6. 训练模型
创建模型实例并将数据表示为张量之后,我们就可以开始训练过程了。
将以下函数复制到您的
script.js 文件中。
async function trainModel(model, inputs, labels) {// Prepare the model for training.model.compile({optimizer: tf.train.adam(),loss: tf.losses.meanSquaredError,metrics: ['mse'],});const batchSize = 32;const epochs = 50;return await model.fit(inputs, labels, {batchSize,epochs,shuffle: true,callbacks: tfvis.show.fitCallbacks({ name: 'Training Performance' },['loss', 'mse'],{ height: 200, callbacks: ['onEpochEnd'] })});}
我们来详细介绍一下。
为训练做好准备
// Prepare the model for training.model.compile({optimizer: tf.train.adam(),loss: tf.losses.meanSquaredError,metrics: ['mse'],});
在我们训练模型之前,我们必须对其进行“编译”。为此,我们必须指定一些非常重要的事项:
- optimizer:这是用于控制模型更新的算法,如样本所示。TensorFlow.js 中提供了许多优化器。我们选择了 Adam 优化器,因为它在实际使用中非常有效,无需进行任何配置。
- loss:这是一个函数,用于告知模型在学习所显示的各个批次(数据子集)时的表现如何。我们使用 meanSquaredError 将模型所做的预测与真实值进行比较。
const batchSize = 32;const epochs = 50;
接下来,我们将选择 batchSize 和多个周期:
- batchSize 是指模型在每次训练迭代时会看到的数据子集的大小。常见的批次大小通常介于 32-512 之间。对于所有问题,实际上并没有理想的批次大小,并且描述各种批次大小的数学动机超出了本教程的范围。
- epochs 表示模型查看您提供的整个数据集的次数。我们将对数据集执行 50 次迭代。
启动训练循环
return await model.fit(inputs, labels, {batchSize,epochs,callbacks: tfvis.show.fitCallbacks({ name: 'Training Performance' },['loss', 'mse'],{ height: 200, callbacks: ['onEpochEnd'] })});
model.fit 是您为了启动训练循环而调用的函数。这是一个异步函数,因此我们会返回它提供的 promise,以便调用方确定训练何时完成。
为了监控训练进度,我们会将一些回调传递给 model.fit。我们使用 tfvis.show.fitCallbacks 来生成可为我们之前指定的“损失”和“均方误差’”指标绘制图表的函数。
综合应用
现在,我们必须调用通过 run 函数定义的函数。
将以下代码添加到
run 函数的底部。
// Convert the data to a form we can use for training.const tensorData = convertToTensor(data);const {inputs, labels} = tensorData;// Train the modelawait trainModel(model, inputs, labels);console.log('Done Training');
刷新页面几秒钟后,您应该会看到以下图表更新。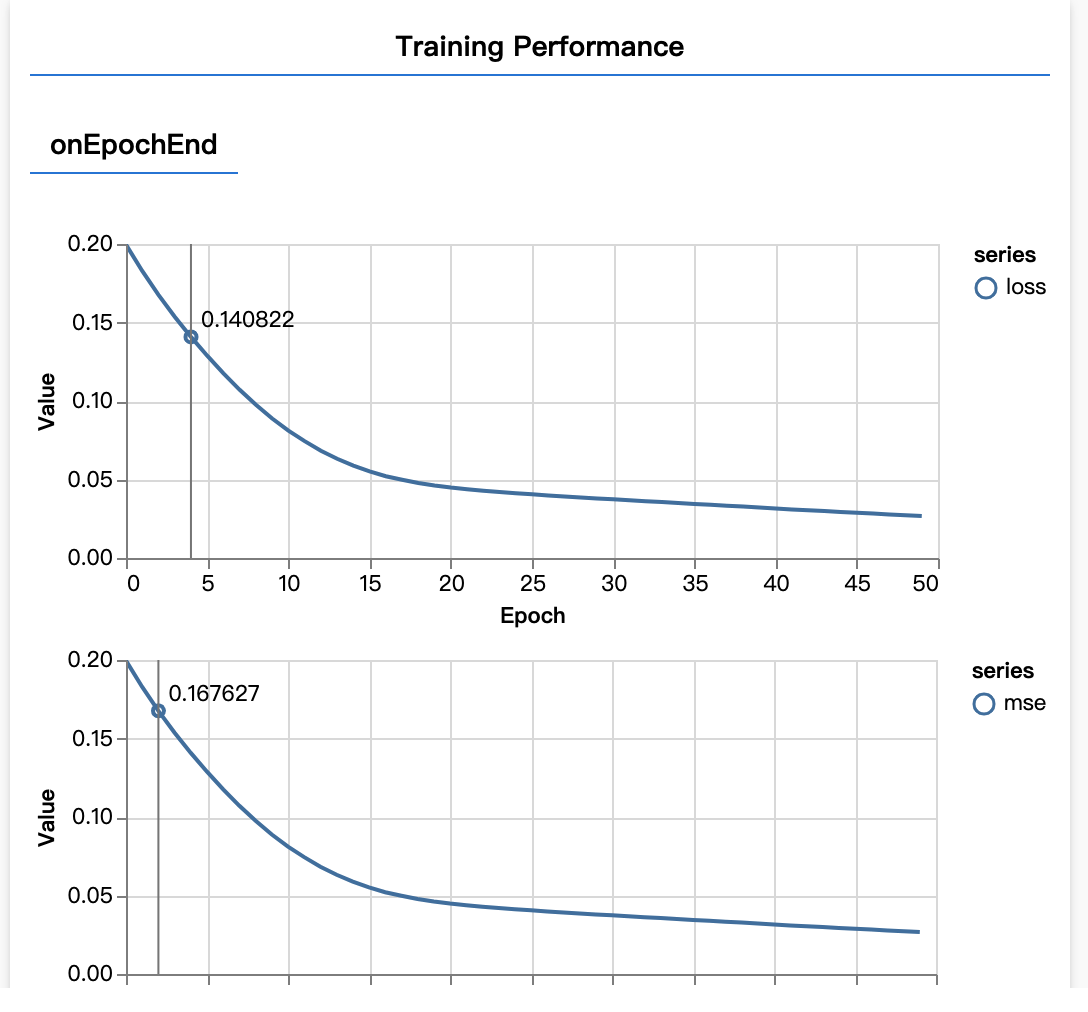
这是由我们之前创建的回调创建的。它们显示每个周期结束时整个数据集的平均损失和均方误差。
在训练模型时,我们希望看到损失下降。在本例中,由于我们的指标是用来衡量错误的,因此我们还希望看到该指标下降。
如果您想要了解训练时后台发生的情况,请参阅我们的指南或观看由 3blue1brown 制作的视频。

若有收获,就点个赞吧
0 人点赞
