Lecture 2. Image Classification
Introduction
当我们试图去识别一张图像时,一个很容易想到的函数框架是:
def classify_image(image):# some magic here?return class_label
然而其中的 magic 的实现,却非常困难。可以说,没有一个直观的方法能够通过一个 rgb 矩阵来识别图片。于是人们就有了以下的尝试。通过 Hubel and Wiesel 的实验我们知道了“线条”在视觉识别中起到非常重要的作用。我们是否可以通过计算这些边界的组合,例如找到三条线相交组成的一个角,然后通过这些线条和角的特征分类来识别图片?事实证明这种方法效果并不好。首先它的鲁棒性很差。另外,如果想要换一个识别目标,例如从识别猫改为识别卡车,那么一切都要重新来过。这并不是一个普适的、可扩展的识别方法。我们希望能得到一种能够识别世界上所有物体的算法。基于以上想法,**“数据驱动方法”**的思想诞生了。我们选择通过大量的数据来训练一个模型,而不是手工地来确定什么样的线条是猫、什么样的线条是卡车。也就是如下的框架:
def train(images, labels):# Machine learning!return modeldef predict(model, test_images):# Use model to predict labelsreturn test_labels
Nearest Neighbor Classification
一种基于“数据驱动方法”思想的**分类器(classifier)**叫做**“Nearest Neighbor”**,即 train 部分用于记忆所有的数据和标签,然后在predict部分,在记忆中寻找与之最接近的一张图片,它的标签就是识别图片的标签。下图是利用 Nearest Neighbor训练出来的结果的示例。

可以看到这种 classifier 的效果还是会有不少的误差,因为很多看起来非常接近的图片其实并不是一个东西。虽然 Nearest Neighbor 算法的实际效果并不尽如人意,但是这个过程中如何判断两张图片为 nearest neighbor 还是一件非常有意思的事情。一个非常简单的方法是利用 **L1 distance (又称 Manhattan distance)** 来比较两个矩阵。
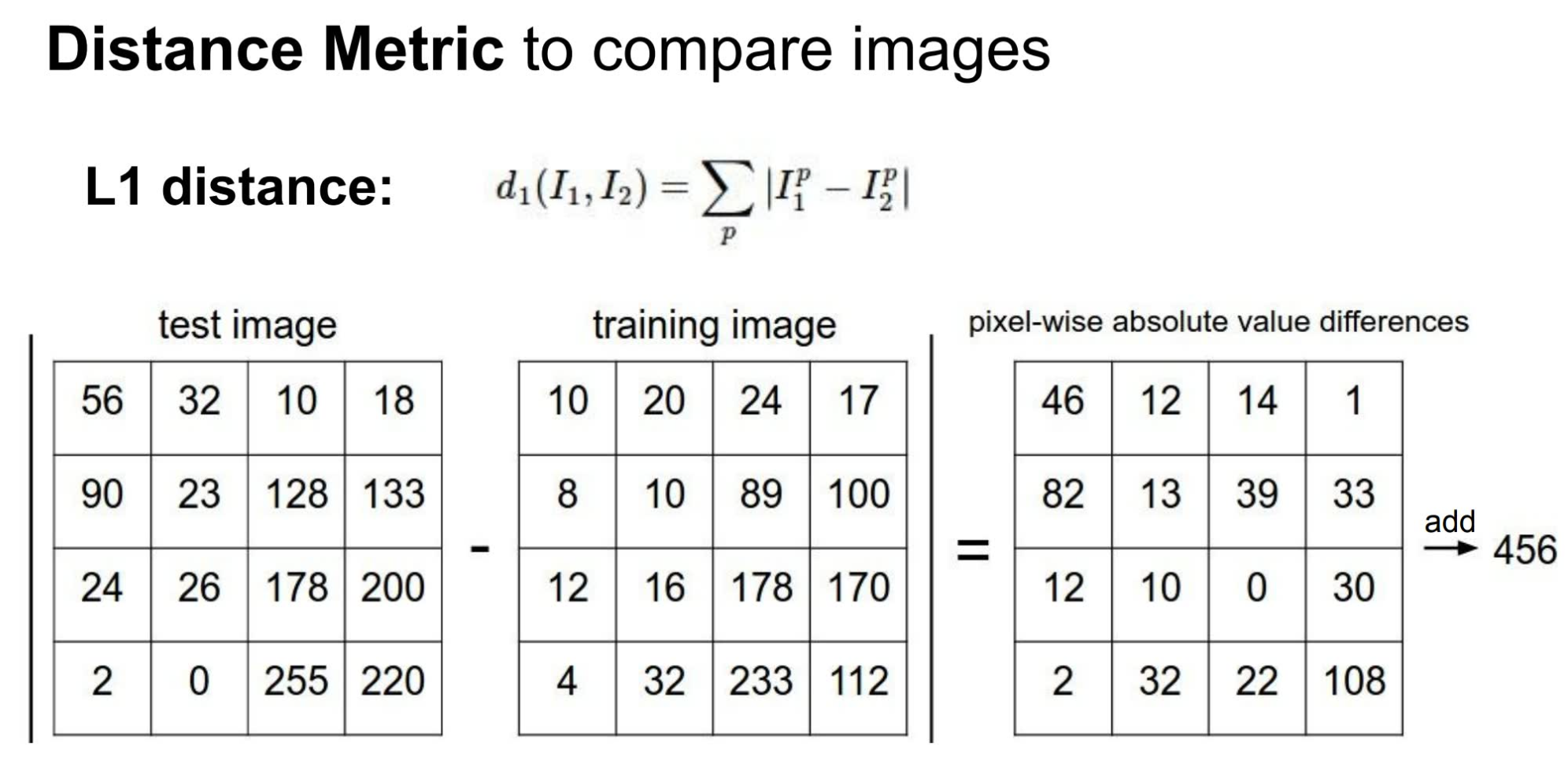
利用 L1 distance 来实现 Nearest Neighbor 的代码如下:
import numpy as npclass NearestNeighbor:def __init__(self):Xtr = Noneytr = Nonedef train(self, X, y):""" X is N x D where each row is an example. Y is 1-dimension of size N """# the nearest neighbor classifier simply remembers all the training dataself.Xtr = Xself.ytr = ydef predict(self, X):""" X is N x D where each row is an example we wish to predict label for"""num_test = X.shape[0]# lets make sure that the output type matches the input typeYpred = np.zeros(num_test, dtype = type(self.ytr))# loop over all test rowsfor i in range(num_test):# find the nearest training image to the i'th test image# using the L1 distance(sum of absolute value differences)distances = np.sum(np.abs(self.Xtr - X[i, :]), axis = 1)min_index = np.argmin(distances)Ypred[i] = self.ytr[min_index]return Ypred
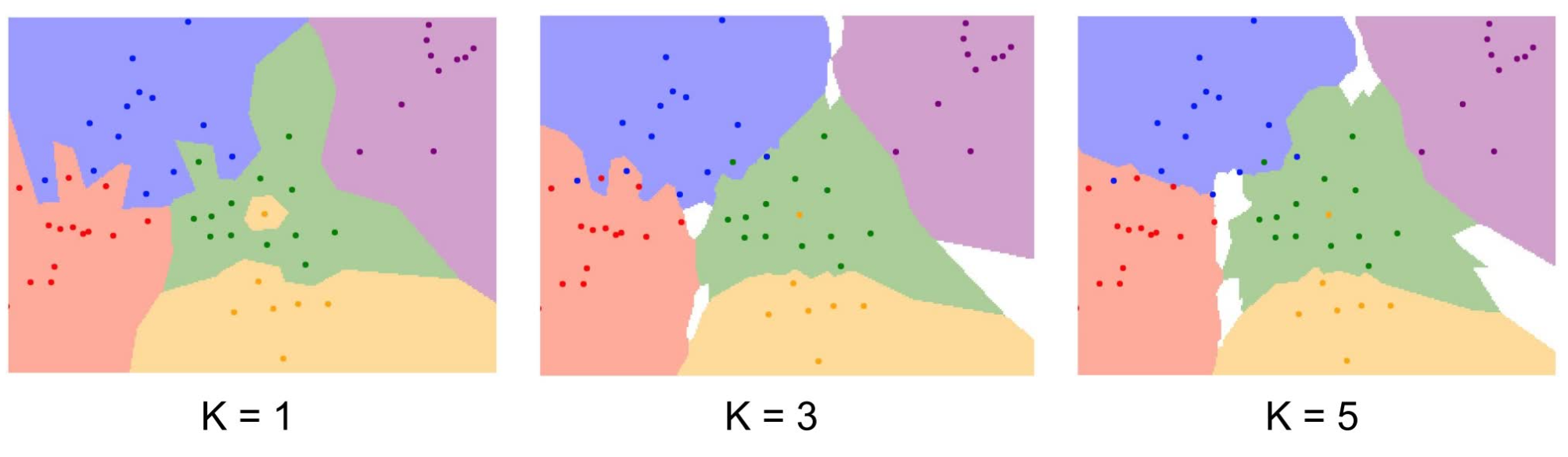
这个算法的 train 复杂度几乎是常数的,因为它只需要把所有的内容都记下来,然而在 predict 阶段,会需要 O(N) 的复杂度。这也是我们不希望看到的,因为显而易见的是,我们可以花费大量的时间用于 train ,得到一个精确度很高的模型,但当我们应用这个模型来 predict 的时候,我们希望它能快速得出结果。一种对 Nearest Neighbor 算法的精确度的改进策略是使用 **K-Nearest Neighbors** 的想法。也就是说,对于一张图我们不再是寻找数据集中距离它最近的那一张图,而是寻找最近的 K 张图,并取最多的那一个标签作为测试图的标签结果。如下图所示的示例可以看到,当 K 取 5 时,决策边界已经相当平滑漂亮(图中的点表示数据集中的图片,点的颜色表示其标签,不同的颜色区块表示位于此区间的测试图的标签取区块的颜色)
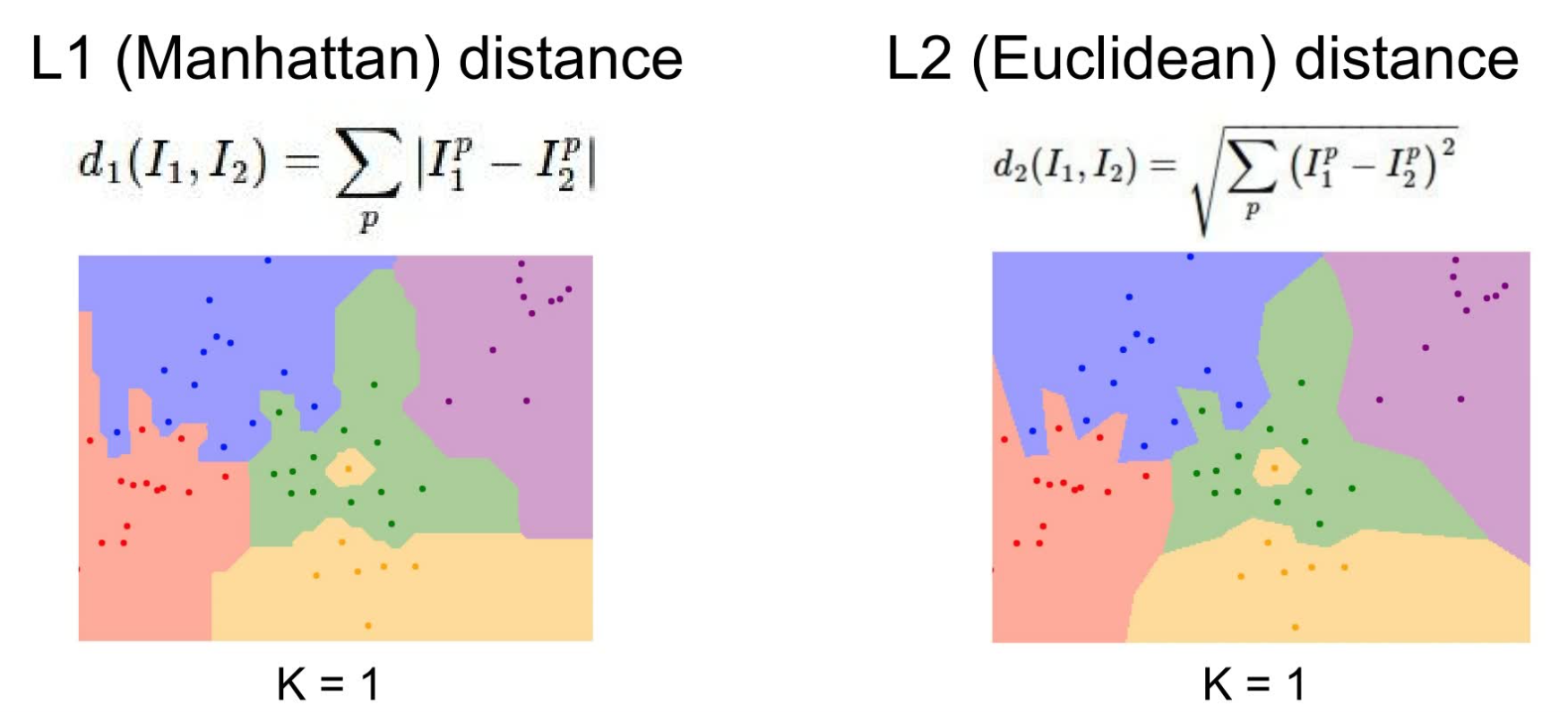
另外除了 L1 distance,也可以考虑使用 **L2 distance(Euclidean distance)**来距离。由于 L1 distance 会随坐标轴的旋转而改变,而 L2 distance 不会,故应根据场景的不同选择不同的路径算法。
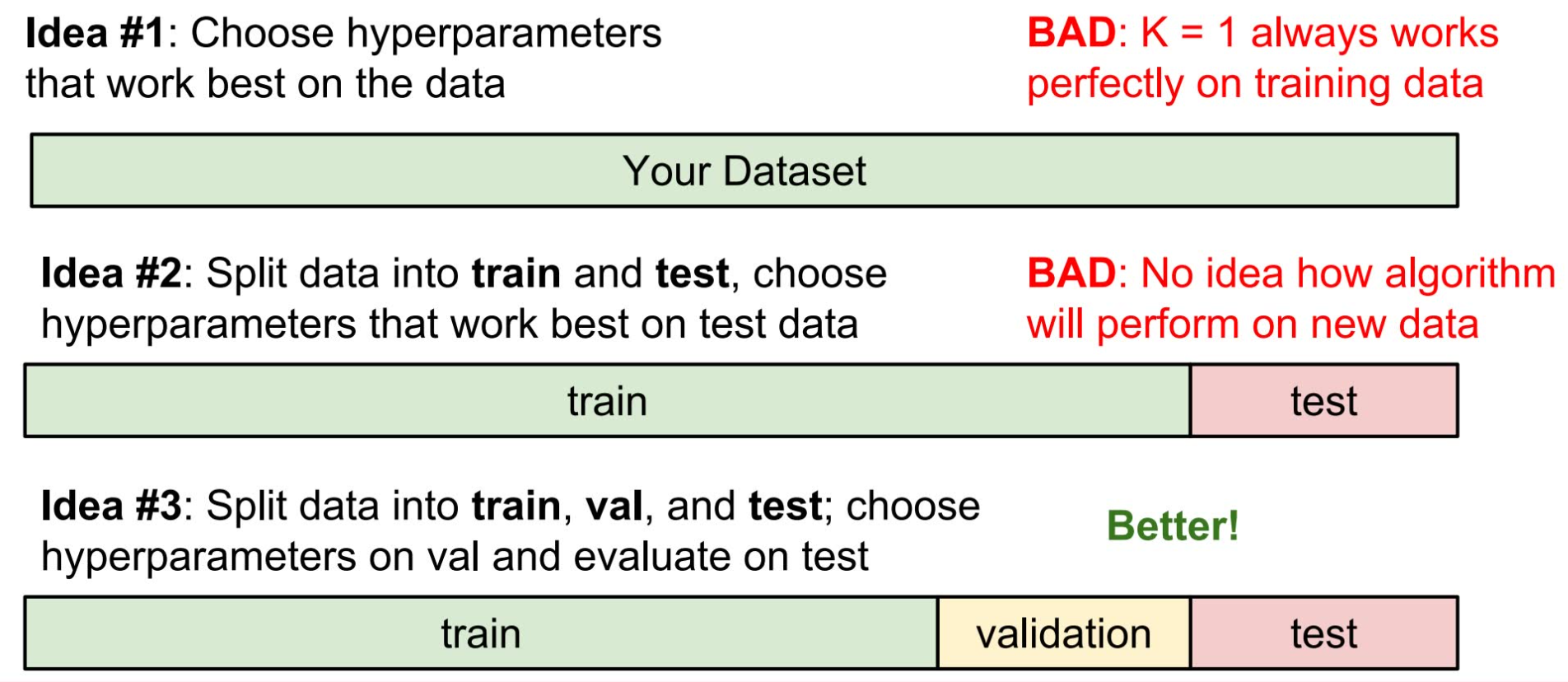
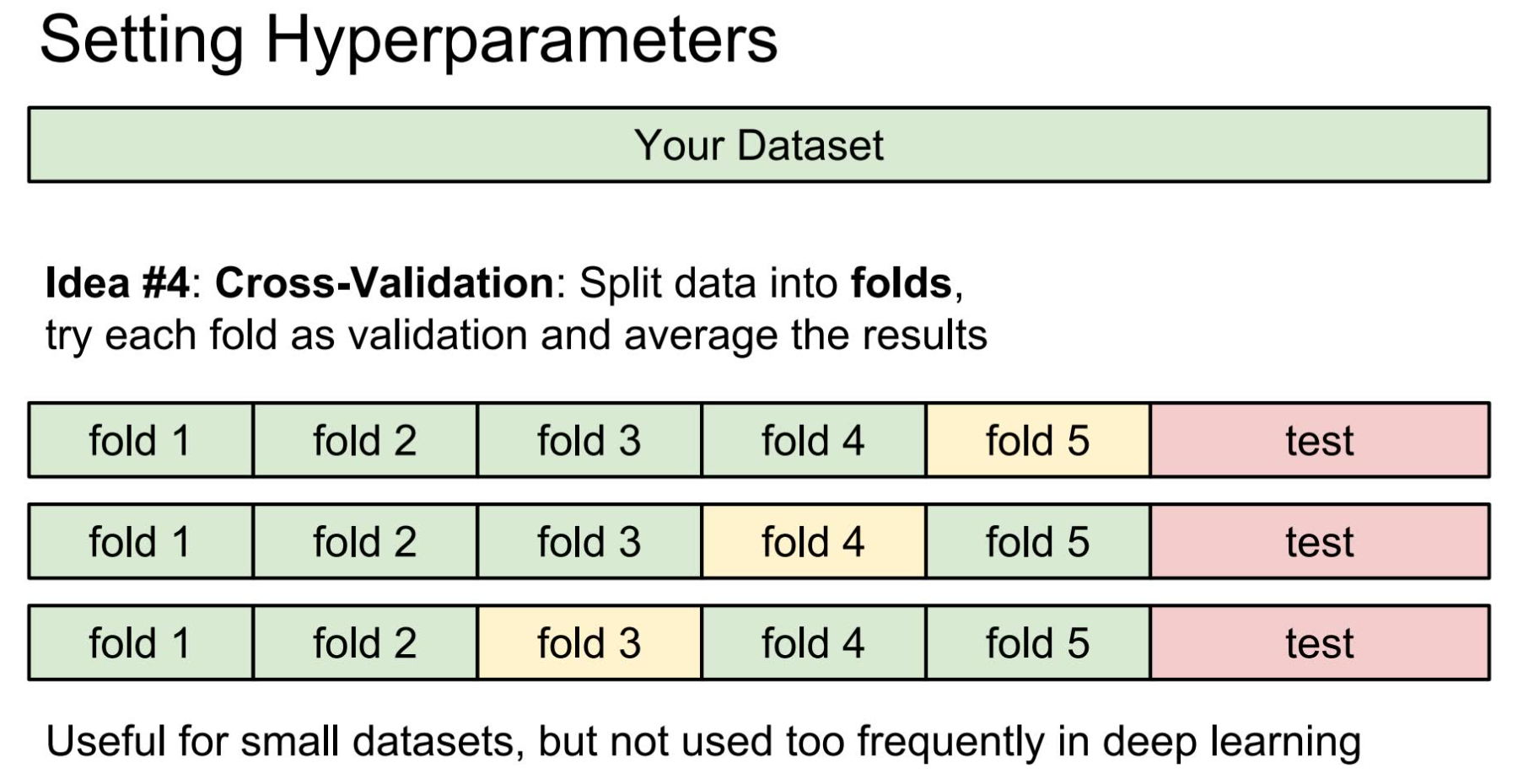
在这个例子中, k 的选择和路径算法的选择称为**超参数(hyperparameters)**。超参数与模型中其他的参数的区别在于,其他的参数是模型通过训练得出的,而超参数则是人为设定的,用于控制学习的过程。超参数的设定非常取决于你希望解决的问题(problem-dependent),对绝大多数情况而言,选择超参数的最好方法是一一尝试过来,并选择其中表现最好的那一个。事实上,对于超参数的尝试和选择也有相应的方法。当拿到一个数据集,首先应当将其进行划分。如果不划分直接训练,那么任意的超参数都将表现非常好——因为所有的数据全都拿来训练了。这将无法选出真正表现优秀的超参数。将数据集划分为训练数据和测试数据听起来是一个不错的主意,但也不可取。这种情况下,调整超参数将是这样的流程:设置一个超参数,然后在训练数据上跑训练,再用测试数据来看这个训练模型的表现,据此修改超参数并寻找最佳表现的超参数。这种方法的问题在于找出的超参数是最拟合测试数据的超参数,但我们对它面对其他未知数据的表现将不得而知。也就是说这种方法训练出来的模型将过于拟合测试数据而丧失普适性。种常用的数据划分方法是将其划为三部分——大部分划分为训练数据,剩下的划分为调整数据和测试数据。训练数据用于跑训练,根据模型在调整数据上的表现来调整超参数,得到表现最好的超参数以后,用测试数据来看最终模型的结果,并将准确率写在报告、论文上。
当数据集不大时,还可以用准确率更高的方法,如 K-Cross Validation ,这种方法对数据集的划分是,除去少量的测试数据以外,其余的进行 k 等分,每次选取其中一部分作为调整数据,剩下的作为训练数据。循环 k 次后再在测试数据上进行最后测试。这种划分方法准确率更高,但效率要低很多,因此当数据量大的时候通常不采用。
事实上即使是改进后的 K-Nearest Neighbors 算法也依旧表现很不好。首先,它的运行效率较低。其次,L1 distance 和 L2 distance 用于图片比较距离并不是一个很好的想法。最后,由于这种算法其实可以看作是在点的周围根据距离不同涂上颜色,因此如果我们想要得到准确的结果就需要训练数据集中的点尽可能的密集。然而显而易见,这是随着维数的增长呈指数级增长的。这很不好。

Linear Classification
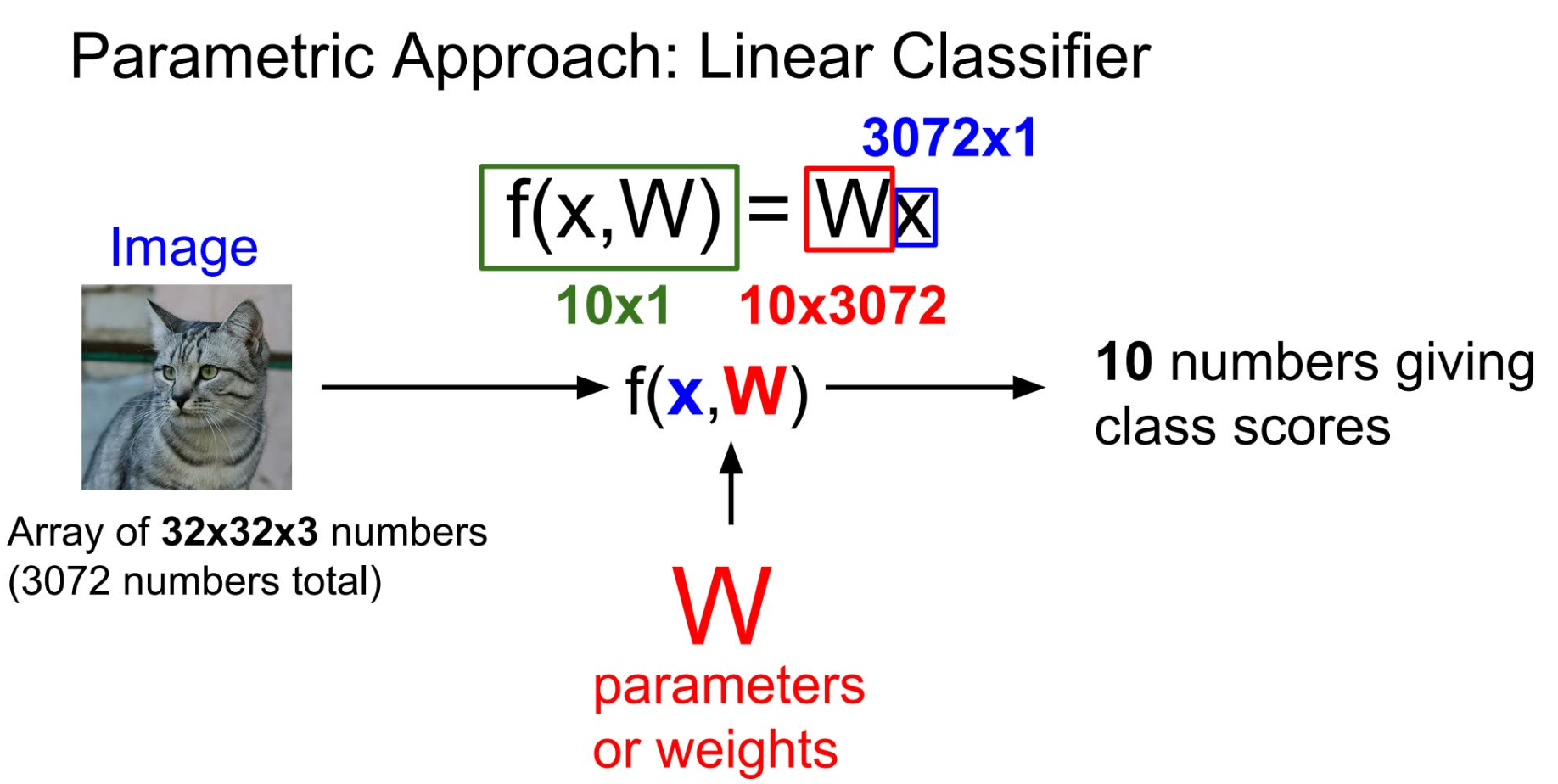
另一种思路是利用线性计算来给出一张图片属于 n 种分类的得分,得分最高的就是这张图片的分类。也就是说,利用 %20%3D%20Wx#card=math&code=f%28x%2C%20W%29%20%3D%20Wx&id=An67l) ,其中 x 是需要判断的图片,W 是训练得到的矩阵,而得到的结果就是得分矩阵。W 矩阵的大小是这样得到的:我们假设图片是 32 _ 32 _ 3 的(即CIFAR-10提供图片的标准大小),那么x矩阵可以用 3072 _ 1 的矩阵来表示;假设总共有10个标签,那么我们最终希望得到的得分矩阵就是 10 _ 1。由矩阵乘法的规则可知,W 应为一个10 * 3072 大小的矩阵。
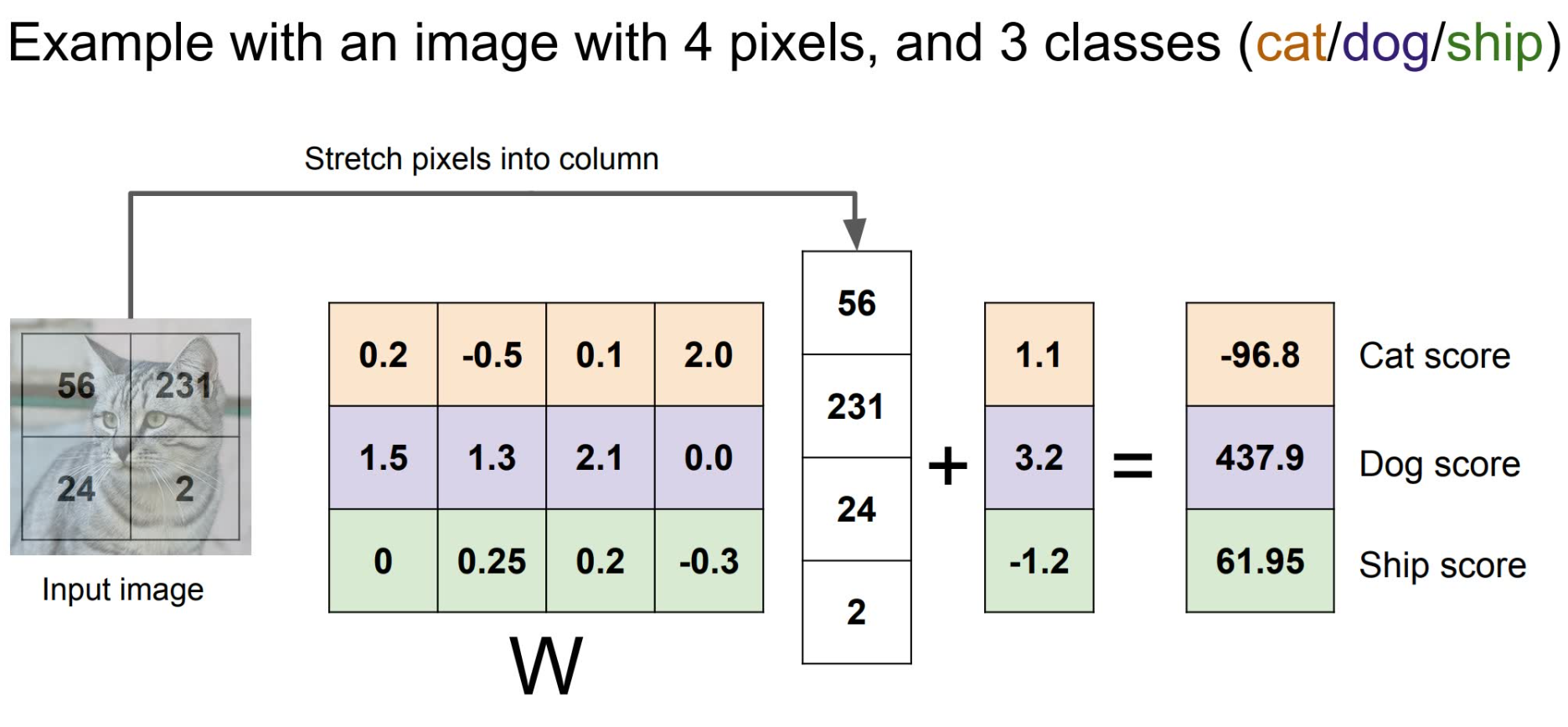
很多时候我们还会选择在之后加上一个常量  ,用于调整数据集中本身数量的不平衡。例如数据集中猫比狗多,那么相应的这个常量也会做出变化,变得更高。下图是一个具体的例子。
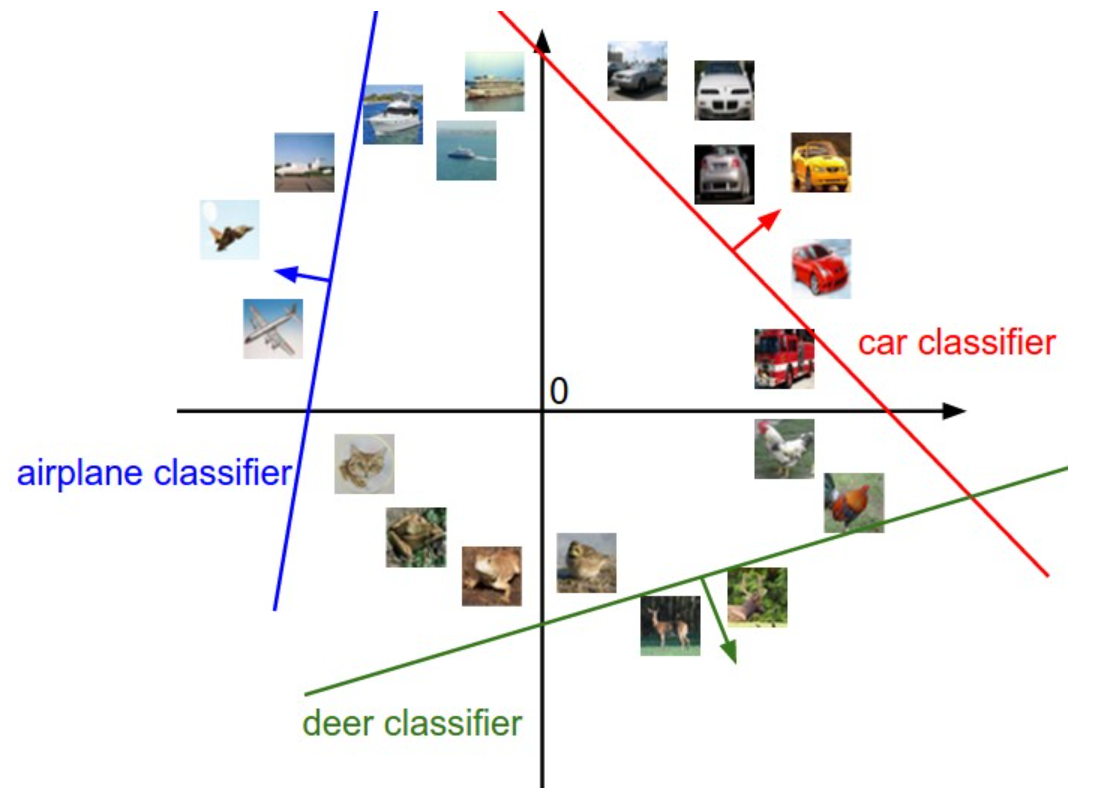
线性分类的公式到底在做什么?下图是一个根据 CIFAR-10 的数据训练出来的一个 W 矩阵结果,通过这个结果我们可以大致看到这个训练过程结果究竟是什么。W 中的每一行实际上可以看作是对相应种类的一个图片模版。当我们计算一张图片对于一个标签种类的得分的时候我们实际是在算这张图和这类图片的模版的点积,用于进行比较(类比 Nearest Neighbor 的思想,这里的点积类似于 L1 distance 或者 L2 distance ,区别在于我们不需要用成千上万的数据集来比较,而是通过一个训练完的模版进行比较)。

从另一个角度来看,对于 W 中的每一行,实际上是对一个种类的分类器,它将平面划分为两部分;而 b 的存在则是为了防止所有的直线都经过原点。由这张图也可一看到,当区域并非线性的时候,用线性分类的方法就会遇到一些困难。

若有收获,就点个赞吧
0 人点赞
