CIFAR-10 数据集使用介绍
CIFAR-10 数据集介绍
CIFAR-10 数据由 60000 张 32 × 32 的图片组成,共有 10 个种类,每一种 6000 张。CIFAR-10 本身已经把图片分成了 6 份,每份 10000 张,其中 5 份是训练图片,1 份是测试图片。测试图片集中每一种恰有 1000 张,而训练图片集中剩余的图片随机分布。下图是其中一些图片示例:

CIFAR-10 数据集下载
官方提供了 3 种版本的数据集,如下:
| Version | Size | md5sum |
|---|---|---|
| CIFAR-10 python version | 163 MB | c58f30108f718f92721af3b95e74349a |
| CIFAR-10 matlab version | 175 MB | 70270af85842c9e89bb428ec9976c926 |
| CIFAR-10 binary version (suitable for C programs) | 162 MB | c32a1d4ab5d03f1284b67883e8d87530 |
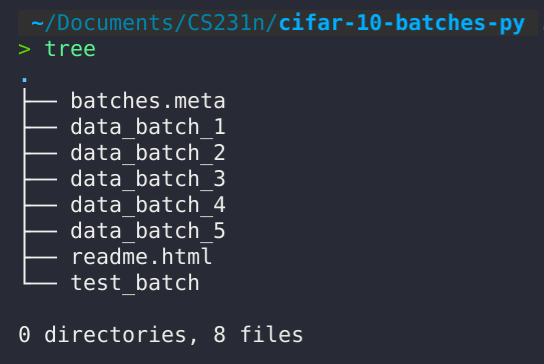
这里我们选择 python 版本的数据集进行下载。下载完解压后,文件结构如下图所示,其中 data_batch_1 到 data_batch_5 分别存放了每一份训练数据集,test_batch 中存放了测试数据集,batches.meta 则存放了标签信息。
CIFAR-10 数据集解析
数据集中提供的数据是经过 pickle 包压缩过的,根据官网提供的资料,可以用以下代码进行解压:
python 2:
def unpickle(file):import cPicklewith open(file, 'rb') as fo:dict = cPickle.load(fo)return dict
python 3:
def unpickle(file):import picklewith open(file, 'rb') as fo:dict = pickle.load(fo, encoding='bytes')return dict
解压后的数据是一个字典结构,对于六个图片数据集,结构如下:
| Key | Description |
|---|---|
| b’batch_label’ | 这一份数据的名称 |
| b’labels’ | 一个长为 10000 的 list ,对应每一张图片的 label 序号 |
| b’data’ | 一个 10000 × 3072 的 array ,对应每一张图片的 32 ×32 × 3 通道形式 |
| b’filenames’ | 一个长为 10000 的 list ,对应每一张图片的文件名 |
对于 batches.meta ,其解压后的字典结构如下:
| Key | Description |
|---|---|
| b’num_cases_per_batch’ | 一个 int ,表示每一个数据集中的数据量 |
| b’label_names’ | 一个长为 10 的list ,表示每一个 label 序号对应的标签名 |
| b’num_vis’ | 一个 int ,表示每一张图的大小(即 3072 ) |
b'data' 中的每一张图片是以展开形式存储的(即一张 32 × 32 × 3的图片被展开为一个长为 3072 的 list ),每一个数据的格式为 uint8 。在这个 list 中,前 1024 个数据表示红色通道,中间 1024 个数据表示绿色通道,最后 1024 个数据表示蓝色通道。根据这样的组成,可以根据需要来进行处理。例如以下代码可以将每一张图片还原为 32 × 32 × 3 的图片:
def getPhoto(pixel):assert len(pixel) == 3072r = pixel[0: 1024]r = np.reshape(r, [32, 32, 1])g = pixel[1024: 2048]g = np.reshape(g, [32, 32, 1])b = pixel[2048: 3072]b = np.reshape(b, [32, 32, 1])photo = np.concatenate([r, g, b], -1)return photo

若有收获,就点个赞吧
0 人点赞
