1、计算机硬件处理器
在计算机中,所有的运算操作都是由处理器(CPU)的寄存器来完成的,处理器指令的执行过程需要涉及数据的读取和写入操作,处理器所能访问的所有数据只能是计算机的主内存(通常是 RAM),这里涉及到处理器与内存之间的交互,如读取运算数据、存储运算结果等,这个 I/O 操作就是很难消除的(无法仅靠寄存器来完成所有运算任务)。虽然处理器的发展频率不断得到提升,但受到制造工艺以及成本等的限制,计算机的内存反倒在访问速度上并没有多大的突破,因此处理器的处理速度和内存的访问速度之间的差距越拉越大,通常这种差距可以达到上千倍,极端情况下甚至会在上万倍以上。
1.1、处理器缓存模型
由于计算机的存储设备预处理器的运算速度有几个数量级的差距,所以现代计算机系统不得不加入一层读写速度尽可能快接近处理器运算速度的高速缓存来作为内存与处理器之间的缓冲:将运算需要使用的数据复制到缓存中,让运算能快速进行,当运算结束后再从缓存同步到内存中,这样处理器就无须等待缓慢的内存读写了。现在缓存的数量都可以增加到 3 级了,最靠近处理器的缓存称为 L1,然后一次是 L2,L3 和主内存,处理器缓存模型如图所示
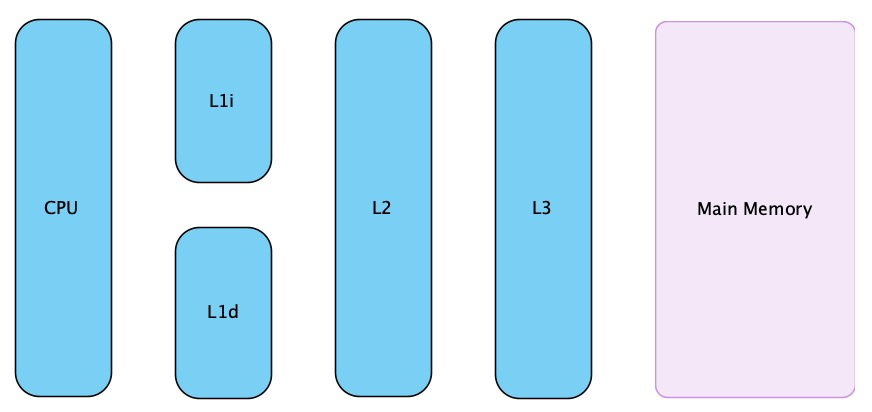
由于程序指令和程序数据的行为和热点分布差异很大,因此 L1 缓存又被划分为 L1i(i 代表 instruction)和 L1d(d 代表 data)这两种有各自专门用途的缓存,处理器缓存又是由很多个缓存行(cache line)构成的,缓存行是处理器缓存中的最小缓存单位,目前主流处理器缓存的缓存行大小是 64 字节。
主内存以及各级缓存之间的响应时间对比如图所示。通过图,可以知道主内存的读写速度远远低于处理器缓存的速度,更别说是处理器本身的计算速度了
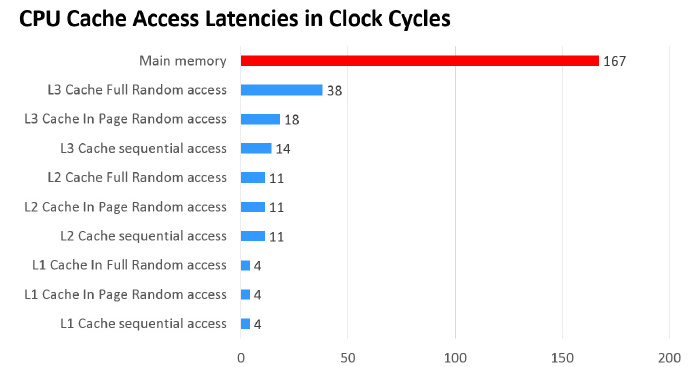
缓存的出现是为了解决处理器直接访问内存效率低下的问题,程序在运行过程中,会将运算所需的数据从主内存复制一份到处理器缓存中。这样处理器进行计算时就可以直接对处理器缓存中的数据进行读取和写入操作了,当运算结束之后,再将处理器缓存中的最新数据刷新到主内存中,处理器通过直接访问缓存的方式替代直接访问主内存的方式极大地提高了处理器的吞吐能力。有了处理器缓存之后,整体处理器和主内存之间交互大致如图所示

1.2、缓存一致性问题
基于高速缓存的存储交互很好地解决了处理器与内存的速度矛盾,但是也为计算机系统带来更高的复杂度,因为它引入了一个新的问题,缓存一致性(Cache Coherence)。在多个处理器系统中,每个处理器都有自己的缓存,而它们又共享同一主内存(Main Memory)。当多个处理器的运算任务都涉及同一块主内存区域时,将可能导致各自的缓存数据不一致。
比如 i++ 这个操作,在程序的运行过程中,首先需要将主内存中的数据复制一份存放到处理器缓存中,那么 CPU 寄存器在进数值计算的时候就直接到缓存中读取和写入,当整个过程运算结束之后再将缓存中的数据刷新至主内存中,具体过程如下:
- 读取主内存的 i 到 CPU Cache
- 对 i 进行加 1 操作
- 将结果回写到 CPU Cache
- 将数据刷新至主内存中
i++ 单线程的情况不会出现任何问题,但是在多线程的情况下就回有问题,每个线程都有自己的工作内存(本地内存,对应于处理器的缓存),变量 i 会在多个线程的本地内存中都存一个副本。如果同时有两个线程执行 i++ 操作,假设 i 的初始值为 0,每一个线程都从主内存中获取 i 的值存入处理缓存中,然后经过计算再写入主内存中,很有可能 i 在经过了两次自增之后结果还是
1,这就是典型的缓存不一致性的问题。解决缓存一致性的问题,通常有两种方式
- 通过总线加锁
- 通过缓存一致性协议
缓存一致性协议有 MSI、MESI、MOSI、Synapse、Firefly 及 Dragon Protocol 等。 其中 Intel 处理器用的是 MESI,MESI 协议保证了每一个缓存中使用的共享变量副本是一致的,它的大致思想是,当处理器在操作缓存中的数据时,如果发现该变量是一个共享变量,也就是说在其他处理器其的缓存中也存在一个副本,那么进行如下操作
- 读取操作,不做任何处理,只是将缓存中的数据读取到期存器中
- 写入操作,发出信号通知其他处理器将该共享变量的缓存行置位无效状态,其他处理器在进行读取的时候不得不到主内存中再次获取
第一种是常见于早期的处理器当中,而且是一种悲观的实现方式,处理器和其他组件的通信都是通过总线(数据总线、控制总线、地址总线)来进行的,如果采用总线锁的方式,则会阻塞其他处理器对其他组件的访问,从而使得只有一个处理器能够访问到这个变量的内存。这种方式效率低下,所以就有了第二种通过缓存一致性协议的方式来解决不一致的问题。如图所示

除了增加缓存之外,为了使得处理器内部的运算单元被充分利用,处理器可能会对输入的代码进行乱序执行(Out-Of-Order Execution)优化,处理器会在计算之后将乱序执行的结果重组,保证该结果与顺序执行的结果是一致的,但并不保证程序中各个语句计算的先后顺序与输入代码中的顺序一致。因此,如果存在一个计算任务依赖另外一个计算任务的中间结果,那么其顺序并不能靠代码的先后顺序来保证。与处理器的乱序执行优化类似,Java 虚拟机的即时编译器中也有类似的指令重排序(Instruction Reorder)的优化
1.3、伪共享
1.3.1、什么是伪共享
当处理器访问某个变量时,首先会去看处理器缓存内是否有该变量了,如果有则直接从中获取,否则就去主内存里面获取该变量,然后把该变量所在内存区域的一个缓存行大小的内存复制到缓存中。由于存放到缓存行的是内存块而不是单个变量,所以可能会把多个变量存放到一个缓存行中。当多个线程同时修改一个缓存行里面的多个变量时,由于同时只能有一个线程操作缓存行,所以相比将每个变量每个变量放到一个缓存行,性能会有所下降,这就是伪共享。即位于同一缓存行的两个不同数据,被两个不同CPU锁定,产生互相影响的伪共享问题,如图。
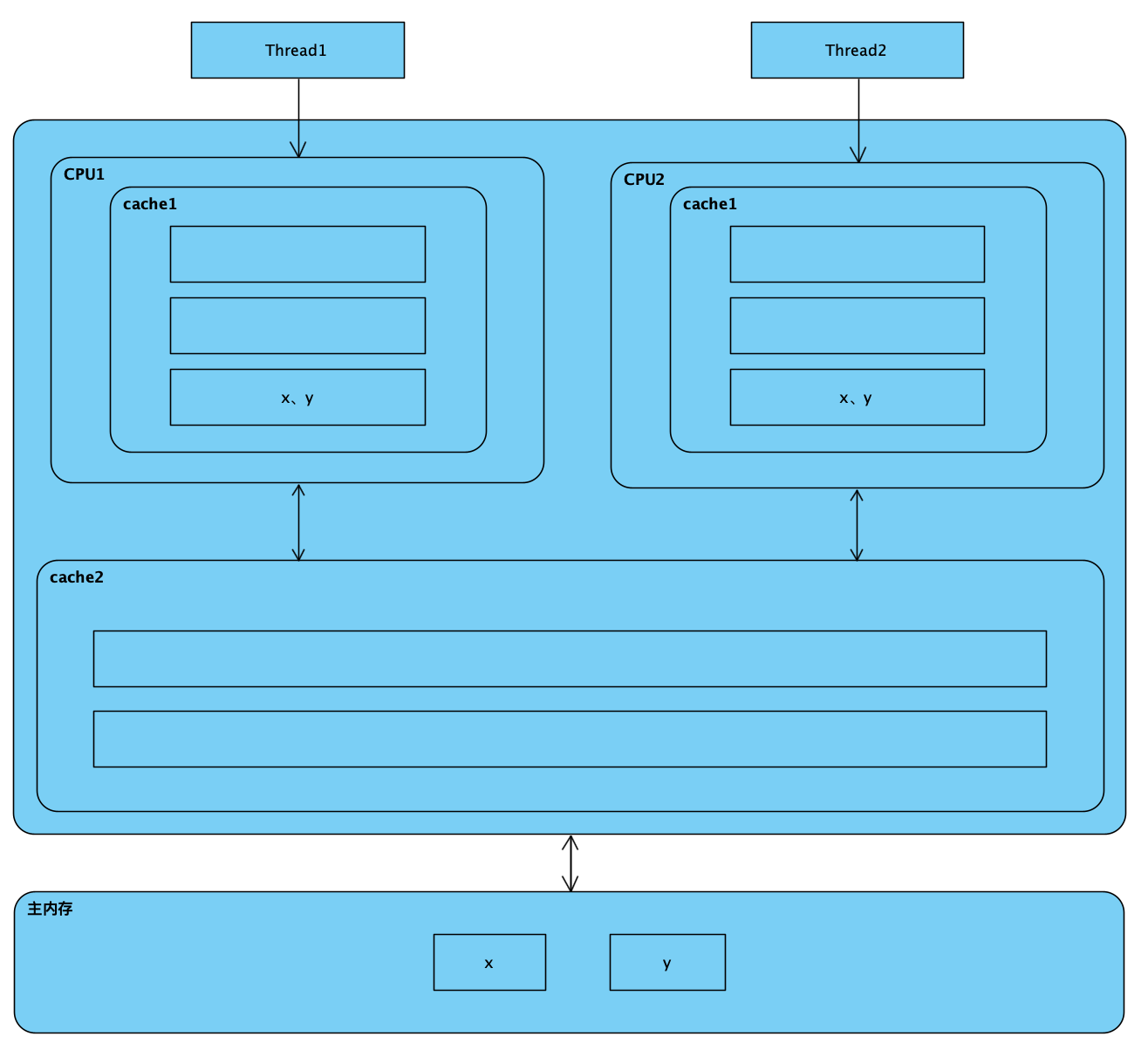
该图中,变量 x 和 y 同时被放到了处理器的一级和二级缓存,当线程1 使用 CPU1 对变量 x 进行更新时,首先会修改 CPU1 的一级缓存变量 x 所在的缓存行,这时候在缓存一致性协议下,CPU2 中变量 x 对应的换行失效。那么线程2 在写入变量 y 时,就只能去二级缓存里查找,这就破坏了一级缓存。而一级缓存比二级缓存更快,这也说明了多个线程不可能同时去修改自己所使用的处理器中相同缓存行里面的变量。更坏的情况是,如果处理器只有一级缓存,则会导致频繁地访问主内存。下面这段代码会导致执行时间偏长
package com.yj.jmm;/*** @description: 伪共享* @author: erlang* @since: 2021-01-09 14:54*/public class CacheLineNonPadding {public static class NonPadding {private volatile long value = 0L;public long getValue() {return value;}public void setValue(long value) {this.value = value;}}public static NonPadding[] arr = new NonPadding[2];static {arr[0] = new NonPadding();arr[1] = new NonPadding();}}
1.3.2、如何避免伪共享
在 JDK8 之前一般都是通过字节填充的方式来避免该问题的,也就是创建一个变量时使用填充字段填充该变量所在的缓存行,这样就避免了将多个变量存放在同一个缓存行中。如图所示
package com.yj.jmm;/*** @description: 缓存行填充* @author: erlang* @since: 2021-01-09 15:02*/public class CacheLinePadding {public static class Padding {// long 8 字节public volatile long p1, p2, p3, p4, p5, p6, p7;// 前面用 7 个 long 类型变量填充// 缓存行 64 位,可以存八个 long 类型变量private volatile long value = 0L;public long getValue() {return value;}public void setValue(long value) {this.value = value;}}public static Padding[] arr = new Padding[2];static {arr[0] = new Padding();arr[1] = new Padding();}}
JDK8 提供了一个 sun.misc.Contended 注解,用来解决伪共享问题。将上面的代码修改为如下
package com.yj.jmm;import sun.misc.Contended;/*** @description: 使用 Contendded 注解解决伪共享问题* 如果该用户类路径下的类需要使用这个注解,则需要添加 JVM 参数:-XX:-RestrictContended* 填充的宽度默认认为 128,要自定义宽度则可以设置 -XX:ContendedPaddingWidth 参数* 这里的参数设置为:-XX:-RestrictContended -XX:ContendedPaddingWidth=56* @author: erlang* @since: 2021-01-09 15:18*/public class CacheLinePaddingContended {@Contendedpublic static class Padding {public volatile long value = 0L;public long getValue() {return value;}public void setValue(long value) {this.value = value;}}public static Padding[] arr = new Padding[2];static {arr[0] = new Padding();arr[1] = new Padding();}}
需要注意的是,在默认情况下,sun.misc.Contended 注解只用于核心类,比如 rt 包下的类,用户类路径下该注解无效。如果需要使这个注解生效,则需要添加 JVM 参数:-XX:-RestrictContended;填充的宽度默认认为 128,要自定义宽度则可以设置 -XX:ContendedPaddingWidth 参数。
2、Java 内存模型
Java 虚拟机规范中试图定义一种 Java 内存模型(Java Memory Model,JMM)来屏蔽掉各种硬件和操作系统的内存访问差异,指定虚拟机如何与计算机的主内存(RAM)进行工作,以实现让 Java 程序在各种平台下都能达到一致内存访问效果。
在此之前,主流程序语言(如 C/C++)直接使用物理硬件和操作系统的内存模型,因此,会由于不同平台上内存模型的差异,有可能导致程序在一套平台上并发完全正确,而在另外一套平台上并发访问却经常出错,因此在某些场景就必须针对不同的平台来编写程序。
定义 Java 内存模型并非一件容易的事情,这个模型必须定义得足够严谨,才能让 Java 的并发内存访问操作不会产生歧义;但是,也必须定义的足够宽松,使得虚拟机的实现有足够的空间去利用硬件的各种特性(寄存器、高速缓存和指令集中某些特有的指令)来获取更好的执行速度。在 JDK1.5 以前的版本中,Java 内存模型存在着一定的缺陷,在 JDK1.5 的时候,JDK 官方对 Java 内存模型重新进行了修订,在 JDK1.8 及最新的在 JDK 版本都沿用了 JDK1.5 修订的内存模型。
2.1 并发编程模型的两个关键问题
在并发编程中,需要处理两个关键问题:线程之间如何通信和线程之间如何同步(这里的线程是指并发执行的活动实体)。通信是指线程之间以何种机制来交换信息。在命令式编程中,线程之间的通信机制有两种:共享内存(Shared Memory)和消息传递(CSP和Actor模型)。
- 在共享内存的并发模型里,线程之间共享程序的公共状态,通过写-读内存中的公共状态进行隐式通信。
- 线程 Threads
- 锁 Locks
- 互斥量 Mutexes
- 在消息传递的并发模型里,线程之间并没有公共状态,线程之间必须通过发送消息来显式进行通信。
- 进程 Processes
- 消息 Messages
- 不共享数据(状态) No shared data
同步是指程序中用于控制不同线程间操作发生相对顺序的机制。在共享内存并发模型里,同步是显式进行的。程序员必须显式指定某个方法或某段代码需要在线程之间互斥执行。在消息传递的并发模型里,由于消息的发送必须在消息的接收之前,因此同步是隐式进行的。
Java 的并发模型采用的是共享内存模型,Java 线程之间的通信总是隐式进行的,整个通信过程对程序员完全透明的。如果编写多线程程序的 Java 程序员不理解隐式进行的线程通信的工作机制,很可能会遇到各种奇怪的内存可见性问题。
2.2、主内存与工作内存
Java 内存模型的主要目标是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节。此处的变量(Variables)与 Java 编程中所说的变量有所区别,它包括了实例字段、静态字段和构成数组对象的元素,但不包括局部变量与方法参数,因为后者是线程私有的,不会被共享,自然就不会存在竞争问题。
如果局部变量是一个 reference 类型,它引用的对象在 Java 堆中可被各个线程共享,但是 reference 本身在 Java 栈的局部变量表中,它是线程私有的 Java 的内存模型决定一个线程对共享变量的写入何时对其他线程可见
为了获得较好的执行效能,Java 内存模型并没有限制执行引擎使用处理器的特定寄存器或缓存来和主内存进行交互,也没有限制即时编译器进行调整代码执行顺序这类优化措施。
Java 内存模型规定了所有的变量都存在主内存(Main Memory)中。每条线程还有自己的工作内存(Working Memory),线程的工作内存中保存了该线程使用到的变量的主内存副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存存中的变量。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成,线程、主内存、工作内存三者之间的关系,如图所示。
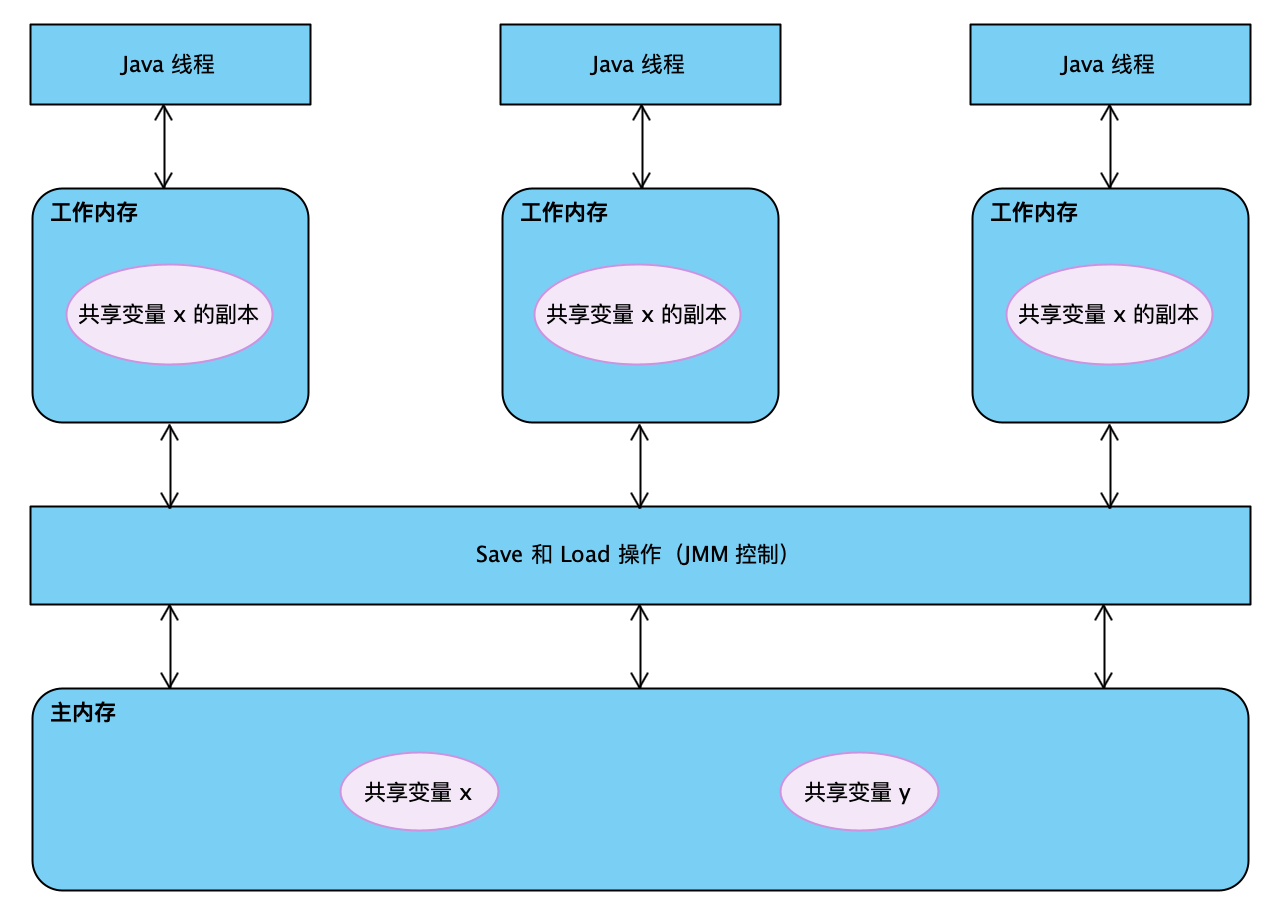
- 这里的副本,如:假设线程访问一个 10MB 的对象,也会把这个 10MB 的内存复制一份拷贝出来吗?事实上并不会如此,这个对象的引用、对象中某个在线程中访问到的字段是有可能被复制的,但不会有虚拟机实现成把整个对象复制一次
这里所讲的主内存、工作内存与 Java 内存区域中的 Java 堆、栈、方法区等并不是同一个层次的内存划分,这两者基本上是没有关系的,如果两者一定要勉强对应起来,那从变量、主内存、工作内存的定义来看,主内存主要对应于 Java 堆中的对象实例数据部分,而工作内存则对应于虚拟机栈中的部分区域。从更低层次上说,主内存就直接对应于物理硬件的内存,而为了获取更好的运行速度,虚拟机(或者是硬件、操作系统本身的优化措施)可能会让工作内存优先存储于寄存器和高速缓存中,因为程序运行时主要访问读写的是工作内存。
- 工作内存和 Java 内存模型一样也是一个抽象的概念,它其实并不存在,它涵盖了缓存、寄存器、编译器优化以及硬件等
- 共享变量存储于主内存之中,每个线程都可以访问
- Java 堆中,除了实例数据,还保存了对象的其他信息,对于 HotSpot 虚拟机来讲,有 Mark Word(存储对象哈希码、GC 标志、GC 年龄、同步锁等信息),Klass Point(指向存储类型元数据指针)及一些字节对齐补白的填充数据(如果实例数据刚好满足 8 字节对齐的话,则可以不存在补白)
2.3、线程之间的通信
如图,如果线程 A 与线程 B 之间要通信的话,必须要经历下面两个步骤。
- 线程 A 把本地内存 A 中更新过的共享变量刷新到主内存中
- 线程 B 到主内存中去读取线程 A 之前已更新过的共享变量到本地内存 B 中
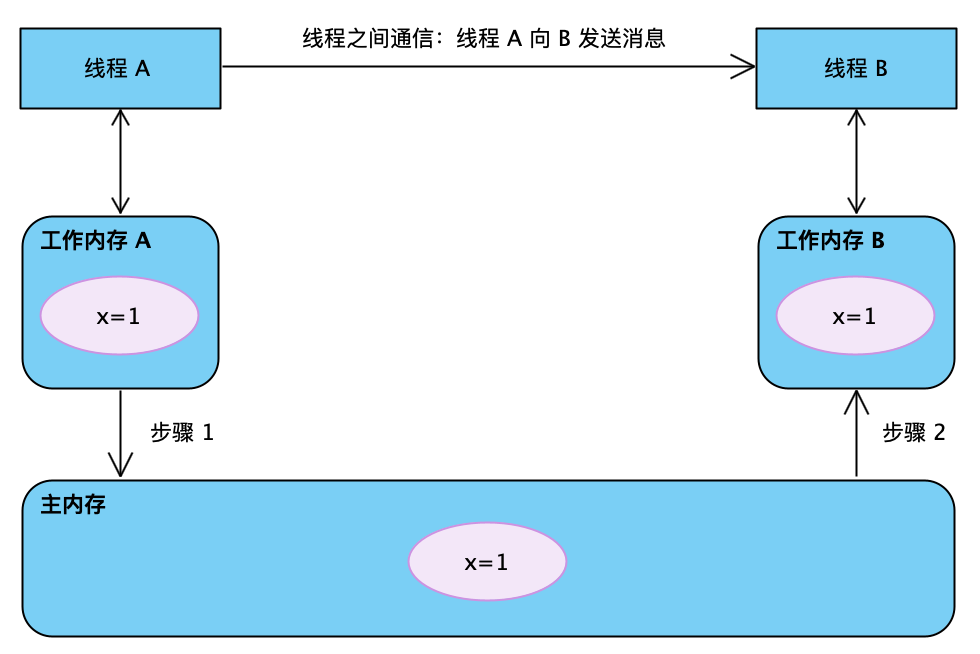
上图,工作内存 A 和工作内存 B 有主内存中共享变量 x 的副本,假设初始时,这三个内存中的 x 都是 0。两个线程之间如何保证可见性的呢?
- 线程 A 执行时,把更新后的 x=1 的值临时存放在自己的工作内存中。
- 当线程 A 和线程 B 需要通信时,线程 A 首先会把自己工作内存中修改后的 X 值刷新到主内存中,此时主内存中的 x 值为 1
- 最后,线程 B 到主内存中去读取线程 A 更新后的 x 值,此时线程 B 的工作内存中 x 的值也变成了 1
从整体来看,这两个步骤实质上是线程 A 在向线程 B 发送消息,而且这个通信过程必须要经过主内存。JMM 通过开工至主内存与每个线程的工作内存之间的交互,来为 Java 程序员提供内存可见性保证。
2.4、内存间交互操作
关于主内存与工作内存之间具体的交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步回主内存之类的实现细节,Java 内存模型定义了 8 中操作来完成,虚拟机实现时必须保证下面提交的每一种操作都是原子的、不可再分(对于 double 和 long 类型来说,load、store、read 和 write 操作在某些平台上允许有例外)。
- lock(锁定):主内存,它把一个变量标识为一条线程独占的状态
- unlock(解锁):主内存,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
- read(读取):主内存,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的 load 动作使用
- load(载入):工作内存,它把 read 操作从主内存中得到的变量值放入到工作内存的变量副本中
- use(使用):工作内存,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节指令时,将会执行这个操作
- assing(赋值):工作内存,它把一个执行引擎接收到的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作
- store(存储):工作内存,它把一个工作内存中一个变量的值传送到主内存中,以便随后的 write 操作使用
- write(写入):主内存,它把 store 操作从工作内存中得到的变量的值放入主内存的变量中
如果要把一个变量从主内存复制到工作内存,那就要顺序地执行 read 和 load 操作,如果要把变量从工作内存同步回主内存,就要顺序地执行 store 和 write 操作。注意,Java 内存模型要求上述两个操作必须按顺序执行,而没有保证是连续执行。也就是说,read 与 load 之间,store 和 write 之间是可插入其他指令的,如对主内存中的变量 a、b 进行访问时,一种可能出现顺序是 read a、read b、load b、load a。除此之外,Java 内存模型还规定了在执行上述 8 种基本操作时必须满足如下规则:
- 不允许 read 和 load、store 和 write 操作之一单独出现;即不允许一个变量从主内存读取了,但工作内存不接受;或者从工作内存发起回写了但主内存不接受的情况出现
- 不允许一个线程丢弃它最近的 assign 操作;即变量在工作内存中改变了之后,必须把该变化同步会主内存
- 不允许一个线程无原因地(没有发生过任何 assign 操作)把数据从线程的工作内存同步会主内存中
- 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load 或 assign)的变量,换句话说就是对一个变量实施 use、store 操作之前,必须执行 assign 和 load 操作。
- 一个变量在同一个时刻只允许一条线程对进行 lock 操作,但 lock 操作可以被同一条线程重复执行多次,多次执行 lock 后,只有执行相同次数的 unlock 操作,变量才会被解锁
- 如果对一个变量执行 lock 操作,那将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行 load 或 assign 操作以初始化变量的值
- 如果一个变量事先没有被 lock 操作锁定,那就不允许对它执行 unlock 操作,也不允许去 unlock 一个被其他线程锁定的变量
- 对一个变量执行 unlock 操作之前,必须先把此变量同步回主内存中(执行 store、write 操作)

若有收获,就点个赞吧
0 人点赞
