1. pandas的基本介绍
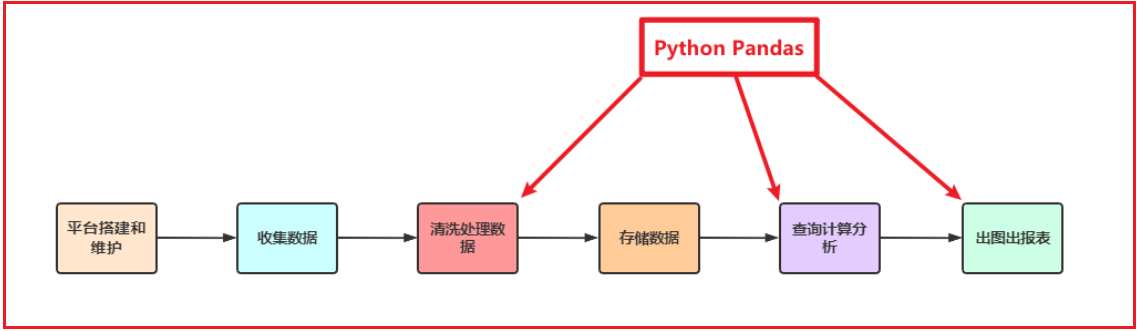
Python在数据处理上独步天下:代码灵活、开发快速;尤其是Python的Pandas包,无论是在数据分析领域、还是大数据开发场景中都具有显著的优势:
- Pandas是Python的一个第三方包,也是商业和工程领域最流行的结构化数据工具集,用于数据清洗、处理以及分析
- Pandas和Spark中很多功能都类似,甚至使用方法都是相同的;当我们学会Pandas之后,再学习Spark就更加简单快速
- Pandas在整个数据开发的流程中的应用场景
- 在大数据场景下,数据在流转的过程中,Python Pandas丰富的API能够更加灵活、快速的对数据进行清洗和处理
- Pandas在数据处理上具有独特的优势:
- 底层是基于Numpy构建的,所以运行速度特别的快
- 有专门的处理缺失数据的API
- 强大而灵活的分组、聚合、转换功能
适用场景:
- 数据量大到excel严重卡顿,且又都是单机数据的时候,我们使用pandas
- pandas用于处理单机数据(小数据集(相对于大数据来说))
- 在大数据ETL数据仓库中,对数据进行清洗及处理的环节使用pandas
2. 安装pandas的库
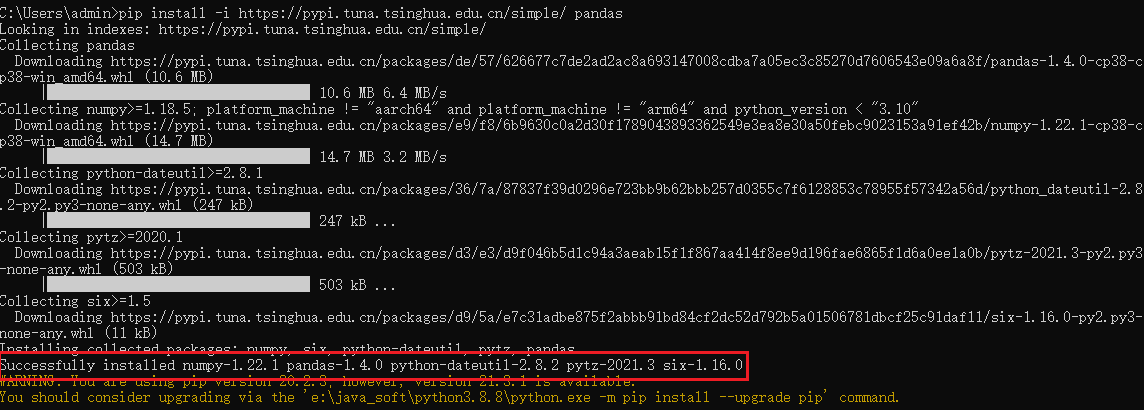
打开cmd界面, 执行 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ pandas
说明:
在安装python环境的时候, 除了基于之前直接安装python解析器方案, 其实安装python还有一些其他的操作,比如说, 我们可以通过anaconda 方式来进行安装,anaconda: 数据科学库包含了python环境, 以及包含了非常多余数据科学相关的库, 全部的集成在了一起, 如果是基于anaconda安装的时候, 很多的数据科学库就不需要自己安装了, anaconda都自带, 其中pandas其实就是anaconda库中一员anaconda提供了虚拟环境方案, 可以在一个操作系统中, 安装不同版本的python环境, 各个环境之间还相对独立
3. pandas的初体验
- 1-将资料中提供的数据集导入到data目录中

- 2- 创建python脚本, 导入pandas库
import pandas as pd
- 3- 基于pandas加载数据
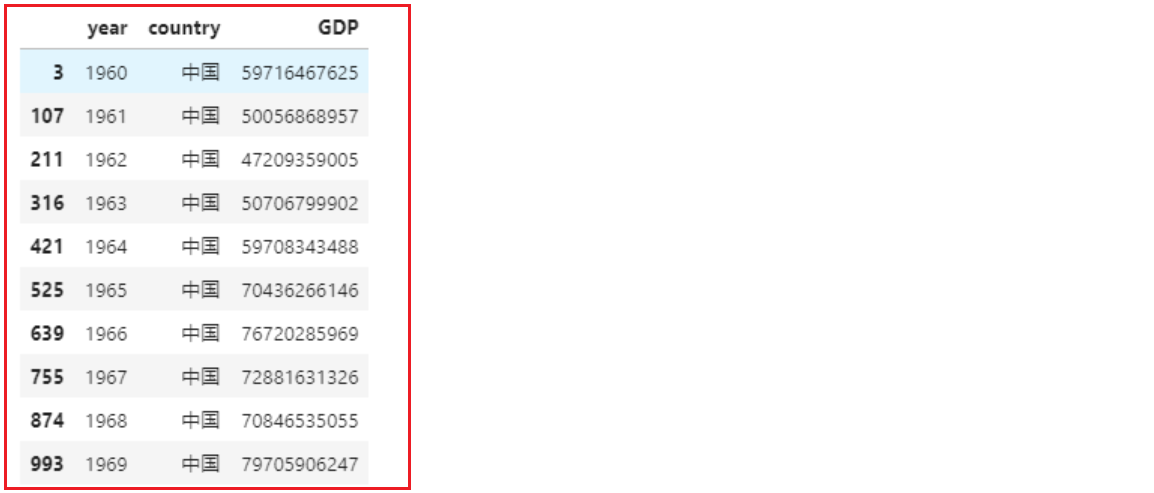
df = pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk', )
- 4- 基于pandas完成相关查询:
# 查询中国的GDPchina_gdp = df[df.country=='中国'] # df.country 选中名为country的列china_gdp.head(10) # 显示前10条数据
4. pandas的数据结构
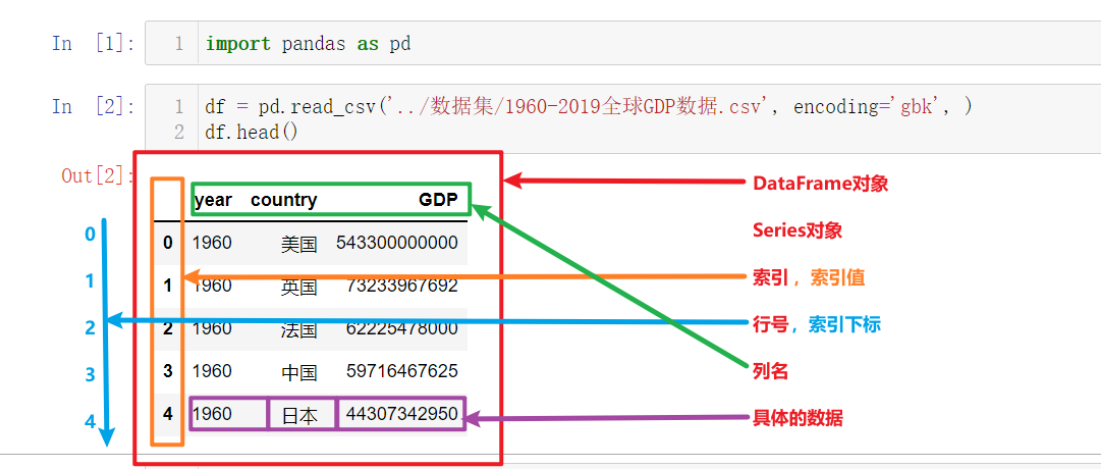
上图为上一节中读取并展示出来的数据,以此为例我们来讲解Pandas的核心概念,以及这些概念的层级关系:
- DataFrame
- Series
- 索引列
- 索引名、索引值
- 索引下标、行号
- 数据列
- 列名
- 列值,具体的数据
- 索引列
- Series
其中最核心的就是Pandas中的两个数据结构:DataFrame和Series
4.1 series对象
Series也是Pandas中的最基本的数据结构对象,下文中简称s对象;是DataFrame的列对象,series本身也具有索引。
Series是一种类似于一维数组的对象,由下面两个部分组成:
- values:一组数据(numpy.ndarray类型)
- index:相关的数据索引标签;如果没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引。
4.1.1 创建Series对象
- 1- 导入pandas
import pandas as pd
- 2- 通过list列表来创建
# 使用默认自增索引s2 = pd.Series([1, 2, 3])print(s2)# 自定义索引s3 = pd.Series([1, 2, 3], index=['A', 'B', 'C']) # series信息和索引信息数量要一致s3结果为:0 11 22 3dtype: int64A 1B 2C 3dtype: int64
- 3- 使用字典或元组创建series对象
#使用元组tst = (1,2,3,4,5,6)pd.Series(tst)#使用字典:dst = {'A':1,'B':2,'C':3,'D':4,'E':5,'F':6}pd.Series(dst)
4.1.2 Series对象常用API
构造一个series对象
s4 = pd.Series([i for i in range(6)], index=[i for i in 'ABCDEF'])s4# 返回结果如下A 0B 1C 2D 3E 4F 5dtype: int64
- 1- series对象常用属性和方法
# s对象有多少个值,intlen(s4)s4.size# s对象有多少个值,单一元素构成的元组 (6,)s4.shape# 查看s对象中数据的类型s4.dtypes# s对象转换为list列表s4.to_list()# s对象的值 array([0, 1, 2, 3, 4, 5], dtype=int64)s4.values# s对象的值转换为列表s4.values.tolist()# s对象可以遍历,返回每一个值for i in s4:print(i)# 下标获取具体值s4[1]# 返回前2个值,默认返回前5个s4.head(2)# 返回最后1个值,默认返回后5个s4.tail(1)# 获取s对象的索引 Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object')s4.index# s对象的索引转换为列表s4.index.to_list()# s对象中数据的基础统计信息s4.describe()# 返回结果及说明如下#count 6.000000 # s对象一共有多少个值#mean 2.500000 # s对象所有值的算术平均值#std 1.870829 # s对象所有值的标准偏差#min 0.000000 # s对象所有值的最小值#25% 1.250000 # 四分位 1/4位点值#50% 2.500000 # 四分位 1/2位点值#75% 3.750000 # 四分位 3/4位点值#max 5.000000 # s对象所有值的最大值#dtype: float64# 标准偏差是一种度量数据分布的分散程度之标准,用以衡量数据值偏离算术平均值的程度。标准偏差越小,这些值偏离平均值就越少,反之亦然。# 四分位数(Quartile)也称四分位点,是指在统计学中把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。# seriest对象转换为df对象s4.to_frame()s4.reset_index()
4.1.3 Series 对象的运算
Series和数值型变量计算时,变量会与Series中的每个元素逐一进行计算两个Series之间计算,索引值相同的元素之间会进行计算;索引不同的元素最终计算的结果会填充成缺失值,用NaN表示
- Series和数值型变量计算
s4 * 5# 返回结果如下A 0B 5C 10D 15E 20F 25dtype: int64
- 索引完全相同的两个Series对象进行计算
s4# 构造与s4索引相同的s对象s5 = pd.Series([10]*6, index=[i for i in 'ABCDEF'])s5# 两个索引相同的s对象进行运算s4 + s5# 返回结果如下A 0B 1C 2D 3E 4F 5dtype: int64A 10B 10C 10D 10E 10F 10dtype: int64A 10B 11C 12D 13E 14F 15dtype: int64
- 索引不同的两个s对象运算
s4# 注意s6的最后一个索引值和s4的最后一个索引值不同s6 = pd.Series([10]*6, index=[i for i in 'ABCDEG'])s6s4 + s6# 返回结果如下A 0B 1C 2D 3E 4F 5dtype: int64A 10B 10C 10D 10E 10G 10dtype: int64A 10.0B 11.0C 12.0D 13.0E 14.0F NaNG NaNdtype: float64
4.2 DataFrame
4.2.1 创建DF对象
DataFrame的创建有很多种方式
- Serires对象转换为df:上一小节中学习了
s.to_frame()以及s.reset_index() - 读取文件数据返回df:在之前的学习中我们使用了
pd.read_csv('csv格式数据文件路径')的方式获取了df对象 - 使用字典、列表、元组创建df:接下来就展示如何使用字段、列表、元组创建df
- 使用字典加列表创建df,使默认自增索引
df1_data = {'日期': ['2021-08-21', '2021-08-22', '2021-08-23'],'温度': [25, 26, 50],'湿度': [81, 50, 56]}df1 = pd.DataFrame(data=df1_data)df1# 返回结果如下日期 温度 湿度0 2021-08-21 25 811 2021-08-22 26 502 2021-08-23 50 56
- 使用列表加元组创建df,并自定义索引
df2_data = [('2021-08-21', 25, 81),('2021-08-22', 26, 50),('2021-08-23', 27, 56)]df2 = pd.DataFrame(data=df2_data,columns=['日期', '温度', '湿度'],index = ['row_1','row_2','row_3'] # 手动指定索引)df2# 返回结果如下日期 温度 湿度row_1 2021-08-21 25 81row_2 2021-08-22 26 50row_3 2021-08-23 27 56
4.2.2 DataFrame对象常用API
- DataFrame对象常用API与Series对象几乎相同
# 返回df的行数len(df2)# df中数据的个数df2.size# df中的行数和列数,元组 (行数, 列数)df2.shape# 返回列名和该列数据的类型df2.dtypes# 返回nparray类型的2维数组,每一行数据作为一维数组,所有行数据的数组再构成一个二维数组df2.values# 返回df的所有列名df2.columns# df遍历返回的只是列名for col_name in df2:print(col_name)# 返回df的索引对象df2.index# 返回第一行数据,默认前5行df2.head(5)# 返回倒数第1行数据,默认倒数5行df2.tail(5)# 返回df的基本信息:索引情况,以及各列的名称、数据数量、数据类型df2.info() # series对象没有info()方法# 返回df对象中所有数字类型数据的基础统计信息# 返回对象的内容和Series.describe()相同df2.describe()# 返回df对象中全部列数据的基础统计信息df2.describe(include='all')
4.2.3 DataFrame对象的运算
当DataFrame和数值进行运算时,DataFrame中的每一个元素会分别和数值进行运算,但df中的数据存在非数值类型时不能做加减法运算两个DataFrame之间、以及df和s对象进行计算,和2个series计算一样,会根据索引的值进行对应计算:当两个对象的索引值不能对应时,不匹配的会返回NaN
- df和数值进行运算
f2 * 2 # 不报错df2 + 1 # 报错,因为df2中有str类型(Object)的数据列
- df和df进行运算
# 索引完全不匹配df1 + df2# 构造部分索引和df2相同的新dfdf3 = df2[df2.index!='row_3']df3# 部分索引相同df2 + df3# 返回结果如下日期 温度 湿度0 NaN NaN NaN1 NaN NaN NaN2 NaN NaN NaNrow_1 NaN NaN NaNrow_2 NaN NaN NaNrow_3 NaN NaN NaN日期 温度 湿度row_1 2021-08-21 25 81row_2 2021-08-22 26 50日期 温度 湿度row_1 2021-08-212021-08-21 50.0 162.0row_2 2021-08-222021-08-22 52.0 100.0row_3 NaN NaN NaN
4.3 pandas的数据类型
- df或s对象中具体每一个值的数据类型有很多,如下表所示 | Pandas数据类型 | 说明 | 对应的Python类型 | | —- | —- | —- | | Object | 字符串类型 | string | | int | 整数类型 | int | | float | 浮点数类型 | float | | datetime | 日期时间类型 | datetime包中的datetime类型 | | timedelta | 时间差类型 | datetime包中的timedelta类型 | | category | 分类类型 | 无原生类型,可以自定义 | | bool | 布尔类型 | True,False | | nan | 空值类型 | None |
- 可以通过下列API查看s对象或df对象中数据的类型
s1.dtypesdf1.dtypesdf1.info() # s对象没有info()方法
5. pandas多格式数据读写
常用读写文件函数清单
| 文件格式 | 读取函数 | 写入函数 |
|---|---|---|
| xlsx | pd.read_excel | df.to_excel |
| xls | pd.read_excel | df.to_excel |
| csv | pd.read_csv | df.to_csv |
| tsv | pd.read_csv | df.to_csv |
| json | pd.read_json | to_json |
| html | pd.read_html | df.to_html |
| sql | pd.read_sql | df.to_sql |
| 剪贴板 | df.read_clipboard | df.to_clipboard |
5.1 写文件
数据准备
# 导包 加载数据集import pandas as pd# 构造df数据集df = pd.DataFrame([['1960-5-7', '刘海柱', '职业法师'],['1978-9-1', '赵金龙', '大力哥'],['1984-12-27', '周立齐', '窃格瓦拉'],['1969-1-24', '于谦', '相声皇后']],columns=['birthday', 'name', 'AKA'])df
- 以写入csv文件为例
df.to_csv('./写文件.csv') # 此时应该在运行代码的相同路径下就生成了一个名为“写文件.csv”的文件
注意:执行`df.to_csv()`时,文件需要关闭才能写入,不然会报 `PermissionError: [Errno 13] Permission denied: 'xxxx.csv'`的异常
5.2 读文件
以读取csv文件为例
df = pd.read_csv('./写文件.csv')df

- index_col 参数指定索引 ``` index_col参数可以在读文件的时候指定列作为返回dataframe的索引,两种用法如下:
- 通过列下标指定为索引
- 通过列名指定为索引 ```
通过列下标指定为索引
index_col=[列下标]df = pd.read_csv('./写文件.csv', index_col=[0])df
通过列名指定为索引
index_col=['列名']df = pd.read_csv('./写文件.csv', index_col=['Unnamed: 0'])df

parse_dates 参数指定列解析为时间日期类型 ```properties parse_dates参数可以在读文件的时候解析时间日期类型的列,两种作用如下:
将指定的列解析为时间日期类型
- 通过列下标解析该列为时间日期类型
- 通过列名解析该列为时间日期类型
- 将df的索引解析为时间日期类型 ```
通过列下标解析该列为时间日期类型
parse_dates=[列下标]pd.read_csv('./写文件.csv').info()pd.read_csv('./写文件.csv', parse_dates=[1]).info()

通过列名解析该列为时间日期类型
parse_dates=[列名]pd.read_csv('./写文件.csv').info()pd.read_csv('./写文件.csv', parse_dates=['birthday']).info()
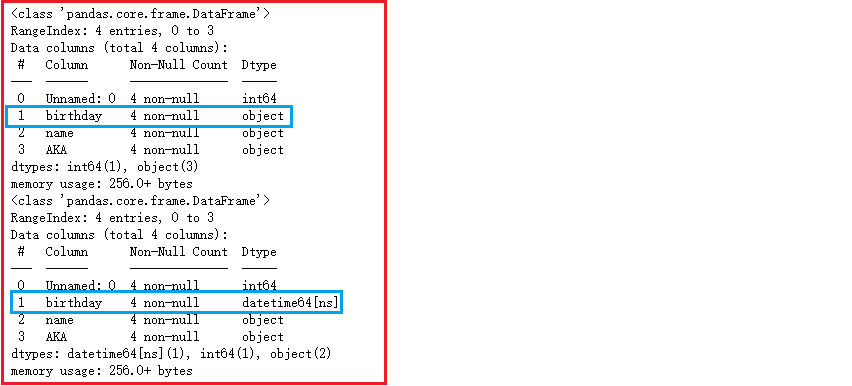
将df的索引解析为时间日期类型
parse_dates=Truedf = pd.read_csv('./写文件.csv', index_col=[1], parse_dates=True)dfdf.index

encoding 参数 指定编码格式
常见的编码格式有:ASCII、GB2312、UTF8、GBK 等pd.read_csv('../数据集/1960-2019全球GDP数据.csv', encoding='gbk').head()

sep参数, 指定字段之间的分隔符号
默认的分隔符号为逗号, 当文件中的字段之间的分隔符号不是逗号的时候, 我们可以采用此参数来调整pd.read_csv('../数据集/csv示例文件.csv', sep='\t', index_col=[0])

5.3 读写数据库
以MySQL数据库为例,**此时默认你已经在本地安装好了MySQL数据库**。如果想利用pandas和MySQL数据库进行交互,需要先安装与数据库交互所需要的python包
pip install pymysql==1.0.2# 如果后边的代码运行提示找不到sqlalchemy的包,和pymysql一样进行安装即可#pip install sqlalchemy==1.4.31

- 准备要写入数据库的数据
import pandas as pddf = pd.read_csv('../数据集/csv示例文件.csv', sep='\t', index_col=[0])df

- 创建数据库操作引擎对象并指定数据库
# 需要安装pymysql,部分版本需要额外安装sqlalchemy# 导入sqlalchemy的数据库引擎from sqlalchemy import create_engine# 创建数据库引擎,传入uri规则的字符串engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')# mysql+pymysql://root:chuanzhi@127.0.0.1:3306/test?charset=utf8# mysql 表示数据库类型# pymysql 表示python操作数据库的包# root:chuanzhi 表示数据库的账号和密码,用冒号连接# 127.0.0.1:3306/test 表示数据库的ip和端口,以及名叫test的数据库# charset=utf8 规定编码格式
- 将数据写入MySQL数据库
# df.to_sql()方法将df数据快速写入数据库df.to_sql('test_pdtosql', engine, index=False, if_exists='append')# 第一个参数为数据表的名称# 第二个参数engine为数据库交互引擎# index=False 表示不添加自增主键# if_exists='append' 表示如果表存在就添加,表不存在就创建表并写入
- 此时我们就可以在本地test库的test_pdtosql表中看到写入的数据

从数据库中加载数据:
读取整张表, 返回dataFrame
# 指定表名,传入数据库连接引擎对象pd.read_sql('test_pdtosql', engine)
使用SQL语句获取数据,返回dataframe
# 传入sql语句,传入数据库连接引擎对象pd.read_sql('select name,AKA from test_pdtosql', engine)

可能出现的问题:

说明:sqlalche 库版本过低导致的解决方案:先删除原有版本:pip uninstall sqlalchemy重新安装:pip install sqlalchemy==1.4.31

若有收获,就点个赞吧
0 人点赞
