
1.事务隔离级别
示例表结构
CREATE TABLE `book` (`id` int(11) NOT NULL AUTO_INCREMENT,`book_type` varchar(4) DEFAULT NULL,`book_name` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
第三个隔离级别叫做:Repeatable Read (可重复读),它解决了不可重复读的问题, 也就是在同一个事务里面多次读取同样的数据结果是一样的,但是在这个级别下,没有 定义解决幻读的问题。
最后一个就是:,在这个隔离级别里面,所有的事务都是串行执行的,也就是对数据的操作需要排队,已经不存在事务的并发操作了,所以它解决了所有的问题。
在实际应用中,读未提交在并发时会导致很多问题,而性能相对于其他隔离级别提高却很有限,因此使用较少。可串行化强制事务串行,并发效率很低,只有当对数据一致性要求极高且可以接受没有并发时使用,因此使用也较少。因此在大多数数据库系统中,默认的隔离级别是读已提交(如Oracle)或可重复读(后文简称RR)

1.Read Uncommitted(未提交读[脏读])
session1:
set session transaction isolation level read uncommitted;SELECT @@session.tx_isolation;SET autocommit = 0;INSERT INTO book(id,book_type,book_name)VALUES(0,"1","中国近代历史");
session2:
set session transaction isolation level read uncommitted;SELECT @@session.tx_isolation;SET autocommit = 0;SELECT * FROM book;
说明:目前session1是没有做事务提交的,此时session2读取是能读取到的,这样就出现脏读了。
2.Read Committed(已提交读[不可重复读])
session1:
set session transaction isolation level read committed;SELECT @@session.tx_isolation;SET autocommit = 0;SELECT * FROM book WHERE id=2;
session1 第一次查询结果:
session2:
set session transaction isolation level read committed;SELECT @@session.tx_isolation;SET autocommit = 0;UPDATE book SET book_name="马克思主义" WHERE id=2
说明:session1读取两次结果不一致,两次读取的结果不一样,这种现象称为不可重复读。脏读与不可重复读的区别在于:前者读到的是其他事务未提交的数据,后者读到的是其他事务已提交的数据。
session1 第二次查询结果:
3.Repeatable Read (可重复读[幻读])
session1:
set session transaction isolation level Repeatable Read;SELECT @@session.tx_isolation;SET autocommit = 0;SELECT * FROM book WHERE id>=1;
session1第一次读取结果:
session2:
set session transaction isolation level Repeatable Read;SELECT @@session.tx_isolation;SET autocommit = 0;-- UPDATE book SET book_name="马克思主义" WHERE id=2;INSERT INTO book(id,book_type,book_name)VALUES(0,"2","数据结构");COMMIT;
session1第二次读取结果:
说明:session1两次读取结果不一致,幻读:在事务A中按照某个条件先后两次查询数据库,两次查询结果的条数不同,这种现象称为幻读。不可重复读与幻读的区别可以通俗的理解为:前者是数据变了,后者是数据的行数变了。
4.Serializable(串行化[解决以上所有问题])
1.解决脏读
session1:
set session transaction isolation level Serializable;SELECT @@session.tx_isolation;SET autocommit = 0;INSERT INTO book(id,book_type,book_name)VALUES(0,"4","算法实践");
seesion2:
set session transaction isolation level Serializable;SELECT @@session.tx_isolation;SET autocommit = 0;SELECT * FROM book;
说明:注意此时session1的事务的没有提交的,session2查询就会等待获取锁,直到超时弹出错误。
[SQL]SELECT * FROM book;[Err] 1205 - Lock wait timeout exceeded; try restarting transaction
2.解决不可重复度
session1:
set session transaction isolation level Serializable;SELECT @@session.tx_isolation;SET autocommit = 0;SELECT * FROM book WHERE id=2;
session2:
set session transaction isolation level Serializable;SELECT @@session.tx_isolation;SET autocommit = 0;SELECT * FROM book;UPDATE book SET book_name="马克思主义" WHERE id=2;COMMIT;
说明:session1读取数据后并没有提交,此时session2对数据进行写入操作就等待锁,直到超时弹出错误。只有session1提交了,session2才能获取锁并完成写入操作。
3.解决幻读
session1:
set session transaction isolation level Serializable;SELECT @@session.tx_isolation;SET autocommit = 0;SELECT * FROM book WHERE id>=1;
session2:
set session transaction isolation level Serializable;SELECT @@session.tx_isolation;SET autocommit = 0;INSERT INTO book(id,book_type,book_name)VALUES(0,"7","躺平");COMMIT;
说明:session1读取数据后并没有提交,此时session2对数据进行写入操作就等待锁,直到超时弹出错误。只有session1提交了,session2才能获取锁并完成写入操作。讲道理2和3还是蛮像的。
5.事务处理
1.rollback
ROLLBACK语句回退START TRANSACTION之后的所有语句
SELECT * FROM book WHERE id=1;START TRANSACTION;DELETE FROM book WHERE id=1;SELECT * FROM book WHERE id=1;ROLLBACK;SELECT * FROM book WHERE id=1;
2.commit
因为涉及更新两个数据库表jnotes_privilege和book,所以使用事务处理块来保证不被部分删除。最后的COMMIT语句仅在不出错时写出更改。如果第一条DELETE起作用,但第二条失败,则DELETE不会提交。这里为了保证例子能成功特地将第二条delete的id改为id1。
START TRANSACTION;SAVEPOINT d1;DELETE FROM jnotes_privilege WHERE id=1;ROLLBACK d1;DELETE FROM book WHERE id1=1;
3.SAVEPOINT
每个保留点都取标识它的唯一名字,以便在回退时,MySQL知道要回退到何处。为了回退到本例给出的保留点,这里为了保证例子能成功特地将第二条delete的id改为id1。
START TRANSACTION;DELETE FROM jnotes_privilege WHERE id=1;DELETE FROM book WHERE id1=1;COMMIT;
4.autocommit
autocommit标志决定是否自动提交更改,不管有没有COMMIT语句。设置autocommit为0(假)指示MySQL不自动提交更改(直到autocommit被设置为真为止)
set autocommit=0;
2.锁的分类
1.share lock(共享锁,行锁)
1.可重复获取锁
# session1SET autocommit = 0;SELECT * FROM book WHERE id=7 LOCK IN SHARE MODE;COMMIT;
# session2SET autocommit = 0;SELECT * FROM book WHERE id=7 LOCK IN SHARE MODE;COMMIT;
2.共享锁操作同一行
# session1SET autocommit = 0;SELECT * FROM book WHERE id=7 LOCK IN SHARE MODE;
# session2SET autocommit = 0;UPDATE book SET book_type="12" WHERE id=7;COMMIT;
说明:session1未提交事务,session2等待获取锁直到超时。
3.共享锁操作不同行
# session1SET autocommit = 0;SELECT * FROM book WHERE id=7 LOCK IN SHARE MODE;
# session2SET autocommit = 0;UPDATE book SET book_type="12" WHERE id=8;COMMIT;
说明:行锁只会针对一行,操作不同行是不会受到印象的,session2可以正常执行不会被陷入等待。
2.Exclusive Locks(排它锁,行锁)
# session1SET autocommit = 0;UPDATE book SET book_type="12" WHERE id=7;
# session2SET autocommit = 0;SELECT * FROM book WHERE id=7;
说明:update delete 都是属于exclusive locks,session1执行后没有提交事务,session2等待获取锁直到超时。
# session1SET autocommit = 0;SELECT * FROM book WHERE id=7 FOR UPDATE;
# session2SET autocommit = 0;UPDATE book SET book_name="hh" WHERE id=7;
说明:查询语句加锁 for update,同样这也属于排它锁,session2等待获取锁直到超时。
3.表锁
1.意向共享锁(IS Lock)
# session1LOCK TABLE book read;SELECT * FROM book WHERE id=7 LOCK IN SHARE MODE;--这行加了S锁,这张表加了IS锁SELECT * FROM book WHERE id=7 FOR UPDATE;--这行加了X锁,这张表加了IX锁
# session2LOCK TABLE book read;SELECT * FROM book WHERE id=7 LOCK IN SHARE MODE;--这行加了S锁,这张表加了IS锁SELECT * FROM book WHERE id=7 FOR UPDATE;--这行加了X锁,这张表加了IX锁
说明:表锁+行锁后这样执行不会阻塞,但是去掉表锁后session2会阻塞。
2.显式上锁
3.索引
4.一些有趣的语法
1.update select
查询的结果作为更新条件
UPDATE jnotes_revenue_2021 j INNER JOIN(SELECT COUNT(user_id) as payNumber,SUM(amount) as totalAmount,pay_time as `time` FROM jnotes_order_2021_08 WHERE order_status=1 and TO_DAYS(pay_time) = TO_DAYS('2021-08-12')) o SET j.pay_number=o.payNumber,j.total_amount=o.totalAmount WHERE j.id=29
2.ON DUPLICATE KEY UPDATE
这个操作会返回影响行数3个结果
- 0:不需要插入也不需要更新
- 1:插入数据
- 2:已有数据进行更新操作
ON DUPLICATE KEY UPDATE使用VALUES可以动态改变值,这个写法主要是避免主键重复
1.插入根据查询的数据作为结果加上ON DUPLICATE KEY UPDATE
INSERT INTO jnotes_order(order_id,amount,pattern_payment,product,order_status,device,model,user_id,transaction_id,pay_time,version,create_time,update_time)SELECT order_id,amount,pattern_payment,product,order_status,device,model,user_id,transaction_id,pay_time,version,create_time,update_timeFROM jnotes_order_2021_08 WHERE order_status=1 ON DUPLICATE KEY UPDATE order_id=VALUES(order_id);
2.ON DUPLICATE KEY UPDATE
还可以参考一下这个链接:https://blog.csdn.net/zyb2017/article/details/78449910
INSERT INTO jnotes_bind_old (user_id, bind_info, bind_type, open_id, `type`)VALUES (#{userId}, #{bindInfo}, #{bindType}, #{openId}, #{type}) ON DUPLICATE KEY UPDATE user_id=#{userId};
5.视图
5.1查看所有视图语法
show table status where comment='view';
5.2视图的创建
# 创建视图存储设备信息CREATE VIEW collection_model(device) ASSELECT device FROM (SELECT * FROM jnotes_order_2021_07 UNION SELECT * FROM jnotes_order_2021_08) collection;# 通过视图查询设备分类 查询作为校验SELECT device FROM collection_model GROUP BY device;
6.存储过程
6.1 局部变量与成员变量赋值
DROP PROCEDURE IF EXISTS test;CREATE PROCEDURE test()BEGIN# 定义局部变量DECLARE flag,page INT;SET flag = 10;SET page = 10;# 定义成员变量SET @number = 0;# 成员变量在select语句中赋值需要@number:= 结果字段# 局部变量在select语句中赋值select 结果字段 into 变量名SELECT @number:=id INTO flag FROM t;SELECT flag,page,@number;END;CALL test();
6.2 循环与if条件
DROP PROCEDURE IF EXISTS test;CREATE PROCEDURE test()BEGINDECLARE i INT DEFAULT 0;WHILE i<10 DOSET i=i+1;# 条件成立就执行 then后面的语句 也就是 select iIF i%2=0 THEN SELECT i;# 不成立执行 SELECT 1ELSESELECT 1;END IF;END WHILE;END;CALL test();
7.日期
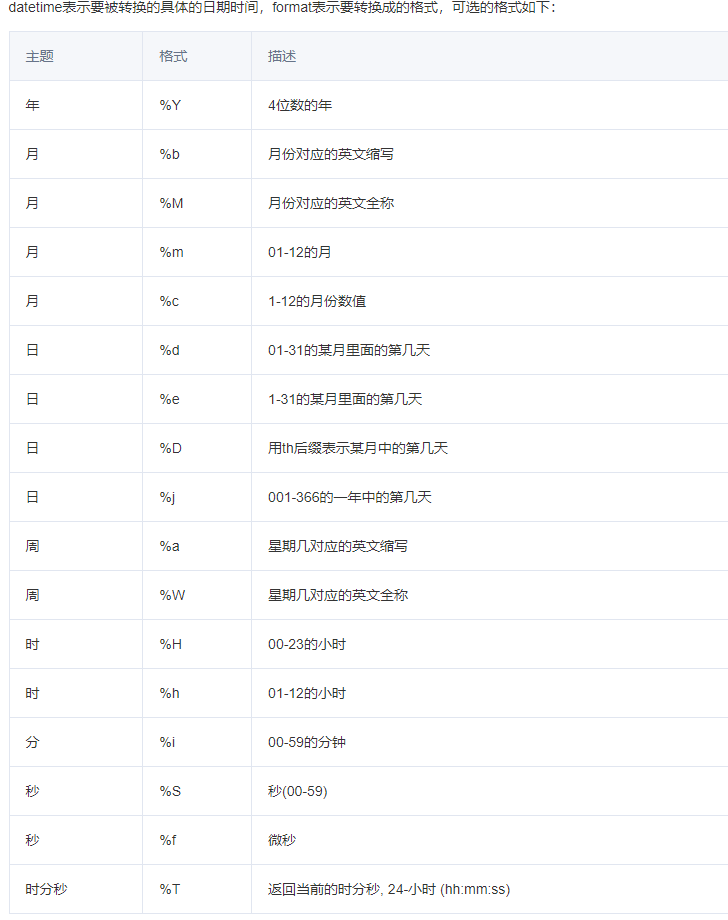
在查询条件中的写法,这种可以精确到时间分秒
# 第一种SELECT * FROM jnotes_order WHERE DATE_FORMAT(create_time,"%Y-%m-%d %H:%i:%S") = "2022-04-14 13:46:04"# 第二种,推荐第二种优雅SELECT * FROM jnotes_order WHERE update_time > "2022-04-20 13:57:00";
时间的加减
# 减少天数select DATE_SUB(CURDATE(),INTERVAL 3 DAY)# 增加天数select DATE_ADD(CURDATE(),INTERVAL 3 DAY)

若有收获,就点个赞吧
0 人点赞
