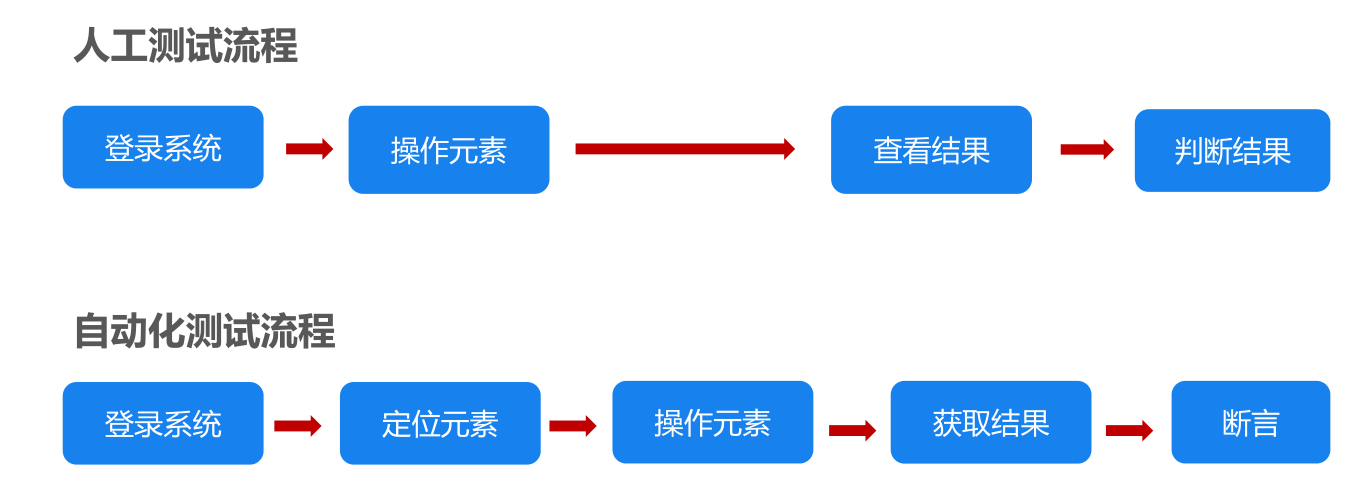
- 第一章 自动化测试基础
- 第二章 自动化环境搭建
- 获取当前页面的URL
- 关闭浏览器
- 2.HTML基础
- 3.元素定位
- 百度搜索框元素
- 搜索按钮元素
- 根据link_text定位到百度新闻超链接,并点击
- 暂停1秒
- 在新闻新闻页面,根据一条新闻链接的部分文本定位,并点击
- 暂停1秒
- 关闭浏览器,quit关闭所有浏览器窗口
- 通过相对路径定位到输入框,并且输入selenium
- // 从当前节点选取
- *:匹配任何标签
- @:选取id属性为kw的节点
- 另一种写法://input[@id=’kw’]
- 暂停2秒
- 关闭浏览器
- 使用[] 通过id属性定位百度首页搜索框,并输入selenium
- 暂停2秒
- 关闭浏览器
- 4.元素操作
- 定位到新闻超链接,再获取元素文本
- 关闭浏览器
- 定位到搜索框,再获取元素尺寸
- 关闭浏览器
- 定位到搜索框,再获取元素属性
- 关闭浏览器
- 定位到搜索框
- 使用submit,代替click
- 关闭浏览器
- 6. 鼠标操作
- 单击click me按钮
- 打印结果区的值
- 定位 dbl click按钮
- 双击
- 打印结果区的值
- 定位right click按钮
- 打印结果区的值
- 添加智能等待
- 进行搜索操作
- 加一个等待,避免页面没有加载完成导致不能拖动
- 将页面滚动条拖动到底部(纵坐标)
- 横坐标可以与纵坐标结合使用
- 将滚动条拖动到最右(横坐标)
- 定位到下拉框
- 再点击选择里面的选项
- 获取当前窗口handle
- 打开一条新闻
- 切换到新闻首页窗口
- 获取所有窗口handle,返回列表
- 切换到最顶层frame
- 在百度搜索框中输入selenium
- 返回默认层
- 切换到中间层frame
- 如果frame没有id/name属性,则通过二次定位解决
- f = driver.find_element_by_xpath(‘/html/frameset/frame[2]’)
- driver.switch_to.frame(f)
- 点击新浪首页中的新闻链接
- 返回默认层
- 设置程序执行入口
- 组织测试用例
- 定义报告的相关参数
- 程序的执行入口
- 第五章 PageObject模型
- 第六章 测试框架开发
- 第七章 测试集成
- 其他
- 定义列表储存需要参数化的数据
- 附注
第一章 自动化测试基础
1. 什么是自动化测试
-
2.自动化测试的目的
用自动化手段替代测试中 重复性 的工作,降低人力成本
- 提高测试用例执行效率,及时反馈项目质量
-
3.什么项目适合自动化测试
需求明确,不会频繁变动
- 系统界面稳定
- 项目周期长
- 需要频繁的进行回归测试
-
4.常见的自动化测试工具
QTP
- 企业级自动化测试工具
- 收费
- 支持脚本录制与回放
- 支持B/S与C/S架构
- Robot Framework
- 基于Python的自动化测试框架
- 支持关键字驱动
- 支持B/S架构
Selenium
开源,免费
- 支持多浏览器:IE、Chrome、Safari、Firefox
- 支持多语言:python、Java、PHP等
-
6. Selenium工具介绍
Selenium1.0
- Selenium IDE:浏览器录制回放插件
- Selenium Grid:分布式执行
- Selenium RC:代理服务器
- Selenium2.0(引入webdriver)
- Selenium 1.0
- webdriver:通过原生浏览器驱动操作浏览器
Selenium3.0(去掉RC)
webdriver和browser driver作为测试脚本和浏览器的传递者,从而达到脚本控制浏览器操作的目的
- Selenium采用 C/S 模式开发,C是webdriver,S是浏览器

8. 自动化测试脚本思路
- 定位页面元素
- 对元素执行操作
- 自动检查结果
第二章 自动化环境搭建
1.安装Python3
- 安装好Python3
-
2.安装Selenium
win+r,打开命令行窗口
使用pip安装Selenium
# 安装Selenium的最新版本pip install selenium# 安装Selenium指定版本pip install selenium==2.53.0# 如果安装失败,尝试使用阿里云的国内源下载pip install -i https://mirrors.aliyun.com/pypi/simple selenium
3.下载webdriver驱动
以chrome浏览器为例
- 查看chrome浏览器版本:在地址栏输入 chrome://version/
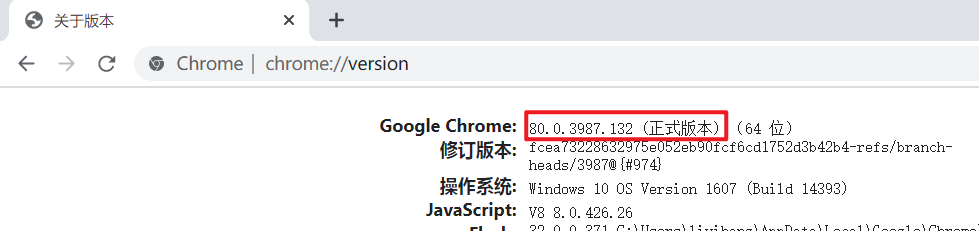
- chromedriver下载地址:http://chromedriver.storage.googleapis.com/index.html
- 淘宝镜像站:http://npm.taobao.org/mirrors/chromedriver/
- 下载与浏览器版本对应的chrome driver
将下载好的chrome driver 解压,并放至到Python安装路径的根目录
4.第一个自动化测试脚本
需求
- 打开浏览器
- 访问百度首页 ```python from selenium import webdriver # 导入webdriver
d = webdriver.Chrome() # 创建浏览器对象 d.get(‘https://www.baidu.com‘) # 调用get方法访问百度首页
d.close() # 关闭浏览器
<a name="6d65d06b"></a>
# 第三章 webdriver API
<a name="7055d21b"></a>
## 1.浏览器操作
<a name="6459f0d3"></a>
### 1.1浏览器最大化
- 在统一的浏览器大小下运行用例,可以提高用例的适用性
```python
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
print('浏览器最大化')
driver.maximize_window()
driver.close()
1.2 设置浏览器宽、高
- 在不同浏览器大小下运行用例,可以对缩放、样式等进行评估 ```python from selenium import webdriver from time import sleep
driver = webdriver.Chrome() driver.get(‘https://www.baidu.com‘)
print(‘设置浏览器宽480,高800显示’) driver.set_window_size(480, 800)
sleep(2) driver.close()
<a name="4ec8f70d"></a>
### 1.3 控制浏览器前进、后退
```python
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
#访问百度首页
driver.get('https://www.baidu.com')
#访问百度新闻
driver.find_element_by_link_text('新闻').click()
#暂停1秒
sleep(1)
#后退到百度首页
driver.back()
#暂停1秒
sleep(1)
#前进到百度新闻
driver.forward()
#暂停1秒
sleep(1)
#关闭浏览器
driver.close()
1.4 关闭浏览器
driver = webdriver.Chrome() driver.get(‘https://www.baidu.com‘)
获取当前页面的URL
url = driver.current_url print(url)
关闭浏览器
driver.close()
```
https://www.baidu.com/
1.7 获取当前title
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
title = driver.title
print(title)
# 关闭浏览器
driver.close()
百度一下,你就知道
1.8 浏览器截图
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
# 截图并保存到当前路径下,名字为s1.png
driver.save_screenshot('s1.png')
# 关闭浏览器
driver.close()
2.HTML基础
2.1 什么是HTML
- HTML:超文本标记语言(Hyper Text Markup Language)
-
2.2 HTML标签
标签由尖括号包围
- 标签是成对出现的
-
2.3 第一个网页
<html> <body> <h1>我的第一个标题</h1> <p>我的第一个段落</p> </body> </html>2.4 元素常见的属性
class:元素的类名
- id:元素的唯一id
-
2.5 常见的标签
<a>:超链接<input>:输入标签,如输入框,按钮等<div>:块级元素,把文档分割为独立的、不同的部分<form>:为用户输入创建HTML表单<img>:图片<iframe>:定义内嵌框架,在一个HTML中嵌入另一个HTML(QQ邮箱)<span>:组合行内元素<html> <body> <h1>我的第一个标题</h1> <p>我的第一个段落</p> <form> 账号 <input type="text" name="uaername"> </br> 密码 <input type="text" name="password"> </form> </body> </html>3.元素定位
元素定位和操作是自动化测试的核心部分
- 一个元素就像一个人,有自己的特征(属性)
- webdriver提供了一系列的元素定位方法,常用的有下面几种: | 定位方法 | 释义 | | —- | —- | | driver.find_element_by_id() | 根据元素id值定位 | | driver.find_element_by_name() | 根据元素name值定位 | | driver.find_element_by_class_name() | 根据元素class值定位 | | driver.find_element_by_tag_name() | 根据元素标签名定位 | | driver.find_element_by_link_text() | 根据超链接文本内容定位 | | driver.find_element_by_partrial_link_text() | 根据超链接的部分文本内容定位 | | driver.find_element_by_xpath() | 根据xpath值定位 | | driver.find_element_by_css_selector() | 根据css值定位 |
3.1 id和name定位
搜索按钮元素
- 根据id定位搜索框,根据name定位到搜索按钮
```python
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
driver.maximize_window()
# 根据id定位到百度搜索框,并输入Selenium
driver.find_element_by_name('wd').send_keys('Selenium')
# 根据name定位到搜索按钮,并点击
driver.find_element_by_id('su').click()
# 暂停2秒
sleep(2)
# 关闭浏览器
driver.close()
3.2 tag name和class name定位
HTML文本
<div id="searchform" class="jhp_big" style="margin-top:-2px">
<form id="tsf" onsubmit="return name="f" method="GET" action="/search">
<input id="kw" class="s_ipt" type="text" name="wd" autocomplete="off">
tag name
- 通过标签名定位
- 不推荐使用,因为HTML文件中有很多同名的标签名,不唯一
<div> find_element_by_tag_name('div')
class name:直接访问百度首页讲解,可以通过class name定位到输入框
class="s_ipt" find_element_by_class_name('s_ipt')
3.3 link text和partial link text定位
- 根据链接文本定位:
driver.find_element_by_link_text('新闻') - 根据链接部分文本定位:
driver.find_element_by_partial_link_text('央视快评') - 根据超链接中的文本内容定位 ```python from selenium import webdriver from time import sleep
driver = webdriver.Chrome() driver.get(‘https://www.baidu.com‘)
根据link_text定位到百度新闻超链接,并点击
driver.find_element_by_link_text(‘新闻’).click()
暂停1秒
sleep(1)
在新闻新闻页面,根据一条新闻链接的部分文本定位,并点击
driver.find_element_by_partial_link_text(‘央视快评’).click()
暂停1秒
sleep(1)
关闭浏览器,quit关闭所有浏览器窗口
driver.quit()
<a name="82df7230"></a>
### 3.4 Xpath定位
- Xpath是一门在XML文档中查找信息的语言
- 常用方法如下:
| 描述 | Xpath |
| --- | --- |
| 直接子元素 | ``**//div/a** |
| 子元素或后代元素 | ``**//div//a** |
| 以id定位元素 | ``**//input[@id="kw"]** |
| 第1个子元素 | ``**//input[@id="kw"]/li[1]** |
| 最后一个子元素 | ``**//input[@id="kw"]/li[last()]** |
| 文本中包含text | ``**//*[contains(text(), 'text')]** |
| name属性以user开头 | ``**//*[starts-with(@name, 'user')]** |
| name属性以user结尾(有可能不支持) | ``**//*[end-with(@name, 'user')]** |
```markdown
• XPath是一种在XML文档中定位元素的语言,有多种可能性
• 语法
• /:从根节点选取(绝对路径)
• //:从当前节点选取,不考虑节点的位置(相对路径)
• .:选取当前节点
• ..:选取当前节点的父节点 搜索框的上两级父节点://*[@id='kw']/../..
• @:选取属性
• 绝对路径定位上面文档中的输入框
• 不推荐使用绝对路径定位
• 难以阅读和维护
• xpath定位元素时,元素没有属性,可以定位他的父节点再定位到他本身
注意:如果一个元素本身没有任何属性值,则可以通过xapth定位到它的父级元素再定位到它自己
案例:
使用绝对路径定位百度首页输入框:/html/body/div/div/div/div/div/form/span/input
使用相对路径定位百度首页输入框://input[@id="kw"]
当子节点有多个同名标签时,可以用[数字]的方法按顺序选取元素://input[@id="kw"]/input[2] (选取百度首页输入框下的第二个input)
百度搜索框://*[@id="form"]/span/input
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
# 通过绝对路径定位到输入框,并且输入selenium
driver.find_element_by_xpath("/html/body/div/div/div/div/div/form/span/input").send_keys('selenium')
# 暂停2秒
sleep(2)
# 关闭浏览器
driver.close()
- 相对路径定位上面文档中的输入框 ```python from selenium import webdriver from time import sleep
driver = webdriver.Chrome() driver.get(‘https://www.baidu.com‘)
通过相对路径定位到输入框,并且输入selenium
// 从当前节点选取
*:匹配任何标签
@:选取id属性为kw的节点
另一种写法://input[@id=’kw’]
driver.find_element_by_xpath(“//*[@id=’kw’]”).send_keys(‘selenium’)
暂停2秒
sleep(2)
关闭浏览器
driver.close()
<a name="b6b148ee"></a>
### 3.5 CSS定位
- 语法
- `#`:元素id属性选取,如 #kw:id为kw的元素
- `.`:元素class属性选取,如 .s_ipt:class值为s_ipt的元素
- `[]`:其他属性选取,如 [id='kw']
- 层级关系选取,如 #form > span:nth-of-type(1) >input
- 第几个span用“span:nth-of-type(n)”表示
- 范例
- `#`:元素id属性选取
```python
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
# 使用# 通过id属性定位到百度首页搜索框,并输入selenium
driver.find_element_by_css_selector("#kw").send_keys('selenium')
# 暂停2秒
sleep(2)
# 关闭浏览器
driver.close()
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
# 使用. 通过class值定位百度首页搜索框,并输入selenium
driver.find_element_by_css_selector(".s_ipt").send_keys('selenium')
# 暂停2秒
sleep(2)
# 关闭浏览器
driver.close()
[]:其他属性选取 ```python from selenium import webdriver from time import sleep
driver = webdriver.Chrome() driver.get(‘https://www.baidu.com‘)
使用[] 通过id属性定位百度首页搜索框,并输入selenium
driver.find_element_by_css_selector(“[id=’kw’]”).send_keys(‘selenium’)
暂停2秒
sleep(2)
关闭浏览器
driver.close()
- 层级关系选取
```python
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
# css层级关系定位
# 首先通过id属性定位到form
# 然后定位form里面的第一个span
# 最后再span的子节点input为最终选取的节点
driver.find_element_by_css_selector("#form > span:nth-of-type(1) >input").send_keys('selenium')
# 暂停2秒
sleep(2)
# 关闭浏览器
driver.close()
3.6 捕获元素定位失败异常
在元素可能定位失败时,为了让代码继续执行,可以捕获异常
from selenium import webdriver
from time import sleep
from selenium.common.exceptions import NoSuchElementException # 需要先导入异常包
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
try:
driver.find_element_by_id('kw123').send_keys('python')
except NoSuchElementException as e:
print('元素定位失败,异常信息是:{}'.format(e))
sleep(2)
driver.quit()
输出信息:
元素定位失败,异常信息是:Message: no such element: Unable to locate element: {"method":"id","selector":"kw123"}
(Session info: chrome=73.0.3683.86)
(Driver info: chromedriver=70.0.3538.97 (d035916fe243477005bc95fe2a5778b8f20b6ae1),platform=Windows NT 10.0.14393 x86_64)
4.元素操作
4.1 输入内容
send_keys()
driver.find_element_by_id('kw').send_keys('selenium')4.2 点击元素
click()
driver.find_element_by_id('kw').click()4.3 清空元素中的内容
clear()
driver.find_element_by_id('kw').clear()4.4 获取元素文本内容
text ```python from selenium import webdriver
driver = webdriver.Chrome() driver.get(‘https://www.baidu.com‘)
定位到新闻超链接,再获取元素文本
text = driver.find_element_by_link_text(“新闻”).text print(text)
关闭浏览器
driver.close()
```
新闻
4.5 获取元素的尺寸
- size ```python from selenium import webdriver
driver = webdriver.Chrome() driver.get(‘https://www.baidu.com‘)
定位到搜索框,再获取元素尺寸
size = driver.find_element_by_css_selector(‘#kw’).size print(size)
关闭浏览器
driver.close()
```
{'height': 22, 'width': 500}
4.6 获取元素属性
- get_attribute() ```python from selenium import webdriver
driver = webdriver.Chrome() driver.get(‘https://www.baidu.com‘)
定位到搜索框,再获取元素属性
attribute = driver.find_element_by_css_selector(‘#kw’).get_attribute(‘type’) print(attribute)
关闭浏览器
driver.close()
```
text
4.7 提交表单
- submit() ```python from selenium import webdriver from time import sleep driver = webdriver.Chrome() driver.get(‘https://www.baidu.com‘)
定位到搜索框
driver.find_element_by_css_selector(‘#kw’).send_keys(‘selenium’)
使用submit,代替click
driver.find_element_by_css_selector(‘#su’).submit()
sleep(2)
关闭浏览器
driver.close()
<a name="765af22c"></a>
## 5.设置等待时间
<a name="ea1b061a"></a>
### 5.1 强制等待
- 导入time模块下的sleep
- 强制让代码等待若干秒
<a name="33b579cd"></a>
### 5.2 隐式等待
- `driver.implicitly_wait()`
- 隐式等待是在等待周期内一直检测元素是否出现,元素出现后则马上继续,如果等待超时就会报错
- 隐式等待只需设置一次即可对整个测试周期生效
- 任何时候都应该加上隐式等待
- 建议设置等待时间:30s内
- 隐式等待缺陷
- 对一些一直存在但值在变化的元素没有意义
- 如网页title
```python
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
# 添加智能等待
driver.implicitly_wait(10)
# 获取当前页面的title
old_title = driver.title
print(old_title)
# 进行搜索操作
driver.find_element_by_css_selector('#kw').send_keys('selenium')
driver.find_element_by_css_selector('#su').click()
# 实验:添加强制等待后再获取新title
#sleep(3)
# 获取搜索界面的title
new_title = driver.title
print(new_title)
if old_title == new_title:
print('智能等待对title失效,title还没有变化')
else:
print('智能等待对title已生效')
driver.close()
5.3 显示等待
5.3.1 title is
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait # 导入webdriverwait类
from selenium.webdriver.support.expected_conditions import title_is
driver = webdriver.Chrome() # 创建浏览器对象
# 创建webdriverwait对象
# 最长超时时间为10s
wait = WebDriverWait(driver, 10)
# 访问百度首页
driver.get('https://www.baidu.com')
# 百度首页的页面标题为:百度一下,你就知道
# 使用title_is判断
title = wait.until(title_is('百度一下,你就知道'))
# 打印title值,true表示页面标题正确,反之不正确
print(title)
# 这部分会抛出timeout异常
# 因为10s后,页面标题还是百度一下,你就知道
# 注意是用的until_not
title2 = wait.until_not(title_is('百度一下,你就知道'))
print(title2)
driver.quit()
5.3.2 百度搜索-显示等待
from selenium import webdriver
from time import sleep
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()
driver.find_element_by_id("kw").send_keys("python")
driver.find_element_by_id("su").click()
sleep(0.5)
# x = '//div[@id="2"]/h3/a' # Python百度百科的元素xpath值
x = '//div[@id=2]//a' # Python百度百科的元素xpath值
# 等待 Python百度百科 这个元素出现 显示等待
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.XPATH, x)))
# 元素出现后再点击
driver.find_element_by_xpath(x).click()
sleep(3)
driver.quit()
6. 鼠标操作
鼠标点击
- 单击:click()
- 双击:double_click()
- 右击:context_click() ```python from selenium import webdriver from time import sleep from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome() driver.get(“http://sahitest.com/demo/clicks.htm“) driver.maximize_window()
单击click me按钮
driver.find_element_by_xpath(“//input[@value=’click me’]”).click()
打印结果区的值
print(driver.find_element_by_name(‘t2’).get_attribute(‘value’))
定位 dbl click按钮
dbl_click = driver.find_element_by_xpath(“//input[@value=’dbl click me’]”)
双击
ActionChains(driver).double_click(dbl_click).perform()
打印结果区的值
print(driver.find_element_by_name(‘t2’).get_attribute(‘value’))
定位right click按钮
right_click = driver.find_element_by_xpath(“//input[@value=’right click me’]”) ActionChains(driver).context_click(right_click).perform()
打印结果区的值
print(driver.find_element_by_name(‘t2’).get_attribute(‘value’))
sleep(0.5) driver.quit()
**鼠标悬浮 **
```python
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
driver.get("http://sahitest.com/demo/mouseover.htm")
driver.maximize_window()
# 定位鼠标悬浮监测按钮
woh = driver.find_element_by_name('b1')
# 鼠标悬浮到按钮上
ActionChains(driver).move_to_element(woh).perform()
# 打印结果区的值
print(driver.find_element_by_name('t1').get_attribute('value'))
sleep(0.5)
driver.quit()
鼠标拖拽
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
driver.get("http://sahitest.com/demo/dragDropMooTools.htm")
driver.maximize_window()
# 定位drag me
drag_me = driver.find_element_by_id('dragger')
# 定位item1
item1 = driver.find_element_by_xpath('/html/body/div[2]')
# 将drag me 拖拽到item1
ActionChains(driver).drag_and_drop(drag_me, item1).perform()
sleep(0.5) # 注意等待一下再看看拖拽是否成功
# 查看是否拖拽成功
print(item1.text)
sleep(0.5)
driver.quit()
7. 键盘操作
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
# driver.get("http://sahitest.com/demo/clicks.htm")
# driver.get("http://sahitest.com/demo/mouseover.htm")
# driver.get("http://sahitest.com/demo/dragDropMooTools.htm")
driver.get("http://sahitest.com/demo/label.htm")
driver.maximize_window()
# 定位第一个用户名输入框
username1 = driver.find_element_by_xpath('/html/body/label[1]/input')
# 定位第二个用户名输入框
username2 = driver.find_element_by_xpath('/html/body/label[2]/table/tbody/tr/td[2]/input')
action = ActionChains(driver) # 实例化
username1.click() # 点击username1
action.send_keys('test keys').perform() # 输入值
# 模拟按键ctrl+a
action.key_down(Keys.CONTROL).send_keys('a').key_up(Keys.CONTROL).perform()
# 模拟按键ctrl+c
action.key_down(Keys.CONTROL).send_keys('c').key_up(Keys.CONTROL).perform()
# 在username2模拟按键ctrl+v
action.key_down(Keys.CONTROL, username2).send_keys('v').key_up(Keys.CONTROL).perform()
# 检验结果
print(username2.get_attribute('value'))
sleep(0.5)
driver.quit()
8 .浏览器控制滚动条
- 阅读用户协议等页面时,通过滚动条是否拉到最下方判断用户阅读情况
- 需要操作的元素不在视觉范围内,需要拖动滚动条 ```python from selenium import webdriver from time import sleep
driver = webdriver.Chrome() driver.get(‘https://www.baidu.com‘)
添加智能等待
driver.implicitly_wait(10)
进行搜索操作
driver.find_element_by_css_selector(‘#kw’).send_keys(‘selenium’) driver.find_element_by_css_selector(‘#su’).click()
加一个等待,避免页面没有加载完成导致不能拖动
sleep(1)
将页面滚动条拖动到底部(纵坐标)
js = ‘window.scrollTo(0,10000)’ driver.execute_script(js)
横坐标可以与纵坐标结合使用
sleep(1)
将滚动条拖动到最右(横坐标)
js2 = ‘window.scrollTo(10000,0)’ driver.execute_script(js2)
sleep(2)
driver.quit()
<a name="506ec997"></a>
## 9.下拉框操作
- 下拉框源码
```html
<html>
<body>
<select id='kw'>
<option value='1'>湖南</option>
<option value='2'>广东</option>
<option value='3'>湖北</option>
</body>
</html>
9.1 使用二次定位
- 先定位到下拉框,再点击里面的选项 ```python from selenium import webdriver from time import sleep import os
driver = webdriver.Chrome() file_path = ‘file:///‘ + os.path.abspath(‘下拉框.html’) driver.get(file_path)
sleep(2)
定位到下拉框
m = driver.find_element_by_id(‘kw’)
再点击选择里面的选项
m.find_element_by_xpath(“//option[@value=’2’]”).click()
sleep(3)
driver.quit()
<a name="d395d2ec"></a>
### 9.2 使用Select库
- 导入selenium自带的select库
- 再通过索引、值、文本等定位下拉框选项
```python
from selenium import webdriver
from time import sleep
import os
from selenium.webdriver.support.select import Select # 导入select
driver = webdriver.Chrome()
file_path = 'file:///' + os.path.abspath('下拉框.html')
driver.get(file_path)
sleep(2)
# 定位到下拉框
m = driver.find_element_by_id('ShippingMethod')
# 使用select库选择
#Select(m).select_by_index(2) # 根据索引选择,注意索引从0开始
#Select(m).select_by_value("7.45") # 根据value值选择
Select(m).select_by_visible_text('UPS Ground ==> $8.34') # 根据标签文本选择
sleep(3)
driver.quit()
10. 多窗口处理
- 根据窗口的handle值进行切换
- 获取当前窗口:
driver.current_window_handle - 切换到指定窗口:
driver.switch_to.window() - 获取所有窗口:
driver.window_handles```python from selenium import webdriver from time import sleep
driver = webdriver.Chrome() driver.get(‘https://news.baidu.com‘) driver.implicitly_wait(20)
获取当前窗口handle
shouye_handle = driver.current_window_handle print(‘新闻首页窗口的handle是:{}’.format(shouye_handle))
打开一条新闻
driver.find_element_by_partial_link_text(‘创新是’).click()
sleep(3)
切换到新闻首页窗口
driver.switch_to.window(shouye_handle)
获取所有窗口handle,返回列表
all_handle = driver.window_handles print(‘所有窗口的handle是:{}’.format(all_handle))
sleep(2)
driver.quit()
<a name="91b8dfd1"></a>
## 11. 弹框处理
- 弹框源码(test目录中alert.html)
- 点击弹框中的确定:`driver.switch_to.alert.accept()`
- 点击弹框中的取消:`driver.switch_to.alert.dismiss()`
- 弹框中输入文本:`driver.switch_to.alert.send_keys('xiaoming')`
- 获取弹框中的文本:`driver.switch_to.alert.text`
```python
from selenium import webdriver
from time import sleep
import os
driver = webdriver.Chrome()
file_path = 'file:///' + os.path.abspath('alert.html')
driver.get(file_path)
# 点击第三种弹框
driver.find_element_by_id('b3').click()
sleep(1)
# 点击弹框中的确定
driver.switch_to.alert.accept()
sleep(1)
# 点击第三种弹框
driver.find_element_by_id('b3').click()
sleep(1)
# 点击弹框中的取消
driver.switch_to.alert.dismiss()
# 点击第二种弹框
driver.find_element_by_id('b2').click()
sleep(1)
# 在弹框中输入xiaoming
driver.switch_to.alert.send_keys('xiaoming')
sleep(2)
# 点击确定
driver.switch_to.alert.accept()
sleep(2) # 输入小明后,有一句提示语
driver.switch_to.alert.accept()
# 点击第三种弹框
driver.find_element_by_id('b3').click()
print(driver.switch_to.alert.text)
sleep(2)
driver.quit()
12. 框架切换
- 通过frame中的id/name切换:driver.switch_to.frame()
- 返回默认框架:driver.switch_to.default_content()
```python from selenium import webdriver from time import sleep driver = webdriver.Chrome() file_path = ‘file:///C:/Users/%E6%9D%8E%E4%B8%80%E6%9D%AD/Desktop/frame.html’ driver.get(file_path) driver.implicitly_wait(20)<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>窗口切换</title> </head> <frameset rows="50%,50%" ,border="0" scrolling="no" noresize="noresize"> <frame src="https://www.baidu.com/" name="top" noresize="noresize" /> <frame src="https://www.taobao.com/" name="bottom" /> </frameset> </frameset> </html>
切换到最顶层frame
driver.switch_to.frame(‘top’)
在百度搜索框中输入selenium
driver.find_element_by_id(‘kw’).send_keys(‘selenium’)
返回默认层
driver.switch_to.default_content()
切换到中间层frame
driver.switch_to.frame(‘body’)
如果frame没有id/name属性,则通过二次定位解决
f = driver.find_element_by_xpath(‘/html/frameset/frame[2]’)
driver.switch_to.frame(f)
点击新浪首页中的新闻链接
driver.find_element_by_link_text(‘新闻’).click()
sleep(2)
返回默认层
driver.switch_to.default_content()
driver.quit()
```python
# QQ登录
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("https://mail.qq.com") #/cgi-bin/loginpage
driver.implicitly_wait(30)
# 切换到登录frame
driver.switch_to.frame('login_frame')
# 切换到账号密码登录
driver.find_element_by_id('switcher_plogin').click()
# 输入用户名
driver.find_element_by_id('u').send_keys('630746762')
# 输入密码
driver.find_element_by_id('p').send_keys('xxxxxxx')
# 点击登录
driver.find_element_by_id('login_button').click()
sleep(2)
driver.quit()
13. 异常截图
假设在元素定位过程中出现异常,则可以对整个页面进行截图保存
示例代码:
from selenium import webdriver
import time
from selenium.common.exceptions import NoSuchElementException # 需要先导入异常包
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
driver.maximize_window()
try:
driver.find_element_by_id('kw123').send_keys('python')
except NoSuchElementException as e:
print('元素定位失败,异常信息是:{}'.format(e))
ctime = time.strftime('%Y-%m-%d_%H-%M-%S')
pic_name = ctime + '.png'
driver.save_screenshot(pic_name)
time.sleep(2)
driver.quit()
14. 单选框与复选框
单选框与复选框都可以直接定位到该元素,然后点击即可。
但是,有一种情况是,要勾选所有复选框,这时候要用到定位到一组元素然后再点击的方法。
「HTML源码」
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<html>
<head><title>单选复选框</title></head>
<body>
<table align="center" width="500" border="0" cellpadding="2" cellspacing="0">
<caption align="center"><h2>单选复选框</h2></caption>
<form action="server.php" method="post">
<tr>
<th>姓名:</th>
<td><input type="text" name="username" sixe="20"></td>
</tr>
<tr>
<th>性别:</th>
<td><input type="radio" id="boy" name="sex" value="1" checked>男
<input type="radio" id="girl" name="sex" value="2">女
<input type="radio" id="secret" name="sex" value="0">保密</td>
</tr>
<tr>
<th>学历:</th>
<td>
<select name="edu">
<option>--请选择--</option>
<option value="1">高中</option>
<option value="2">大专</option>
<option value="3">本科</option>
<option value="4">研究生</option>
<option value="5">其他</option>
</select>
</td>
</tr>
<tr>
<th>选修课程:</th>
<td>
<input type="checkbox" id="linux" name="course[]" value="4">Linux
<input type="checkbox" id="ios" name="course[]" value="5">IOS
<input type="checkbox" id="php" name="course[]" value="6">PHP
<input type="checkbox" id="java" name="course[]" value="7">JAVA
</td>
</tr>
<tr>
<th>自我评价:</th>
<td>
<textarea name="eval" rows="4" cols="40"></textarea>
</td>
</tr>
<tr>
<td colspan="2" align="center">
<input type="submit" name="submit" value="提交">
<input type="reset" name"reset" value="重置">
</td>
</tr>
</form>
</table>
</body>
</html>
「脚本」
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('file:///C:/Users/Alex/Desktop/checkbox.html')
# 先使用find elements定位到一组元素
# 注意:elements是复数形式
checkboxs = driver.find_elements_by_xpath('//input[@type="checkbox"]')
# 然后使用循环去点击每个复选框
for i in checkboxs:
i.click()
# 点击复选框后,可以定位到该元素,然后使用is selected查看该元素是否被勾选了
# 被勾选返回True,没有勾选返回False
print(driver.find_element_by_id('linux').is_selected())
sleep(2)
driver.quit()
15. cookie登录
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('http://localhost:82/ecshop')
# 先登录一遍获取到cookies
# driver.find_element_by_name('username').send_keys('selenium')
# driver.find_element_by_name('password').send_keys('123456')
# driver.find_element_by_name('submit').click()
# cookies = driver.get_cookies()
# print(cookies)
'''
[{'domain': 'localhost', 'expiry': 1586873436.521795, 'httpOnly': False, 'name': 'ECS[visit_times]',
'path': '/', 'secure': False, 'value': '1'},
{'domain': 'localhost', 'httpOnly': False, 'name': 'ECS_ID', 'path': '/',
'secure': False, 'value': '381a1835a459356c1042096bd4b9b47ea184d01c'}]
'''
# 定义好cookie格式
cookie = {'domain': 'localhost', 'httpOnly': False, 'name': 'ECS_ID', 'path': '/',
'secure': False, 'value': '381a1835a459356c1042096bd4b9b47ea184d01c'}
driver.add_cookie(cookie) # 添加cookie
sleep(1)
driver.refresh() # 刷新页面即可看到已登录成功
sleep(2)
driver.quit()
16. 文件上传
input上传
input标签type属性为file,可以直接使用send_keys上传
文件上传HTML范例如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>File Upload</title>
</head>
<body>
<h3>文件上传</h3>
<input type="file" name="file">
</body>
</html>
selenium代码
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("file:///E:/chandao_po/demo/file_upload.html")
driver.find_element_by_name('file').send_keys(r"E:\chandao_po\demo\keys.py")
sleep(1)
driver.quit()
Autoit上传
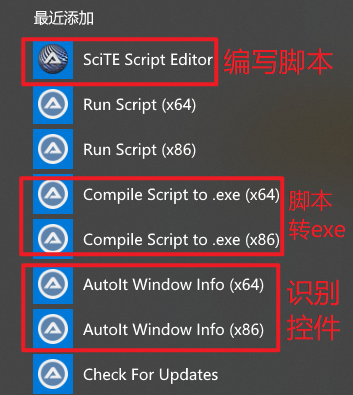
- 打开windows info 抓取文件选择框控件信息
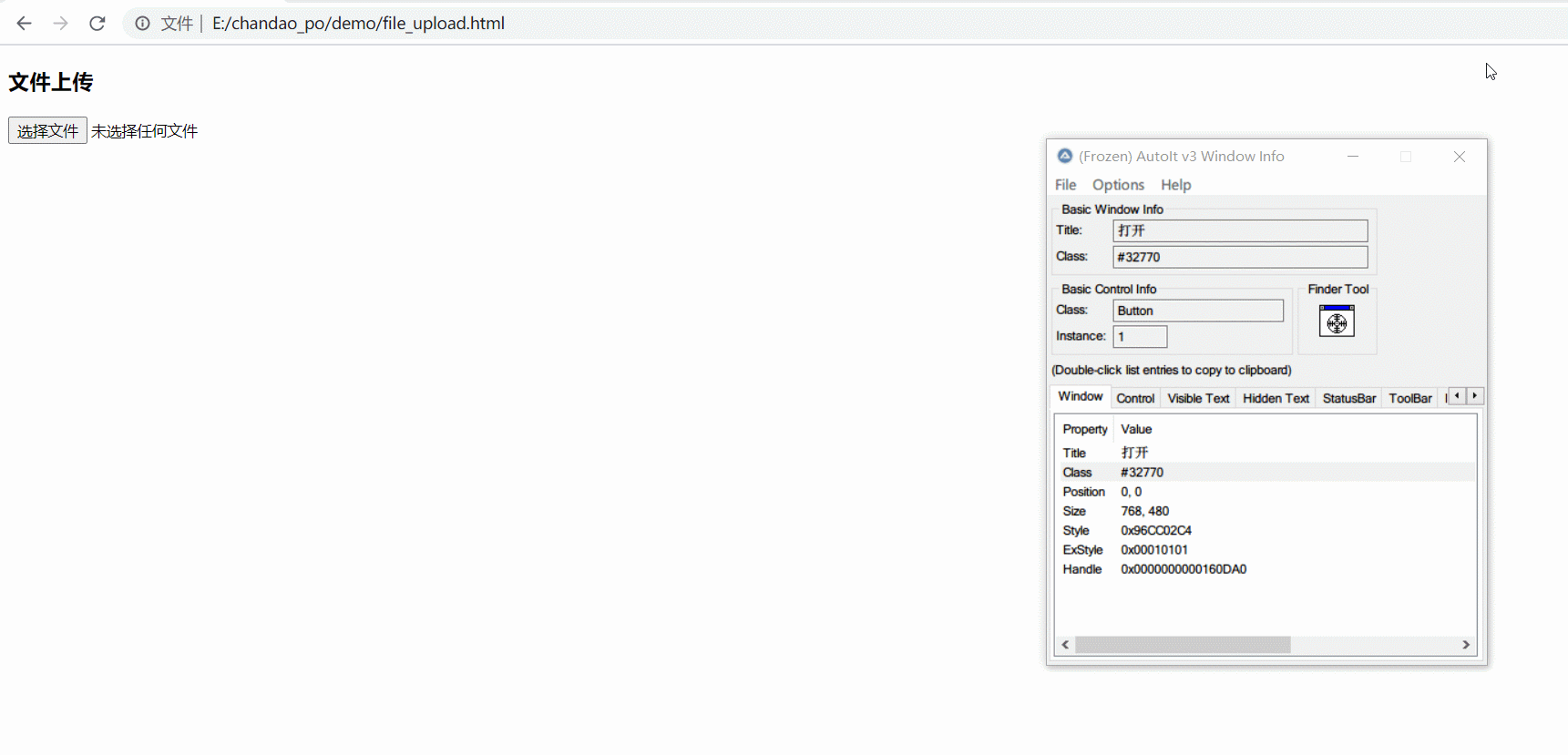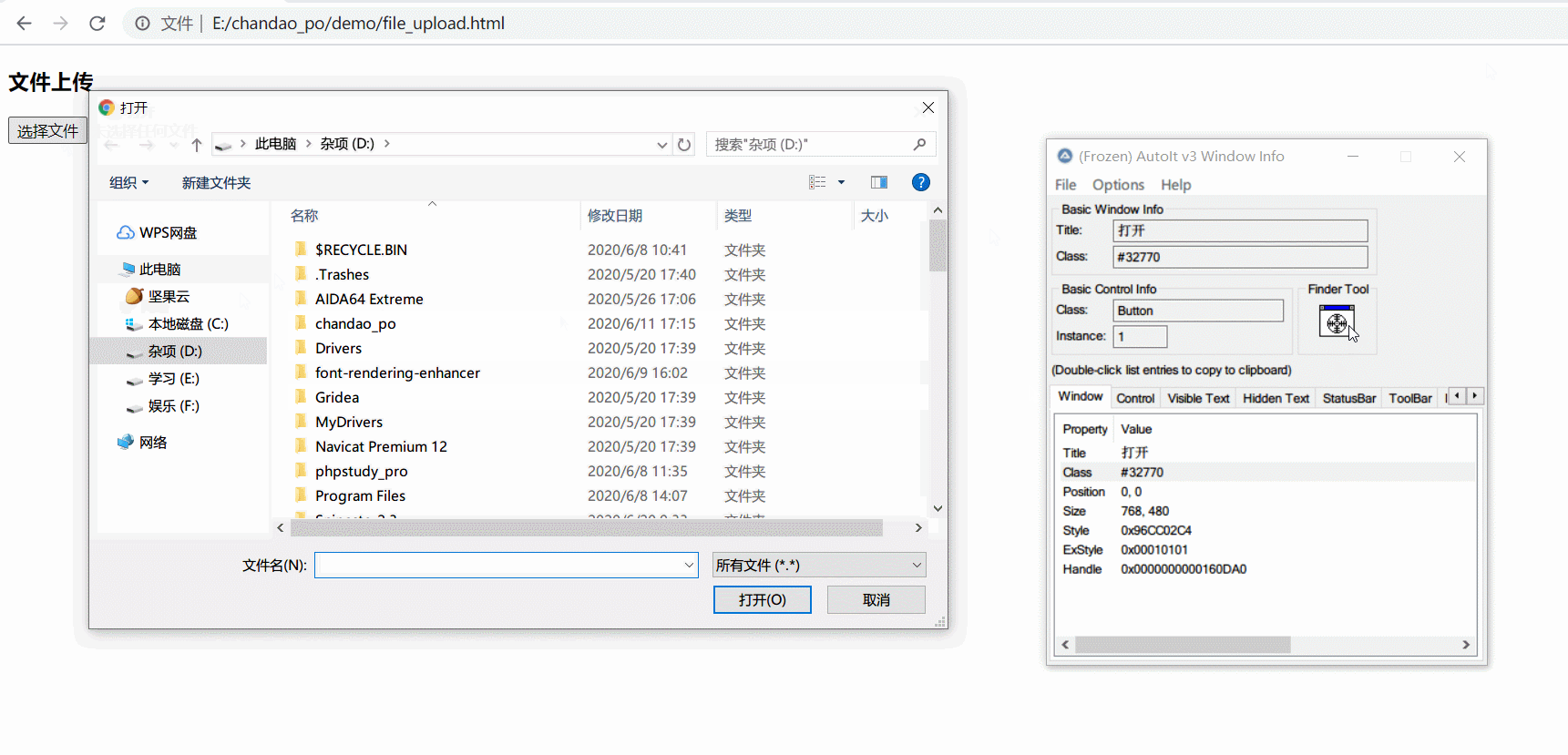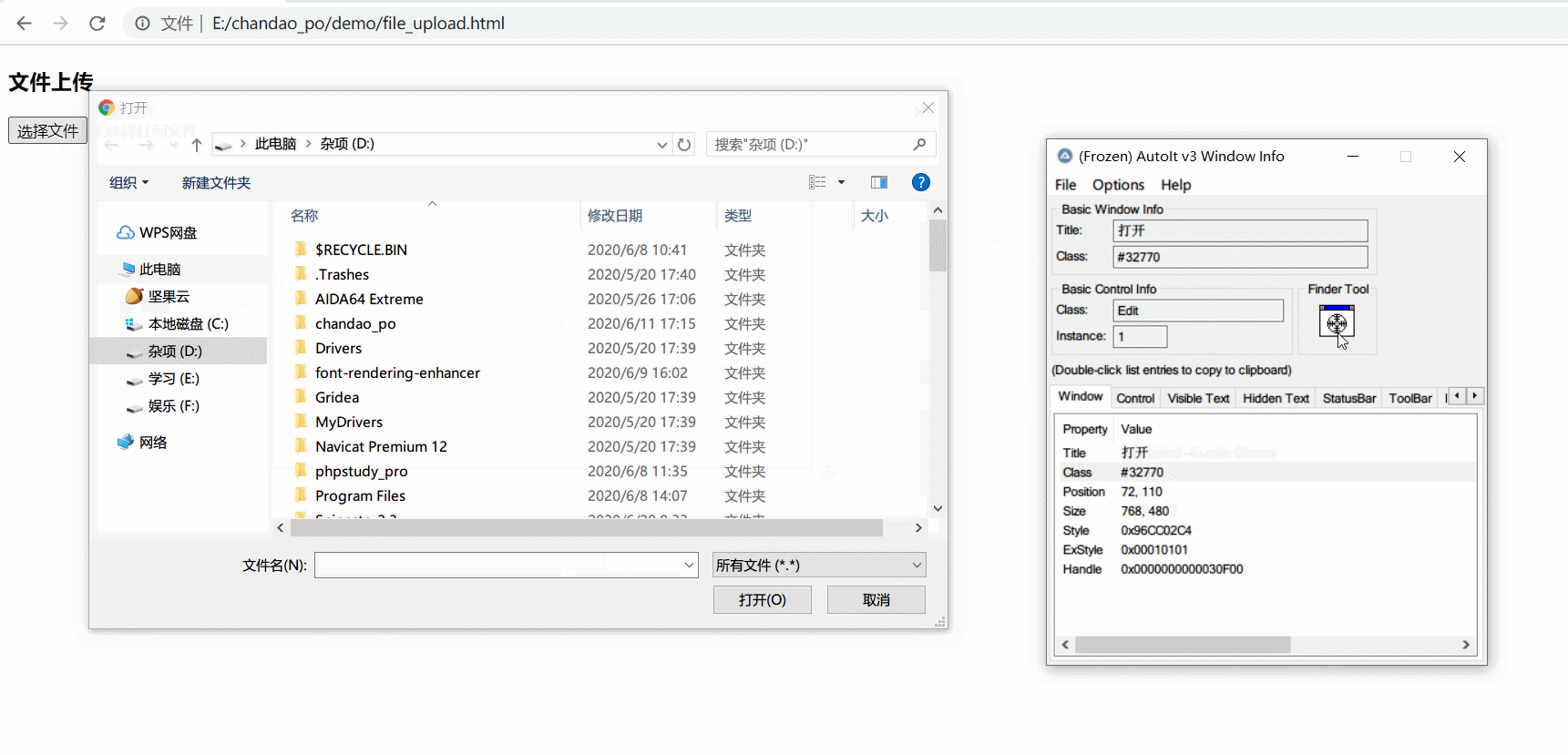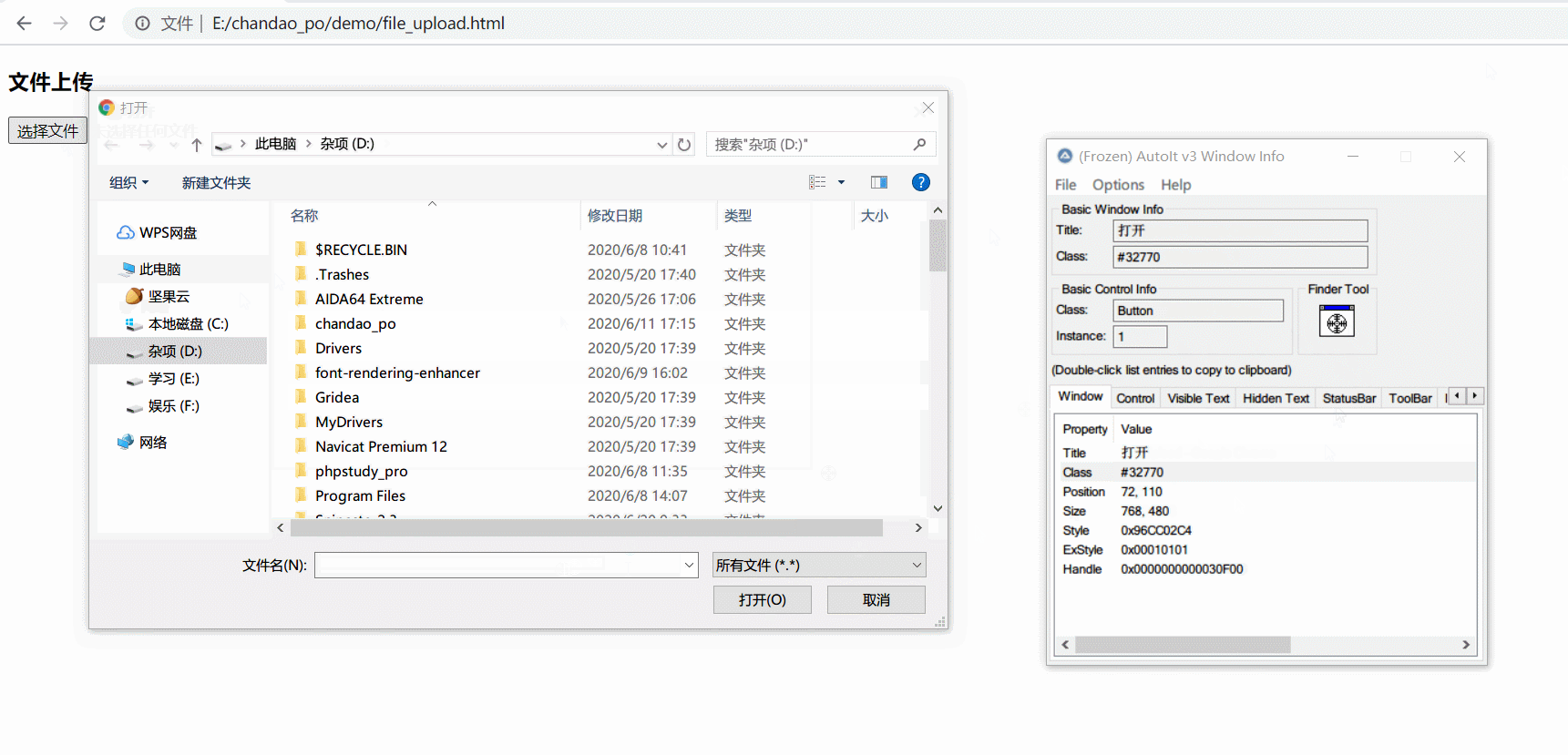
编写autoit脚本
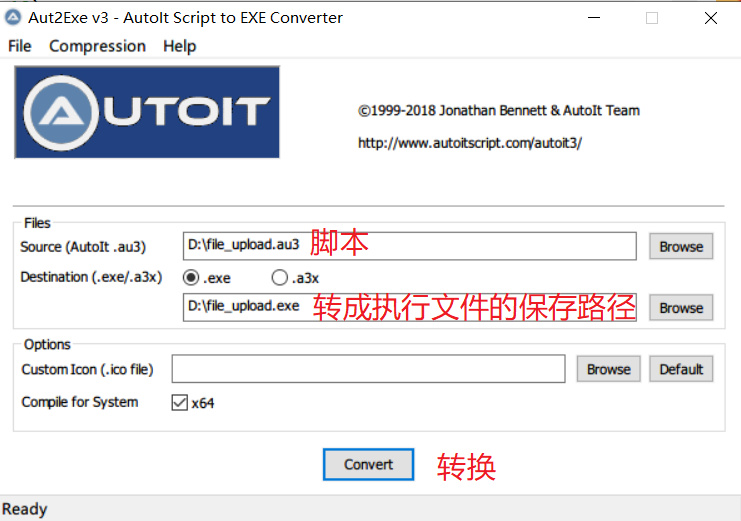
ControlFocus("打开", "","Edit1") WinWait("[CLASS:#32770]","",10) ControlSetText("打开", "", "Edit1","D:\test.txt") Sleep(2000) ControlClick("打开", "","Button1");将脚本转成可执行文件
- 在脚本中调用 ```python from selenium import webdriver from time import sleep import os from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome() driver.get(“file:///E:/chandao_po/demo/file_upload.html”) driver.implicitly_wait(30)
fp = driver.find_element_by_xpath(“//input[@name=’file’]”) ActionChains(driver).click(fp).perform() sleep(1) os.system(r”D:\file_upload.exe”) # 调用使用autoit生成的可执行文件
sleep(1) driver.quit()
<a name="Mnx0m"></a>
# 第四章 unittest 单元测试框架
<a name="cef8fccf"></a>
## 1.为什么用unittest
- 通过unittest来组织测试用例
- 方便用例的管理与维护
- 为测试报告提供数据
<a name="160d2581"></a>
## 2.使用unittest步骤
- 注意:在命名测试文件时,不要使用selenium、unittest等和模块名相同的名字,否则会出现导入模块不存在等错误
- `F`:表示有用例失败(断言没有通过等)
- `E`:表示有用例没有成功执行(用例代码错误)
```python
import unittest # 导入unittest
from selenium import webdriver
from time import sleep
class SearchBaidu(unittest.TestCase): # 定义测试类,继承unittest.TestCase
'''百度首页搜索框测试'''
# 测试之前初始化
def setUp(self):
# 这里可以定义打开浏览器,访问网址,设置等待等初始化动作
self.driver = webdriver.Chrome()
self.driver.get('https://www.baidu.com')
self.driver.maximize_window()
self.driver.implicitly_wait(10)
# 定义测试结束后的动作
def tearDown(self):
# 关闭浏览器,恢复测试数据等操作
sleep(2)
self.driver.quit()
# 编写测试用例
# 测试类中可以写多个测试用例
# 用例名必须以test开头
# 需要用例按顺序执行时,给用例进行编号
def test_01_search_success(self):
self.driver.find_element_by_id('kw').send_keys('Python')
self.driver.find_element_by_id('su').click()
# 设置程序执行入口
if __name__ == '__main__':
unittest.main(verbosity=2)
# verbosity表示测试结果的详细程度,默认为verbosity=1l
# 0:(静默模式) 用例总数和结果
# 1:(默认模式) 成功用例用.表示,失败用F表示
# 2:(详细模式) 显示每个用例的所有相关信息
3.断言
- 断言用于判断用例是否执行成功
- 常见的断言方法有:
- self.assertEqual(a,b) # 断言a是否与b相等
- self.assertNotEqual(a,b) # 断言a与b不相等
- self.assertIn(a,b) # 断言a在b中
- self.assertNotIn(a,b) # 断言a不在b中
- self.assertIs(a,b) # 断言a是b
- self.assertIsNot(a,b) # 断言a不是b
- self.assertTrue(a) # 断言a为真
- self.assertFalse(a) # 断言a为假 ```python import unittest # 导入unittest from selenium import webdriver from time import sleep
class SearchBaidu(unittest.TestCase): # 定义测试类,继承unittest.TestCase ‘’’百度首页搜索框测试’’’
# 测试之前初始化
def setUp(self):
# 这里可以定义打开浏览器,访问网址,设置等待等初始化动作
self.driver = webdriver.Chrome()
self.driver.get('https://www.baidu.com')
#self.driver.maximize_window()
self.driver.implicitly_wait(10)
# 定义测试结束后的动作
def tearDown(self):
# 关闭浏览器,恢复测试数据等操作
sleep(2)
#self.driver.quit()
# 编写测试用例
# 测试类中可以写多个测试用例
# 用例名必须以test开头
# 需要用例按顺序执行时,给用例进行编号
def test_01_search_success(self):
self.driver.find_element_by_id('kw').send_keys('python')
self.driver.find_element_by_id('su').click()
sleep(2)
# 等待页面加载完成以后,获取当前title
new_title = self.driver.title
# 拿当前title与预期title比较,相同即用例执行成功
self.assertEqual('python_百度搜索', new_title)
设置程序执行入口
if name == ‘main‘: unittest.main()
<a name="47dc62f9"></a>
## 4.测试报告
<a name="94eeef60"></a>
### 4.1 BeautifulReport
- 下载BeautifulReport
- 将BeautifulReport放至site-package目录下
- 进入该目录,在命令行中执行本地安装命令:python setup.py install
<a name="qn7ft"></a>
### 4.2 run.py
- 组织,执行用例脚本
- 只需将脚本存放在指定目录,即可一键批量执行
1)完整版
```python
import os
import unittest
import time
from BeautifulReport import BeautifulReport as BF
# 获取当前文件的路径
#cur_path = os.path.dirname(os.path.realpath(__file__))
cur_path = os.getcwd()
# 加载测试用例
def addCase(caseName='case',rule='test*.py'):
'''加载case文件夹里里面所有以test开头的测试用例文件'''
# 定义用例存放目录
case_path = os.path.join(cur_path, caseName)
print('测试用例的路径为:' + case_path)
# 如果用例存放目录不存在就新建该目录
if not os.path.exists(case_path):os.mkdir(case_path)
# 组织case下的所有用例。以test开头,参数填用例路径,规则以test开头的文件
all_case = unittest.defaultTestLoader.discover(case_path, pattern=rule)
return all_case
# 执行测试用例
def runCase(all_case, reportName='\\report'):
cur_time = time.strftime('%Y-%m-%d_%H%M%S') # 获取当前时间并格式化输出时间
report_file_name = os.path.join(cur_time + 'report.html') # 定义报告的文件名
report_path = os.path.join(cur_path + reportName ) # 定义测试报告存放的路径
print('测试报告的路径为:' + report_path )
if not os.path.exists(report_path):os.mkdir(report_path) # 如果report文件夹不存在就创建该文件夹
runner = BF(all_case)
runner.report(filename=report_file_name,description='百度自动化测试报告',log_path=report_path)
if __name__ == "__main__":
all_case = addCase()
runCase(all_case)
2)精简版
- 获取时间戳组织文件名时千万不能用冒号!!! ```python from BeautifulReport import BeautifulReport import unittest import time
current_time = time.strftime(‘%Y-%m-%d-%H%M%S’) # 获取当前时间 report_name = current_time + ‘-report.html’ # 定义测试报告名字
组织测试用例
test_suite = unittest.defaultTestLoader.discover(‘./case’, pattern=’test*.py’) runner = BeautifulReport(test_suite) # 调用beautifulreportru
定义报告的相关参数
runner.report(filename=report_name, description=’百度搜索框自动化测试报告’, log_path=’./report’)
程序的执行入口
if name == “main“: unittest.main()
<a name="df0f4f01"></a>
## 5.classmethod
> unittest中的setUp在每个case执行之前都会执行一次,一般写入一些用例准备工作,如打开浏览器等等,这样有效减少了代码量,但是浪费了时间。
> 那么,如何只打开一次浏览器就能执行所有用例呢?
- setUp:每个case运行前都会执行
- setUpcClass:必须使用`@classmethod装饰器`,所有case运行前只执行一次
- tearDown:每个case运行后都会执行
- tearDwonClass:必须使用`@classmethod装饰器`,所有case运行后只执行一次
示例代码:
```python
import unittest
class Test(unittest.TestCase):
@classmethod # 注意要使用classmethod装饰
def setUpClass(cls):
print('开始初始化')
@classmethod # 注意要使用classmethod装饰
def tearDownClass(cls):
print('结束咯')
def test_01(self):
print('第一条用例')
def test_02(self):
print('第二条用例')
if __name__=='__main__':
unittest.main()
执行结果:
..
开始初始化
----------------------------------------------------------------------
第一条用例
第二条用例
Ran 2 tests in 0.000s
结束咯
OK
6.跳过用例
当用例有变动或者项目有变动导致一部分用例无法执行时,需要暂时跳过执行这些用例
跳过用例需要使用到skip装饰器
以下是skip装饰器详情:
@unittest.skip(reason):无条件跳过用例,reason说明原因@unittest.skipIf(conditon, reason):在condition为True时跳过用例,reason说明原因@unittest.skipUnless(conditon, reason):在condition为False时跳过用例,reason说明原因@unittest.expectedFailuere:断言失败时跳过
示例代码:
import unittest
class Test(unittest.TestCase):
@unittest.skip('无条件跳过该用例')
def test_01(self):
print('第一条用例')
def test_02(self):
print('第二条用例')
@unittest.skipIf(True, 'condition为True时跳过')
def test_03(self):
print('第三条用例')
@unittest.skipUnless(False, 'condition为FALSE时跳过')
def test_04(self):
print('第四条用例')
@unittest.expectedFailure # 断言失败时跳过
def test_05(self):
print('第五条用例')
self.assertEqual(2, 3, msg='判断是否相等')
if __name__=='__main__':
unittest.main()
第五章 PageObject模型
1. 基本用例
编写禅道登录的基本用例
import unittest
from selenium import webdriver
class Login(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.get("http://www.chandao.com/zentaopms/www")
self.driver.implicitly_wait(30)
self.driver.maximize_window()
def tearDown(self):
self.driver.quit()
def test_01_login_success(self):
self.driver.find_element_by_id("account").send_keys("admin")
self.driver.find_element_by_name("password").send_keys("123456")
self.driver.find_element_by_id("submit").click()
text = self.driver.find_element_by_class_name("user-name").text
self.assertEqual("admin", text)
if __name__ == '__main__':
unittest.main()
2. 分离元素定位器
登录脚本中使用了很多元素定位方法,假如某个元素定位方法在多个脚本中被使用,一旦页面发生变化,则需要修改多个脚本的元素定位,大大增加了维护自动化脚本的成本。所以,在这一步将元素定位从脚本中分离出来。
在common目录中新建一个 chandao_locators.py
from selenium.webdriver.common.by import By
# 将所有元素定位器,按照不同页面定义在不同class中
class LoginPageLocators():
UserName = (By.ID, "account") # 用户名输入框
PassWord = (By.NAME, "password") # 密码输入框
LoginButton = (By.ID, "submit") # 登录按钮
CheckUserName = (By.CLASS_NAME, "user-name") # 登录后用户名
修改登录脚本
import unittest
from selenium import webdriver
from test.common.locators import LoginPageLocators # 导入定位器
class Login(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.get("http://www.chandao.com/zentaopms/www")
self.driver.implicitly_wait(30)
self.driver.maximize_window()
def tearDown(self):
self.driver.quit()
def test_01_login_success(self):
"""在登录页面输入正确的用户名密码,登录成功"""
self.driver.find_element(*LoginPageLocators.UserName).send_keys("admin")
self.driver.find_element(*LoginPageLocators.PassWord).send_keys("123456")
self.driver.find_element(*LoginPageLocators.LoginButton).click()
text = self.driver.find_element(*LoginPageLocators.CheckUserName).text
self.assertEqual("admin", text)
if __name__ == '__main__':
unittest.main()
3. 封装页面元素操作
将页面元素操作按照页面封装
创建一个 pages.py 文件
from test.common.locators import *
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 将页面元素操作分离出来
class BasePage():
def __init__(self, driver):
self.driver = driver
def wait_element(self, element):
try:
WebDriverWait(self.driver, 10).until(EC.visibility_of_element_located(element))
except Exception:
print("Waiting {} element located...".format(element))
# raise Exception("error: {} element is not found!".format(element))
class LoginPage(BasePage):
"""登录页面操作"""
def enter_username(self, username):
"""登录页面输入用户名"""
BasePage.wait_element(*LoginPageLocators.UserName)
self.driver.find_element(*LoginPageLocators.UserName).send_keys(username)
def enter_password(self, password):
"""登录页面输入密码"""
BasePage.wait_element(*LoginPageLocators.PassWord)
self.driver.find_element(*LoginPageLocators.PassWord).send_keys(password)
def click_login_button(self):
"""在登录页面点击登录按钮"""
BasePage.wait_element(*LoginPageLocators.LoginButton)
self.driver.find_element(*LoginPageLocators.LoginButton).click()
def get_username(self):
"""获取登录后的用户名"""
BasePage.wait_element(*LoginPageLocators.CheckUserName)
text = self.driver.find_element(*LoginPageLocators.CheckUserName).text
return text
再次修改登录脚本
import unittest
from selenium import webdriver
from test.common.locators import LoginPageLocators # 导入定位器
from test.page.pages import LoginPage # 导入页面元素操作
from time import sleep
class Login(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.get("http://www.chandao.com/zentaopms/www")
self.driver.implicitly_wait(30)
self.driver.maximize_window()
def tearDown(self):
self.driver.quit()
def test_01_login_success(self):
"""在登录页面输入正确的用户名密码,登录成功"""
loginpage = LoginPage(self.driver) # 实例化元素操作
loginpage.enter_username("admin") # 输入用户名
loginpage.enter_password("123456") # 输入密码
loginpage.click_login_button() # 点击登录按钮
self.assertEqual("admin", loginpage.get_username()) # 断言
if __name__ == '__main__':
unittest.main()
第六章 测试框架开发
1. 配置文件
在 config 目录中新建 config.py
import time
# 根路径
one_path = r"D:\chandao_po"
# 当前时间戳
current_time = time.strftime("%Y-%m-%d")
# IP地址
ip = 'http://www.chandao.com'
2. 数据驱动
安装openpyxl
pip install opnepyxl==2.3.3
创建测试数据文件
- 在 data 目录创建 login_data.xlsx 数据文件
- 表格数据如下图
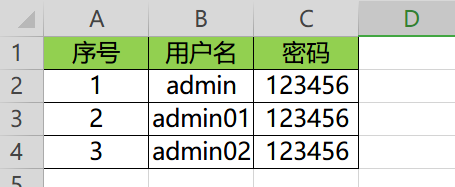
创建读取数据工具
在 utils 目录中创建 excel_utils.py 用来读取excel数据文件
from openpyxl import load_workbook
class ParseExcel():
def __init__(self, excelpath, sheetname='Sheet1'):
# 将需要读取的excel文件加载到内存
self.wb = load_workbook(excelpath)
# 获取工作表对象
self.sheet = self.wb.get_sheet_by_name(sheetname)
# 获取工作表中的最大行号
self.maxRowNum = self.sheet.max_row
def get_data(self):
# 定义一个空列表用来存放读取到的数据
datalist = []
for i in self.sheet.rows[1:]: # 从第二行开始循环读取数据(第一行是列名)
tmplist = []
tmplist.append(i[1].value) # 将第二列的数据添加到临时列表(因为第一列是序号)
tmplist.append(i[2].value) # 将第三列的数据添加到临时列表
datalist.append(tmplist) # 将临时表添加到datalist
return datalist
if __name__ == '__main__':
file = "D:\\chandao_po\\data\\login_data.xlsx"
pe = ParseExcel(file)
print(pe.get_data())
# 测试结果
# [['admin', 123456], ['admin01', 123456], ['admin02', 123456]]
安装ddt模块
pip install ddt
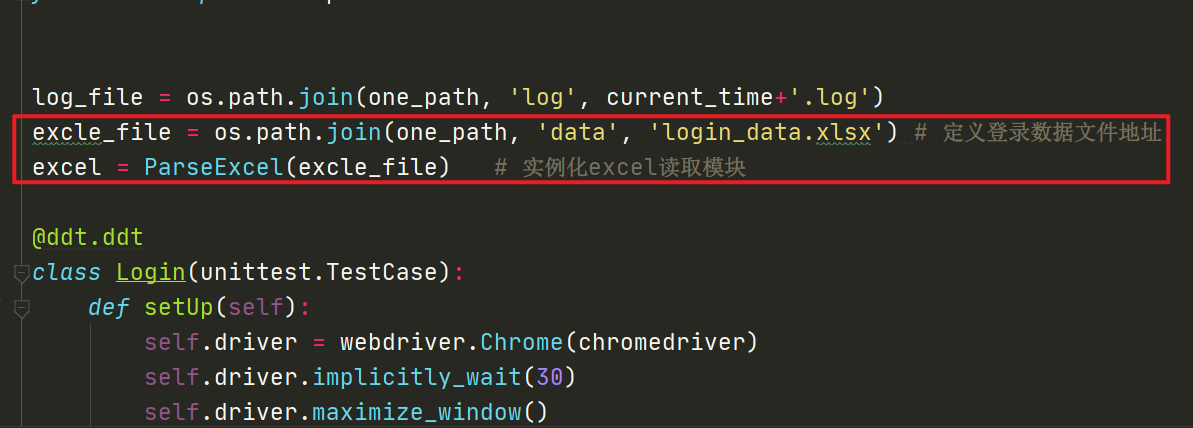
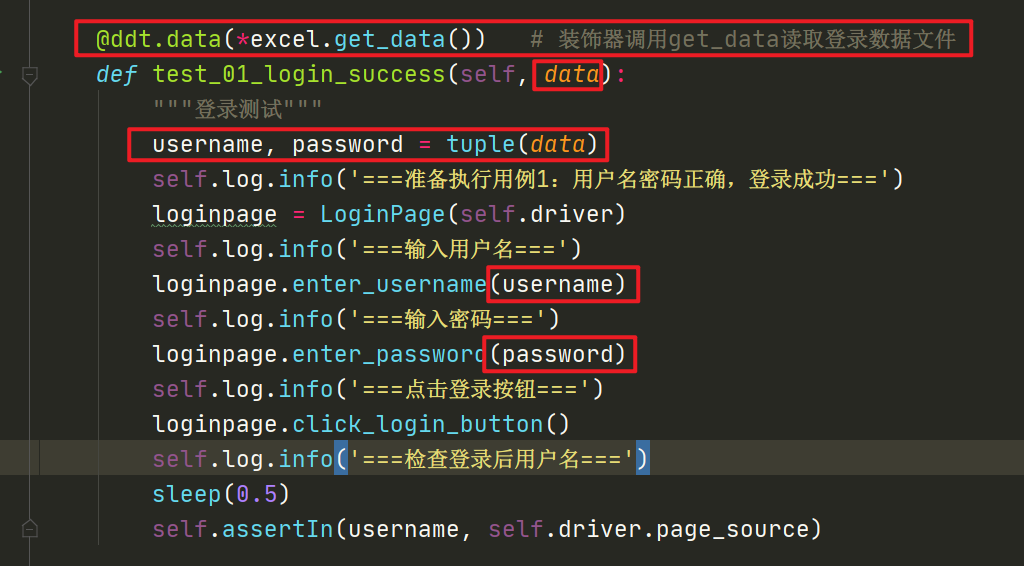
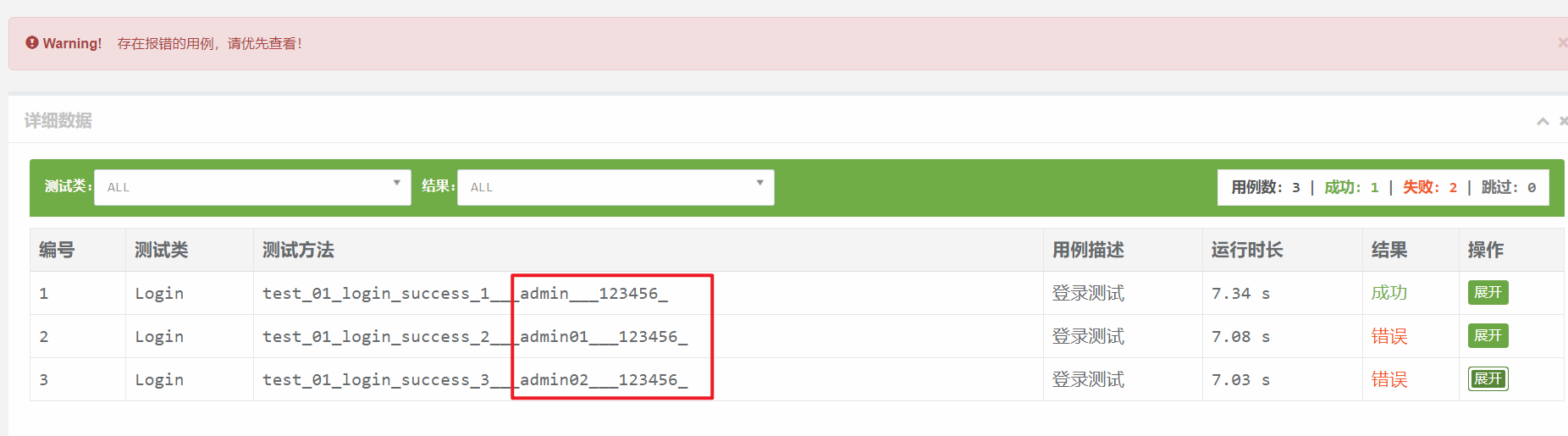
3. driver分离
- 将浏览器driver保存到特定目录中
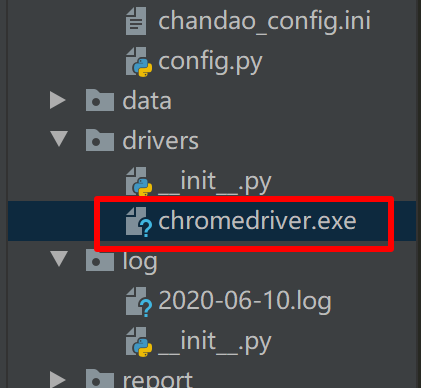
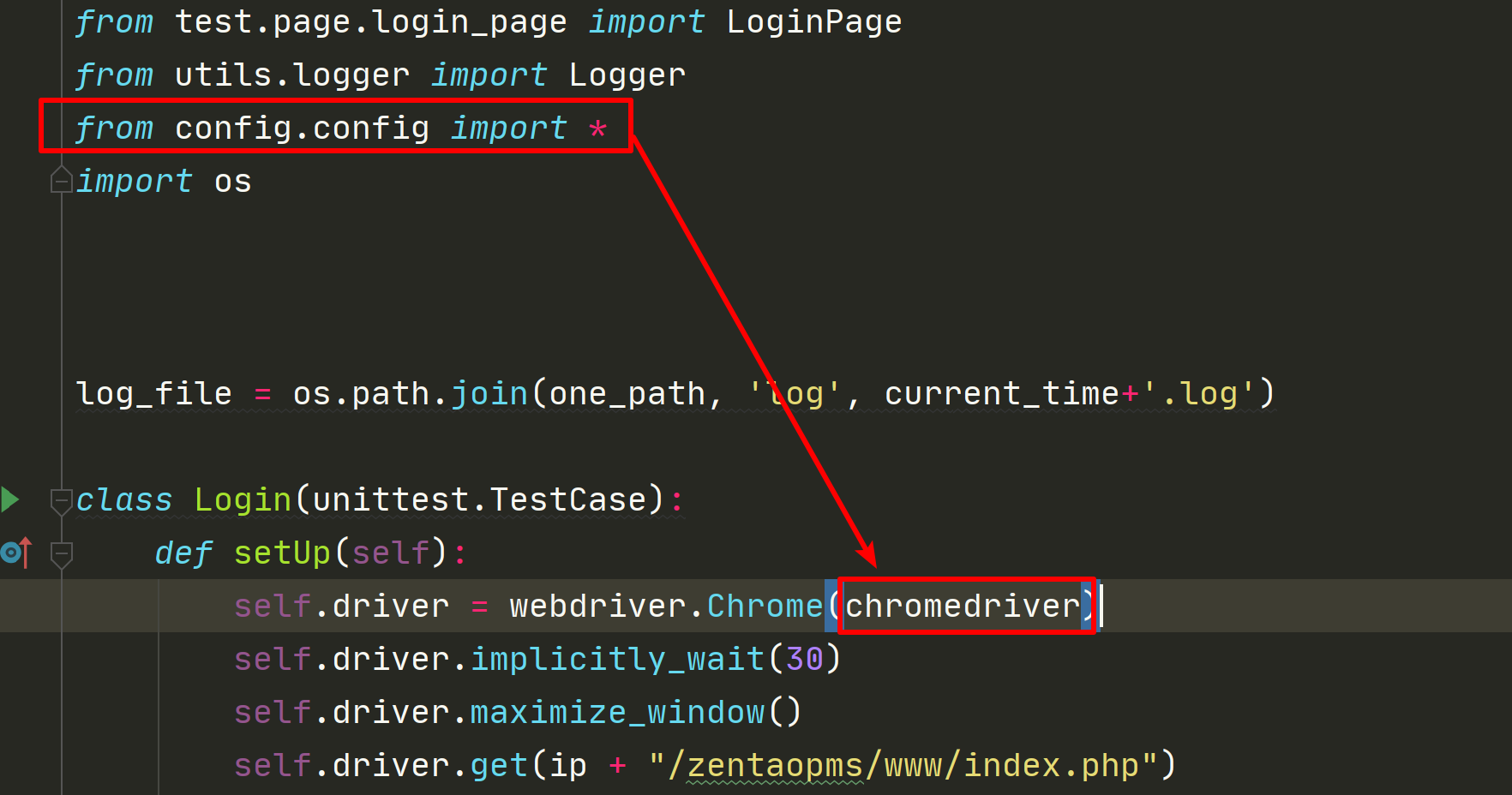
- 在配置文件中新增chromedriver路径

- 修改登录脚本,在脚本文件中引入框架中chromedriver
4. 公共函数封装
因为在多个脚本中被使用,所以将其抽离,单独封装值common目录中
chandao_login.py
from test.page.pages import LoginPage
from selenium import webdriver
from config.config import *
class Login():
@staticmethod # 静态方法可以不用实例化,直接调用
def login(broswerdriver):
driver = broswerdriver
driver.implicitly_wait(30)
driver.maximize_window()
driver.get(ip + "/zentaopms/www/index.php")
loginpage = LoginPage(driver)
loginpage.enter_username('admin')
loginpage.enter_password('123456')
loginpage.click_login_button()
if __name__ == '__main__':
driver = webdriver.Chrome(chromedriver)
Login.login(driver)
5. 日志封装
日志等级介绍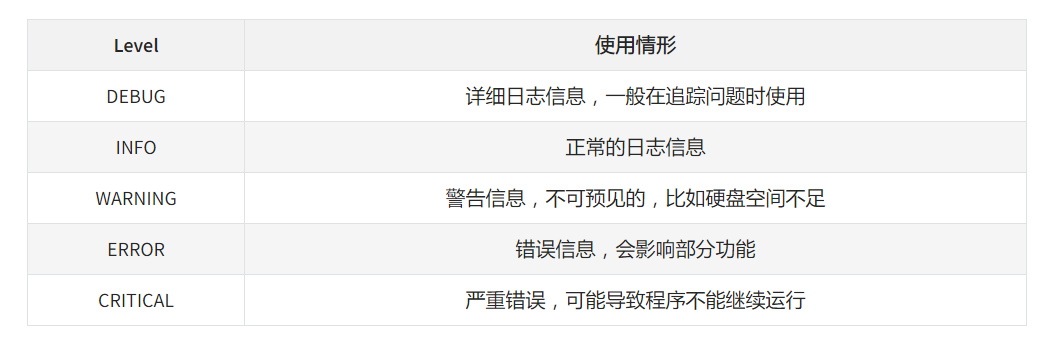
在utils目录新增 logger.py 文件
import logging
class Logger():
# debug<info<warning<error<critical
# 定义log级别映射关系
level_relations = {
'debug':logging.DEBUG,
'info':logging.INFO,
'warning':logging.WARNING,
'error':logging.ERROR,
'critical':logging.CRITICAL
}
def __init__(self, filename, level):
self.level = self.level_relations.get(level) # 获取log级别
self.logger = logging.getLogger(filename) # 创建一个logger
self.logger.setLevel(self.level) # 设置log级别总开关
# 定义handler输出格式
formatter = logging.Formatter('%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s')
fh = logging.FileHandler(filename) # 创建handler
fh.setFormatter(formatter) # 设置输出格式
fh.setLevel(self.level) # 设置输出日志文件的等级开关
self.logger.addHandler(fh) # 添加handler
def debug(self, msg):
self.logger.debug(msg)
def info(self, msg):
self.logger.info(msg)
def warning(self, msg):
self.logger.warning(msg)
def error(self, msg):
self.logger.error(msg)
def critical(self, msg):
self.logger.critical(msg)
if __name__ == '__main__':
log = Logger('a.log', 'debug')
log.info('lalal')
修改测试登录脚本
from selenium import webdriver
import unittest
from test.page.login_page import LoginPage
from utils.logger import Logger
from config.config import *
import os
# 定义日志文件的存放路径
log_file = os.path.join(one_path, 'log', current_time+'.log')
class Login(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.driver.maximize_window()
self.driver.get("http://www.chandao.com/zentaopms/www/index.php")
self.log = Logger(log_file, 'debug') # 实例化logger对象,需要传入log文件路径以及等级
def tearDown(self):
# sleep(2)
self.driver.quit()
def test_01_login_success(self):
"""用户名密码正确,登录成功"""
self.log.info('===准备执行用例1:用户名密码正确,登录成功===')
loginpage = LoginPage(self.driver)
self.log.info('===输入用户名===')
loginpage.enter_username()
self.log.info('===输入密码===')
loginpage.enter_password()
self.log.info('===点击登录按钮===')
loginpage.click_login()
self.log.info('===检查登录后用户名===')
loginpage.check_username()
if __name__ == "__main__()":
unittest.main()
6. 测试框架说明文档
第七章 测试集成
1. gitee
使用pycharm将脚本同步至gitee
安装插件
打开pycharm设置,安装gitee插件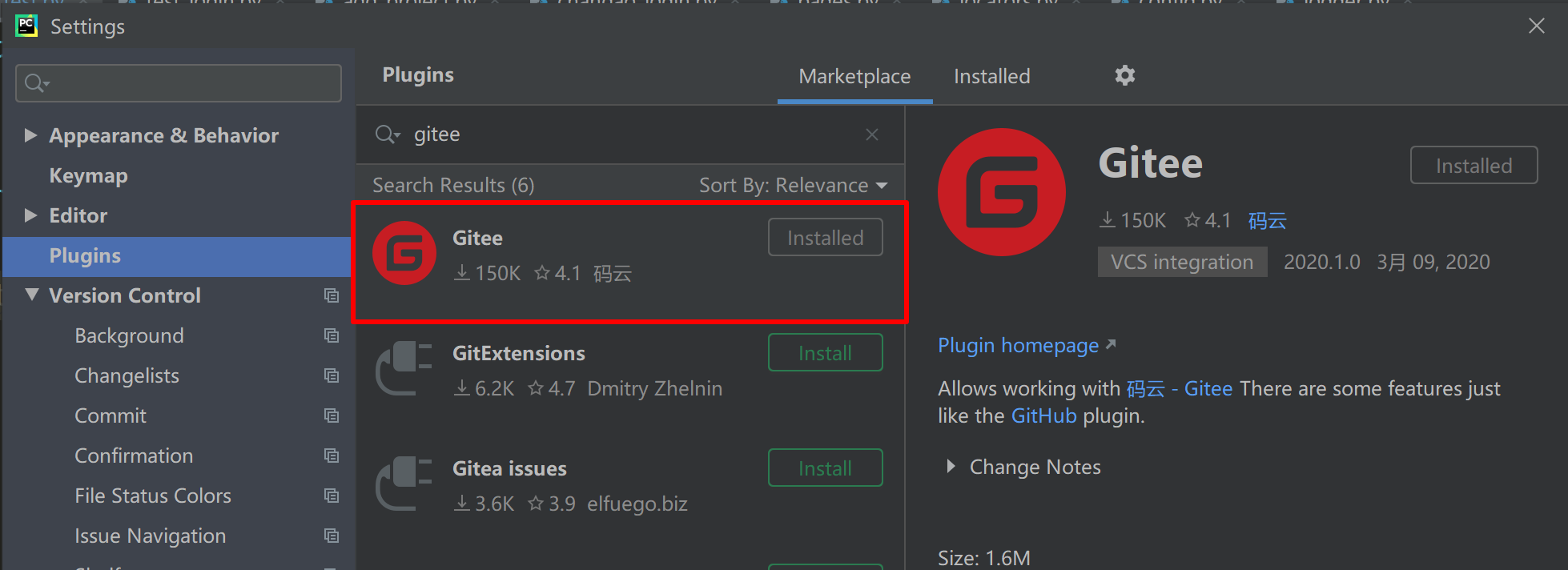
首次同步
首次将项目同步至gitee,gitee中必须不存在与项目名相同的仓库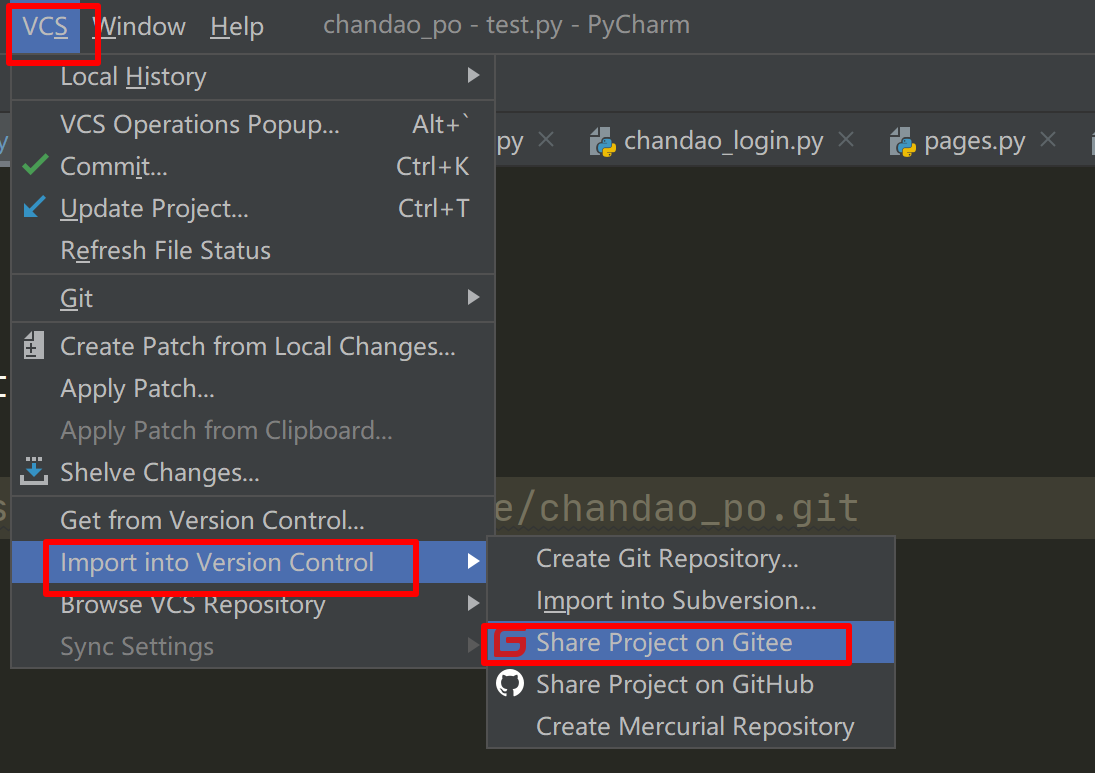
添加文件
如果在项目中有新增/修改文件,将该文件添加到本地仓库,并添加一个信息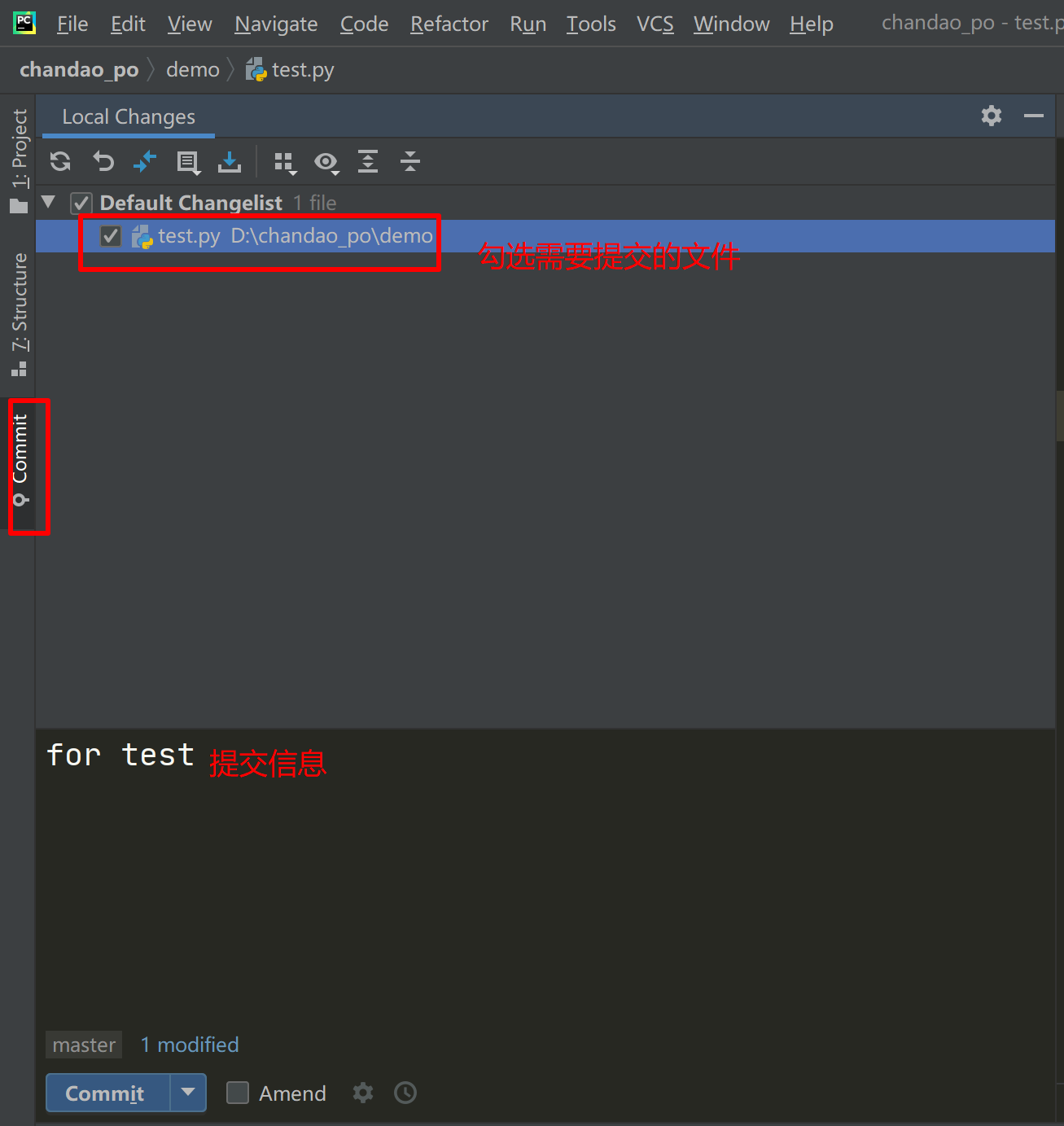
提交
将新增/修改的文件提交到远端仓库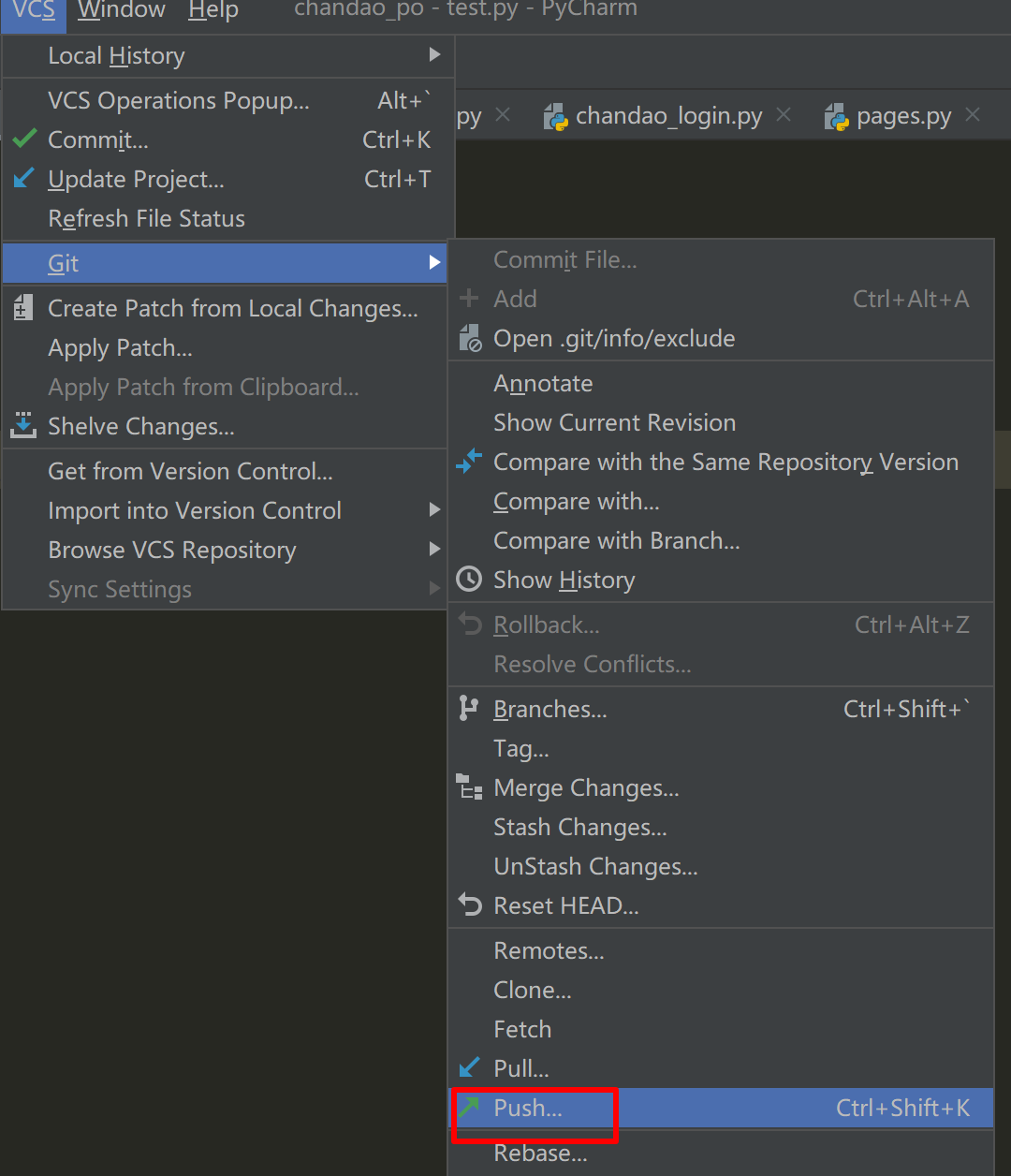
2. Pycharm+gitee
使用Pycharm开发代码的过程中,可以将代码托管在Gitee等相关代码托管平台
🔴安装git客户端
默认安装即可
🔴新建一个项目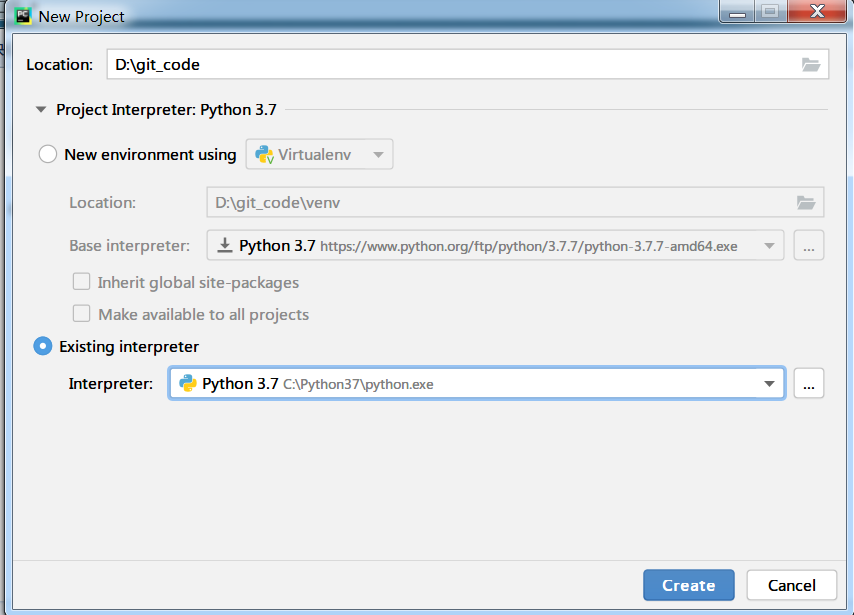
🔴Pycharm配置Git
在pycharm中验证git客户端是否正常
点击图中第2步测试时,pycharm会自动添加已安装git的路径,成功看到git版本号即可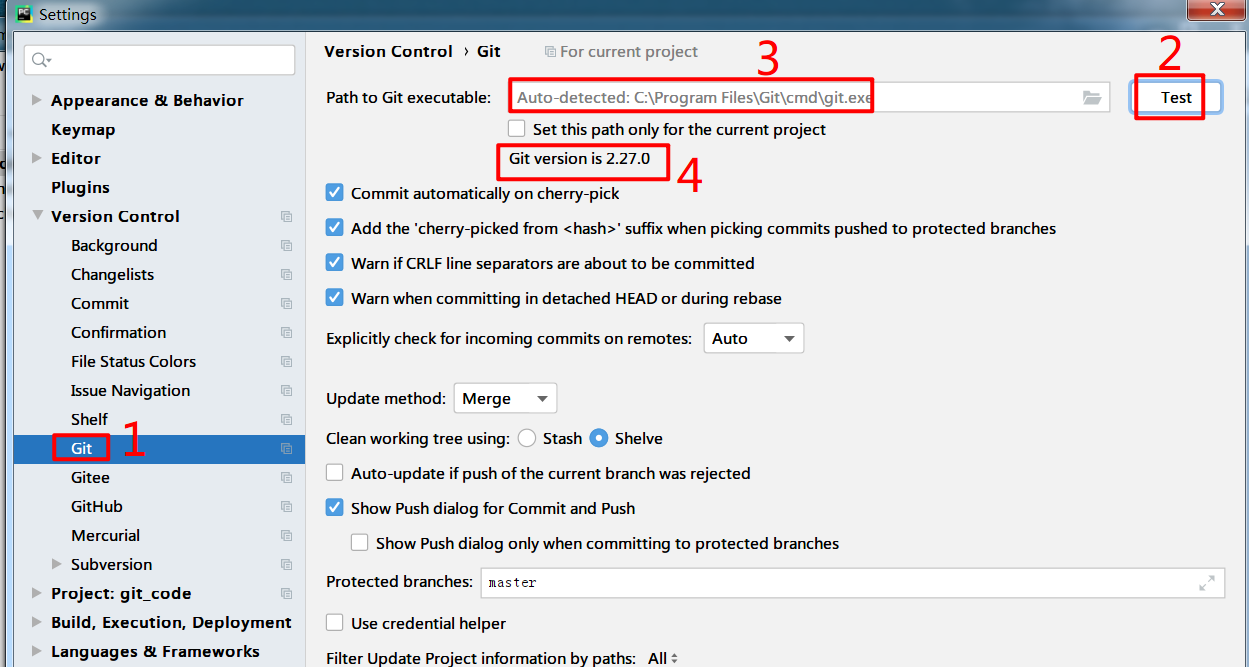
🔴安装Gitee插件
在设置中心-插件中搜索gitee插件并安装,然后重启pycharm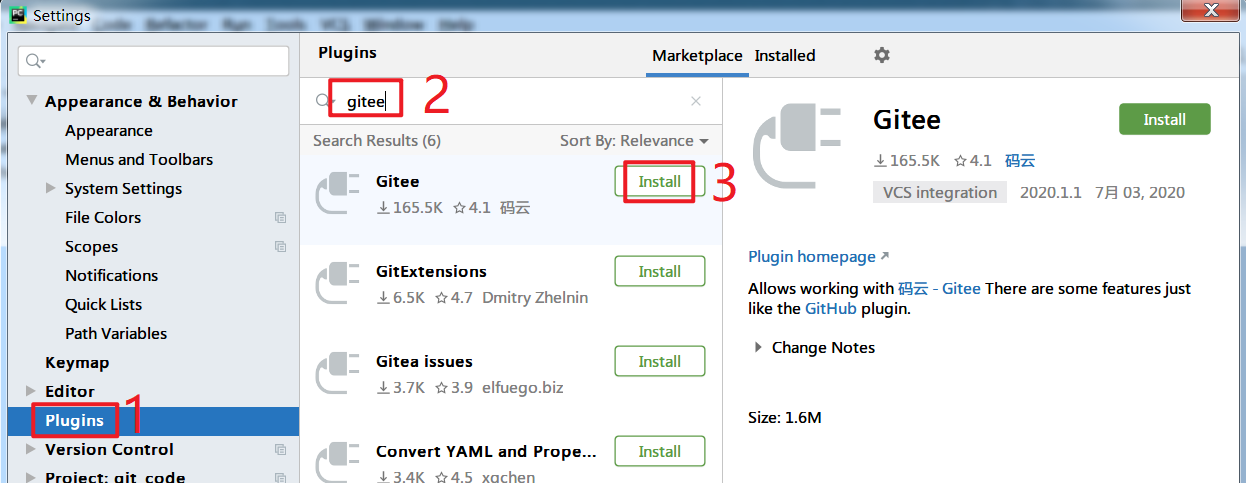
🔴创建仓库
如果在Gitee中还未曾创建过任何仓库且需要将当前项目中的代码同步到Gitee当中时,可以使用如下方法在Gitee中创建一个仓库并将本地代码同步至Gitee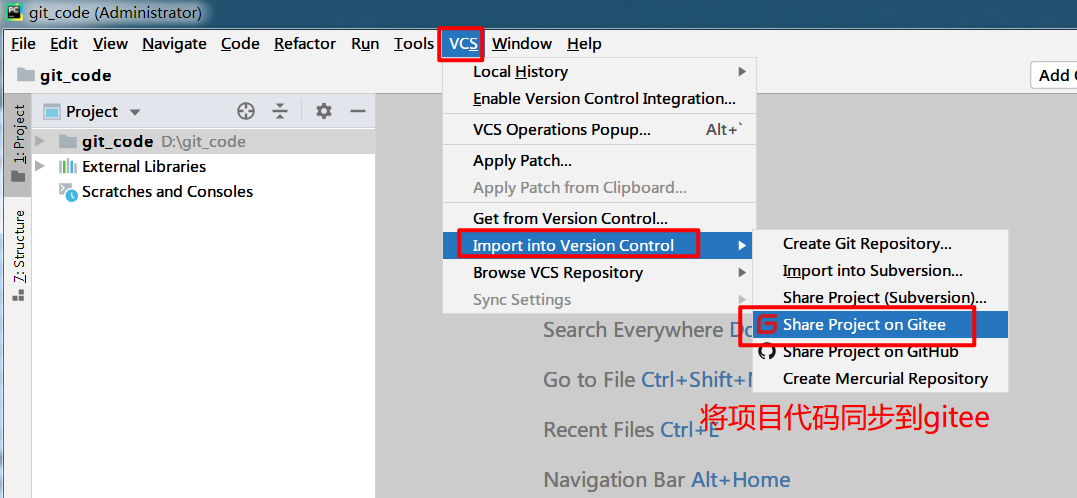
🔴克隆项目代码
如果需要首次将代码从远程仓库中复制到本地,则需要使用克隆功能
在pycharm中选择从版本控制中导入项目并登录gitee账号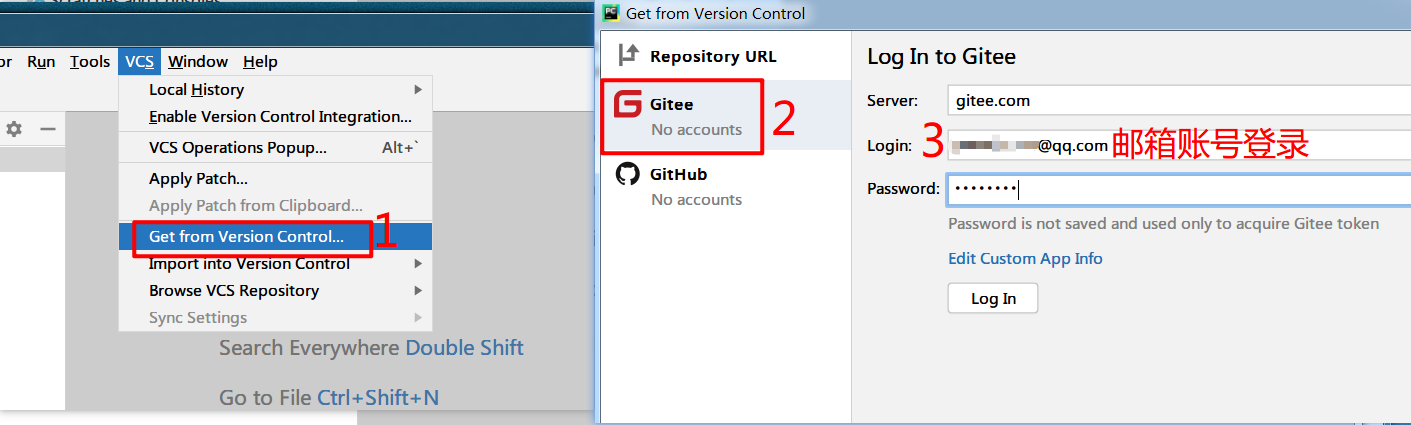
选择需要克隆的项目,设置克隆项目的存放路径即可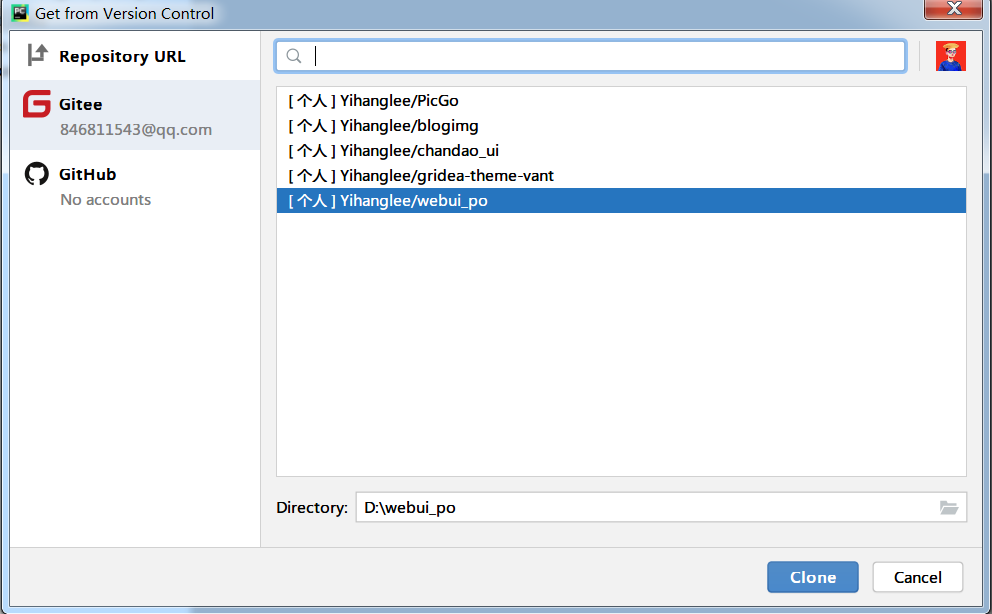
🔴拉取代码
如果希望代码时刻保持最新状态,那么需要将远程仓库的主分支(master)拉取本地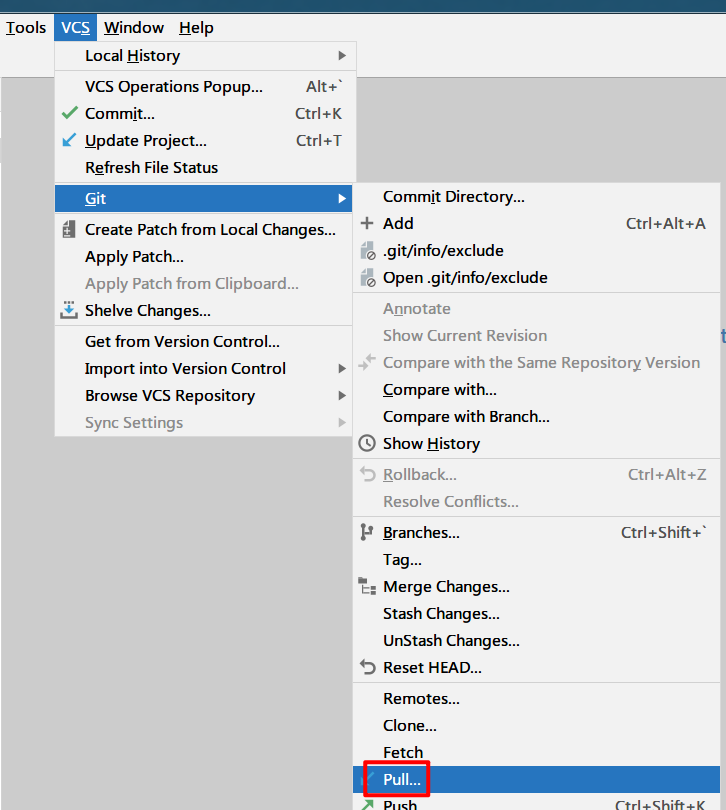
🔴提交代码
Git中,提交/修改代码等操作时,需要尽可能的使用 分支 进行,不过目前,本步骤中并没有涉及到分支的操作,所有操作均提交到了master分支,即在 主分支 。请注意!
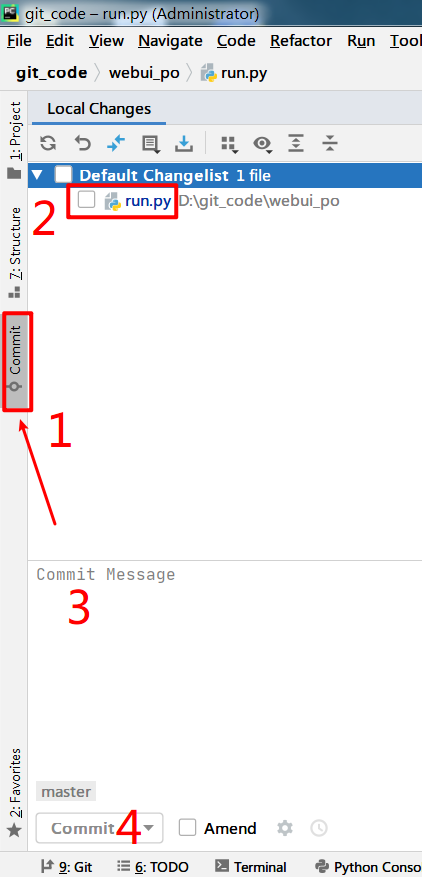
在项目中,如果修改更新了某些代码文件后,提交代码步骤如下:
- 第1步,切换到 commit 选项卡,你会看到已经变化更新的文件列表
- 第2步勾选 上你需要提交的文件
- 第3步中填入本次提交的简介信息
- 第4步的提交按钮即可将本次文件变化同步至本地暂存库
- 注意:首次提交时,需要设置Git的用户名与邮箱
- 第5步,打开提交界面,第6步选择需要提交的版本,提交到远程即可

其他
1. 12306
from selenium import webdriver
from selenium.webdriver.common.keys import Keys # 键盘操作
from time import sleep
driver = webdriver.Chrome() # 创建浏览器对象
driver.get('https://www.12306.cn/index/') # 访问12306
driver.implicitly_wait(10) # 添加智能等待
driver.maximize_window() # 最大化浏览器
driver.find_element_by_id('fromStationText').click()
driver.find_element_by_id('fromStationText').send_keys('shenzhen')
driver.find_element_by_id('fromStationText').send_keys(Keys.ENTER) # 模拟按下回车键
driver.find_element_by_id('toStationText').click()
driver.find_element_by_id('toStationText').send_keys('changsha')
driver.find_element_by_id('toStationText').send_keys(Keys.ENTER)
js_value = 'document.getElementById("train_date").value="2019-01-04"'
driver.execute_script(js_value)
driver.find_element_by_id('search_one').click()
sleep(3)
driver.quit()
2. 参数化
2.1 参数化的好处
-
2.2 安装插件
unittest本身并不支持参数化
- 需要下载参数化插件:
parameterized- 打开命令行窗口,输入:
pip install parameterized,安装参数化插件 - github地址:https://github.com/wolever/parameterized
2.3 案例
```python import unittest from selenium import webdriver from time import sleep from parameterized import parameterized # 导入参数化插件
- 打开命令行窗口,输入:
定义列表储存需要参数化的数据
searchlist_success = [[‘selenium’, ‘selenium百度搜索’], [‘python’, ‘python百度搜索’], [‘java’, ‘java百度搜索’]]
search_list_fail = [[‘selenium’, ‘selenium百度搜索’], [‘python’, ‘python百度搜索’]]
class BaiDuTest(unittest.TestCase): def setUp(self): self.driver = webdriver.Chrome() self.driver.get(‘https://www.baidu.com‘) self.driver.maximize_window() self.driver.implicitly_wait(10)
def tearDown(self):
sleep(2)
self.driver.quit()
# 使用parameterized插件提供的装饰器装饰用例,把参数化数据替换到用例里面
# python中的装饰器的作用是:为已存在的函数或对象添加额外的功能
@parameterized.expand(search_list_success)
def test_01_search_success(self, search_keywords, expect_result):
'''百度首页搜索框测试用例--成功'''
self.driver.find_element_by_id('kw').send_keys(search_keywords)
self.driver.find_element_by_id('su').click()
sleep(2)
self.assertEqual(expect_result, self.driver.title)
@parameterized.parameterized.expand(search_list_fail)
def test_02_search_fail(self, search_keywords, expect_result):
'''百度首页搜索框测试用例--失败'''
self.driver.find_element_by_id('kw').send_keys(search_keywords)
self.driver.find_element_by_id('su').click()
sleep(2)
self.assertEqual(expect_result, self.driver.title)
if name == ‘main‘: unittest.main(verbosity=2)
# verbosity表示测试结果的详细程度,默认为verbosity=1
# 0:(静默模式) 用例总数和结果
# 1:(默认模式) 成功用例用.表示,失败用F表示
# 2:(详细模式) 显示每个用例的所有相关信息
```python
import unittest
from selenium import webdriver
from time import sleep
from ddt import ddt,data,unpack
@ddt
class BaiDu(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.get('https://www.baidu.com')
def tearDown(self):
sleep(1)
self.driver.quit()
@data(('python','python_百度搜索'), ('123', '123_百度搜索'))
@unpack
def test_01_search(self, search, expected):
self.driver.find_element_by_id('kw').send_keys(search)
self.driver.find_element_by_id('su').click()
sleep(2)
self.assertEqual(self.driver.title, expected)
if __name__=='__main__':
unittest.main(verbosity=2)
3. Chrome无界面模式
from selenium.webdriver import Chrome, ChromeOptions
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = Chrome(options=opt) # 创建Chrome无界面对象
driver.get('http://www.baidu.com')print(driver.current_window_handle)
print(driver.page_source)
driver.close()
附注
工具下载

若有收获,就点个赞吧
0 人点赞
