导学
Java的输入输出流在我们的日常的使用中,无处不在。只要涉及到数据的传输,比如复制粘贴文件,微信,QQ上传头像,下载游戏安装包等都是在利用输入输出流。再比如我们之前所学习过的System.out.println(),它的作用就是向控制台输出一条信息,也是运用了流的概念。
那么什么是流呢?
流就是指一连串流动的字符,以先进先出的的方式发送信息的通道
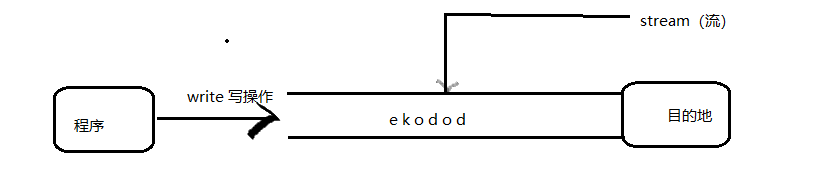
在程序中所有的数据都是以流的方式进行传输或保存的,程序需要数据的时候要使用输入流读取数据,而当程序需要将一些数据保存起来的时候,就要使用输出流完成。
程序中的输入输出都是以流的形式保存的,流中保存的实际上全都是字节文件。
什么是输入输出流
- 流是个抽象的概念,是对输入输出设备的抽象,输入流可以看作一个输入通道,输出流可以看作一个输出通道。
- 输入流是相对程序而言的,外部传入数据给程序需要借助输入流。
- 输出流是相对程序而言的,程序把数据传输到外部需要借助输出流。
在java.io包中操作文件内容的主要有两大类:字节流(二进制数据)、字符流(char和String等类型的文字数据),两类都分为输入和输出操作。在字节流中输出数据主要是使用OutputStream完成,输入使的是InputStream,在字符流中输出主要是使用Writer类完成,输入流主要使用Reader类完成。
File类应用
文件简介
首先,什么是文件?文件可认为是相关记录或放在一起的数据的集合。
在实际的存储数据中,如果对数据的读写速度要求不高,而且存储的数据量也不是很大,此时,可以选择使用文件这种持久化的存储方式。
所谓持久化,就是当程序退出,或者计算机关机以后,数据还是存在的。但是在程序内存中的数据会在程序关闭或计算机退出时丢失。
文件的组成:路径+文件的全名(文件名和文件后缀)。
关于文件后缀:只是定义了文件的打开方式不一样,如果更改后缀不会对文件的内部数据产生变化。
在不同的操作系统中,文件的路径表示形式是不一样的。
比如:windows c:\windows\system\driver.txtLinux /user/my/tomcat/startup.txt
如果程序需要在不同的操作系统中运行,那么如果出现文件路径相关的设置时,必须要进行操作系统的判断,特别是windows和Linux关于斜杠的区别。 针对于不同操作系统的斜杠我们可以使用File类的路径分隔符常量
File.separator
File类应用
java.io.File类是一个与文件本身操作有关的类,此类可以实现文件创建,删除,重命名,取得文件大小,修改日期等常见的系统文件操作File类常用方法:
| 方法 | 描述 |
|---|---|
| canRead() | 文件是否可读 |
| canWrite() | 文件是否可写 |
| exists() | 文件或目录是否存在 |
| getName() | 获取文件或路径的名称 |
| isDirectory() | 是否是目录 |
| isFile() | 是否是文件 |
| isHidden() | 是否是隐藏文件 |
| mkdir() | 是否创建单级目录 |
| mkdirs() | 是否创建多级目录 |
| createNewFile() | 创建文件 |
| isAbsolute() | 是否是绝对路径 |
| getPath() | 获取相对路径 |
| getAbsolutePath() | 获取绝对路径 |
示例:
public class FileDemo {public static void main(String[] args) {//创建File对象//File file1=new File("c:\\dodoke\\io\\score.txt");//File file1=new File("c:\\dodoke","io\\score.txt");//文件和目录分成两个字符串File file=new File("c:\\dodoke");//File.separatorFile file1=new File(file,"io\\score.txt");//判断是文件还是目录System.out.println("是否是目录:"+file1.isDirectory());System.out.println("是否是文件:"+file1.isFile());//创建目录File file2=new File("c:\\dodoke\\set\\HashSet");if(!file2.exists()) {file2.mkdirs();}//创建文件if(!file1.exists()) {try {file1.createNewFile();} catch (IOException e) {e.printStackTrace();}}}}
绝对路径与相对路径
绝对路径
绝对路径:是指文件在硬盘上真正存在的路径。(指对站点的根目录而言某文件的位置)————以web站点为根目录为参考基础的目录路径,之所以成为绝对,意指当所有网页引用同一文件时,所引用的路径都是一样的。
引用本地文件
Windows系统中的文件绝对路径E:\companyWorkSpace\braun\bin\src\main\resources\js\dicList.js当我们想要引入这样本地的一个js文件的时候。写法:<script src="file:///E:/companyWorkSpace/braun/bin/src/main/resources/js/dicList.js"></script>
file:///:本地超文本传输协议
注意点:需要将路径中的反斜杠\改为斜杆/
引用网络文件
写法:<link rel="stylesheet" href="https://cdn.bootcss.com/bootstrap/4.0.0/css/bootstrap.min.css" />
相对路径
相对路径:就是相对于自己的目标文件的位置。(指以当前文件所处目录而言文件的位置)————以引用文件之间网页所在位置为参考基础,而建立出的目录路径。因此当保存于不同目录的网页引用同一个文件时,所使用的路径将不相同,故称之为相对。
相对路径的点与斜杠概念
/、./、../、../../
/这个斜杠代表的是根目录的意思,什么是根目录呢?
先看例子:F盘中有个文件夹vue_bamboos和一张图片 test-me.pngvue_bamboos下有一个文件夹 a , a文件夹中有一个文件夹b;b文件夹下有一个index.html文件;F-------------------------------------------vue_bamboos-------------------------a--------------------------b-----------------index.html-test-me.png-------------------------index.html:显示一张图片test-me.png, 这里我们使用就是根目录,也就是我们项目目录的上一级,也就是 F 盘是我们的根目录;注意,我们的项目目录是vue_bamboos,但是vue_bamboos不是根目录,它的上一级才是!!!<body><img src="/test-me.png" alt="测试根目录"></body>
./这个代表的是当前目录,也就是和我们的index.html 在同一级上
先看例子
假设我们的项目目录:F---------------------------------vue_bamboos---------------index.html------test-me.png-----<body><img src="./test-me.png" alt="测试当前目录"><img src="test-me.png" alt="测试当前目录"></body>也就是说我们可以这样写 ./test-me.png 或者省略 ./ 也是可以的, 直接写 test-me.png
../这个代表的意思是返回到上一级目录;
先看例子假设我们的项目目录:F-------------------------------------vue_bamboos-------------------index.html----------b------------------------------test-me.png---<body><img src="../b/test-me.png" alt="测试父目录"></body>也就是说我们先找到index.html所在的vue_bamoos这个文件夹,再在vue_bamoos文件夹的上级目录F盘中,找到b文件夹,最后找到test-me.png
第四个
../../这个代表的是返回到上一级,再向上返回一级,返回了两级; 第五个../../../这个比上面的多了一级,那么就是向上返回三级了;
eclipse中的相对路径
在eclipse中路径比较特殊,clipse中java程序的当前工作目录都是在项目根目录下的。
字节流
字节输入流InputStream
InputStream是字节输入流的父类,以下是Inputstream的子类结构图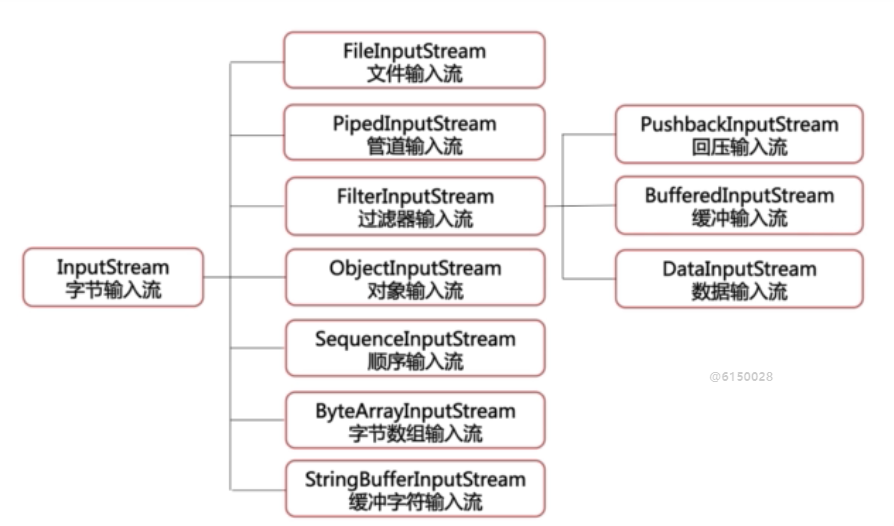
[info]常用的输入流有
FileInputStream,ObjectInputStream,BufferedInputStream
文件输入流FileInp``u``tStream
该类用于从文件系统中的某个文件中获得输入字节,用于读取诸如图像数据之类的原始字节流。
常用方法:
| 方法名 | 描述 |
|---|---|
| public int read() | 从输入流中读取一个数据字节 |
| public int read(byte[] b) | 从输入流中将最多b.length个字节的数据读入到一个byte数组中 |
| public int read(byte[] b,int off,int len) | 从此输入流中将最多len个字节的数据读入一个 byte 数组中。 |
| public void close() | 关闭此文件输入流并释放与此流有关的所有系统资源。 |
除了第一个方法可以得到读取到的下一个数据字节,这三个read()方法,如果返回值为-1,则表示已经到达文件末尾。可以用来作为文件是否读完的一个标志。
import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.IOException;public class FileInputDemo {public static void main(String[] args) {//创建一个FileInputStream对象try {FileInputStream fis = new FileInputStream("d:"+File.separator + "fileTest" + File.separator + "abcNew.txt");//********************无参read()方法使用**********************/*int n = fis.read();System.out.println((char)n);//得到H*//*int n = fis.read();while(n != -1) {System.out.println((char)n);n = fis.read();}*///为了提升代码的简洁性/*int n = 0;while((n = fis.read()) != -1) {System.out.println((char)n);}*///*******************read(byte[] b)和read(byte[] b,int off,int len)方法的使用*****************/*byte[] b = new byte[100];fis.read(b);System.out.println(new String(b));*/byte[] b = new byte[100];fis.read(b,0,5);System.out.println(new String(b));fis.close();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}}
字节输出流OutputStream
OutputStream是字节输出流的父类,以下是Outputstream的子类结构图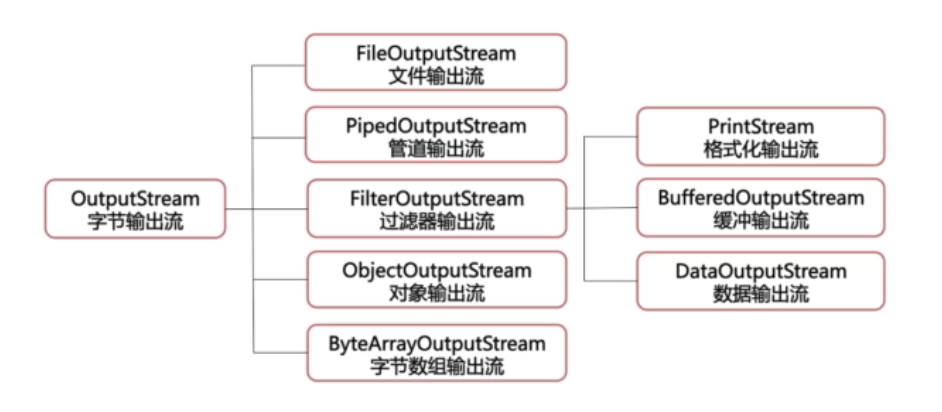
常用的输入流有
FileOutputStream,ObjectOutputStream,BufferedOutputStream
文件输出流FileOutputStream
该类用来讲数据写入到文件系统的文件中
常用方法:
| 方法名 | 描述 |
|---|---|
| public void write(int b) | 将指定字节写入此文件输出流。 |
| public void write(byte[] b) | 将b.length个字节从指定 byte 数组写入此文件输出流中。 |
| public void write(byte[] b,int off,int len) | 将指定 byte 数组中从偏移量off开始的len个字节写入此文件输出流。 |
| public void close() | 关闭此文件输出流并释放与此流有关的所有系统资源。 |
import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;public class FileOutputDemo {public static void main(String[] args) {String path = "d:"+File.separator + "fileTest" + File.separator + "abcNew.txt";FileOutputStream fos;FileInputStream fis;try {fos = new FileOutputStream(path,true);fis = new FileInputStream(path);/*fos.write(50);fos.write('e');//编码问题导致System.out.println(fis.read());System.out.println((char)fis.read());*/String content = "\nsay Hello World again!";fos.write(content.getBytes());fos.close();fis.close();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}}
文件拷贝
import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;public class FileOutputDemo {public static void main(String[] args) {String path = "d:"+File.separator + "picture" + File.separator + "20170315inHome.jpg";String copyPath = "d:"+File.separator + "fileTest" + File.separator + "flower.jpg";FileInputStream fis;FileOutputStream fos;try {//创建输入流fis = new FileInputStream(path);File file = new File(copyPath);//判断文件的父路径是否存在,如果不存在则新建目录if(!file.getParentFile().exists()) {file.getParentFile().mkdirs();}//创建新文件file.createNewFile();//创建输出流fos = new FileOutputStream(copyPath);int n = 0;byte[] b = new byte[1024];while((n = fis.read(b)) != -1) {//一边读取输入流,一边写入到新建的文件中去//fos.write(b);//为了保证最后复制文件和源文件同样大小fos.write(b, 0, n);}fos.close();fis.close();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}}
缓冲流
- 缓冲输入流
BufferedInputStream - 缓冲输出流
BufferedOutputStream
相较于之前直接从硬盘中读取数据,利用缓冲输入输出流,可以从内存中读取数据,可以极大的提高读写速度。
以缓冲输入流为例,它是不能直接读取文件系统中的文件的,需要和文件输入流结合。读取原理是,文件输入流首先从文件系统中读取数据,读取到数据后不是直接到程序中,而是给缓冲流读取到字节数组中。输出流也是一样。
针对于缓冲输出流,如果缓冲区已满,则执行文件写入操作,如果缓冲区不满需要先执行
flush()方法刷新缓冲区。
import java.io.BufferedInputStream;import java.io.BufferedOutputStream;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;public class BufferedIODemo {public final static String PATH = "d:"+File.separator + "fileTest" + File.separator + "abcNew.txt";public static void main(String[] args) {setBufferedIO();}public static void setBufferedIO() {try {//首先利用文件输出流,执行文件的写操作FileOutputStream fos = new FileOutputStream(PATH);BufferedOutputStream bos = new BufferedOutputStream(fos);//读操作FileInputStream fis = new FileInputStream(PATH);BufferedInputStream bis = new BufferedInputStream(fis);//利用缓冲输出流进行写操作,需要注意的是此时数据是写在缓冲区的,如果缓冲未满,且没有调用flush()方法,则不会写入文件bos.write(50);bos.write('a');//一般会要求同时写flush和closebos.flush();System.out.println(bis.read());System.out.println((char)bis.read());fos.close();//close()方法会释放有关bos的一切资源,所以调用close()方法,也会执行写入操作bos.close();fis.close();bis.close();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}}
字符流
Java提供了字符流便于针对字符串的输出,尤其是针对中文的数据处理,都会采用字符流的形式。
字符输入流Reader
Reader是字符输入流的父类,以下是字符输入流的结构图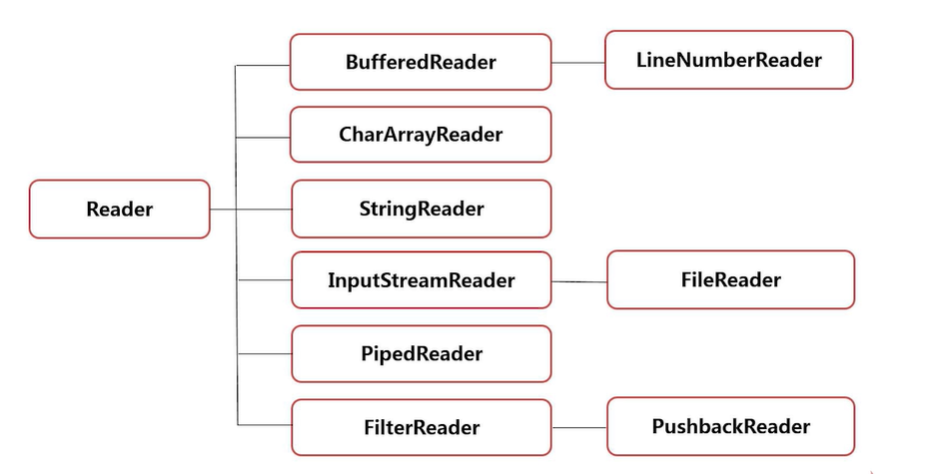
常用的字符输入流有
BufferedReader,InputStreamReader,FileReader
字节字符转换输入流
转换流,可以将一个字节流转换为字符流,也可以将一个字符流转换为字节流。InputStreamReader:将输入的字节流转换为字符流输入形式。
public class ReadDemo {public final static String PATH = "d:"+File.separator + "fileTest" + File.separator + "abcNew.txt";public static void main(String[] args) {FileInputStream fis;InputStreamReader isr;try {fis = new FileInputStream(PATH);//这里其实是一个流的连接isr = new InputStreamReader(fis);int n = 0;/*while((n = isr.read()) != -1) {System.out.println((char)n);}*/char[] charArr = new char[15];while((n = isr.read(charArr)) != -1) {//System.out.println(new String(charArr));//根据操作系统和字符编码的不同,可能最后的读取的效果不经如人意System.out.println(new String(charArr,0,n));}fis.close();isr.close();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}}
字符输出流Writer
Writer是字符输出流的父类,以下是字符输出流的结构图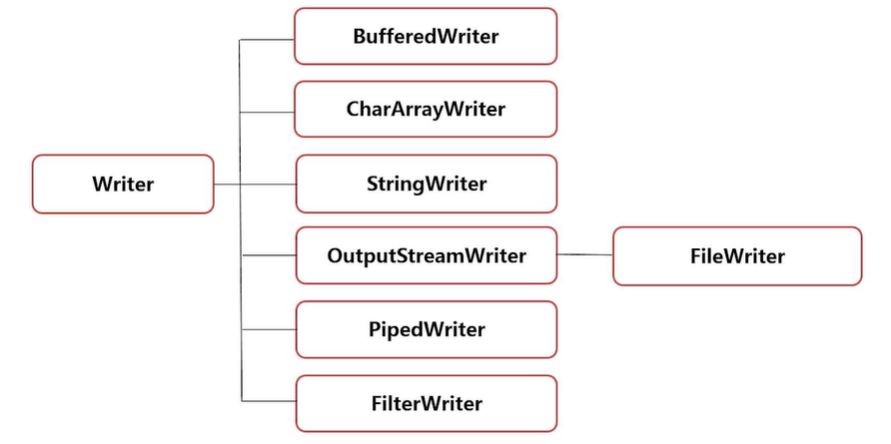
常用的字符输出流有
BufferedWriter,InputStreamWriter,FileWriter
字节字符转换输出流
转换流,可以将一个字节流转换为字符流,也可以将一个字符流转换为字节流。OutputStreamWriter:可以将输出的字符流转换为字节流的输出形式。
public class WriterDemo {public final static String PATH = "d:"+File.separator + "fileTest" + File.separator + "abcNew.txt";public final static String PATH2 = "d:"+File.separator + "fileTest" + File.separator + "abcNew2.txt";public static void main(String[] args) {FileInputStream fis;InputStreamReader isr;FileOutputStream fos;OutputStreamWriter ost;try {fis = new FileInputStream(PATH);isr = new InputStreamReader(fis,"UTF-8");//其实这个文件并没有但是文件输出流会帮我们自动创建一个fos = new FileOutputStream(PATH2);ost = new OutputStreamWriter(fos,"UTF-8");int n = 0;char[] charArr = new char[13];while((n = isr.read(charArr)) != -1) {ost.write(charArr, 0, n);ost.flush();}fis.close();isr.close();fos.close();ost.close();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}}
读写的时候需要保持编码的一致
字节字符转换缓冲流
BufferedReader和BufferedWriter
public class BufferedRWDemo {public final static String PATH = "d:"+File.separator + "fileTest" + File.separator + "abcNew.txt";public final static String PATH2 = "d:"+File.separator + "fileTest" + File.separator + "abcNew2.txt";public static void main(String[] args) {FileInputStream fis;InputStreamReader isr;FileOutputStream fos;OutputStreamWriter ost;try {fis = new FileInputStream(PATH);isr = new InputStreamReader(fis,"UTF-8");//其实与之前的缓冲输入输出流相比,这里出现的是一个三层的连接BufferedReader br = new BufferedReader(isr);//其实这个文件并没有但是文件输出流会帮我们自动创建一个fos = new FileOutputStream(PATH2);ost = new OutputStreamWriter(fos,"UTF-8");BufferedWriter bw = new BufferedWriter(ost);int n = 0;char[] charArr = new char[13];while((n = br.read(charArr)) != -1) {bw.write(charArr, 0, n);bw.flush();}fis.close();isr.close();fos.close();ost.close();br.close();bw.close();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}}
总结
字符流与字节流中的类多种多样,不可能全部讲完,但是各个类的使用大多是大同小异。
在字符流中使用字节流去读写文件,其实只是为了模拟网络文件的读写操作。字符流有着自己的读写文件的类FileReader和FileWriter
对象序列化与反序列化
针对于对象序列化,我们可以设想这样一个场景。比如,我们在同别人聊天的过程中,仅仅是把一条信息发送过去了吗?并不是这样的,发送的信息中可能包含发送方的ip,接收方的ip,以及端口号,聊天内容,昵称等等,那么这些信息如果一条一条的发送过去是没有办法接收的。
所以,我们可以把这些信息封装到一个类中,然后把包含这些信息的对象发送过去,然后接收方就可以根据这些信息作出反应。那么在这个场景中如何去发送对象内容,以及如何去解析对象的内容,就可以通过对象序列化技术解决。
对象序列化的实现步骤:
- 创建一个类,实现Serializable接口(只有当类实现了Serializable接口才能序列化与反序列化)
- 创建该类的对象
- 将对象写入文件(不一定要写入文件,也可以写入网络中)
- 从文件读取对象信息
对象序列化需要借助两个类,
ObjectInputStream()和ObjectOutputStream()序列化:把Java对象转换为字节序列的过程。 反序列化:把字节序列恢复为Java对象的过程。
import java.io.Serializable;public class Goods implements Serializable{private String goodsId;private String goodsName;private double price;public Goods(String goodsId,String goodsName,double price){this.goodsId=goodsId;this.goodsName=goodsName;this.price=price;}public String getGoodsId() {return goodsId;}public void setGoodsId(String goodsId) {this.goodsId = goodsId;}public String getGoodsName() {return goodsName;}public void setGoodsName(String goodsName) {this.goodsName = goodsName;}public double getPrice() {return price;}public void setPrice(double price) {this.price = price;}@Overridepublic String toString() {return "商品信息 [编号:" + goodsId + ", 名称:" + goodsName+ ", 价格:" + price + "]";}}
import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.io.ObjectInputStream;import java.io.ObjectOutputStream;public class GoodsTest {public static void main(String[] args) {// 定义Goods类的对象Goods goods1 = new Goods("gd001", "电脑", 3000);try {FileOutputStream fos = new FileOutputStream("dodoke.txt");ObjectOutputStream oos = new ObjectOutputStream(fos);FileInputStream fis = new FileInputStream("dodoke.txt");ObjectInputStream ois = new ObjectInputStream(fis);// 将Goods对象信息写入文件oos.writeObject(goods1);oos.writeBoolean(true);oos.flush();// 读对象信息try {Goods goods = (Goods) ois.readObject();System.out.println(goods);} catch (ClassNotFoundException e) {e.printStackTrace();}System.out.println(ois.readBoolean());//读取的顺序要和写入的顺序一致fos.close();oos.close();fis.close();ois.close();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}}

若有收获,就点个赞吧
0 人点赞
