SQL脚本
SQL脚本```sql — 创建dept表,并插入数据 create table dept( id int auto_increment comment ‘ID’ primary key, name varchar(50) not null comment ‘部门名称’ )comment ‘部门表’; INSERT INTO dept (id, name) VALUES (1, ‘研发部’), (2, ‘市场部’),(3, ‘财务部’), (4, ‘销售部’), (5, ‘总经办’), (6, ‘人事部’);
— 创建emp表,并插入数据 create table emp( id int auto_increment comment ‘ID’ primary key, name varchar(50) not null comment ‘姓名’, age int comment ‘年龄’, job varchar(20) comment ‘职位’, salary int comment ‘薪资’, entrydate date comment ‘入职时间’, managerid int comment ‘直属领导ID’, dept_id int comment ‘部门ID’ )comment ‘员工表’;
— 添加外键 alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id); INSERT INTO emp (id, name, age, job,salary, entrydate, managerid, dept_id) VALUES (1, ‘金庸’, 66, ‘总裁’,20000, ‘2000-01-01’, null,5), (2, ‘张无忌’, 20, ‘项目经理’,12500, ‘2005-12-05’, 1,1), (3, ‘杨逍’, 33, ‘开发’, 8400,’2000-11-03’, 2,1), (4, ‘韦一笑’, 48, ‘开发’,11000, ‘2002-02-05’, 2,1), (5, ‘常遇春’, 43, ‘开发’,10500, ‘2004-09-07’, 3,1), (6, ‘小昭’, 19, ‘程序员鼓励师’,6600, ‘2004-10-12’, 2,1), (7, ‘灭绝’, 60, ‘财务总监’,8500, ‘2002-09-12’, 1,3), (8, ‘周芷若’, 19, ‘会计’,48000, ‘2006-06-02’, 7,3), (9, ‘丁敏君’, 23, ‘出纳’,5250, ‘2009-05-13’, 7,3), (10, ‘赵敏’, 20, ‘市场部总监’,12500, ‘2004-10-12’, 1,2), (11, ‘鹿杖客’, 56, ‘职员’,3750, ‘2006-10-03’, 10,2), (12, ‘鹤笔翁’, 19, ‘职员’,3750, ‘2007-05-09’, 10,2), (13, ‘方东白’, 19, ‘职员’,5500, ‘2009-02-12’, 10,2), (14, ‘张三丰’, 88, ‘销售总监’,14000, ‘2004-10-12’, 1,4), (15, ‘俞莲舟’, 38, ‘销售’,4600, ‘2004-10-12’, 14,4), (16, ‘宋远桥’, 40, ‘销售’,4600, ‘2004-10-12’, 14,4), (17, ‘陈友谅’, 42, null,2000, ‘2011-10-12’, 1,null);
<a name="P6uLT"></a># 介绍- 笛卡尔积:笛卡尔积是指数学中,两个集合A集合B集合的所有组合情况。(在多表查询的时,需要消除无效笛卡尔积)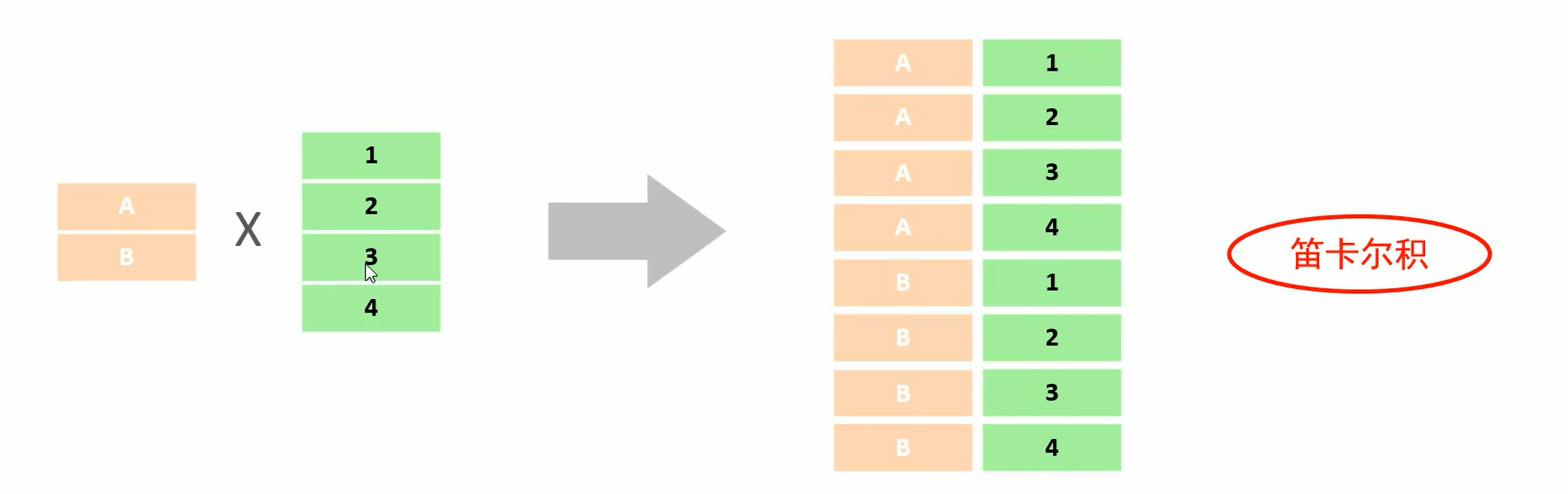- 多表查询分类- 连接查询- 内连接:相当于查询A、B交集部分数据- 外连接- 左外连接:查询左表所有数据,以及两张表交集部分数据- 右外连接:查询右表所有数据,以及两张表交集部分数据- 自连接:当前表与自身的连接查询,自连接必须使用表别名- 子查询- 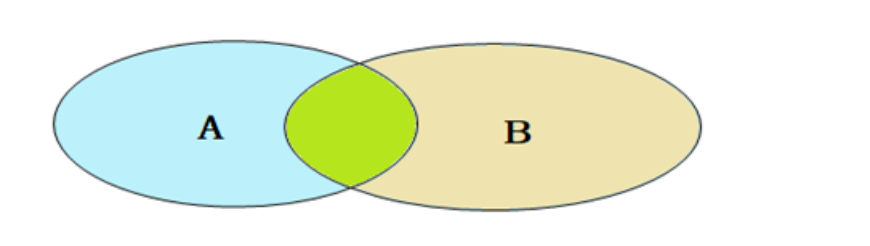<a name="c8oct"></a># 内连接** 内连接的语法分为两种: **```sqlSELECT 字段列表 FROM 表1 , 表2 WHERE 条件 ... ;
SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 ... ;
内连接查询的是两张表交集部分的数 据。(也就是绿色部分的数据) 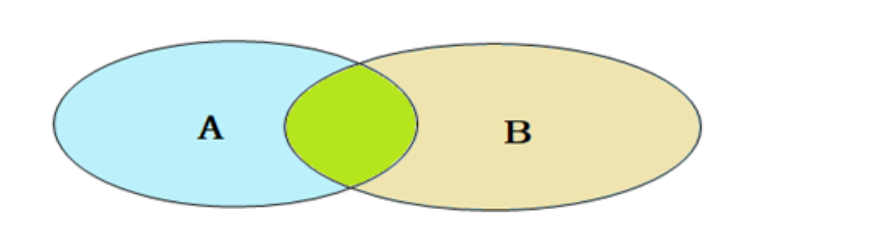
SELECT emp.`name`,dept.`name` FROM dept,emp WHERE emp.dept_id = dept.id
SELECT emp.`name`,emp.job,dept.`name` FROM emp INNER JOIN dept ON emp.dept_id = dept.id
外连接
左外连接
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 ...
右外连接
SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 条件 ...
案列
A. 查询emp表的所有数据, 和对应的部门信息
由于需求中提到,要查询emp的所有数据,所以是不能内连接查询的,需要考虑使用外连接查询。
select e.*, d.name from emp e left join dept d on e.dept_id = d.id;
B. 查询dept表的所有数据, 和对应的员工信息(右外连接)
由于需求中提到,要查询dept表的所有数据,所以是不能内连接查询的,需要考虑使用外连接查 询。
select d.*, e.* from dept d left outer join emp e on e.dept_id = d.id;
自连接
自连接查询,顾名思义,就是自己连接自己,也就是把一张表连接查询多次
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ...
案例
select a.name , b.name from emp a , emp b where a.managerid = b.id;
select a.name '员工', b.name '领导' from emp a left join emp b on a.managerid =b.id;
注意事项: 在自连接查询中,必须要为表起别名,要不然我们不清楚所指定的条件、返回的字段,到底 是哪一张表的字段。
联合查询
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集。
SELECT 字段列表 FROM 表A ...UNION [ ALL ]SELECT 字段列表 FROM 表B ....;
- 对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
- union all 会将全部的数据直接合并在一起,union 会对合并之后的数据去重。
案例:
将薪资低于 5000 的员工 , 和 年龄大于 50 岁的员工全部查询出来.
当前对于这个需求,我们可以直接使用多条件查询,使用逻辑运算符 or 连接即可。 那这里呢,我们 也可以通过union/union all来联合查询.
union all查询出来的结果,仅仅进行简单的合并,并未去重。select * from emp where salary < 5000union allselect * from emp where age > 50;
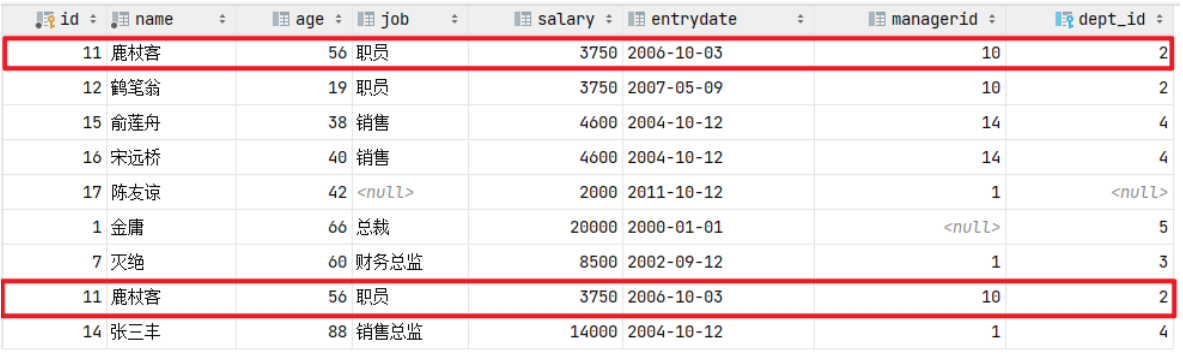
union
union 联合查询,会对查询出来的结果进行去重处理。select * from emp where salary < 5000unionselect * from emp where age > 50;
子查询
子查询外部的语句可以是INSERT / UPDATE / DELETE / SELECT 的任何一个。SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 )
分类 :
根据子查询结果不同,分为:
A. 标量子查询(子查询结果为单个值)
B. 列子查询(子查询结果为一列)
C. 行子查询(子查询结果为一行)
D. 表子查询(子查询结果为多行多列)
根据子查询位置,分为:
A. WHERE之后
B. FROM之后
C. SELECT之后标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。 常用的操作符:= <> > >= < <=
案例: ```sql — 完成这个需求时,我们可以将需求分解为两步: — 1. 查询 “销售部” 部门ID select id from dept where name = ‘销售部’;
— 2. 根据 “销售部” 部门ID, 查询员工信息 select * from emp where dept_id = (select id from dept where name = ‘销售部’);
```sql-- 分解为以下两步:-- 1. 查询 方东白 的入职日期select entrydate from emp where name = '方东白';-- 2. 查询指定入职日期之后入职的员工信息select * from emp where entrydate > (select entrydate from emp where name = '方东白');
列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:IN 、NOT IN 、 ANY 、SOME 、 ALL
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范围之内,多选一 |
| NOT IN | 不在指定的集合范围之内 |
| ANY | 子查询返回列表中,有任意一个满足即可 |
| SOME | 与ANY等同,使用SOME的地方都可以使用ANY |
| ALL | 子查询返回列表的所有值都必须满足 |
案例 :
-- 分解为以下两步:-- 1. 查询 "销售部" 和 "市场部" 的部门IDselect id from dept where name = '销售部' or name = '市场部';-- 2. 根据部门ID, 查询员工信息select * from emp where dept_id in (select id from dept where name = '销售部' orname = '市场部');
-- 分解为以下两步:-- 1. 查询所有 财务部 人员工资select id from dept where name = '财务部';select salary from emp where dept_id = (select id from dept where name = '财务部');-- 2. 比 财务部 所有人工资都高的员工信息select * from emp where salary > all ( select salary from emp where dept_id =(select id from dept where name = '财务部') );
-- 分解为以下两步-- 1. 查询研发部所有人工资select salary from emp where dept_id = (select id from dept where name = '研发部');-- 2. 比研发部其中任意一人工资高的员工信息select * from emp where salary > any ( select salary from emp where dept_id =(select id from dept where name = '研发部') );
行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<> 、IN 、NOT IN
案例:
-- 这个需求同样可以拆解为两步进行:-- 1. 查询 "张无忌" 的薪资及直属领导select salary, managerid from emp where name = '张无忌'-- 2. 查询与 "张无忌" 的薪资及直属领导相同的员工信息 ;select * from emp where (salary,managerid) = (select salary, managerid from empwhere name = '张无忌');
表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。
常用的操作符:IN
案例:
-- 分解为两步执行:-- 1. 查询 "鹿杖客" , "宋远桥" 的职位和薪资select job, salary from emp where name = '鹿杖客' or name = '宋远桥'-- 2. 查询与 "鹿杖客" , "宋远桥" 的职位和薪资相同的员工信息select * from emp where (job,salary) in ( select job, salary from emp where name ='鹿杖客' or name = '宋远桥' );
-- 分解为两步执行:-- 1. 入职日期是 "2006-01-01" 之后的员工信息select * from emp where entrydate > '2006-01-01'-- 2. 查询这部分员工, 对应的部门信息 (将1的sql作为一张临时表)select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e leftjoin dept d on e.dept_id = d.id ;

若有收获,就点个赞吧
0 人点赞
