- 1. 一行代码求1-100的和
- 2. 任意数字列表去重
- 3. args与kwargs
- 4. range函数在Python2与3中的区别
- 5. 一句话解释什么样的语言能够使用装饰器
- 6. with打开文件帮助我们做了什么
- 7. 现有列表[1, 2, 3, 4, 5],请使用map函数输出[1, 4, 9, 16, 25],并使用列表推导式提取出大于10的数,最终输出[16, 25]
- 8. 随机数生成
- 生成1-10之间的随机整数
- 生成1-10之间的随机浮点数
- 生成10个10-100之间的随机整数
- 11. 断言方法举例
- 12. Python2与3的区别
- 13. 可变类型与不可变类型
- 14. 字符串去重并排序
- 15. 匿名函数lambda实现两数相乘
- 16. 水仙花数
- 17. 根据字典中的键排序
- 18. 统计字符串中每个字母出现的次数
- 19. 去除字符串中的数字与字母,保留汉字
- 20. 使用filter方法找出列表中所有的奇数并构造成新列表
- 21. 列表合并
- 22. 绘制统计图的开源库
- 23. 列表推导式展开嵌套列表
- 24. 使用re模块修改字符串中的数字
- 25. 如何提高Python运行效率
- 26. Python如何读取大文件
- 27. 输入任意日期,判断这一天是今年的第几天
- 28. 如何打乱排好序的列表
- 29. 字典推导式
- 30. 最长回文子串
1. 一行代码求1-100的和
print(sum(range(1, 101)))
2. 任意数字列表去重
nums = [1, 2, 3, 3, 2] # 通过集合不允许有重复值的特性去重print(list(set(nums)))
3. args与kwargs
*args可以将不定数量的参数打包成tuple提供给函数体使用
def fun1(*args): # *args可以传入任意数量的参数print(type(args)) # <class 'tuple'>for i in args:print(i)fun1(1, 2, 3) # 分别将1, 2, 3打印
*kwargs可以传入不定数量的键值对参数打包成dict给函数使用
def fun2(*kwargs):for k, v in kwargs:print(f"key={k}, value={v}")fun2({"name":"zs", "age":18}) # key=name, value=age
4. range函数在Python2与3中的区别
range函数在Python2中直接返回一个列表
-
5. 一句话解释什么样的语言能够使用装饰器
函数可以作为参数传递的语言,可以使用装饰器(在执行一个目标函数之前或者之后执行一些特定的事情)
6. with打开文件帮助我们做了什么
打开文件读写时,可能会出现一些异常状况
如果按照常规的f=open()的写法,我们需要写try、except、finally等做异常处理,并且文件最终不管遇到什么情况,都必须执行f.close()方法,而with帮我实现了最终自动关闭文件的功能
f = open('a.txt', 'wb')try:f.write("hello")except:passfinally:f.close()
7. 现有列表[1, 2, 3, 4, 5],请使用map函数输出[1, 4, 9, 16, 25],并使用列表推导式提取出大于10的数,最终输出[16, 25]
从题中可知,需要将列表中的每个元素都计算其平方值
- 而map函数中会根据提供的函数对指定序列做映射,第一个参数传入函数,第二个参数传入序列
nums = [1, 2, 3, 4, 5]# 定义一个函数用来计算平方值def func(num):return num**2res = map(func, nums) # 注意这里返回迭代器res = [i for i in res if i > 10]print(res)
8. 随机数生成
```python import random
生成1-10之间的随机整数
print(random.randint(1, 10))
生成1-10之间的随机浮点数
print(random.uniform(1, 10))
生成10个10-100之间的随机整数
nums = [random.randint(1, 100) for i in range(10)] print(nums)
<a name="pSWwM"></a>### 9. 如何避免字符串转义- 在原始字符串前加r<a name="PxQ5n"></a>### 10. 正则提取现有一个标签如:<div class="a">中国<div>,用正则匹配出其中的 **中国**, class属性值是不确定的。```pythonimport restr = '<div class="a">中国<div>'# .表示可有可无,*表示任意字符# (.*?)表示提取目标文本res = re.findall('<div class=".*">(.*?)<div>', str)print(res) # ['中国']
11. 断言方法举例
a = 5
assert (a > 3) # 断言成功,继续往下执行
print('断言成功')
# b = 4
# assert (b < 2) # 断言失败,如需继续往下执行,则需捕获异常
# print('断言失败')
# 捕获异常版本
b = 4
try:
assert (b < 2)
except Exception as e:
print('断言失败啦')
12. Python2与3的区别
| 区别 / 版本 | Python2 | Python3 |
|---|---|---|
| 语句 | 函数 | |
| 编码 | asscii | utf-8 |
| True False | 变量(可以被赋值) | 关键词(不可以被赋值) |
| 迭代器 | range返回列表 | range返回迭代器,节约内存 |
| 整除 | 结果为整型 | 结果为浮点型 |
13. 可变类型与不可变类型
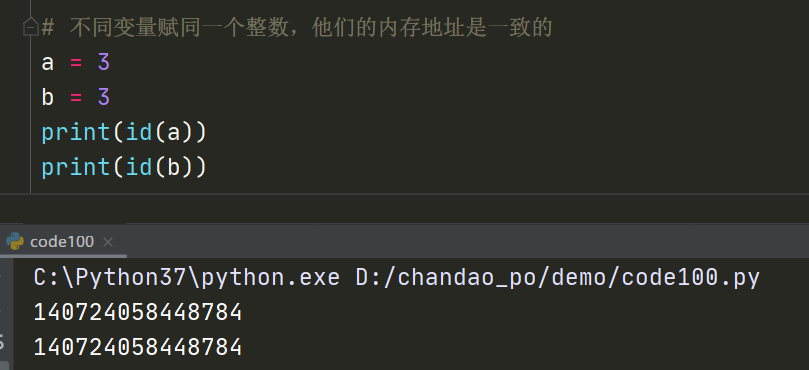
不可变类型:不允许变量的值发生变化,如果改变了变量的值,相当于新建了一个对象,对象的地址会发生变化
- 数值型:int、float
- 字符串:string
- 元组:tuple
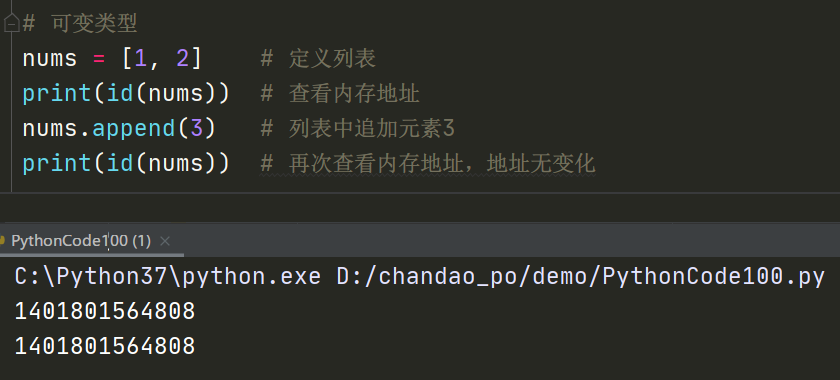
可变类型:允许改变变量的值,比如对变量进行append、+等操作,只是改变变量的值,变量的内存地址无变化
- 列表:list
- 字典:dict
14. 字符串去重并排序
现有字符串 s = “ashjasaksjaslaksl”,去重并排序输出 “ahjkls”
s = 'ashjasaksjaslaksl'
temp = sorted(set(s)) # 将字符串转成set,再强转为list,最后用sorted排序
res = ''.join(temp) # 将排好序的列表转成字符串
print(res)
15. 匿名函数lambda实现两数相乘
res = lambda a,b:a*b # a,b是参数,a*b是表达式
print(res(2, 3))
16. 水仙花数
“水仙花数”是指一个三位数,其各位数字立方和等于该数本身。例如:153是一个“水仙花数”, 
# 求100-1000之间的水仙花数
for i in range(100, 1000):
s = 0
nums = list(str(i))
for j in nums:
s += int(j)**len(nums)
if i == s:
print(f"{i}是一个水仙花数!")
17. 根据字典中的键排序
# 字典根据键从小到大排序
students = {'name':"zs", "age":18, "tel":"17688477894"}
res = sorted(students.items(), key=lambda i:i[0], reverse=False)
print(res)
fin = {}
for i in res:
fin[i[0]] = i[1]
print(fin)
# 结果如下
# {'age': 18, 'name': 'zs', 'tel': '17688477894'}
18. 统计字符串中每个字母出现的次数
解法一:
# 统计字符串中每个字母出现的次数
from collections import Counter
s = 'abcdabcdabcd'
res = Counter(s)
print(res)
解法二:
import re
s = 'abcdabcdabcdAB'
# 使用正则找出字符串中每个字母,并返回列表
target = re.findall('[a-zA-z]', s)
# 定义空串
res = {}
for i in target:
res[i] = res.get(i, 0) + 1 # 接受键与默认值,如果出现过键则+1
print(res)
19. 去除字符串中的数字与字母,保留汉字
字符串 s = ‘You are so handsome 123 张三 深圳’ ,将字符串中的所有单词、数字去除,只保留中文
import re
s = 'You are so handsome 123 张三 深圳'
temp = s.split(' ') # 使用空格切割字符串,输出列表
# 用正则匹配列表中的所有单词、数字
# | 在正则中用来连接多个匹配条件
res = re.findall('[A-za-z]+|\d+', s)
# for i in res:
# if i in temp:
# temp.remove(i)
temp = [i for i in temp if i not in res]
fin = ' '.join(temp)
print(fin)
20. 使用filter方法找出列表中所有的奇数并构造成新列表
filter()函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。该函数接收两个参数,第一个为函数,第二个为序列,序列中的每个元素作为参数传递给函数进行判定,然后返回True或False,最后将返回True的元素放到新列表中。
# 使用filter方法找出列表中所有的奇数并构造成新列表
nums = [1, 2, 3, 4, 5]
temp = filter(lambda i:i%2==1, nums)
res = [i for i in temp]
print(res)
21. 列表合并
extend可以将另一个列表中的元素逐个添加到原列表中,不同于append整体添加。
# 列表合并
nums1 = [1, 2]
nums2 = [3, 4]
nums1.extend(nums2)
print(nums1)
22. 绘制统计图的开源库
绘制形图、折线图等
- pychart
- matplotlib
23. 列表推导式展开嵌套列表
nums = [[1, 2], [3, 4], [5, 6]]
res = [j for i in nums for j in i]
print(res)
24. 使用re模块修改字符串中的数字
re.sub(正则,新字符串, 原字符串) : 将原字符串中所有与正则匹配的字符串用心字符串替换
# 使用re模块修改字符串中的数字
s = '小明英语考了100分!'
# s = s.replace('100', '98')
res = re.sub('\d+', '98', s)
print(res)
25. 如何提高Python运行效率
:::info
- 使用生成器、迭代器,可以节约大量内存
- 循环代码优化,避免过多重复代码的执行
- 核心模块用CPython、PyPy等,提高效率
- 多进程、多线程、协程
- 多个if、elif条件判断,可以把最有可能先发生的条件放到前面,这样可以减少程序判断的次数,提高效率 :::
26. Python如何读取大文件
使用Python读取大文件,如文件体积达到GB以上时,极有可能出现 memory error (内存错误)和文件读取太慢的问题。Python中文件对象提供了三个 读 的方法:read()、readline()、readlines()。read()每次读取整个文件,如果文件大于可用内存,就会爆内存。使用 with open** 加上 for** 循环处理文件,for被视为一个迭代器,会自动的采用缓冲IO和内存管理,这样就可以放心处理大文件了。
with open(r"D:\read_file.txt", "r+", encoding='utf8') as f:
for line in f:
print(line)
在使用python进行大文件读取时,应该让系统来处理,使用最简单的方式,交给解释器,就管好自己的工作就行了。同时根据不同的需求可以选择不同的读取参数进一步获得更高的性能。
27. 输入任意日期,判断这一天是今年的第几天
import datetime
def checkdate():
year = int(input("请输入年份:"))
month = int(input("请输入月份:"))
day = int(input("请输入日:"))
# 将输入日期转为标准日期格式
target_time = datetime.date(year, month, day)
# 输入年份的第一天
first_time = datetime.date(year, month=1, day=1)
# 输入日期减去第一天
return (target_time - first_time).days + 1
if __name__ == "__main__":
print(checkdate())
28. 如何打乱排好序的列表
import random
nums = [1, 2 ,3]
random.shuffle(nums)
print(nums)
# [3, 1, 2]
29. 字典推导式
使用字典推导式,将嵌套tuple数据转为字典
infos = (("name", "zs"), ("age", 18))
infos_dict = {k:v for k, v in infos}
print(infos_dict)
30. 最长回文子串
def longstr(s):
res = ''
for i in range(len(s)):
start = max(0, i-len(res)-1)
temp = s[start : i+1]
if temp==temp[::-1]:
res = temp
else:
temp = temp[1:]
if temp == temp[::-1]:
res = temp
return res
if __name__ == '__main__':
print(longstr('acdca'))

若有收获,就点个赞吧
0 人点赞
