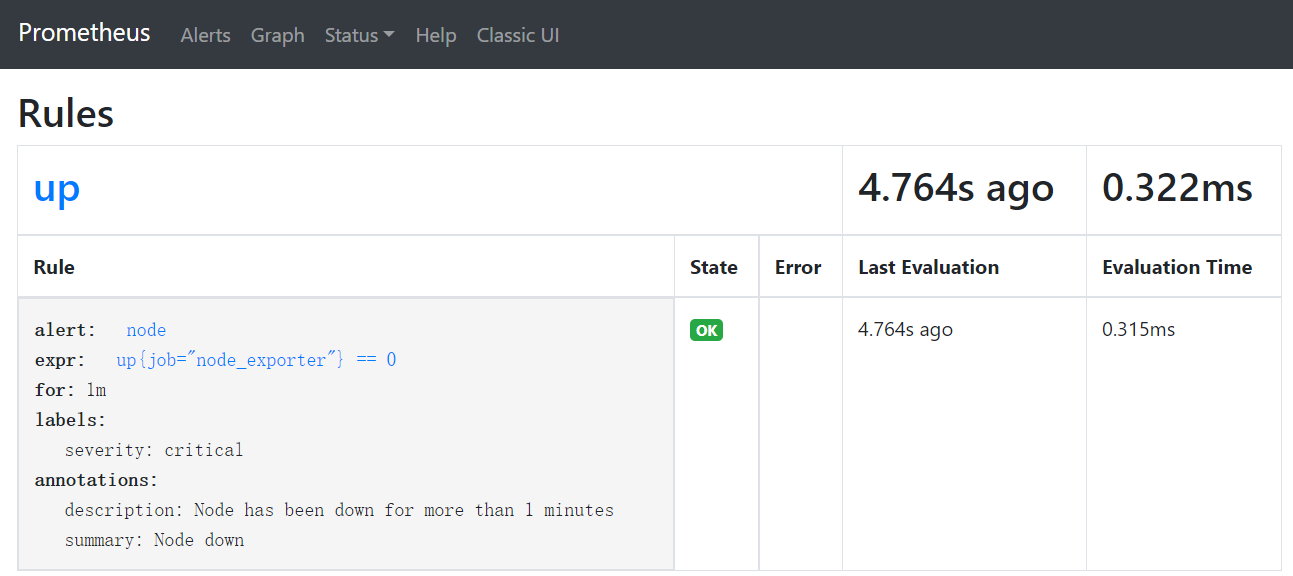
[root@server1 prometheus]# mkdir rules[root@server1 prometheus]# cd rules/[root@server1 rules]# vim rules.ymlgroups:- name: uprules:- alert: node # 警报的名称expr: up{job="node_exporter"} == 0 # 要评估的PromQL表达式for: 1m # 评估等待时间,可选参数,用于表示在触发告警之前expr中表达式必须为true时持续的时间长度labels: # 为每个警报添加或覆盖的标签severity: criticalannotations: # 要添加到每个警报的注释description: "Node has been down for more than 1 minutes"summary: "Node down"
- 启动Prometheus服务
[root@server1 prometheus]# ./prometheus
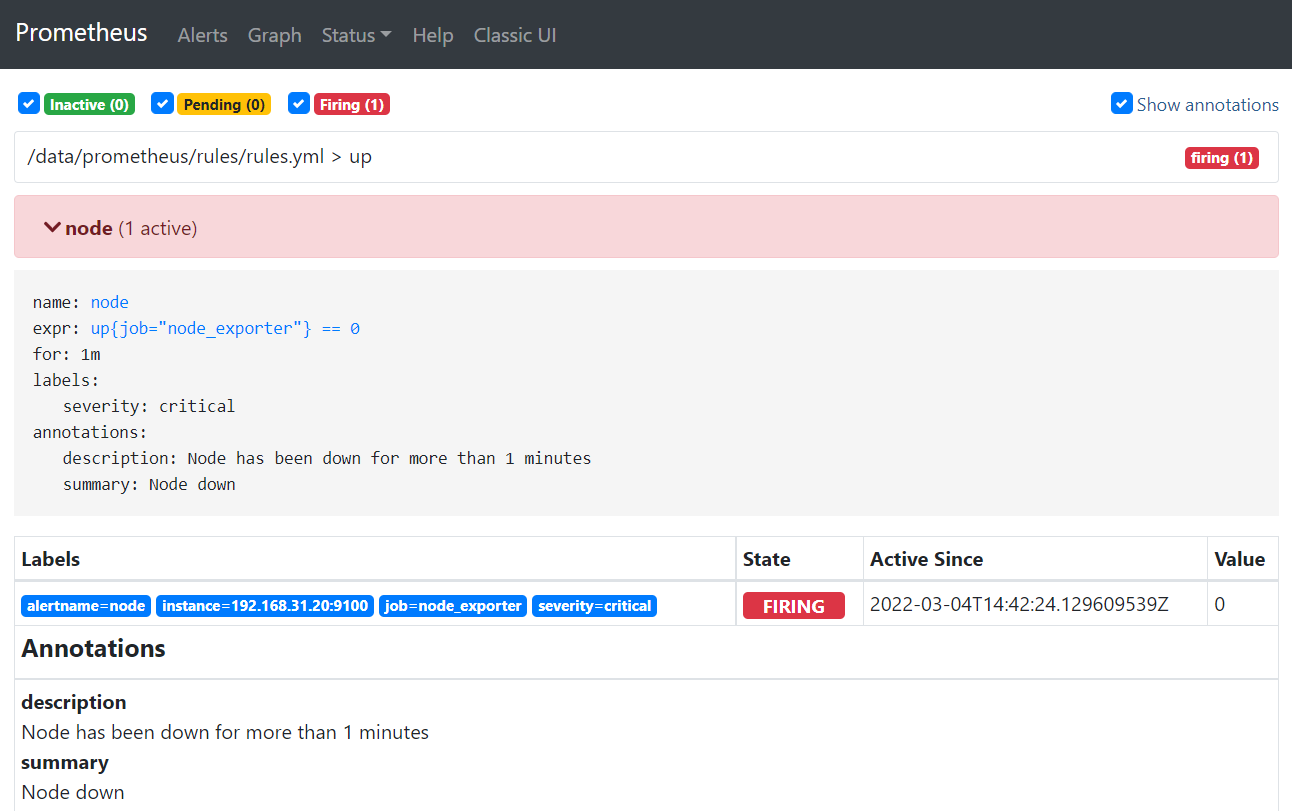
- 进入Web UI界面查看规则
Status >> Rules
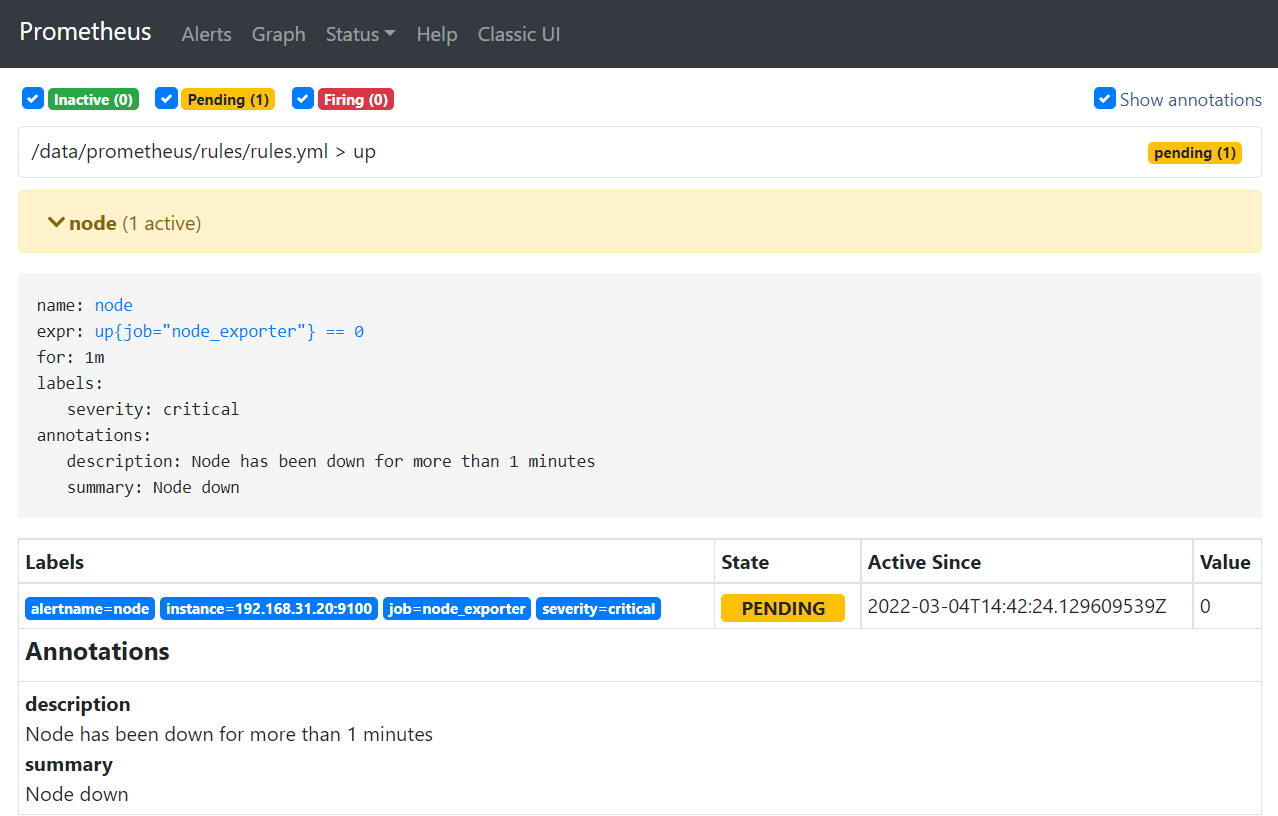
- 然后停止掉192.168.31.20的node_exporter的服务,查看是否进行了QQ邮箱告警
- 在Alter一栏进行查看,反复刷新,会发现状态变化为INACTIVE→ PENDING → FIRING
- INACTIVE:没有满足触发条件,告警未激活状态
- PENDING:已满足触发条件,但未满足告警持续时间的状态
- FIRING:已满足触发条件且已经超过for子句中指定的持续时间时的状态
- 查看QQ邮箱中的信息
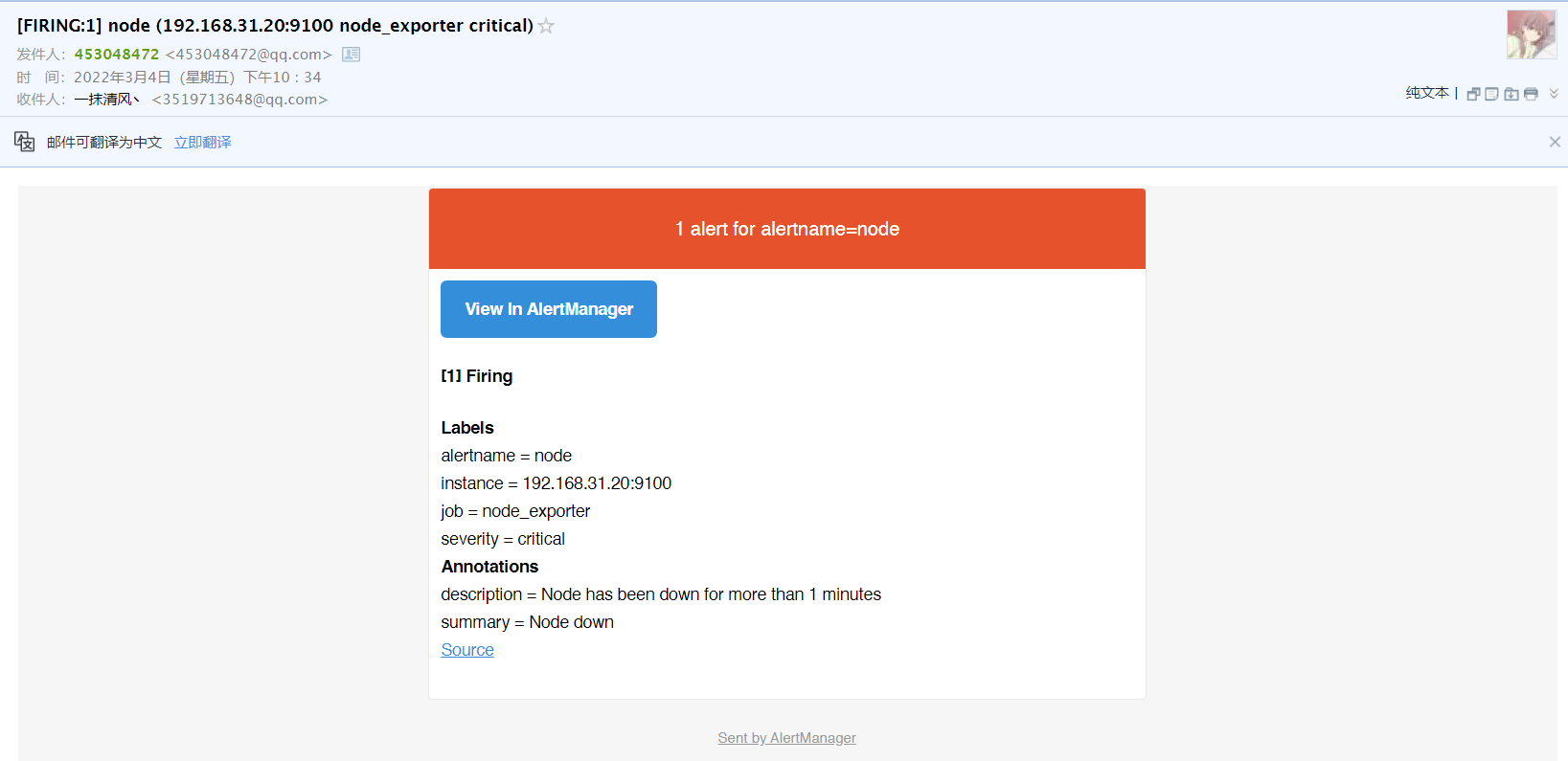
如果故障修复了,还会发送故障已修复的邮件,可以在
alertmanager.yml配置文件中设置

若有收获,就点个赞吧
0 人点赞
