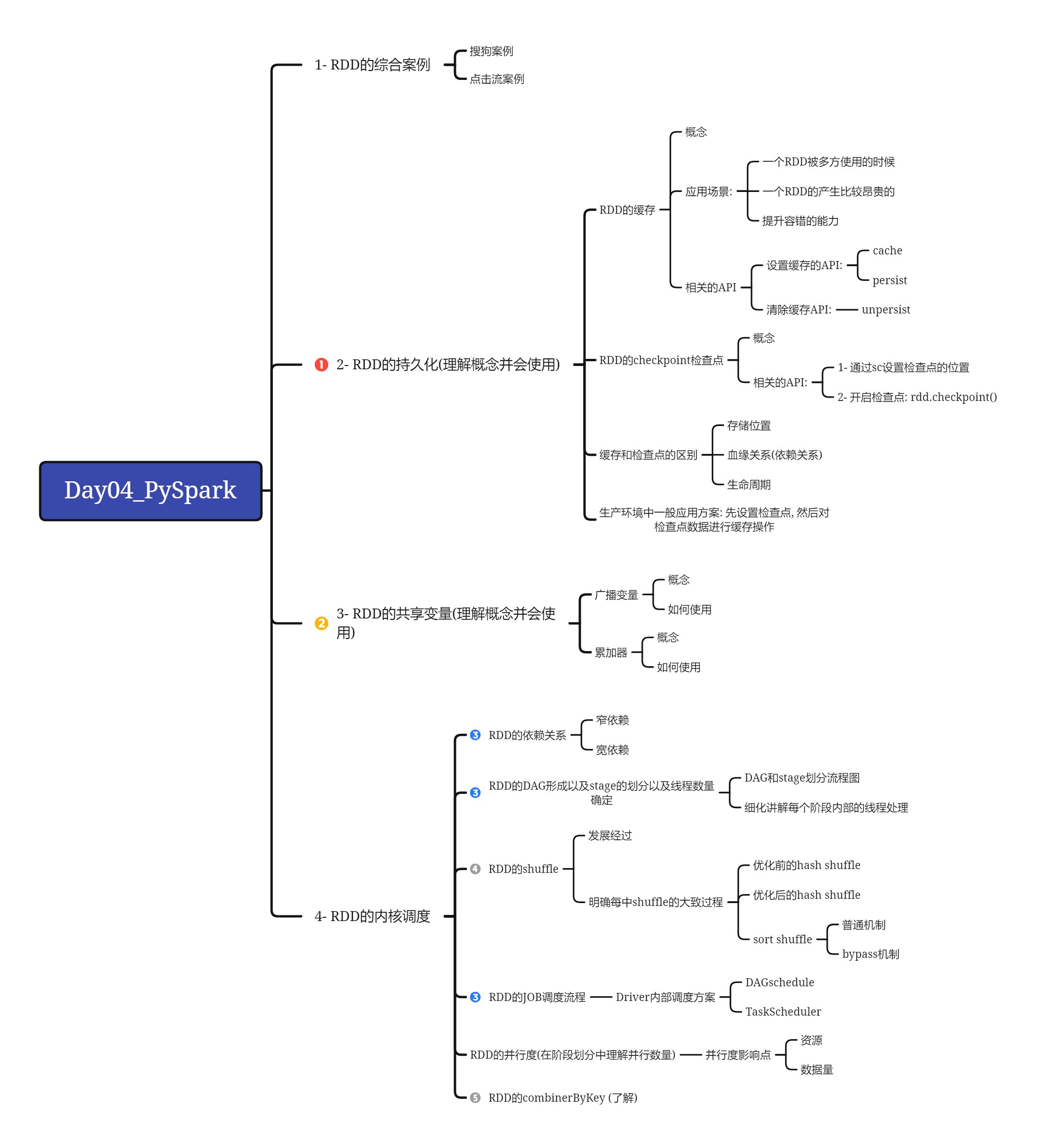
今日内容:
- 1- RDD的综合案例
- 2- RDD的持久化: 缓存 和 checkpoint
- 3- RDD的共享变量: 广播变量 和 累加器
- 4- RDD内核调度原理
3 - [PySpark生态]_PySparkCore.pptx
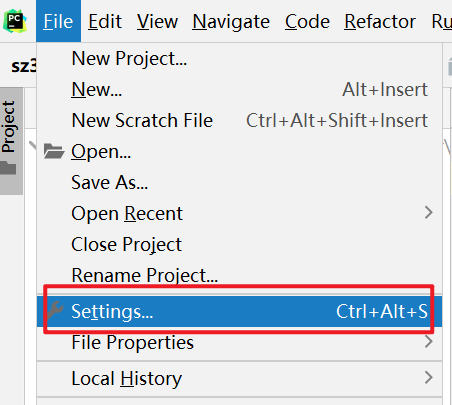
0- 如何在pycharm中设置python的模板
模板内容:
from pyspark import SparkContext, SparkConfimport os# 锁定远端python版本:os.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("pySpark模板")
如何设置:

1. 综合案例
1.1 搜索案例
数据集介绍:

访问时间 用户id []里面是用户输入搜索内容 url结果排名 用户点击页面排序 用户点击URL字段与字段之间的分隔符号为 \t和空格 (制表符号)需求一: 统计每个关键词出现了多少次需求二: 统计每个用户每个搜索词点击的次数需求三: 统计每个小时点击次数
- 准备工作: 读取数据, 将各个字段的数据通过元组的形式, 封装起来,并且对数据进行过滤, 保证每一行不能有空行并且字段个数为 6个
# 搜狗案例from pyspark import SparkContext, SparkConfimport os# 锁定远端python版本:os.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("搜狗案例")# 1- 创建SparkContext对象conf = SparkConf().setMaster('local[*]').setAppName('sougou')sc = SparkContext(conf=conf)# 2- 读取外部文件数据rdd_init = sc.textFile('file:///export/data/workspace/sz30_pyspark_parent/_02_pyspark_core/data/SogouQ.sample')# 3- 过滤数据: 保证数据不能为空 并且数据字段数量必须为 6个rdd_filter = rdd_init.filter(lambda line: line.strip() != '' and len(line.split()) == 6)# 4- 对数据进行切割, 将数据放置到一个元组中: 一行放置一个元组rdd_map = rdd_filter.map(lambda line: (line.split()[0],line.split()[1],line.split()[2][1:-1],line.split()[3],line.split()[4],line.split()[5]))# 5- 进行统计分析处理
- 需求一: 统计每个关键词出现了多少次
在目前的数据集中没有一个字段代表是关键词, 但是关键词是包含在搜索词中, 一个搜索词中可能包含了多个关键词例如:电脑创业 ---> 电脑 创业发现搜索词中包含了多个关键词, 所以首先需要从搜索词中提取各个关键词, 那么也就意味着要对数据进行分词操作如何进行分词呢? 中文分词python: jieba库java: IK分词器如何使用jieba分词器呢?1- 需要安装jieba分词器库 (local模式需要在node1安装即可, 如果集群模式各个节点都需要安装)pip install jieba2- 在代码中引入jieba库, 进行使用from pyspark import SparkContext, SparkConfimport jiebaimport os# 锁定远端python版本:os.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("pySpark模板")print(list(jieba.cut('我毕业于清华大学'))) # 默认分词方案 ['我', '毕业', '于', '清华大学']print(list(jieba.cut('我毕业于清华大学',cut_all=True))) # 全模式(最细粒度分析) ['我', '毕业', '于清华', '清华', '清华大学', '华大', '大学']print(list(jieba.cut_for_search('我毕业于清华大学'))) # 搜索引擎模式 ['我', '毕业', '于', '清华', '华大', '大学', '清华大学']
代码实现
def xuqiu_1():# 5.1.1 获取搜索词rdd_search = rdd_map.map(lambda line_tup: line_tup[2])# 5.1.2 对搜索词进行分词操作rdd_keywords = rdd_search.flatMap(lambda search: jieba.cut(search))# 5.1.3 将每个关键词转换为 (关键词,1) 进行分组统计rdd_res = rdd_keywords.map(lambda keyword: (keyword, 1)).reduceByKey(lambda agg, curr: agg + curr)# 5.1.4: 对结果数据进行排序(倒序)rdd_sort = rdd_res.sortBy(lambda res: res[1], ascending=False)# 5.1.5 获取结果(前50)print(rdd_sort.take(50))
- 需求二: 统计每个用户每个搜索词点击的次数
def xuqiu_2():# SQL: select user,搜索词 ,count(1) from 表 group by user,搜索词;# 提取 用户和搜索词数据rdd_user_search = rdd_map.map(lambda line_tup: (line_tup[1], line_tup[2]))# 基于用户和搜索词进行分组统计即可rdd_res = rdd_user_search.map(lambda user_search: (user_search, 1)).reduceByKey(lambda agg, curr: agg + curr)rdd_sort = rdd_res.sortBy(lambda res: res[1], ascending=False)print(rdd_sort.take(30))
- 需求三: 统计每个小时点击次数
1.2 点击流日志分析
点击流日志数据结构说明:

1- ip地址:2- 用户标识cookie信息(- - 标识没有)3- 访问时间(时间,时区)4- 请求方式(get / post /Head ....)5- 请求的URL路径6- 请求的协议7- 请求状态码: 200 成功8- 响应的字节长度9- 来源的URL( - 标识直接访问, 不是从某个页面跳转来的)10- 访问的浏览器标识
- 需求一: 统计pv(访问次数) 和 uv(用户数量)
# 点击流的案例from pyspark import SparkContext, SparkConfimport os# 锁定远端python版本:os.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("点击流的案例")# 1- 创建SparkContext对象conf = SparkConf().setMaster('local[*]').setAppName('sougou')sc = SparkContext(conf=conf)# 2- 读取外部文件的数据rdd_init = sc.textFile('file:///export/data/workspace/sz30_pyspark_parent/_02_pyspark_core/data/access.log')# 3- 过滤掉空行数据并且数据的长度>=12rdd_filter = rdd_init.filter(lambda line : line.strip() != '' and len(line.split()) >=12)# 4- 统计pv和uv# pv: 访问的次数print(rdd_filter.count())# uv: 独立访客数print(rdd_filter.map(lambda line: line.split()[0]).distinct().count())
- 需求二: 统计每个访问的URL的次数, 找到前10个
# 5- 统计每个访问的URL的次数print(rdd_filter.map(lambda line: (line.split()[6], 1)).reduceByKey(lambda agg, curr: agg + curr).sortBy(lambda res: res[1], ascending=False).take(10))
以上两个案例, 要求: 尽可能自己独立完成
2. RDD的持久化
2.1 RDD的缓存
缓存:当一个RDD的产生过程(计算过程), 是比较昂贵的(生成RDD整个计算流程比较复杂), 并且这个RDD可能会被多方(RDD会被重复使用)进行使用,此时为了提升计算效率, 可以将RDD的结果设置为缓存, 这样后续在使用这个RDD的时候, 无需在重新计算了, 直接获取缓存中数据即可提升Spark的容错的能力, 正常情况, 当Spark中某一个RDD计算失败的时候, 需要对整个RDD链条进行整体的回溯计算, 有了缓存后, 可以将某些阶段的RDD进行缓存操作, 这样当后续的RDD计算失败的时候, 可以从最近的一个缓存中恢复数据 重新计算即可, 无需在回溯所有链条应用场景:1- 当一个RDD被重复使用的时候, 可以使用缓存来解决2- 当一个RDD产生非常昂贵的时候, 可以将RDD设置为缓存3- 当需要提升容错能力的时候, 可以在局部设置一些缓存来提升容错能力注意事项:1- 缓存仅仅是一种临时存储, 可以将RDD的结果数据存储到内存(executor) 或者 磁盘 甚至可以存储到堆外内存(executor以外系统内存)中2- 由于缓存的存储是一种临时存储, 所以缓存的数据有可能丢失的, 所以缓存操作并不会将RDD之间的依赖关系给截断掉(清除掉), 以防止当缓存数据丢失的时候, 可以让程序进行重新计算操作3) 缓存的API都是lazy的, 设置缓存后, 并不会立即触发, 如果需要立即触发, 后续必须跟一个action算子, 建议使用 count
如何使用缓存呢?
设置缓存的相关API:rdd.cache(): 执行设置缓存的操作, cache在设置缓存的时候, 仅能将缓存数据放置到内存中rdd.persist(设置缓存级别): 执行设置缓存的操作, 默认情况下, 将缓存数据放置到内存中, 同时支持设置其他缓存方案手动清理缓存:rdd.unpersist(): 清理缓存默认情况下, 当程序执行完成后, 缓存会被自动清理常用的缓存级别有那些呢?MEMORY_ONLY: 仅缓存到内存中,直接将整个对象保存到内存中MEMORY_ONLY_SER: 仅缓存到内存中, 同时在缓存数据的时候, 会对数据进行序列化(从对象 --> 二进制数据)操作, 可以在一定程序上减少内存的使用量MEMORY_AND_DISK:MEMORY_AND_DISK_2: 优先将数据保存到内存中, 当内存不足的时候, 可以将数据保存到磁盘中, 带2的表示保存二份MEMORY_AND_DISK_SER:MEMORY_AND_DISK_SER_2: 优先将数据保存到内存中, 当内存不足的时候, 可以将数据保存到磁盘中, 带2的表示保存二份, 对于保存到内存的数据, 会进行序列化的操作, 从而减少内存占用量 提升内存保存数据体量,对磁盘必须要进行序列化序列化: 将数据 从 对象 转换为 二进制的数据, 对于RDD的数据来说, 内部数据都是一个个对象, 如果没有序列化是直接将对象存储到内存中, 如果有序列化会将对象转换为二进制然后存储到内存中好处: 减少内存的占用量, 从而让有限内存可以存储更多的数据弊端: 会增大对CPU的占用量, 因为转换的操作, 需要使用CPU来工作带2表示的保存多个副本, 从而提升数据可靠性
代码演示:
# 搜狗案例from pyspark import SparkContext, SparkConf,StorageLevelimport osimport jiebaimport time# 锁定远端python版本:os.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'def xuqiu_1():# 5.1.1 获取搜索词rdd_search = rdd_map.map(lambda line_tup: line_tup[2])# 5.1.2 对搜索词进行分词操作rdd_keywords = rdd_search.flatMap(lambda search: jieba.cut(search))# 5.1.3 将每个关键词转换为 (关键词,1) 进行分组统计rdd_res = rdd_keywords.map(lambda keyword: (keyword, 1)).reduceByKey(lambda agg, curr: agg + curr)# 5.1.4: 对结果数据进行排序(倒序)rdd_sort = rdd_res.sortBy(lambda res: res[1], ascending=False)# 5.1.5 获取结果(前50)print(rdd_sort.take(50))def xuqiu_2():# SQL: select user,搜索词 ,count(1) from 表 group by user,搜索词;# 提取 用户和搜索词数据rdd_user_search = rdd_map.map(lambda line_tup: (line_tup[1], line_tup[2]))# 基于用户和搜索词进行分组统计即可rdd_res = rdd_user_search.map(lambda user_search: (user_search, 1)).reduceByKey(lambda agg, curr: agg + curr)rdd_sort = rdd_res.sortBy(lambda res: res[1], ascending=False)print(rdd_sort.take(30))if __name__ == '__main__':print("搜狗案例")# 1- 创建SparkContext对象conf = SparkConf().setMaster('local[*]').setAppName('sougou')sc = SparkContext(conf=conf)# 2- 读取外部文件数据rdd_init = sc.textFile('file:///export/data/workspace/sz30_pyspark_parent/_02_pyspark_core/data/SogouQ.sample')# 3- 过滤数据: 保证数据不能为空 并且数据字段数量必须为 6个rdd_filter = rdd_init.filter(lambda line: line.strip() != '' and len(line.split()) == 6)# 4- 对数据进行切割, 将数据放置到一个元组中: 一行放置一个元组rdd_map = rdd_filter.map(lambda line: (line.split()[0],line.split()[1],line.split()[2][1:-1],line.split()[3],line.split()[4],line.split()[5]))# -----------------设置缓存的代码--------------------# StorageLevel 这个类需要在前面的from pyspark中加入此对象的导入# 一般建议, 设置完缓存后, 让其立即触发rdd_map.persist(storageLevel=StorageLevel.MEMORY_AND_DISK).count()# 5- 进行统计分析处理# 5.1 : 统计每个关键词出现了多少次# 快速抽取函数: ctrl + alt + mxuqiu_1()# ----------手动清理缓存------------rdd_map.unpersist().count()#5.2 需求二: 统计每个用户每个搜索词点击的次数xuqiu_2()time.sleep(1000)
如果通过job的DAG执行流程图可以看到有一个小绿球 那么就说明缓存生效了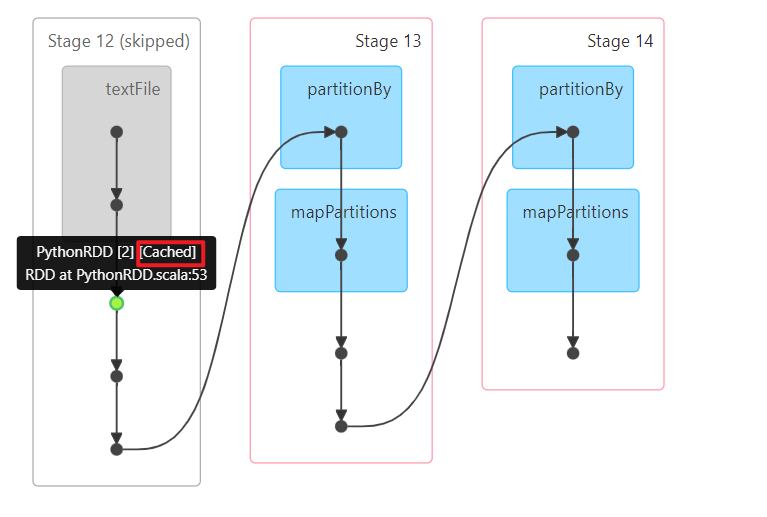
缓存的信息从哪里查看呢?

2.2 RDD的checkpoint检查点
checkPoint跟缓存类似, 也可以将某一个RDD结果进行存储操作, 一般都是将数据保存到HDFS中, 提供一种更加可靠的存储方案, 所以说采用checkpoint方案, 会将RDD之间的依赖关系给截断掉(因为 数据存储非常的可靠)checkpoint出现, 从某种角度上也可以提升执行效率(没有缓存高),更多是为了容错能力对于checkpoint来说, 大家可以将其理解为对整个RDD链条进行设置阶段快照的操作由于checkpoint这种可靠性, 所以Spark本身只管设置, 不管删除, 所以checkpoint即使程序停止了, checkpoint数据依然存储着, 不会被删除, 需要手动删除如何设置checkpoint呢?1- 通过sc对象, 设置checkpoint保存数据的位置: sc.setCheckpointDir('hdfs路径')2- 通过rdd.checkpoint() 设置开启检查点 (lazy)3- 通过rdd.count() 触发检查点的执行
代码演示:
# 演示checkpointfrom pyspark import SparkContext, SparkConfimport osimport time# 锁定远端python版本:os.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("演示checkpoint")# 1- 创建SparkContext对象conf = SparkConf().setMaster('local[*]').setAppName('sougou')sc = SparkContext(conf=conf)# 设置检查点位置sc.setCheckpointDir('/spark/checkpoint/')# 2- 读取数据rdd_init = sc.textFile('file:///export/data/workspace/sz30_pyspark_parent/_02_pyspark_core/data/SogouQ.sample')# 3- 一下演示代码, 无任何价值rdd_map1 = rdd_init.map(lambda line:line)rdd_map2 = rdd_map1.map(lambda line: line)rdd_3 = rdd_map2.repartition(3)rdd_map3 = rdd_3.map(lambda line: line)rdd_map4 = rdd_map3.map(lambda line: line)rdd_4 = rdd_map4.repartition(2)rdd_map5 = rdd_4.map(lambda line: line)# 开启检查点rdd_map5.checkpoint()rdd_map5.count()print(rdd_map5.count())time.sleep(1000)
原来执行流程图:
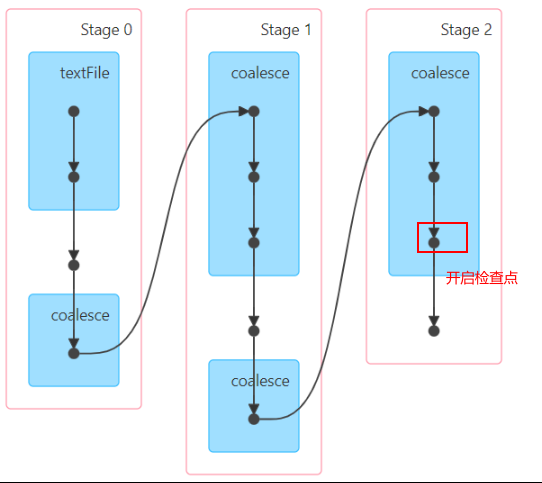
开启检查点后:
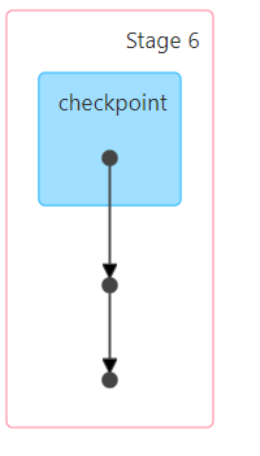
面试题: 在Spark中 RDD的缓存和检查点有什么区别呢?
区别一: 存储位置缓存: 会将RDD的结果数据缓存到内存或者磁盘, 或者堆外内存检查点: 会将RDD的结果数据存储到HDFS(默认),当然也支持本地存储(仅在local模式,但如果是local模式, 检查点无所谓)区别二: 依赖关系缓存: 由于缓存存储是一种临时存储, 所以缓存不会截断掉依赖关系, 以防止缓存丢失后, 进行回溯计算检查点: 会截断掉依赖关系, 因为检查点方案认为存储数据是可靠的, 不会丢失区别三: 生命周期缓存: 当整个程序执行完成后(一个程序中是包含多个JOB任务的), 会自动清理掉缓存数据,或者也可以在程序运行中手动清理检查点: 会将数据保存到HDFS中, 不会自动删除, 即使程序停止了, 检查点数据依然存在, 只能手动删除数据(会永久保存)
请问: 在实际使用中, 在Spark程序中, 是使用缓存呢 还是检查点呢? 会将两种方案都作用于程序中, 一般是先设置检查点, 然后设置缓存
代码演示:
# 搜狗案例from pyspark import SparkContext, SparkConf,StorageLevelimport osimport jiebaimport time# 锁定远端python版本:os.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'def xuqiu_1():# 5.1.1 获取搜索词rdd_search = rdd_map.map(lambda line_tup: line_tup[2])# 5.1.2 对搜索词进行分词操作rdd_keywords = rdd_search.flatMap(lambda search: jieba.cut(search))# 5.1.3 将每个关键词转换为 (关键词,1) 进行分组统计rdd_res = rdd_keywords.map(lambda keyword: (keyword, 1)).reduceByKey(lambda agg, curr: agg + curr)# 5.1.4: 对结果数据进行排序(倒序)rdd_sort = rdd_res.sortBy(lambda res: res[1], ascending=False)# 5.1.5 获取结果(前50)print(rdd_sort.take(50))def xuqiu_2():# SQL: select user,搜索词 ,count(1) from 表 group by user,搜索词;# 提取 用户和搜索词数据rdd_user_search = rdd_map.map(lambda line_tup: (line_tup[1], line_tup[2]))# 基于用户和搜索词进行分组统计即可rdd_res = rdd_user_search.map(lambda user_search: (user_search, 1)).reduceByKey(lambda agg, curr: agg + curr)rdd_sort = rdd_res.sortBy(lambda res: res[1], ascending=False)print(rdd_sort.take(30))if __name__ == '__main__':print("搜狗案例")# 1- 创建SparkContext对象conf = SparkConf().setMaster('local[*]').setAppName('sougou')sc = SparkContext(conf=conf)# ------------设置检查点保存位置------------sc.setCheckpointDir('/spark/checkpoint')# 2- 读取外部文件数据rdd_init = sc.textFile('file:///export/data/workspace/sz30_pyspark_parent/_02_pyspark_core/data/SogouQ.sample')# 3- 过滤数据: 保证数据不能为空 并且数据字段数量必须为 6个rdd_filter = rdd_init.filter(lambda line: line.strip() != '' and len(line.split()) == 6)# 4- 对数据进行切割, 将数据放置到一个元组中: 一行放置一个元组rdd_map = rdd_filter.map(lambda line: (line.split()[0],line.split()[1],line.split()[2][1:-1],line.split()[3],line.split()[4],line.split()[5]))# ---- 开启检查点 和 缓存 -----# 设置开启检查点rdd_map.checkpoint()rdd_map.persist(storageLevel=StorageLevel.MEMORY_AND_DISK).count()#或者rdd_map.persist(storageLevel=StorageLevel.MEMORY_AND_DISK)rdd_map.checkpoint()rdd_map.count()# 5- 进行统计分析处理# 5.1 : 统计每个关键词出现了多少次# 快速抽取函数: ctrl + alt + mxuqiu_1()#5.2 需求二: 统计每个用户每个搜索词点击的次数xuqiu_2()time.sleep(1000)
3. RDD的共享变量
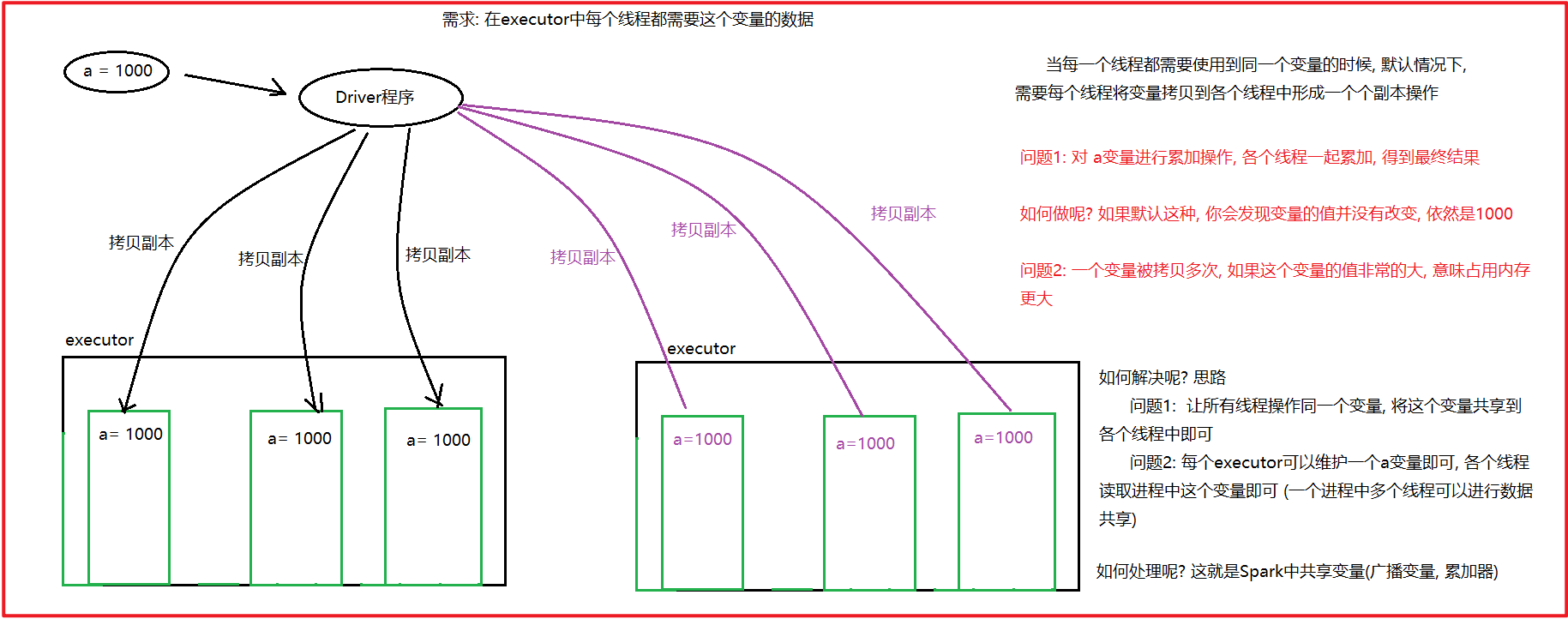
3.1 广播变量
广播变量:
目的: 减少Driver和executor之间网络数据传输数据量, 以及减少内存的使用 从而提升效率
适用于: 多个Task线程需要使用到同一个变量的值的时候
默认做法:
各个线程会将这个变量形成一个副本, 然后拷贝到自己的线程中, 进行使用即可, 由于一个executor中有多个线程, 那么意味需要拷贝多次, 导致executor和 Driver之间的传输量增加, 对带宽有一定影响, 同时拷贝了多次, 对内存占用量提升
解决方案: 引入一个广播变量
让executor从Driver中拉取过来一个副本即可, 一个executor只需要拉取一次副本, 让executor中各个线程读取executor中变量即可, 这样减少网络传输量, 同时减少内存使用量
注意: 广播变量是只读的, 各个线程只能读取数据, 不能修改数据
如何使用广播变量:
通过sc创建一个广播变量: 在Driver设置
广播变量对象 = sc.broadcast(值)
获取变量: 在Task获取
广播变量对象.value
代码演示:
from pyspark import SparkContext, SparkConf
import os
import time
# 锁定远端python版本:
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("演示广播变量的使用操作")
# 1- 创建SparkContext对象
conf = SparkConf().setMaster('local[*]').setAppName('sougou')
sc = SparkContext(conf=conf)
# 设置广播变量
bc = sc.broadcast(1000)
# 2 读取数据
rdd_init = sc.parallelize([1,2,3,4,5,6,7,8,9,10])
# 3- 将每个数据都加上指定值 ,此值由广播变量给出:
# 获取广播: bc.value
rdd_res = rdd_init.map(lambda num: num + bc.value)
# 4- 打印结果
rdd_res.foreach(lambda num: print(num))
time.sleep(10000)
3.2 累加器
累加器主要提供在多个线程中对同一个变量进行累加的操作, 对于多个线程来说只能对数据进行累加, 不能读取数据, 读取数据的操作只能有Driver来处理
应用场景: 全局累加操作
如何使用呢?
1- 由于Driver设置一个累加器的初始值
累加器对象 = sc.accumulator(初始值)
2- 由rdd(线程)来进行累加操作
累加器对象.add(累加内容)
3- 在Driver中获取值:
累加器.value
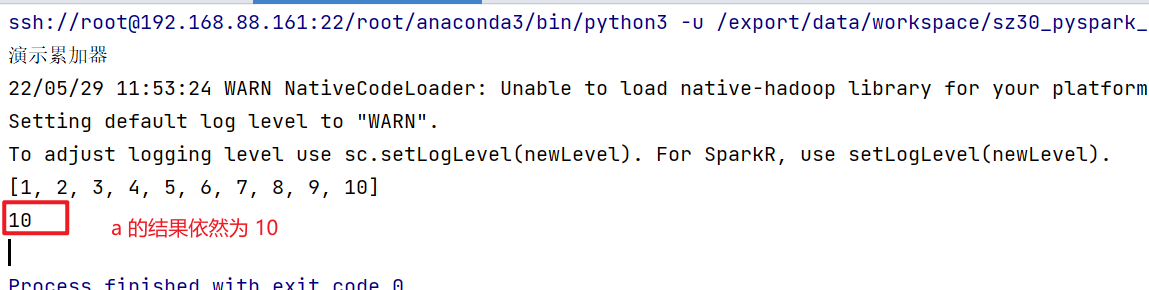
代码演示: 当没有累加器的时候
from pyspark import SparkContext, SparkConf
import os
# 锁定远端python版本:
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("演示累加器")
# 1- 创建SparkContext对象
conf = SparkConf().setMaster('local[*]').setAppName('sougou')
sc = SparkContext(conf=conf)
# 定义一个变量
a = 10
# 2 读取数据
rdd_init = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 3- 处理数据: 为a将列表中变量的值累加上去
def fn1(num):
global a
a += num
return num
rdd_map = rdd_init.map(fn1)
print(rdd_map.collect())
print(a)
引入累加器:
from pyspark import SparkContext, SparkConf
import os
# 锁定远端python版本:
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("演示累加器")
# 1- 创建SparkContext对象
conf = SparkConf().setMaster('local[*]').setAppName('sougou')
sc = SparkContext(conf=conf)
# 定义一个变量, 引入累加器
a = sc.accumulator(10)
# 2 读取数据
rdd_init = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 3- 处理数据: 为a将列表中变量的值累加上去
def fn1(num):
# 对累加器进行进行增加
a.add(num)
return num
rdd_map = rdd_init.map(fn1)
print(rdd_map.collect())
# 获取累加器的结果
print(a.value)

有一个问题点:
当我们对设置过累加器的RDD, 后续在进行一些其他的操作, 调度多次action算子后, 发现累加器被累加了多次, 本应该只累加一次, 这种情况是如何产生的呢?
原因: 当调度用多次action的时候, 会产生多个JOB(计算任务), 由于RDD值存储计算的规则, 不存储数据, 当第一个action计算完成后, 得到一个结果, 整个任务完成了, 接下来再运行下一个job的任务, 这个任务依然需要重头开始进行计算得到最终结果
这样就会 累加的操作就会被触发多次,从而被累加了多次
解决方案: 对累加器执行完的RDD 设置为缓存或者检查点, 或者两个都设置, 即可解决
4. RDD的内核调度
4.1 RDD的依赖
RDD之间是存在依赖关系, 这也是RDD中非常重要特性, 一般将RDD之间的依赖关系划分为两种
依赖关系: 窄依赖 和 宽依赖
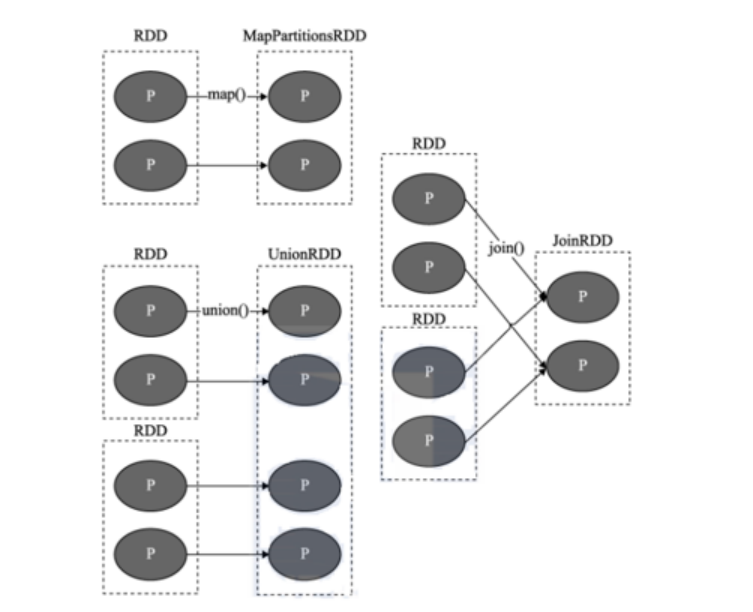
- 窄依赖:
目的: 让各个分区的数据可以并行的计算操作
指的: 上一个RDD的某一个分区的数据 被下一个RDD的某一个分区全部都继承处理下来, 我们将这种关系称为窄依赖关系
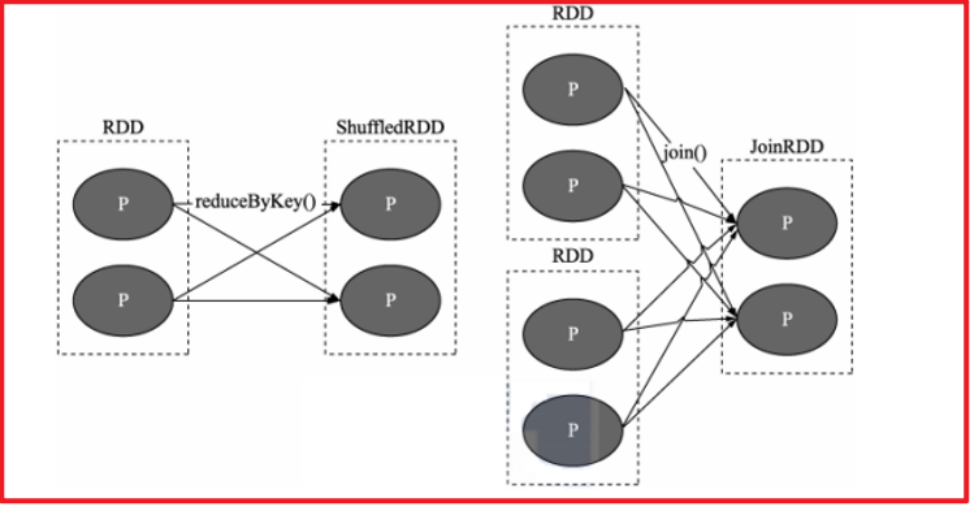
- 宽依赖:
目的: 划分stage阶段
指的: 上一个RDD的分区数据被下一个RDD的多个分区所接收并处理(shuffle), 我们将这种关系称为宽依赖
所以说, 判断两个RDD之间是否存在宽依赖, 主要看两个RDD之间是否存在shuffle, 一旦产生了shuffle, 必须是前面的先计算完成后, 然后才能进行后续的计算操作
说明:
在Spark中, 每一个算子是否存在shuffle操作, 在Spark设计的时候就已经确定了, 比如说 map一定不会有shuffle, 比如说reduceByKey一定是存在shuffle
如何判断这个算子是否会走shuffle呢? 可以从查看DAG执行流程图, 如果发现一执行到这个算子, 阶段被分为多个, 那么一定是存在shuffle, 以及可以通过查看每个算子的文档的说明信息, 里面也会有一定的说明
但是: 在实际操作中, 我们一般不会纠结这个事情, 我们要以实现需求为导向, 需要用什么算子的时候, 我们就采用什么算子来计算即可, 虽然说过多的shuffle操作, 会影响我们的执行的效率, 但是依然该用的还是要用的
判断宽窄依赖的关系最重要就是看两个RDD之间是否存在shuffle
4.2 DAG与stage
DAG: 有向无环图
整个的流程, 有方向, 不能往回走, 不断的往下继续的过程
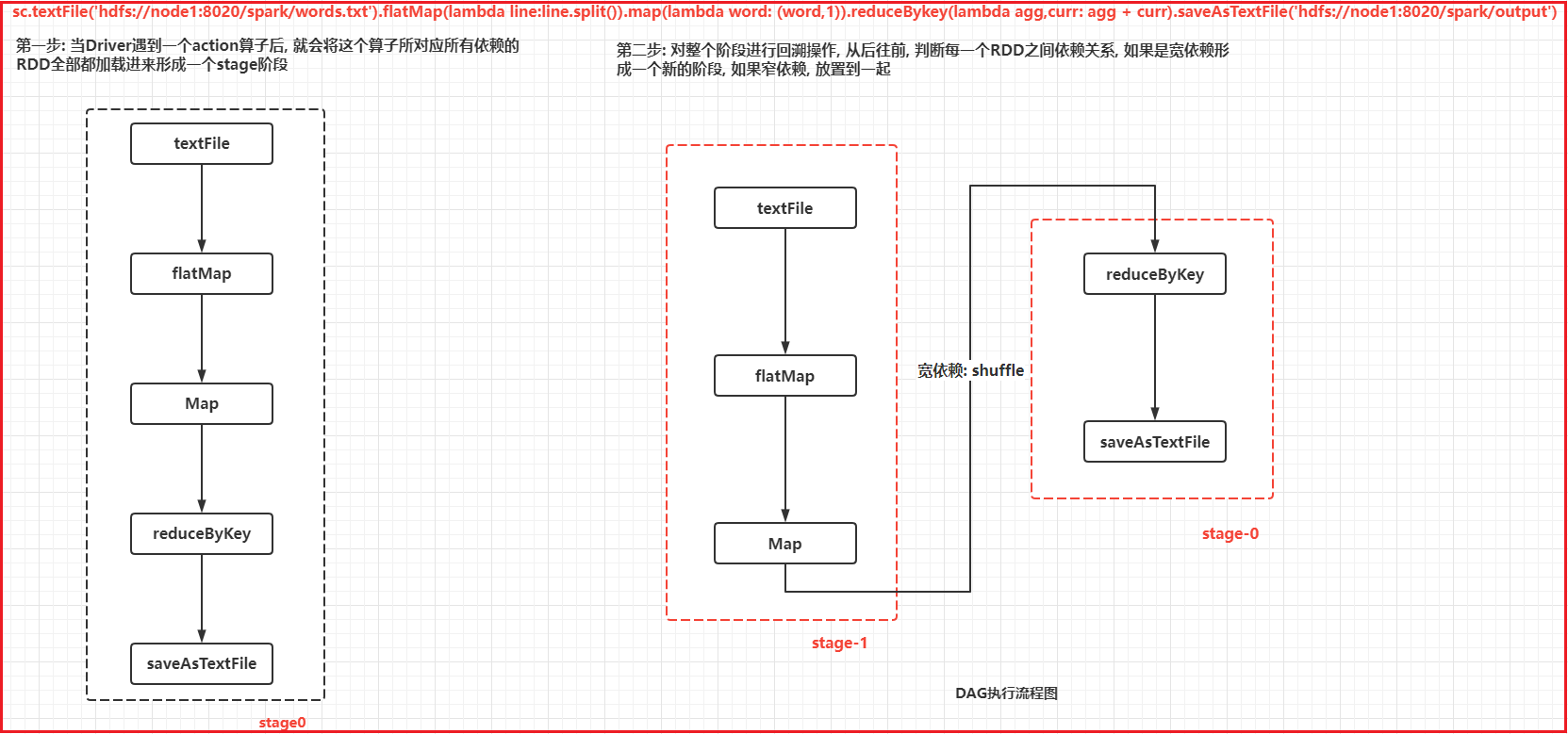
如何形成一个DAG执行流程图呢?
1- 第一步: 当Driver遇到一个action算子后, 就会将这个算子所对应所有依赖的RDD全部都加载进来形成一个stage阶段
2- 第二步: 对整个阶段进行回溯操作, 从后往前, 判断每一个RDD之间依赖关系, 如果是宽依赖形成一个新的阶段, 如果窄依赖, 放置到一起
3- 当整个回溯全部完成后, 形成了DAG的执行流程图
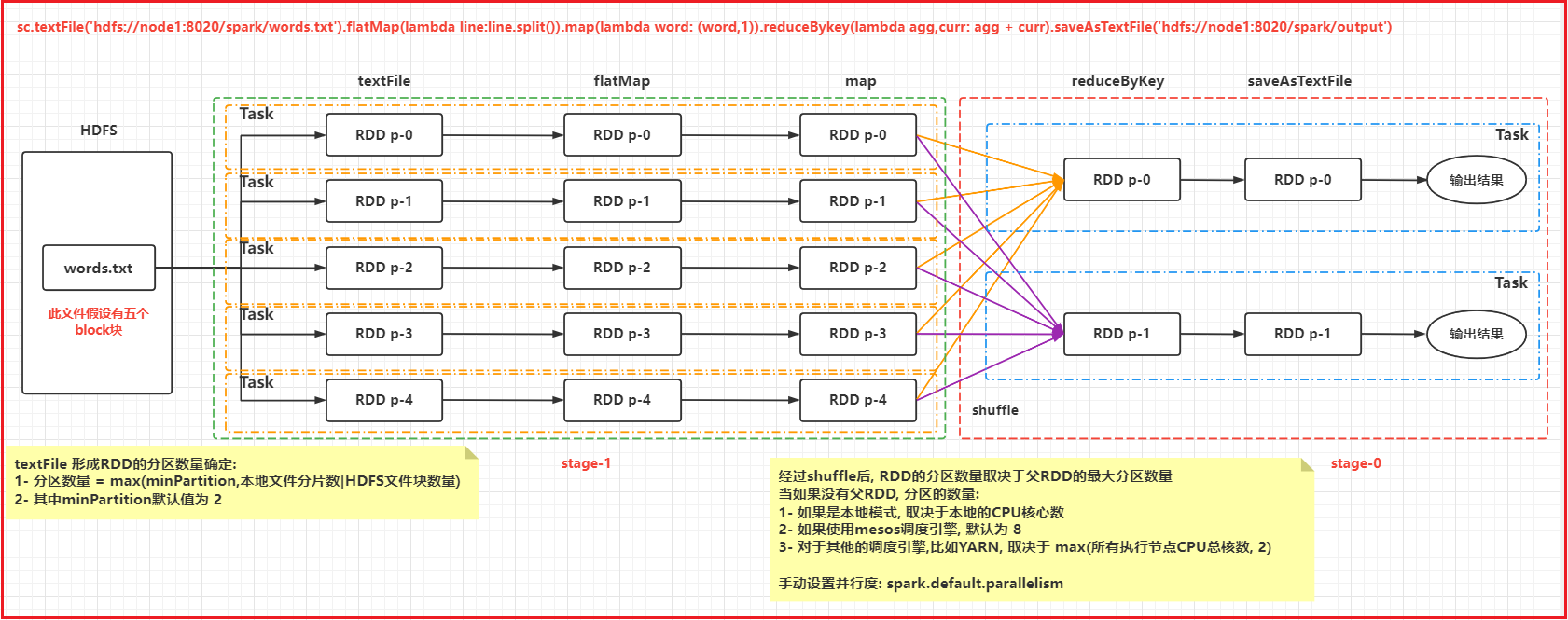
深度剖析, 内部的处理操作:
4.3 RDD的shuffle
spark中shuffle历史进程:
1- 在Spark 1.1以前的版本中, 整个Spark采用shuffle方案为 HASH shuffle
2- 在Spark 1.1版本的时候, 引入 Sort shuffle, 主要增加合并排序操作, 对原有HASH shuffle 进行优化
3- 在Spark 1.5 版本的时候, 引入钨丝计划: 优化操作, 提升内存以及CPU运行
4- 在Spark 1.6版本的时候 将钨丝计划合并到sort Shuffle中
5- 在spark 2.0版本以后, 删除掉 HASH shuffle, 全部合并到Sort shuffle中

优化前的Hash Shuffle:

shuffle过程:
父RDD的每个分区(线程)在生产各个分区的数据的时候, 会产生与子RDD分区数量相等的文件的数量, 每个文件对应一个子RDD的分区
当父RDD执行完成后, 子RDD 从父RDD产生的文件中, 找出对应分区文件, 直接拉取处理即可
思考: 有什么弊端呢?
父RDD产出的分区文件数量太多了, 从而在HDFS上产生了大量的小文件
由于文件变多了 对应磁盘IO也增大了, 需要打开文件N次
子RDD拉取数据, 文件数量也比较多, 磁盘IO比较大, 对效率有比较大的影响
优化后的shuffle:

经过优化后的HASH SHUFFLE, 整个生成的文件数量整体下降很多
将原来由各个线程来生成N个分区文件, 变更为由executor来统一生成与下游RDD分区数量相同的文件数量即可, 这样各个线程在输出数据的时候 将对应分区的数据输出到对应分区文件上即可, 下游的RDD在拉取数据的时候, 只需要拉取自己分区文件的数据即可
sort shuffle:
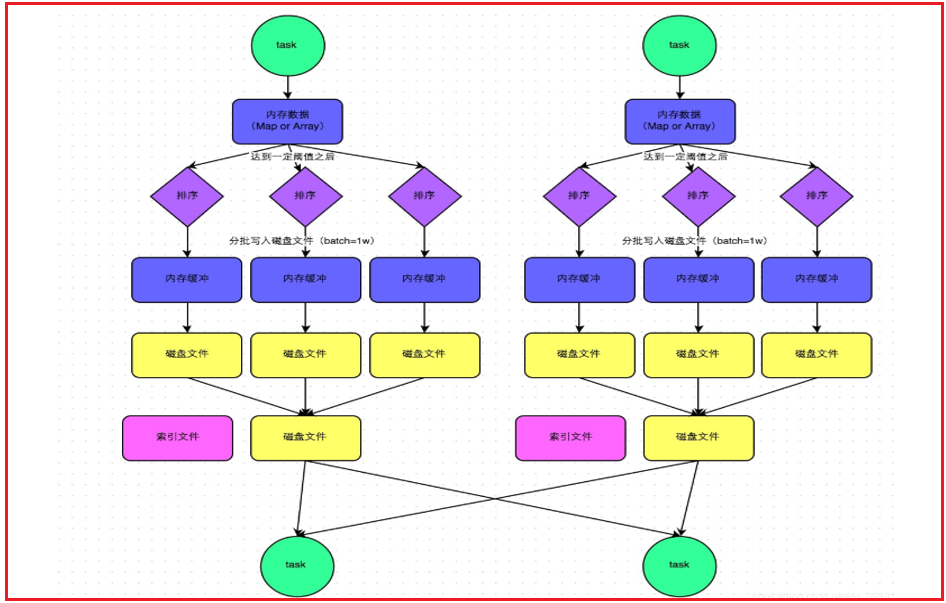
sort shuffle流程:
首先父RDD的各个线程将数据分好区后写入到内存中, 当内存达到一定的阈值后,就会触发溢写操作, 将数据溢写到磁盘上(分批次溢写:1w), 不断输出, 不断的溢写 , 产生多个小文件, 当整个父rdd的数据处理完成后, 然后对小文件进行合并操作, 形成一个最终的文件, 同时每一个文件都匹配一个索引文件, 用于下游的RDD在拉取数据的时候, 根据索引文件快速找到相对应的分区数据
在sort shuffle中两种机制: 普通机制 和 bypass机制
普通机制: 带有排序操作
首先父RDD的各个线程将数据分好区后写入到内存中, 当内存达到一定的阈值后,就会触发溢写操作, 将数据溢写到磁盘上(分批次溢写:1w),在溢写的过程中, 会对数据进行排序操作 不断输出, 不断的溢写 , 产生多个小文件, 当整个父rdd的数据处理完成后, 然后对小文件进行合并操作, 形成一个最终的文件,在形成的时候同样也会对数据进行排序操作, 同时每一个文件都匹配一个索引文件, 用于下游的RDD在拉取数据的时候, 根据索引文件快速找到相对应的分区数据
bypass机制: 不含排序 并不是所有的sort shuffle都可以走bypass
满足以下的条件:
1- 上游的RDD的分区数量要小于200
2- 上游不能执行提前聚合的操作
执行bypass机制, 由于没有了排序的操作, 整个执行效率要高于 普通机制
排序: 是为了后续可以更快速的进行分组聚合操作
4.4 JOB调度流程
Driver底层调度方案:
Driver中核心对象: SparkContext DAGSchedule和 TaskSchedule 和 scheduleBackend(资源平台)
1- 当启动Spark应用的时候, 首先执行Main函数, 创建一个 SparkContext对象, 当这个对象的创建的时候, 底层还同时构建 DAGSchedule和 TaskSchedule
2- 当Spark发现后续的代码有action算子后, 就会立即触发任务的执行, 生成一个JOB任务, 一个action就会触发一个Job任务
3- 触发任务后, 首先由Driver负责任务分配工作(DAG流程图, stage划分, 每个stage需要运行多少个线程, 每个线程需要在那个executor上.....)
3.1 首先由Driver中DAGSchedule执行, 主要进行DAG流程图的生成, 以及划分stage, 并且还会划分出每个stage阶段需要运行多少个线程, 并将每个阶段的线程封装到一个TaskSet的列表中, 有多少个阶段, 就会产生多少个TaskSet, 最后将TaskSet传递给TaskScheduler
3.2 接下来由TaskScheduler来处理, 根据TaskSet中描述的线程的信息, 将线程执行任务发送给executor来执行, 尽可能保证每一个分区的Task运行在不同的executor上, 确保资源最大化 , 整个资源申请都是由TaskScheduler申请的
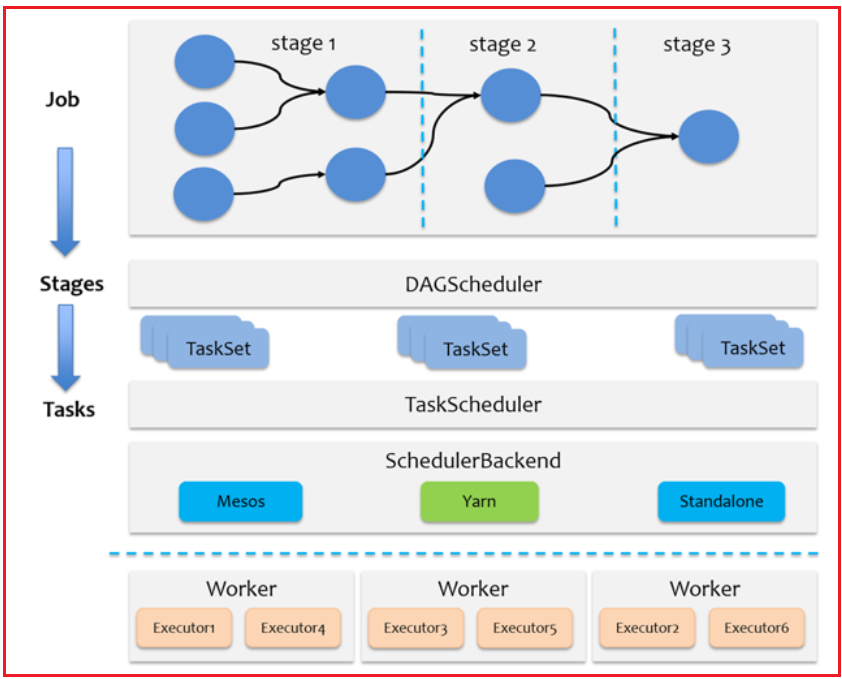
一个Spark应用程序, 可以产生多个JOB任务(有多个action算子),一个job任务产生一个DAG执行流程图, 一个DAG就会有多个stage阶段, 一个stage阶段有多个线程
4.5 Spark的并行度
Spark的并行度是决定Spark执行效率非常重要因素, 一般可以说并行度越高, 执行效率越高 , 前提资源足够
在Spark中并行度主要取决于以下两个因素:
1- 资源因素: 由提交任务时候, 所申请的executor的数量以及CPU核数和内存来决定
2- 数据因素: 数据的大小, 对应分区数量 以及 Task线程
当申请的资源比较大的时候, 如果数据量不大, 这样虽然不会影响执行的效率, 但是会导致资源的浪费
当申请的资源比较小的时候, 但是数据量比较大, 会导致没有相应资源来运行, 本应该可以并行执行的操作, 变成了串行执行,影响整个执行效率
如何调整并行度呢?
调整的标准: 在合适的资源上, 运行合适的任务 产生合适的并行度 除了可以给出一些经验值以外, 更多还需要我们不断的调试'
建议值: 一个CPU核数上运行2~3个线程 一个CPU对应内存大小为 3~5GB
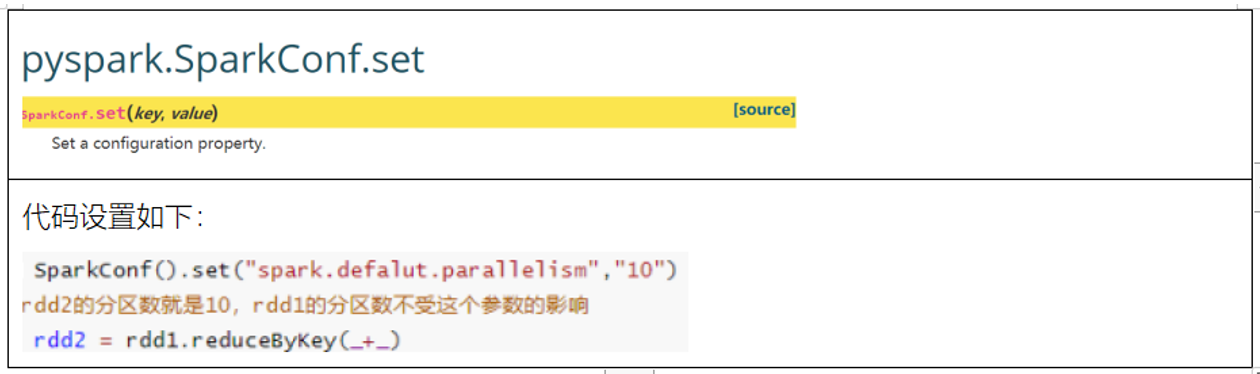
可以通过这个参数设置spark的并行度, 此并行度主要是决定经过shuffle后, 分区的数量
4.6 了解combinerByKey
combinerByKey是一个非常底层的算子, 是 aggregateByKey底层实现:
整体关系:
combinerByKey --> aggregateByKey --> flodByKey --> reduceByKey
使用格式:
combinerByKey(fn1,fn2,fn3)
参数1: fn1 设置初始值
参数2: fn2 对每个分区执行函数
参数3: fn3 对各个分区执行完结果汇总处理
代码演示:
from pyspark import SparkContext, SparkConf
import os
# 锁定远端python版本:
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("combinerByKey演示")
# 1- 创建SparkContext对象
conf = SparkConf().setMaster('local[*]').setAppName('sougou')
sc = SparkContext(conf=conf)
# 2- 初始化数据
rdd_init = sc.parallelize(
[('c01', '张三'), ('c02', '李四'), ('c01', '王五'), ('c01', '赵六'), ('c02', '田七'), ('c03', '周八'), ('c02', '李九')])
# 需求:
"""
要求将数据转换为以下格式:
[
('c01',['张三','王五','赵六'])
('c02',['李四','田七','李九'])
('c03',['周八'])
]
"""
# 3- 处理数据
def fn1(agg):
return [agg]
def fn2(agg, curr):
agg.append(curr)
return agg
def fn3(agg, curr):
print(agg)
agg.extend(curr)
return agg
rdd_res = rdd_init.combineByKey(fn1, fn2, fn3)
print(rdd_res.collect())

若有收获,就点个赞吧
0 人点赞
