1、可见性和有序性
导致可见性的原因是缓存,导致有序性的原因是编译优化。那解决可见性、有序性最直接的办法就是禁用缓存和编译优化,如果真的这样操作,问题是解决了,但是系统的整体性能就堪忧了。
合理的方案应该是按需禁用缓存以及编译优化。那么,如何做到按需禁用呢?对于并发程序,何时禁用缓存以及编译优化只用程序员知道,那所谓按需禁用其实就是指按照程序员的要求来禁用。所以,为了解决可见性和有序性问题,只需提供给程序员按需禁用缓存和编译优化的方法即可。
JMM 是一个较为复杂的规范,可以从不同的视角解读,从程序员的视角来看,JMM 规范了 JVM 如何提供按需禁用缓存和编译优化的方法,主要是 JVM 提供的三个关键字以及 Happens-Before 规则。
- volatile
- synchronized
- final
- Happens-Before 规则
其中 volatile、synchronized 两个关键字前面已经做过详细介绍,这里主要说一下 final 和 Happens-Before 规则。
2、final 关键字
final 修饰变量时,初衷是告诉编译器:这个变量生而不变,可以毫无顾虑的优化。JMM 中 volatile 变量在写操作之后会插入一个 store 屏障,在读操作之前会出入 load 屏障。final 变量会在初始化后插入一个 store 屏障,来确保 final 字段在构造函数一旦初始化完成,并且在构造器没有把 this 的引用传递出去(this 引用逃逸是一件很危险的事情,其他线程可能通过这个引用访问到初始化了一半的对象),那对其他线程中是可见的。
3、Happens-Before 规则
3.1、JMM 的设计
从 JMM 的设计者的角度,在设计 JMM 时,需要考虑两个关键因素。
- 程序员对内存模型的使用。程序员希望内存模型易于理解、易于编程。程序员希望基于一个强内存模型来编写代码
- 编译器和处理器对内存模型的实现。编译器和处理器希望内存模型对它们的约束越少越好,这样它们就可以尽可能多的优化来提高性能。编译器和处理器希望实现一个弱内存模型。
JMM 把 Happens-Before 要求禁止的重排序分了两类
- 会改变程序执行结果的重排序
- 不会改变程序结果的重排序
JMM 对这两种不同性质的重排序,采取了不同的策略
- 对于第一种,JMM 要求编译器和处理器必须禁止这种重排序
- 对于第二种,JMM 对编译器和处理器不做要求,也就是说 JMM 允许这种排序
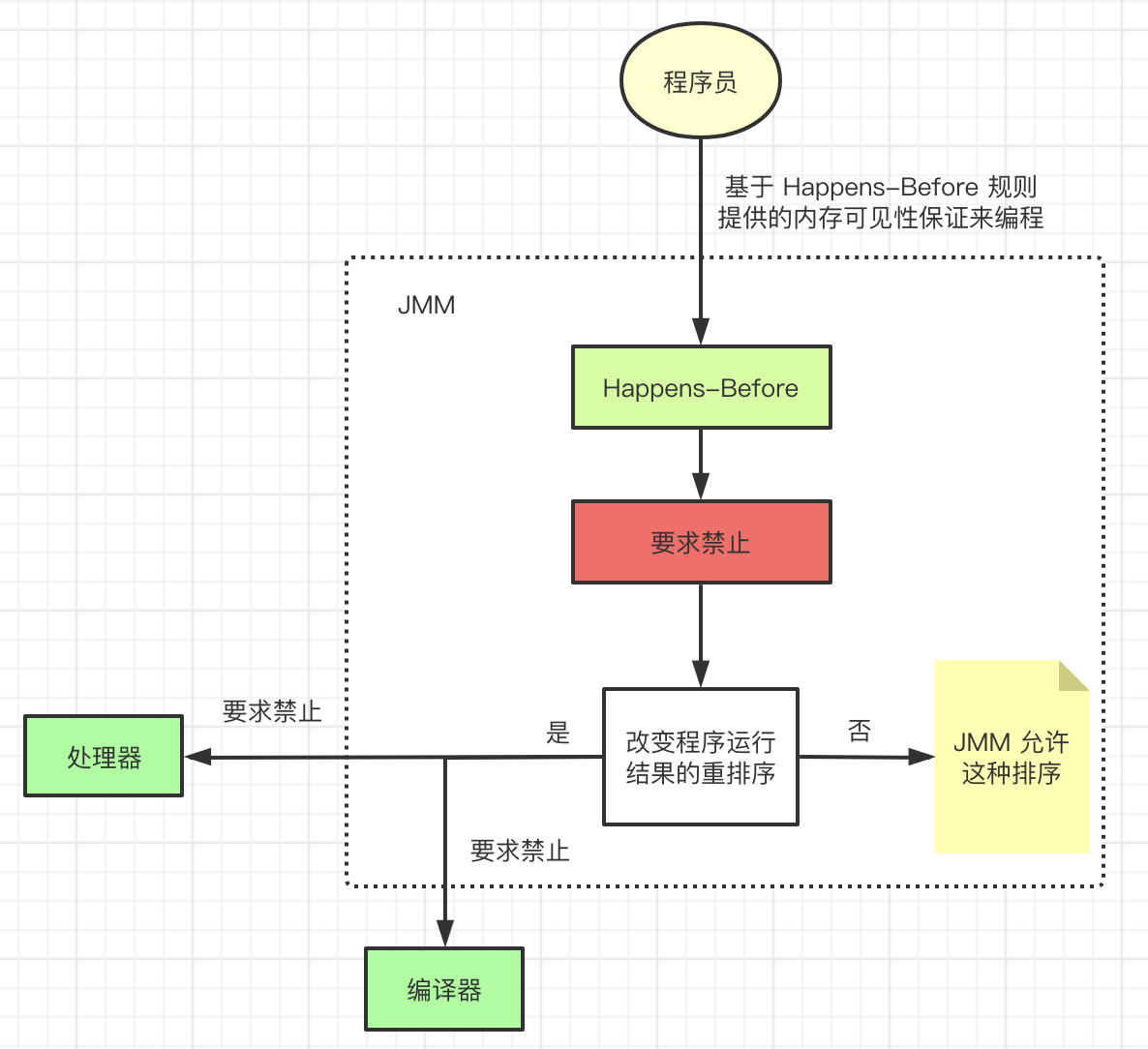
3.2、Happens-Before 的定义 JSR-133
- 如果一个操作 Happens-Before 另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前
- 两个操作之间存在 Happens-Before 关系,并不意味着 Java 平台的具体实现就必须按照 Happens-Before 关系指定的顺序来执行。如果重排序之后的执行结果,与按 Happens-Before 关系来执行的结果一致,那么 JMM 是允许两个操作进行重排序的
3.3、Happens-Before 的规则
如果 Java 内存模型中所有的有序性都仅仅依靠 volatile 和 synchronized 来完成,那么有一些操作将会变得很繁琐,但是我们在编写 Java 并发代码的时候并没有感觉到这点。
Happens-Before 并不是说前面一个操作发生在后续操作的前面,它真正表达的是:前面一个操作的结果对后续可见。也就是说 Happens-Before 约束了编译器的优化行为,虽允许编译器优化,但是要求编译器优化后一定遵守 Happens-Before 规则。
下面是 Java 的内存模型具备的一些天然的有序规则,不需要任何同步手段就能够保证有序性,这个规则被称为 Happens-Before。如果两个操作的执行次序无法从 Happens-Before 规则推导出来,那么它们就无法保证有序性,也就是说虚拟机或者处理器可以随意对它们进行重排序处理。
3.3.1、程序次序规则(Program Order Rule)
在一个线程内,代码按照编写时的顺序执行,编写在前面的操作先行发生于编写在后面的操作。准确地说,应该是控制流顺序而不是程序代码顺序,因为要考虑分支、循环等结构。
下面的代码片段,按照程序的顺序,x = 1; 先行发生于 v = true;,这就是规则 1 的内容,也比较符合单线程里面的思维:程序前面对某个变量的修改一定是对后续操作是可见的。
public void writer() {x = 1;v = true;}
3.3.2、管程锁定规则(Monitor Lock Rule)
一个 unlock 操作先行发生于后面对同一个锁的 lock 操作。这里必须强调的是同一个锁,二后面是指时间上的先后顺序。
管程是一种通用的同步原语,在 Java 中指的就是 synchronized,synchronized 是 Java 里对管程的实现。管程中的锁在 Java 里是隐式实现的,代码如下,在进入代码块之前,会自动加锁;而在代码块执行完成自动释放锁,加锁以及解锁都是编译器实现的。代码片段如下:
public void sync() {synchronized (this) { // 自动加锁if (x == 2) {v = true;}} // 自动解锁}
3.3.3、线程启动规则(Thread Start Rule)
Thread 对象的 start 方法先行发生对该线程的任何操作。这也是在执行 start 方法后,线程才算是真正运行,否则 Thread 也只是一个普通对象。代码片段如下:
public void thread_start() {this.x = 10;Thread thread = new Thread(() -> {// 主线程调用 thread.start() 之前// 所有对共享变量的修改,此处皆可见// 此例中,this.x = 20System.out.println(this.x);});// 此处对共享变量 x 修改this.x = 20;// 主线程启动子线程thread.start();}
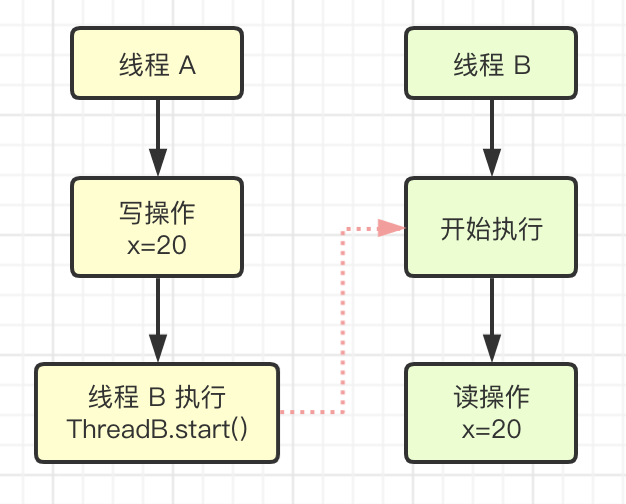
3.3.4、线程终止规则(Thread Termination Rule)
线程中的所有操作都先行发生于线程的终止检测,换句话说,线程的任务执行、逻辑单元执行肯定要发生于线程死亡之前。这里我们可以通过 Thread.join 方法结束、Thread.isAlive 方法的返回值等手段检测到线程已经终止执行。代码片段如下:
public void thread_join() throws InterruptedException {Thread thread = new Thread(() -> {// 此处对共享变量 x 修改this.x = 34;});// 例如此处对共享变量修改,// 则这个修改结果对线程 thread 可见// 主线程启动子线程thread.start();thread.join();// 子线程所有对共享变量的修改// 在主线程调用 thread.join() 之后皆可见// 此例中,x=34System.out.println(this.x);}

3.3.5、线程中断规则(Thread Interruption Rule)
对线程执行 interrupt 方法肯定要先行发生于捕获到中断信号;换句话说,如果线程收到了中断信号,那么在此之前肯定是先执行了 interrupt 方法。这里可以通过 Thread.interrupted 方法检测到线程是否中断发生。代码片段如下:
public void thread_interrupt() throws InterruptedException {this.x = 0;Thread thread = new Thread(() -> {while (!Thread.currentThread().interrupted()) {this.x++;}System.out.println("循环结束时: x = " + this.x);});// 主线程启动子线程thread.start();Thread.sleep(1000);thread.interrupt();System.out.println("线程是否中断:" + thread.isInterrupted());System.out.println("线程结束: x = " + this.x);}

3.3.6、对象终结规则(Finalizer Rule)
一个对象的初始化完成(构造函数执行结束)先行发生于 finalize 方法的之前,先生后死
3.3.7、volatile 变量规则(Volatile Variable Rule)
对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作,这里的后面同样是指时间上的先后顺序。对一个 volatile 变量的写操作相对于后续对这个 volatile 变量的读操作可见,这里怎么看都是禁用缓存的意思。如果单看这个规则,确实是这样,这里可以关联一下下面的规则:传递性,会有不一样的感觉
3.3.8、传递性(Transitivity)
如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,那就可以得出操作 A 先行发生于操作 C 的结论。
这里将传递性应用到我们的例子中,会发生什么呢?可以看下面这幅图:
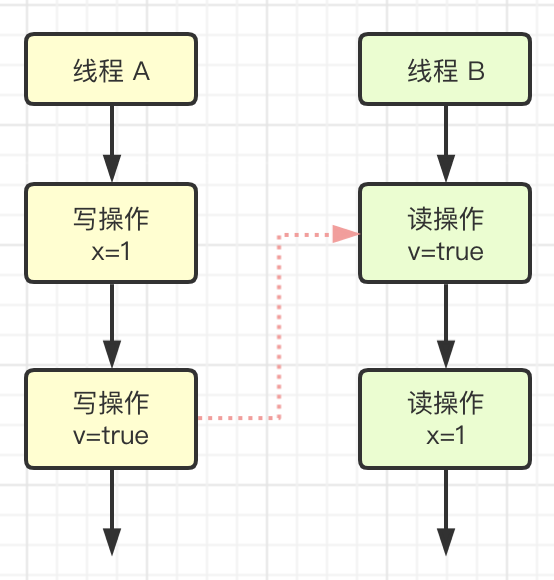
如图,可知:
- 写操作
x=1先行发生于写操作v=true,这是规则 1 的内容 - 写操作
v=true先行发生于读操作v=true,这是规则 2 的内容
再根据这个传递性规则,我们得到结果:x=1先行发生于读变量v=true。这意味着什么呢?
如果线程 B 读到了v=true,那么线程 A 设置的x=1对线程 B 是可见的;也就是说,线程 B 能看到 x=1 。这就是 1.5 版本对 volatile 语义的增强,这个增强意义重大,1.5 版本的并发工具包(java.util.concurrent)就是靠 volatile 语义来搞定可见性的。代码片段如下:
public void writer() {x = 1;v = true;}public void reader() {if (v) {// 这里x会是多少呢?System.out.println("reader: x=" + x);}}public void transitivity() throws InterruptedException {Thread reader = new Thread(this::reader, "volatile test");Thread writer = new Thread(this::writer, "volatile test");// 先执行 写操作writer.start();// 后执行,读操作reader.start();writer.join();reader.join();}
3.3.9、测试代码
package com.yj.order;/*** @description: happens before demo* @author: erlang* @since: 2021-01-10 22:54*/public class TestHappensBefore {int x = 0;volatile boolean v = false;public void writer() {x = 1;v = true;}public void reader() {if (v) {// 这里x会是多少呢?System.out.println("reader: x=" + x);}}public void transitivity() throws InterruptedException {Thread reader = new Thread(this::reader, "volatile test");Thread writer = new Thread(this::writer, "volatile test");// 先执行 写操作writer.start();// 后执行,读操作reader.start();writer.join();reader.join();}public void sync() {synchronized (this) { // 加锁if (x == 2) {v = true;}} // 自动解锁}public void thread_start() {this.x = 10;Thread thread = new Thread(() -> {// 主线程调用 thread.start() 之前// 所有对共享变量的修改,此处皆可见// 此例中,this.x = 20System.out.println(this.x);});// 此处对共享变量 x 修改this.x = 20;// 主线程启动子线程thread.start();}public void thread_join() throws InterruptedException {Thread thread = new Thread(() -> {// 此处对共享变量 x 修改this.x = 34;});// 例如此处对共享变量修改,// 则这个修改结果对线程 thread 可见// 主线程启动子线程thread.start();thread.join();// 子线程所有对共享变量的修改// 在主线程调用 thread.join() 之后皆可见// 此例中,x=34System.out.println(this.x);}public void thread_interrupt() throws InterruptedException {this.x = 0;Thread thread = new Thread(() -> {while (!Thread.currentThread().interrupted()) {this.x++;}System.out.println("循环结束时: x = " + this.x);});// 主线程启动子线程thread.start();Thread.sleep(1000);thread.interrupt();System.out.println("线程是否中断:" + thread.isInterrupted());System.out.println("线程结束: x = " + this.x);}public static void main(String[] args) throws InterruptedException {TestHappensBefore test = new TestHappensBefore();test.thread_start();test.thread_join();test.transitivity();}}
4、重排序对多线程的影响
4.1、实例代码
package com.yj.order;/*** @description:* @author: erlang* @since: 2021-01-11 22:39*/public class TestReorder {int x = 0;boolean v = false;public void writer() {x = 1; // 1v = true; // 2}public void reader() {if (v) { // 3int y = x + 1; // 4}}}
4.2、结果分析
这里假设两个线程 A 和 B,A 先执行 writer 方法,随后 B 线程接着执行 reader 方法。线程 B 在执行操作 4 时,能否看到线程 A 在操作 1 之后对共享变量 x 的写入呢?这里是不一定能看到的。
由于操作 1 和操作 2 没有数据依赖关系,编译器和处理器可以对这两个操作重排序;操作 3 和操作 4 同理。

如图,操作 1 和操作 2 做了重排序。程序执行时,线程 A 首先写入变量 v,随后线程 B 读取这个变量。由于条件判断是 true,线程 B 将读取变量 a。此时,变量 a 还没被线程 A 写入,在这里多线程程序的语义就被重排序破坏了。
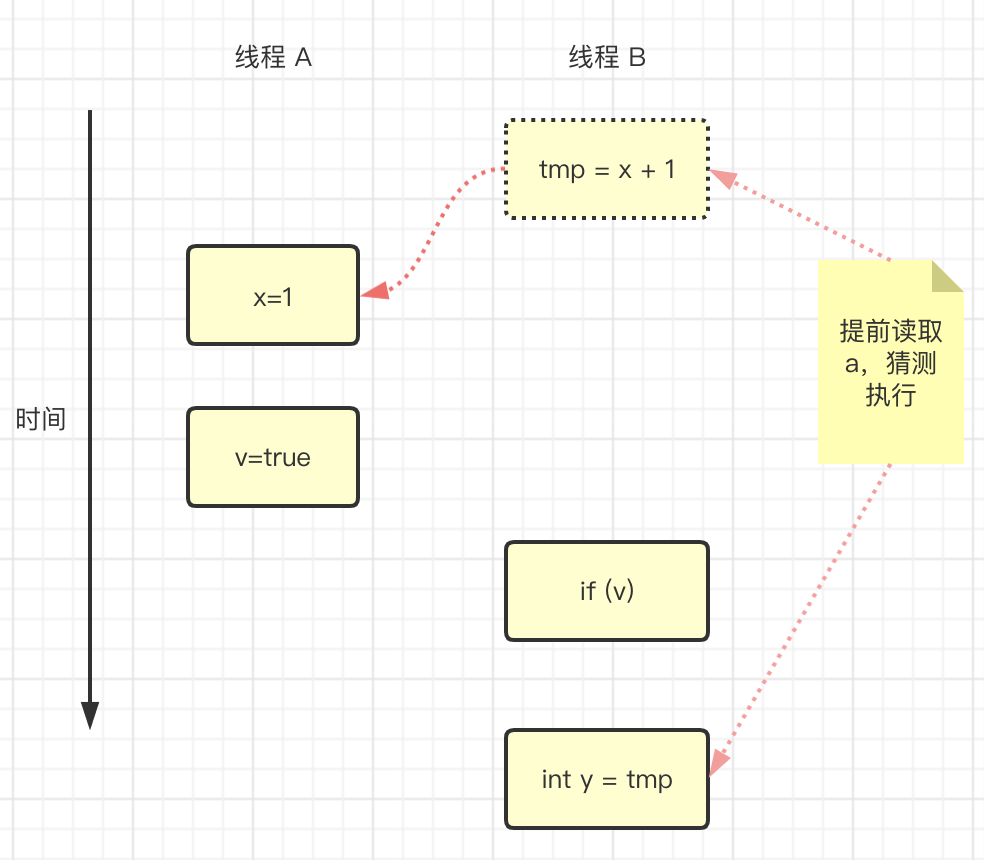
如图,操作 3 和操作 4 做了重排序。在程序中,操作 3 和操作 4 存在控制依赖关系。当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测(Speculation)执行来克服控制相关性对并行度的影响。已处理器的猜测执行为例,执行线程 B 的处理器可以提前读取并计算 x + 1,然后把计算结果临时保存到一个名为重排序缓冲(Reorder Buffer,ROB)的硬件缓存中。当操作 3 的条件判断为真时,就把该计算结果写入变量 y。
从图中可以看出,猜测执行实质上对操作 3 和 4 做了重排序。重排序在这里破坏了多线程程序的语义。在单线程程序中,对存在控制依赖的操作排序,不会改变执行结果(这也是 as-if-serial 语义允许对存在控制依赖的操作做重排序的原因);但在多线程程序中,对存在控制依赖的操作重排序,可能会改变程序的执行结果。

若有收获,就点个赞吧
0 人点赞
