爬虫的3个基本步骤
采, 抽, 存
import requestsr = requests.get("https://wap.zol.com.cn/top/cell_phone/hot.html")
浏览器背后干的事
http协议交流
https://www.processon.com/view/link/5c97952de4b0ab74ece439cd#map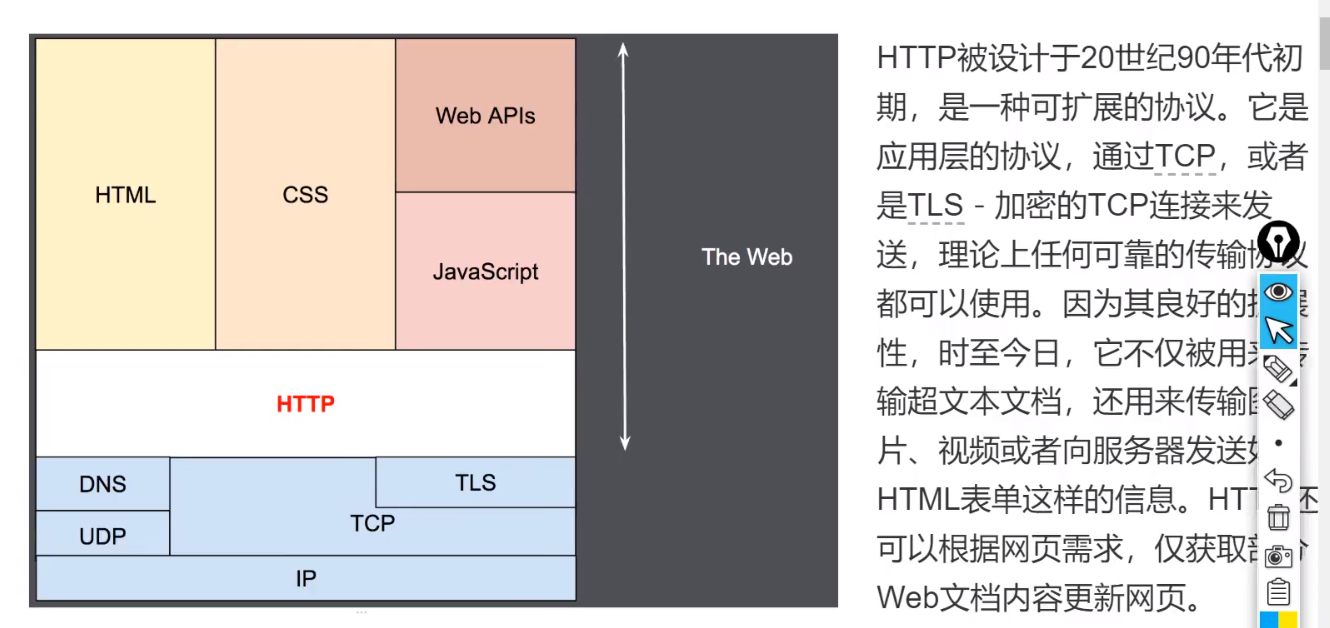
1. url —DNS解析—> ip地址
注: url包括域名
url: http://mail.163.com(网站名)/index.html(默认网页)
1) http://:这个是协议,也就是HTTP超文本传输协议,也就是网页在网上传输的协议。
2) mail:这个是服务器名,代表着是一个邮箱服务器,所以是mail。
3) 163.com:这个是域名,是用来定位网站的独一无二的名字。
4) mail.163.com:这个是网站名,由服务器名+域名组成。
5) /:这个是根目录,也就是说,通过网站名找到服务器,然后在服务器存放网页的根目录
6) index.html:这个是根目录下的默认网页(当然,163的默认网页是不是这个我不知道,只是大部分的默认网页,都是index.html)
7) http://mail.163.com/index.html:这个叫做URL,统一资源定位符,全球性地址,用于定位网上的资源。
一个域名可以扩展不同的网站名
可能到这时候,你还是不明白,这个域名和网站名有什么区别?
比如说,你买下了一个大学,这个大学的名字叫:myname.com。
然后,你想建立一个语文系,所以,文科楼建立了,叫yuwen.myname.com
然后,你又想建立一个数学系,OK,shuxue.myname.com建立了。
就像163一样,他的域名是163.com,
他想建立一个www服务器,所以有了www.163.com。
他又想玩邮箱服务器,所以,mail.163.com也有了。
要知道,我们不仅可以访问文件,还可以访问目录, 键入域名的访问过程:
比如:http://www.163.com/ 意思是,访问当前的根目录/。
此时,web服务器会查看当前自己有没有这个目录,OK,肯定有的。
那么,难道服务器会把整个目录都返回给你?no!
服务器会在自己的目录下寻找默认的网页,一般是index.html,当然,可以通过配置网页去修改。小编在Linux下搭建过阿帕奇,有配置文件专门修改,你们也可以试试。
之后,服务器找到了目录下的index.html,再返回给web浏览器。
所以,当我们访问www.baidu.com的时候,浏览器会自动帮我们加上http://,变成: http://www.baidu.com。
而百度的服务器,收到该请求后,会自动加上/,变成: http://www.baidu.com/。
然后,百度服务器会在该目录下寻找index.html或其他默认网页,也就是百度的主页,找到后,通过http协议返回给你。也就是你看到的百度主页。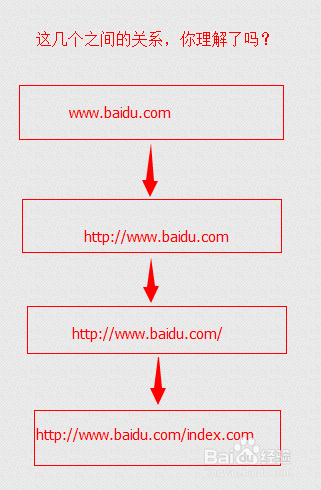
2. 通过ip地址逐级访问服务器
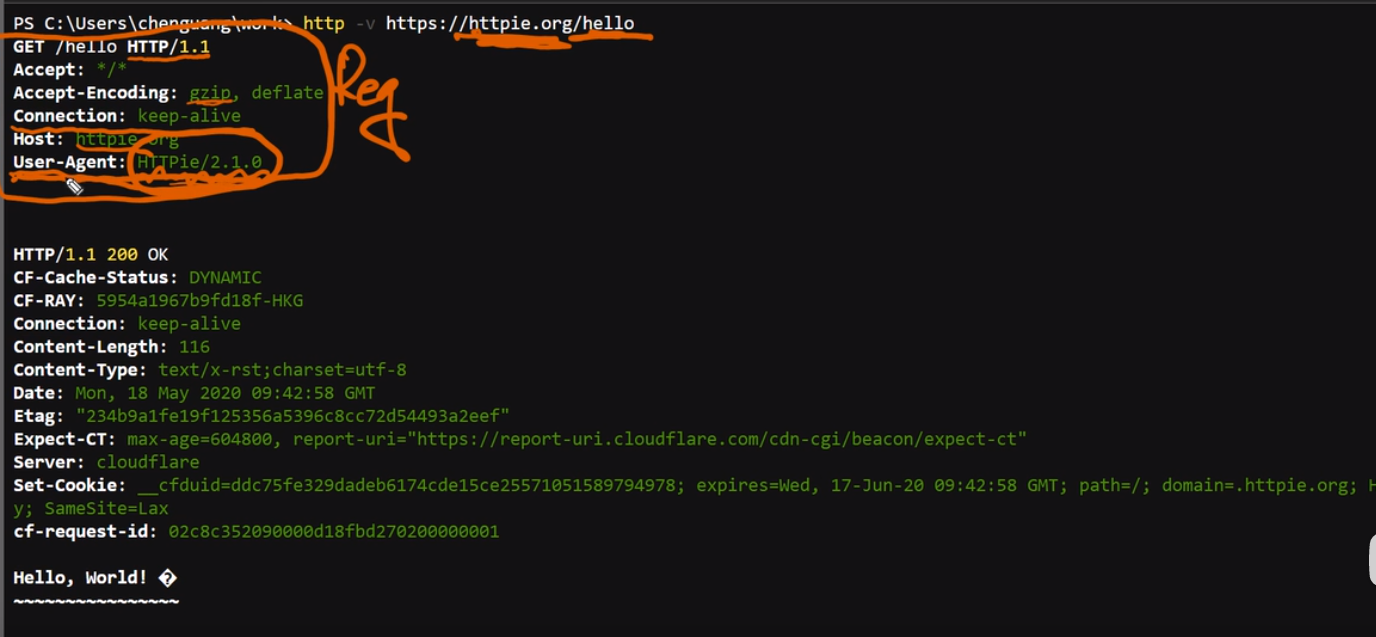
404 就是一个经典的http response code, 200 表示正常返回
Cookie用于缓存一些信息

若有收获,就点个赞吧
0 人点赞
