https://blog.csdn.net/yuzhou_1shu/article/details/105804181
垃圾回收机制
来看一下Python中的垃圾回收技术:
- 引用计数为主
- 标记清除和分代回收为辅
如果一个对象的引用计数为0,Python解释器就会回收这个对象的内存,但引用计数的缺点是不能解决循环引用的问题,所以我们需要标记清除和分代回收。
引用计数
- 每个对象都有存有指向该对象的引用总数
- 查看某个对象的引用计数
sys.getrefcount() - 可以使用del关键字删除某个引用
当对象的引用计数达到零时,解释器会暂停,来取消分配它以及仅可从该对象访问的所有对象。即满足引用计数为0的时候,会启动垃圾回收。import sysl = []print(sys.getrefcount(l)) # Output: 2l2 = ll3 = ll4 = l3print(sys.getrefcount(l)) # Output: 5del l2print(sys.getrefcount(l)) # Output: 4i = 1print(sys.getrefcount(i)) # Output: 140a = iprint(sys.getrefcount(i)) # Output: 141
但是引用计数不能解决循环引用的问题,就如下的代码不停跑就能把电脑内存跑满:>>> a = []>>> b = []>>> while True:... a.append(b)... b.append(a)...[1] 31962 killed python
标记清除
标记清除算法作为Python的辅助垃圾收集技术主要处理的是一些容器对象,比如list、dict、tuple,instance等,因为对于字符串、数值对象是不可能造成循环引用问题。标记清除和分代回收就是为了解决循环引用而生的。
它分为两个阶段:
第一阶段是标记阶段,GC会把所有的活动对象打上标记;
第二阶段是把那些没有标记的对象、非活动对象进行回收;
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈、寄存器。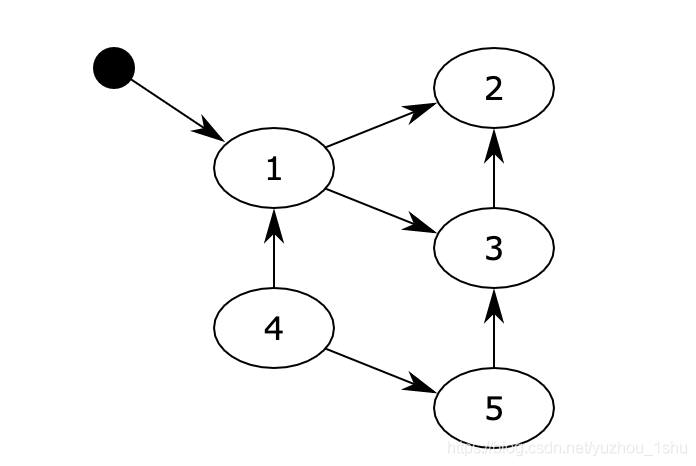
在上图中,可以从程序变量直接访问块1,并且可以间接访问块2和3。程序无法访问块4和5。第一步将标记块1,并记住块2和3以供稍后处理。第二步将标记块2,第三步将标记块3,但不记得块2,因为它已被标记。扫描阶段将忽略块1,2和3,因为它们已被标记,但会回收块4和5。
Python使用一个双向链表将这些容器对象组织起来。不过,这种简单粗暴的标记清除算法也有明显的缺点:清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
分代回收(自动)
分代回收是建立在标记清除技术基础之上的,是一种以空间换时间的操作方式。
- Python将所有的对象分为0,1,2 三代
- 所有的新建的对象都是0代对象
- 当某一代对象经历过垃圾回收,依然存活,那么它就被归入下一代对象。
同时,分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象。
Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数。
当两者的差值高于某个阈值时,垃圾回收才会启动
查看阈值gc.get_threshold()
import gcprint(gc.get_threshold()) # Output: (700, 10, 10)
get_threshold()返回的(700, 10, 10)返回的两个10。也就是说,每10次0代垃圾回收,会配合1次1代的垃圾回收;而每10次1代的垃圾回收,才会有1次的2代垃圾回收。理论上,存活时间久的对象,使用的越多,越不容易被回收,这也是分代回收设计的思想。手动回收
具体参考gc模块。
gc.collect()手动回收
- objgraph模块中的count()记录当前类产生的实例对象的个数
import gcresult = gc.collect()print(result)
import objgraph
``` class Person(Object): pass class Cat(object): pass p = Person() c = Cat() p.name =’yuzhou1su’ c.master = p print(sys.getrefcount(p)) print(sys.getfefcount(c)) del p del c gc.collect() print(objgraph.count(‘Person’)) print(objgraph.count(‘Cat’))
``` 当定位到哪个对象存在内存泄漏,就可以用show_backrefs查看这个对象的引用链。
内存池(memory pool)机制
频繁 申请、消耗 会导致大量的内存碎片,致使效率变低。
内存池的概念就是在内存中申请一定数量的,大小相等的内存块留作备用。
内存池池由单个大小类的块组成。每个池维护一个到相同大小类的其他池的双向链接列表。这样,即使在不同的池中,该算法也可以轻松找到给定块大小的可用空间。
当有新的内存需求时,就会先从内存池中分配内存留给这个需求。内存不够再申请新的内存。
内存池本身必须处于以下三种状态之一:
- 已使用
- 已满
- 或为空。
优点:减少内存碎片,提高效率。
有参考: https://www.cnblogs.com/xybaby/p/7491656.html https://www.jianshu.com/p/c2c960481011 https://www.cnblogs.com/TM0831/p/10599716.html

若有收获,就点个赞吧
0 人点赞
