ElasticSearch
简介
https://www.elastic.co/cn/what-is/elasticsearch 全文搜索属于最常见的需求,开源的 Elasticsearch 是目前全文搜索引擎的首选。 它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它 
Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的 接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。 REST API:天然的跨平台。 官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html 官方中文:https://www.elastic.co/guide/cn/elasticsearch/guide/current/foreword_id.html 社区中文: https://es.xiaoleilu.com/index.html http://doc.codingdict.com/elasticsearch/0
一、基本概念
1、Index(索引)
- 动词,相当于mysql的insert
- 名词,相当于mysql的database
Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
2、 Type(类型)
在 Index(索引)中,可以定义一个或多个类型。
类似于 MySQL 的 Table,每一种类 型的数据存放在一起。
如把一条数据存在ES的某个index下的某个type下,类型和索引通俗点即为 index为数据库,type为数据表,存在某个数据库的某张表下
在Elasticsearch6.0之后,Type 类型被移除。
3、Document(文档)
保存在某个 Index(索引)下,某种 Type(类型)的一个数据,Document(文档)是JSON格式的,Document 就像是 MySQL 中某个 Table 里面每一行的数据,字段就是Document里的属性。
二、安装
三、初步检索
四、进阶检索
SpringBoot整合ElasticSearch
128. 商城业务商品上架-sku在es中存储模型分析
扩展: ELK技术栈(集中化日志解决方案)
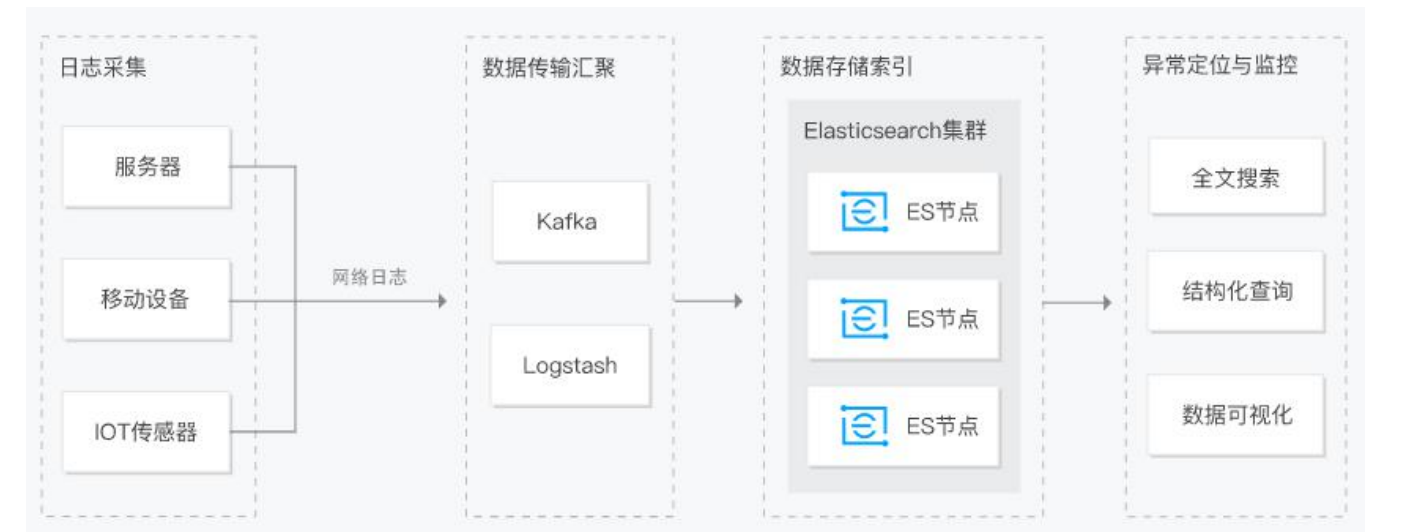
- 只保存有用的数据
- 哪些数据要进ES
规格属于Spu,所有sku共享spu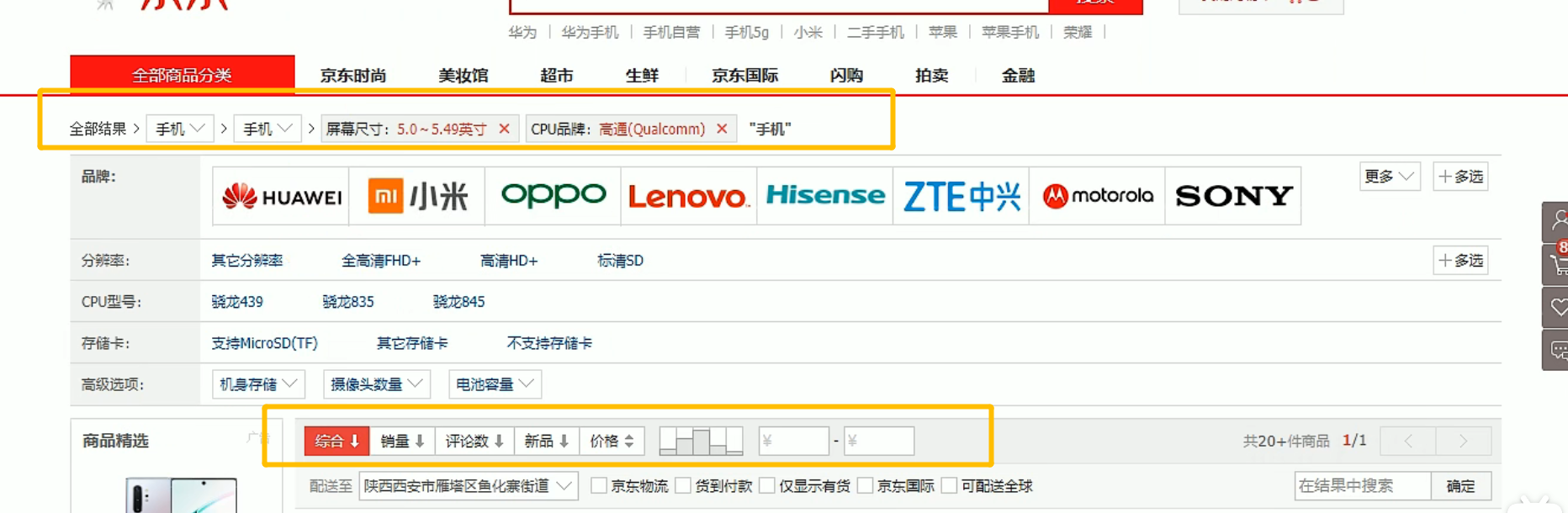
es存放数据选型(1)、方便检索{skuId:1spuId:1skuTitle:华为xprice:998saleCount:99attrs:[{尺寸:5寸},{cpu:高通886},{分辨率:全高清},]}冗余:100万条数据*20个平均属性attrs=1000000*2KB=2000MB=2G 这种方案最稳妥,加根内存条就完事(2)、SKU索引{skuId:1spuId:11sku其他基本信息}为了不冗余,在建一个attr索引attr索引{spuId:1attrs:[{尺寸:5寸},{cpu:高通886},{分辨率:全高清}]}比如检索手机的时候,每选中一个规格,规格不停的变,有个最大的特点,所列举的出来的属性,查出的商品,是系统有的,点个256G没有数据,下面的规格是动态计算的,把所用商品的规格聚合,点击某个规格属性值,可以保证下面一定有商品比如搜一个小米;满足小米的分类有很多,粮食,电器,手机,要检索出sku所涉及的所有小米小米1万条数据,4000个spu,要找到4000个spu拿来聚合,会做个分布式查询,首先第一步查出包含小米的手机,查到了一万条数据,一万个里面涉及到了4000条spu,然后第二部查出这4000个spu对应的所有可能属性,分布的话相当于会调用第二次查询,第二次es客户端还是给es发送Http请求,这个请求不说别的spuId:[4000]数组就要传4000个spuId,每个都是Long类型4000*8=32000Byte=32Kb,也就说一个请求下去就要发送32kb数据,假如并发检索,就一万个人同时检索商品就是 10000*32kb=320mb;一次集群传输都是320mb;假如百万并发加俩零,就是32000MB=32gb数据,别的不说光网络阻塞都要好久空间和时间二选一,最终选第一种

若有收获,就点个赞吧
0 人点赞
