今日内容
- 1 - Spark SQL的基本概念
- 2 - Spark SQL的入门案例
- 3 - dataFrame对象详细说明
1- SparkSql的基本概念
1.1 了解什么是Spark SQL
SparkSQL 是 Spark 的一个模块,此模块主要用于处理结构化的数据 ```properties 思考 : 什么是结构化数据? 指的 : 一份数据,每行都有固定的长度,每列的数据类型都是一致的,我们可以将这样的数据称为结构化的数据
1 张三 男 20 2 李四 女 18 3 王五 男 20 4 赵六 女 15
以上数据为结构化数据
Spark SQL 主要是处理结构化的数据,而Spark Core 可以处理任意数据类型<br />Spark SQL 核心的数据结构为 dataFrame = (数据)RDD+(元数据)Schema信息为什么学习Spark SQL:```properties1 - SQL比较简单,会SQL的人一定比会大数据的人多 : SQL更加通用2 - Spark SQL可以兼容 HIVE , 可以让Spark SQL 和 HIVE集成,从而将执行引擎替换为Spark3 - Spark SQL不仅仅可以写SQL,还可以写代码,SQL和代码是可以共存,也可以单独使用,更加灵活4 - Spark SQL可以处理大规模的数据,底层是基于Spark RDD
Spark SQL的特点 :
1 - 融合性 : Spark SQL中既可以编写SQL、也可以编写代码、也可以混合使用2 - 统一的数据访问 : 使用Spark SQL可以和各种数据源进行集成,比如 HIVE,MySQL,Oracle ... ,集成后,可以使用一套Spark SQL的 API 来操作不同的数据源的数据3 - HIVE 兼容 : Spark SQL 可以和 HIVE进行集成,集成后将HIVE执行引擎以MR替换为 Spark ,提升效率 集成核心是共享 metastore4 - 标准化的连接 : Spark SQL 也是支持 JDBC/ODBC 的连接方式,可以让各种连接数据库的工具来连接使用
1.2 Spark SQL的发展史
HIVE的执行原理

SparkSQL 历程
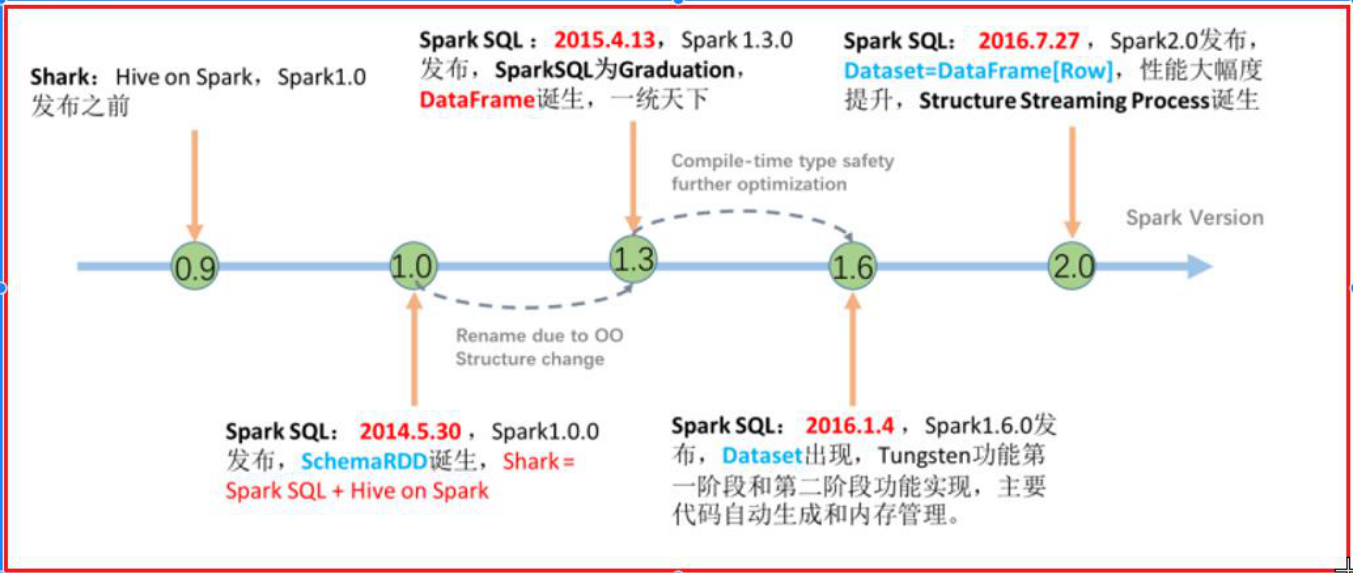
从2.0版本后,SparkSQL将Spark俩个核心对象:dataSet 和 dataFrame 合二为一了,统一称为叫做dataSet,但是为了能够支持向python这样没有泛型的语言,在客户端依然保留dataFrame,但是当dataFrame到达Spark后,依然会被转换为dataSet
1.3 Spark SQL与hive异同
相同点:
1 - Spark SQL 和 hive 都是分布式 SQL 引擎2 - 都可以处理大规模的数据3 - 都是处理结构化的数据4 - Spark SQL 和 HIVE SQL 最终都可以提交到YARN平台来使用
区别:
1 - Spark SQL 是基于内存的计算,HIVE 是基于磁盘的迭代计算2 - HIVE 仅能使用SQL来处理数据,而 SparkSQL 不仅可以使用SQL,还可以使用 DSL 代码3 - HIVE 提供了专门用于元数据管理的服务 : metastore 而 Spark SQL 没有元数据管理的服务,自己来进行维护4 - HIVE 底层是基于MR 来运行的,而 Spark SQL 底层是基于RDD
1.4 Spark SQL的数据结构对比
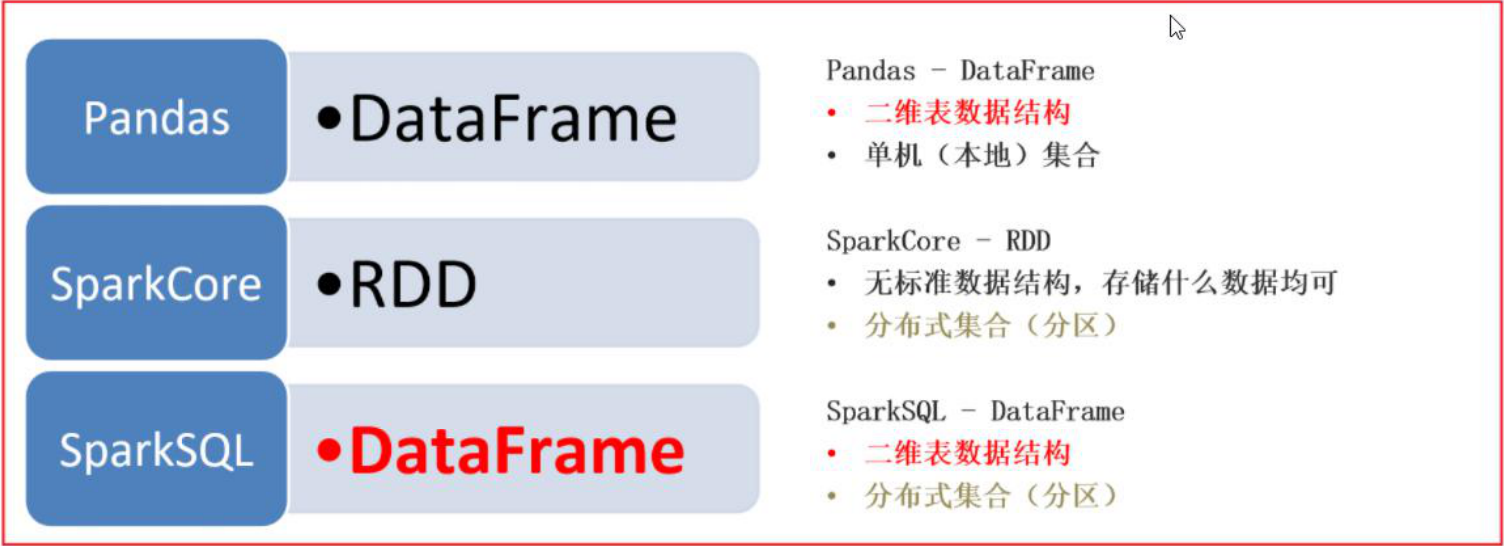
pandas的 dataFrame : 表示的是一个二维的表,仅能处理结构化的数据,单机处理操作Spark Core的RDD : 不局限于数据结构,分布式的处理引擎,可以处理大规模的数据Spark SQL的dataFrame : 表示的一个二维的表,仅能处理结构化的数据,可以分布式的处理,可以处理大规模的数据在实际中 :一般如果遇到的数据集以 KB MB 或者几个GB ,此时可以使用Pandas即可完成统计分析处理,比如财务的相关数据分析如果数据集以 几十GB 或者 TB 甚至 PB 级别以上的数据集,必须使用大规模处理数据的引擎
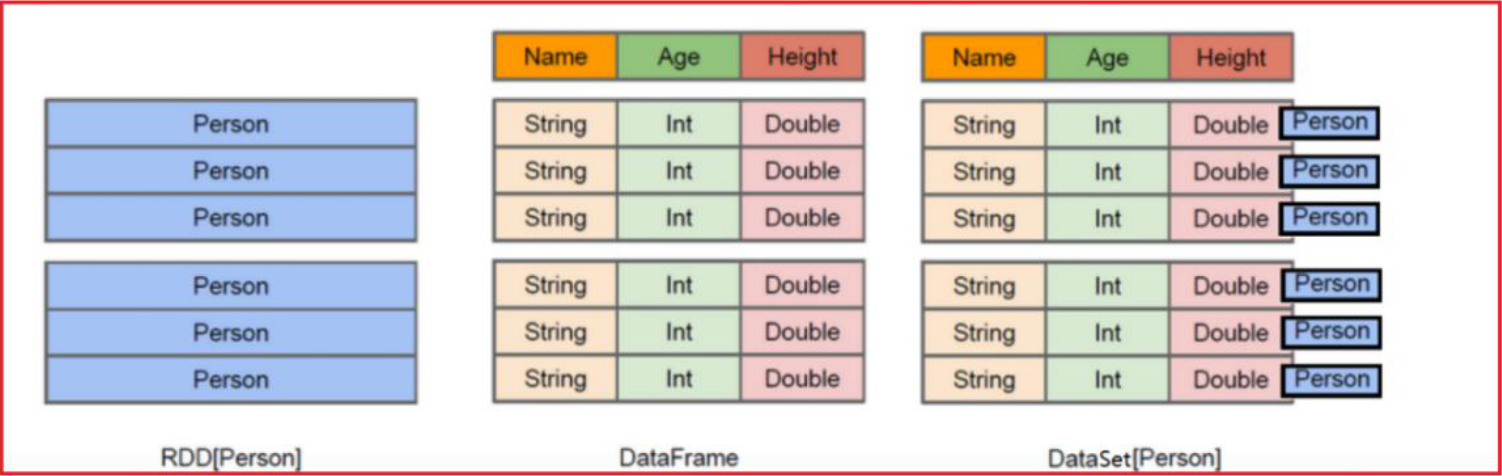
RDD表示的具体数据对象,一个RDD就代表一个数据集dataFrame : 是将RDD中对象中各个属性拆解出来,形成一列列的数据,变更为一个二维的表dataSet : 是在dataFrame的基础上,加入了泛型的支持,将每一行的数据,使用一个泛型来表示从Spark SQL 2.0 开始,整个Spark SQL只有一种数据结构 : dataSet但是由于Spark SQL需要支持多种语言的开发工作,有一些语言并不支持泛型,所以Spark SQL为了能够让这些语言对接Spark SQL,所以在客户端依然保留了dataFrame的接口,让其他无泛型的言使用dataFrame接口来对接即可,底层会将其转换为dataSet
2. Spark SQL的入门案例
2.1 Spark SQL的统一入口
从Spark SQL开始,需要将核心对象,从SparkContext切换为Spark Session对象
Spark Session对象是Spark 2.0后推出一个全新的对象,此对象将会作为Spark整个编码入口对象,次对象不仅仅可以操作Spark SQL还可以获取到SparkContext对象,用于操作Spark Core代码
如何构建Spark Session对象呢?
from pyspark import SparkContext, SparkConffrom pyspark.sql import SparkSessionimport os# 锁定远端python版本:os.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("演示: 如何构建Spark Session")# 1- 创建SparkSession对象:spark = SparkSession.builder.master.master('local[*]').appName('create_part').getOrCreate()print(spark)
2.2 Spark SQL的入门案例
- 1 - 在_03_pyspark_sql 项目中的data目录下创建一个stu.csv文本文件 ```properties 文件内容如下:
id,name,age 1,张三,20 2,李四,18 3,王五,22 4,赵六,25
- 2 - 代码实现:需求 请将年龄大于20岁的数据获取出来```pythonfrom pyspark import SparkContext, SparkConffrom pyspark.sql import SparkSessionimport os# 锁定远端python版本:os.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("spark SQL 入门案例")# 1- 构建SparkSession对象spark = SparkSession\.builder\.master('local[*]').appName('init_pyspark SQL')\.getOrCreate()# 2- 读取外部文件的数据df_init = spark.read.csv(path='file:///export/data/workspace/sz30_pyspark_parent/_03_pyspark_sql/data/stu.csv',header=True,sep = ',',inferSchema = True)# 3- 获取数据 和 元数据信息df_init.show()df_init.printSchema()# 4- 需求 将年龄大于20岁的数据获取出来:DSLdf_where = df_init.where('age > 20')df_where.show()# 使用 SQL 来实现df_init.createTempView('t1')spark.sql('select * from t1 where age > 20').show()# 关闭 spark 对象spark.stop()
3. dataFrame详解
3.1 dataFrame基本介绍
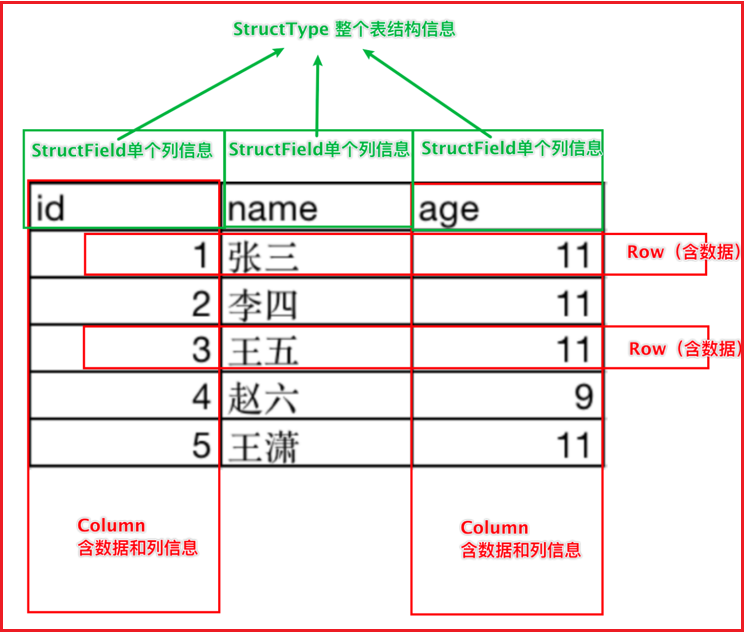
dataFrame表示的是一个二维的表,那么应该有 字段名字,字段的类型,数据
dataFrame中,主要有 structType 和 Row 来组成的其中 :StructType : 其实dataFrame中表示schema元数据信息的核心对象StructField : 表示字段的对象,一个StructTyre中可以有多个StructField,类似于一个表中可以 有多个列涵盖三个部分的内容 : 字段名称,字段的类型,字段数据是否可以为空Row : 行,表示的行数据,每一行的数据就是一个ROW对象Column : 一列数据包含列信息和列数据

3.2 dataFrame的构建方式
- 方式一:通过RDD转换为dataFrame ```python from pyspark import SparkContext, SparkConf from pyspark.sql import SparkSession from pyspark.sql.types import * import os
锁定远端python版本:
os.environ[‘SPARK_HOME’] = ‘/export/server/spark’ os.environ[‘PYSPARK_PYTHON’] = ‘/root/anaconda3/bin/python3’ os.environ[‘PYSPARK_DRIVER_PYTHON’] = ‘/root/anaconda3/bin/python3’
if name == ‘main‘: print(“方式一: 通过RDD转换为dataFrame”)
# 1- 创建SparkSession对象# 快速返回变量:Ctrl + alt + vspark = SparkSession.builder.master('local[*]').appName('create_df').getOrCreate()# 从Spark中获取SparkContext对象sc = spark.sparkContext# 2- 读取数据,获取RDDrdd_init = sc.parallelize([('c01','张三',20),('c02','李四',15),('c03','王五',26),('c01','赵六',30)])# 3- 通过RDD 将c01的数据过滤rdd_filter = rdd_init.filter(lambda tup:tup[0] != 'c01')# 4- 请将RDD转换dataFrame对象# 4.1 方案一schema = StructType()\.add('id',StringType(),True).add('name',StringType(),False).add('age',IntegerType)df_init = spark.createDataFrame(rdd_filter,schema = schema)# 打印结果:df_init.printSchema()df_init.show()# 4.2 方案二df_init = spark.createDataFrame(rdd_filter,schema = ['id','name','age'])# 打印结果df_init.printSchema()df_init.show()# 4.2 方案三:df_init = spark.createDataFrame(rdd_filter)# 打印结果:df_init.printSchema()df_init.show()# 4.3 方案四:df_init = rdd_filter.toDF()# 打印结果:df_init.printSchema()df_init.show()# 4.3 方案五:df_init = rdd_filter.toDF(schema=schema)# 打印结果:df_init.printSchema()df_init.show()# 4.3 方案六:df_init = rdd_filter.toDF(schema=['id','name','age'])# 打印结果:df_init.printSchema()df_init.show()
有啥用:```python当我们需要读取的数据是一种半结构化的数据,但是希望使用spark SQL来处理,此时可以先使用spark core来读取数据,将数据进行清洗转换处理的操作,将其转换为结构化的数据,然后将RDD转换DF 通过spark SQL来处理
- 方式二:通过pandas的DF对象 转换为 spark SQL的DF对象 ```python from pyspark import SparkContext, SparkConf from pyspark.sql import SparkSession import os import pandas as pd
锁定远端python版本:
os.environ[‘SPARK_HOME’] = ‘/export/server/spark’ os.environ[‘PYSPARK_PYTHON’] = ‘/root/anaconda3/bin/python3’ os.environ[‘PYSPARK_DRIVER_PYTHON’] = ‘/root/anaconda3/bin/python3’
if name == ‘main‘: print(“演示pandas DF 转换为 spark SQL DF”)
# 1- 构建Spark SQL对象spark = SparkSession.builder.master('local[*]').appName("create_df").getOrCreate()# 2- 构建 pandas DF 对象pd_df = pd.DataFrame({'id':['c01','c02','c03'],'name':['张三','李四','王五']})# 将 pd_df 转换为 spark SQL 的dfspark_df = spark.createDataFrame(pd_df)spark_df.show()spark_df.printSchema()
```python当初处理的数据源比较特殊的时候,比如 excel 格式,此时可以通过pandas的DF直接读取,然后转换为 spark 的DF进行处理,从而扩充spark的读取的数据源
- 方式三:通过读取外部的文件的方式
通用完整的格式 :sparkSession对象.read.format('text|csv|json|parquet|orc|avro|jdbc|...').option('参数的key','参数的值') # 可选项:读取的格式不同,参数也不同.load('指定读取数据的路径: 支持本地和HDFS')
演示:读取CSV
from pyspark import SparkContext, SparkConffrom pyspark.sql import SparkSessionimport os# 锁定远端python版本:os.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("读取外部文件的方式构建DF")# 1- 构建Spark SQL对象spark = SparkSession.builder.master('local[*]').appName("create_df").getOrCreate()# 2- 读取数据# sep参数: 设置csv文件中字段的分隔符号,默认为 逗号# header参数: 设置csv是否含有头信息 True 有 默认为 false# inferSchema参数: 用于让程序自动推断字段的类型 默认为false 默认所有的类型都是string# encoding参数: 设置对应文件的字符集 默认为 UTF-8df_init = spark.read\.format('csv')\.option('sep',',') \.option('header', True) \.option('inferSchema', True) \.option('encoding', 'UTF-8') \.load('file:///export/data/workspace/sz30_pyspark_parent/_03_pyspark_sql/data/stu.csv')df_init.printSchema()df_init.show()
演示:采用text方式读取数据
from pyspark import SparkContext, SparkConffrom pyspark.sql import SparkSessionimport os# 锁定远端python版本:os.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("读取外部文件的方式构建DF")# 1- 构建Spark SQL对象spark = SparkSession.builder.master('local[*]').appName("create_df").getOrCreate()# 2- 读取数据# 采用text的方式来读取数据, 仅支持产生一列数据, 默认列名为 value, 当然可以通过schema修改列名df_init = spark.read\.format('text')\.schema(schema='id String')\.load('file:///export/data/workspace/sz30_pyspark_parent/_03_pyspark_sql/data/stu.csv')df_init.printSchema()df_init.show()
演示:采用JSON方式来读取数据
from pyspark import SparkContext, SparkConffrom pyspark.sql import SparkSessionimport os# 锁定远端python版本:os.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("读取外部文件的方式构建DF")# 1- 构建Spark SQL对象spark = SparkSession.builder.master('local[*]').appName("create_df").getOrCreate()# 2- 读取数据# 采用text的方式来读取数据, 仅支持产生一列数据, 默认列名为 value, 当然可以通过schema修改列名df_init = spark.read\.format('json')\.load('file:///export/data/workspace/sz30_pyspark_parent/_03_pyspark_sql/data/people.json')df_init.printSchema()df_init.show()
请注意:所有的刚刚的完整的写法都存在简单写法
比如说以CSV举例说明:spark.read.csv(path ='xxx',header=True,encoding='UTF-8',inferSchema=True)其他的类似:spark.read.textjsonparquetorcjdbc.....比如说以CSV举例说明:spark.read.csv()
3.3 dataFrame的相关API
dataFrame的操作,主要支持俩种方式:DSL和SQL
DSL : 特定领域语言在 Spark SQL中 DSL 指的 dataFrame 的相关的API相当简单,因为大多数的API都与SQL的关键词同名SQL : 主要通过编写 SQL 完成统计分析操作思考 : 在工作中,这俩种方案,会使用哪种呢?在刚刚接触使用 Spark SQL 的时候,更多的使用的SQL的方式来操作(大多数的行为),从Spark官方角度来看,推荐使用DSL,因为DSL对于框架更容易解析处理,效率相对SQL来说,更搞笑一些(本质差别不大)一般编写DSL看起来要比SQL高大上一些,而且当你习惯DSL方案后,你会不断尝试使用的
DSL相关的API:
- 1 、 show()方法:用于显示表中的数据

一般都不设置相关的参数,直接用
- 2、printSchema():用于打印表的结构信息(元数据信息)
- 3、select():此API是用于实现在SQL中select后面放置的内容
- 比如说:可以放置字段,或者相关函数,或者表达式
- 如何查看每个API支持传递哪些方式呢?
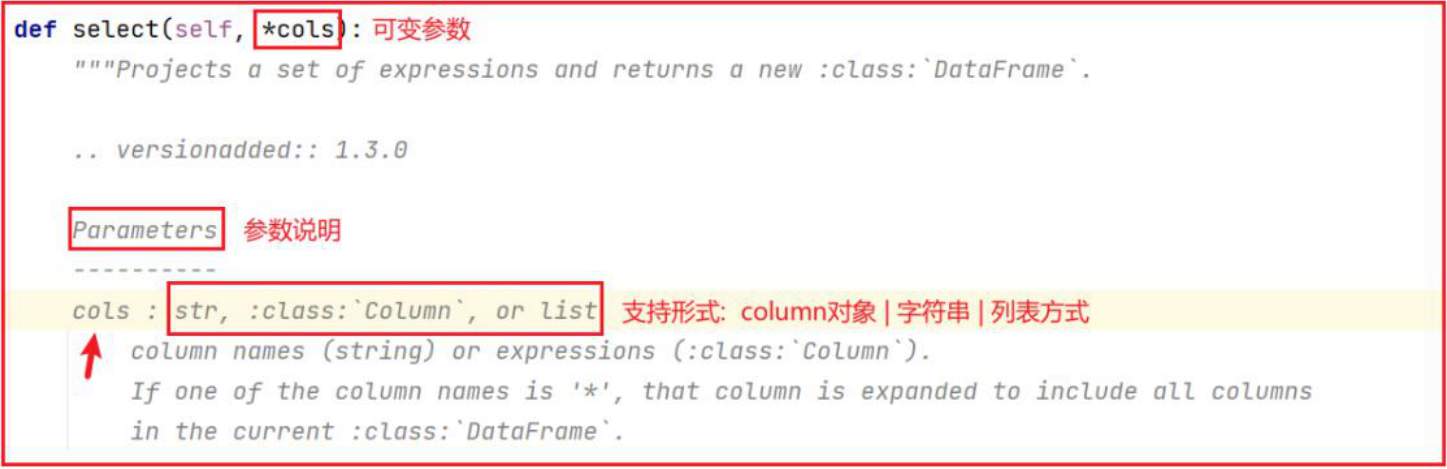
在使用dataFrame的相关API的时候,传入参数的说明:在使用dataFrame的API的时候,每个API的传入参数方式都支持多种方式 : 字符串,列表,column对象select如何使用呢?字符串方式:df.select('id,name,age')列表方式:df.select(['id','name','age'])colume对象:df.select([df['id'],df['name'],df['age']])
- 4、filter 和 where : 用于对数据进行过滤的操作
- 5、groupBy:对数据执行分组
- 说明:分组必聚合
说明:说过想在DSL中使用SQL的函数,在Spark SQL中,专门将函数放置在一个类中
1- 先导入函数的核心对象:
import pyspark.sql.functions as F
2- 使用F.函数名 即可使用
SQL形式:
使用SQL方式来处理,必须将DF注册为一个视图(表):支持临时视图和全局视图
spark.sql(编写SQL语句)
df = spark.SQL() 编写SQL语句即可
编写一个小案例演示刚刚的API
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
import os
import pyspark.sql.functions as F
# 锁定远端python版本:
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("演示dataFrame的相关的API")
# 1- 构建Spark SQL对象
spark = SparkSession.builder.master('local[*]').appName("create_df").getOrCreate()
# 2- 读取数据 :
df = spark.read.csv(
path='file:///export/data/workspace/sz30_pyspark_parent/_03_pyspark_sql/data/stu.csv',
header=True,
inferSchema=True
)
# 演示相关的API:
df.printSchema()
df.show()
# select操作:查看 id列和 address列
df.select('id','address').show()
df.select(df['id'], df['address']).show()
df.select([df['id'], df['address']]).show()
df.select(['id', 'address']).show()
# where和filter
df.where(df['id'] > 2).show()
df.where('id > 2').show()
# group by : 统计每个地区有多少个人
df.groupby(df['address']).count().show()
# 统计每个地区下有多少个人以及有多少个不同年龄的人
df.groupby('address').agg(
F.count('id').alias('cnt'),
F.countDistinct('age').alias('age_cnt')
).show()
# SQL:
df.createTempView('t1')
spark.sql("select address, count(id) as cnt,count(distinct age) as age_cnt from t1 group by address").show()
3.4 综合案例
3.4.1 词频统计分析案例
- 通过RDD转换为DF:演示DSL和SQL ```python from pyspark import SparkContext, SparkConf from pyspark.sql import SparkSession import pyspark.sql.functions as F import os
锁定远端python版本:
os.environ[‘SPARK_HOME’] = ‘/export/server/spark’ os.environ[‘PYSPARK_PYTHON’] = ‘/root/anaconda3/bin/python3’ os.environ[‘PYSPARK_DRIVER_PYTHON’] = ‘/root/anaconda3/bin/python3’
if name == ‘main‘: print(“WordCount案例: 方式一 RDD 转换为 DF 方式完成”)
# 1- 创建SparkSession对象 和 sc对象
spark = SparkSession.builder.master('local[*]').appName('wd_1').getOrCreate()
sc = spark.sparkContext
# 2- 读取数据: 采用 RDD方式
rdd_init = sc.textFile('file:///export/data/workspace/sz30_pyspark_parent/_03_pyspark_sql/data/word.txt')
# 3- 将数据转换为一个个的单词 ['','','']
# 注意: 从 RDD转换为 DF 要求列表中数据必须为元组
rdd_word = rdd_init.flatMap(lambda line: line.split()).map(lambda word: (word,))
# 4- 将RDD转换DF对象
df_words = rdd_word.toDF(schema=['words'])
# 5- 完成 WordCount案例:
# SQL
df_words.createTempView('t1')
spark.sql('select words,count(1) as cnt from t1 group by words').show()
# DSL:
# withColumnRenamed: 修改列表: 参数1表示旧列名 参数2表示新列表
df_words.groupby(df_words['words']).count().withColumnRenamed('count','cnt').show()
df_words.groupby(df_words['words']).agg(
F.count('words').alias('cnt')
).show()
# 6- 关闭 spark
spark.stop()
- 方式二实现:直接读取为DF处理 DSL SQL 以及 DSL + SQL
```python
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
import os
# 锁定远端python版本:
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("演示WordCount案例实现方式二: 通过直接读取数据转换为DF处理")
# 1- 创建SparkSession对象
spark = SparkSession.builder.master('local[*]').appName('wd_2').getOrCreate()
# 2- 读取数据
df_init = spark.read.text('file:///export/data/workspace/sz30_pyspark_parent/_03_pyspark_sql/data/word.txt')
# 3- 处理数据:
# 纯 DSL方案:
# 3.1.1 首先先将数据转换为一列数据, 一行为一个单词 explode(列表)
df_words = df_init.select(
F.explode(F.split('value',' ')).alias('words')
)
# 3.1.2: 分组求个数
df_words.groupby('words').count().show()
# DSL + SQL 混和
#3.2.1 首先先将数据转换为一列数据, 一行为一个单词 explode(列表)
df_init.createTempView('t1')
df_words = spark.sql('select explode(split(value," ")) as words from t1')
# 3.1.2: 分组求个数
df_words.groupby('words').count().show()
# 纯 SQL实现
df_words = spark.sql('select explode(split(value," ")) as words from t1')
df_words.createTempView('t2')
spark.sql('select words,count(1) as cnt from t2 group by words').show()
# 等同于
spark.sql("""
select
words,count(1) as cnt
from
(select
explode(split(value," ")) as words
from t1) as t2
group by words
""") .show()
spark.sql("""
select
words,
count(1) as cnt
from t1 lateral view explode(split(value," ")) t2 as words
group by words
""")
3.4.2 电影分析案例
数据集的介绍: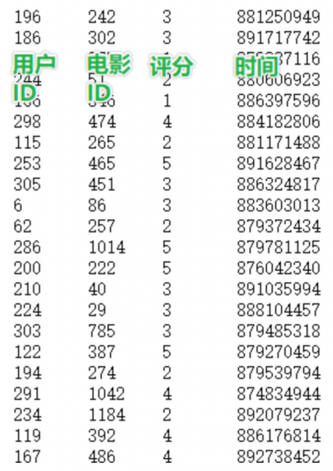
数据说明 : userid , movieid,score,datestr
字段的分隔符号为: \t
需求如下:
- 1- 将资料中 u.data 上传到HDFS的 /spark/movie_data
- 2- 需求实现:
- 实现需求一: 查询用户平均分 ```python from pyspark import SparkContext, SparkConf from pyspark.sql import SparkSession import pyspark.sql.functions as F import os
锁定远端python版本:
os.environ[‘SPARK_HOME’] = ‘/export/server/spark’ os.environ[‘PYSPARK_PYTHON’] = ‘/root/anaconda3/bin/python3’ os.environ[‘PYSPARK_DRIVER_PYTHON’] = ‘/root/anaconda3/bin/python3’
def xuqiu_1():
# SQL实现
spark.sql("""
select
userid,
round(avg(score),2) as u_avg
from t1
group by userid order by u_avg desc limit 10
""").show()
# DSL实现
df_init.groupby(df_init['userid']).agg(
F.round(F.avg('score'), 2).alias('u_avg')
).orderBy(F.desc('u_avg')).limit(10).show()
if name == ‘main‘: print(“演示电影分析案例”)
# 1- 创建SparkSession对象:
spark = SparkSession.builder.master('local[*]').appName('movie').getOrCreate()
# 2- 读取HDFS上movie数据集
df_init = spark.read.csv(
path = 'hdfs://node1:8020/spark/movie_data/u.data',
sep='\t',
schema='userid string,movieid string,score int,datestr string'
)
# 3- 处理数据:
df_init.createTempView('t1')
# 3.1 需求一: 查询用户平均分 (统计每个用户打分平均分)
#xuqiu_1()
- 需求四:查询高分电影中(>3) 打分次数最多的用户, 并求出此人打的平均分
```python
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
import os
# 锁定远端python版本:
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
def xuqiu_1():
# SQL实现
spark.sql("""
select
userid,
round(avg(score),2) as u_avg
from t1
group by userid order by u_avg desc limit 10
""").show()
# DSL实现
df_init.groupby(df_init['userid']).agg(
F.round(F.avg('score'), 2).alias('u_avg')
).orderBy(F.desc('u_avg')).limit(10).show()
if __name__ == '__main__':
print("演示电影分析案例")
# 1- 创建SparkSession对象:
spark = SparkSession.builder.master('local[*]').appName('movie').getOrCreate()
# 2- 读取HDFS上movie数据集
df_init = spark.read.csv(
path = 'hdfs://node1:8020/spark/movie_data/u.data',
sep='\t',
schema='userid string,movieid string,score int,datestr string'
)
# 3- 处理数据:
df_init.createTempView('t1')
# 3.1 需求一: 查询用户平均分 (统计每个用户打分平均分)
#xuqiu_1()
#3.2 需求四: 查询高分电影中(>3) 打分次数最多的用户, 并求出此人打的平均分
# SQL:
# 3.2.1 找出所有的高分电影
df_top_movie = spark.sql("""
select
movieid,
round(avg(score),2) as avg_score
from t1
group by movieid having avg_score > 3
""")
df_top_movie.createTempView('t2_m_top')
# 3.2.2 在高分电影中找到打分次数最多的用户
df_u_top = spark.sql("""
select
t1.userid
from t2_m_top join t1 on t2_m_top.movieid = t1.movieid
group by t1.userid order by count(1) desc limit 1
""")
df_u_top.createTempView('t3_u_top')
# 3.3.3 并求出此人在所有的电影中打的平均分
spark.sql("""
select
userid,
round(avg(score),2) as avg_score
from t1 where userid = (select
t1.userid
from t2_m_top join t1 on t2_m_top.movieid = t1.movieid
group by t1.userid order by count(1) desc limit 1
)
group by userid
""").show()
# 另一种方式 JOIN
spark.sql("""
select
t1.userid,
round(avg(t1.score),2) as avg_score
from t1 join t3_u_top on t1.userid = t3_u_top.userid
group by t1.userid
""").show()
# DSL实现:
# 3.2.1 找出所有的高分电影
df_top_movie = df_init.groupby('movieid').agg(
F.round(F.avg('score'),2).alias('avg_score')
).where('avg_score > 3')
# 3.2.2 在高分电影中找到打分次数最多的用户
df_u_top = df_top_movie.join(df_init,'movieid').groupby('userid').agg(
F.count('userid').alias('u_cnt')
).orderBy(F.desc('u_cnt')).select('userid').limit(1)
# 3.3.3 并求出此人在所有的电影中打的平均分
# df_u_top.first()['userid'] : df_u_top是一个二维表 调用first获取第一行的数据, ['字段名'] 获取对应列的数据的值
df_init.where(df_init['userid'] == df_u_top.first()['userid']).groupby('userid').agg(
F.round(F.avg('score'),2).alias('avg_score')
).show()
# 另一种方式
df_init.join(df_u_top,'userid').groupby('userid').agg(
F.round(F.avg('score'),2).alias('avg_score')
).show()

若有收获,就点个赞吧
0 人点赞
