7. 做出预测
现在模型已经过训练,我们需要进行一些预测。让我们查看模型对均匀范围内的数字(从低到高的马力)的预测情况,从而对其进行评估。
将以下函数添加到您的 script.js 文件中
function testModel(model, inputData, normalizationData) {const {inputMax, inputMin, labelMin, labelMax} = normalizationData;// Generate predictions for a uniform range of numbers between 0 and 1;// We un-normalize the data by doing the inverse of the min-max scaling// that we did earlier.const [xs, preds] = tf.tidy(() => {const xs = tf.linspace(0, 1, 100);const preds = model.predict(xs.reshape([100, 1]));const unNormXs = xs.mul(inputMax.sub(inputMin)).add(inputMin);const unNormPreds = preds.mul(labelMax.sub(labelMin)).add(labelMin);// Un-normalize the datareturn [unNormXs.dataSync(), unNormPreds.dataSync()];});const predictedPoints = Array.from(xs).map((val, i) => {return {x: val, y: preds[i]}});const originalPoints = inputData.map(d => ({x: d.horsepower, y: d.mpg,}));tfvis.render.scatterplot({name: 'Model Predictions vs Original Data'},{values: [originalPoints, predictedPoints], series: ['original', 'predicted']},{xLabel: 'Horsepower',yLabel: 'MPG',height: 300});}
在上述函数中需要注意的一些事项。
const xs = tf.linspace(0, 1, 100);const preds = model.predict(xs.reshape([100, 1]));
我们生成了 100 个新“样本”,以提供给模型。Model.predict 是我们将这些样本提供给模型的方式。请注意,它们必须具有与训练时相似的形状 ([num_examples, num_features_per_example])。
// Un-normalize the dataconst unNormXs = xs.mul(inputMax.sub(inputMin)).add(inputMin);const unNormPreds = preds.mul(labelMax.sub(labelMin)).add(labelMin);
要将数据恢复到原始范围(而非 0-1),我们会使用归一化过程中计算的值,但只是进行逆运算。
return [unNormXs.dataSync(), unNormPreds.dataSync()];
[.dataSync()](https://js.tensorflow.org/api/latest/#tf.Tensor.dataSync)是一种用于获取张量中存储的值的 typedarray 的方法。这使我们能够在常规 JavaScript 中处理这些值。这是通常首选的[.data()](https://js.tensorflow.org/api/latest/#tf.Tensor.data)方法的同步版本。
最后,我们使用 tfjs-vis 来绘制原始数据和模型的预测。
将以下代码添加到您的
run 函数中。
// Make some predictions using the model and compare them to the// original datatestModel(model, data, tensorData);
刷新页面,您应会在模型完成训练后看到如下内容。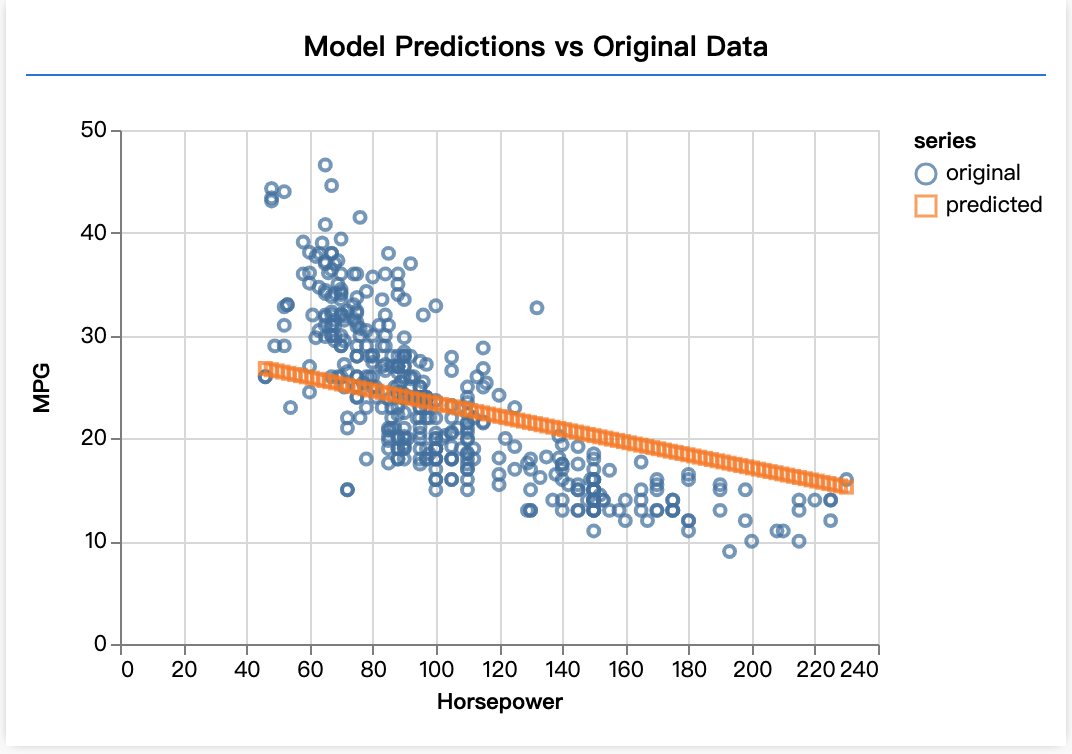
恭喜!您刚刚训练了一个简单的机器学习模型。目前,它会执行所谓的线性回归,从而尝试将一条线与输入数据中的趋势拟合。

若有收获,就点个赞吧
0 人点赞
