一、MyBatis VS JPA
JPA:
java持久层API,可以理解为一种规范,Hibernate就是其具体一个实现。(目前比较常用的是SpringDataJpa,它是Spring提供的一套简化开发的框架,按照约定好的方法命名规则,编写dao层接口,就可以在不编写实现情况下执行数据库操作,还提供了除CRUD以外的功能,例如分页、排序、复杂查询等等,SpringDataJpa可以理解为对JPA的再次封装,底层仍旧是Hibernate)
Mybatis优势:
1、SQL语句可以自由控制,更灵活、性能较高。
2、SQL与代码分离,易于阅读和维护。
3、提供XML标签,支持编写动态SQL语句。
JPA优势:
JPA移植性比较好(Hibernate方言)
提供了很多CRUD方法、开发效率高(不用编写sql语句)
对象化程度更高(面向对象开发思想)
Mybatis劣势:
简单CRUD操作需要编写SQL语句(单表仍需要编写Mapper接口方法和xml的sql)
XML中有大量sql需维护
mybatis自身功能有限
二、MyBatis-Plus简介
Mybatis-plus简介:
MyBatis-Plus(简称 MP)是一个Mybatis增强工具,只做增强,不作改变,简化开发,提高效率。
我们的愿景是成为 MyBatis 最好的搭档,就像 魂斗罗 中的 1P、2P,基友搭配,效率翻倍。
MP在mybatis启动的时候,它在mybatis的xml和注解注入之后,紧接着反射分析实体,然后注入到底层容器中。就是注入crud之类的。注入之前MP会进行判断,是否已经注入同样的方法,如果已经注入,就不在注入。它的注入时机在容器启动时,所以MP使用crud、本身是无性能损耗的。
1、Crab:Mybatisplus3.0教学版。(MP核心程序员作品)
2、Crab:WEB极速开发框架。(MP项目负责人作品)
github项目地址:https://github.com/baomidou/mybatis-plus
码云项目地址:https://gitee.com/baomidou/mybatis-plus
Mybatis-plus特点:
1、无侵入:Mybatis-Plus 在 Mybatis 的基础上进行扩展,只做增强不做改变,引入 Mybatis-Plus 不会对您现有的 Mybatis 构架产生任何影响,而且 MP 支持所有 Mybatis 原生的特性
2、依赖少:仅仅依赖 Mybatis 以及 Mybatis-Spring
3、损耗小:启动即会自动注入基本CRUD,性能基本无损耗,直接面向对象操作
4、通用CRUD操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
5、多种主键策略:支持多达4种主键策略(内含分布式唯一ID生成器),可自由配置,完美解决主键问题
6、支持ActiveRecord:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可实现基本 CRUD 操作
7、支持代码生成:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用(P.S. 比 Mybatis 官方的 Generator 更加强大!)
支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
8、内置分页插件:基于Mybatis物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于写基本List查询
9、内置性能分析插件:可输出Sql语句以及其执行时间,建议开发测试时启用该功能,能有效解决慢查询
10、内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,预防误操作
三、入门小案例
步骤:
建库建表===>引入依赖===>配置===>编码===>测试
1.建库建表
create table user ( id BIGINT(20) PRIMARY key not null comment '主键',name varchar(30) default null comment '姓名',age int(11) default null comment '年龄',email varchar(50) default null comment '邮箱');INSERT INTO user (id,name,age,email) VALUES(1,'jone',18,'test1@qq.com'),(2,'Jack',20,'test2@qq.com'),(3,'Tom',28,'test3@qq.com'),(4,'sandy',25,'test4@qq.com'),(5,'hapi',26,'test5@qq.com'),(6,'oiye',27,'test6@qq.com')
2.创建项目
这里我建好了
链接:https://pan.baidu.com/s/1JwIceu5dF-pCOyP8vZprcw
提取码:1234
3.导入依赖
<!-- Lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><!-- Mybatis-Plus启动器 --><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.0.5</version></dependency>
注意:我们使用mybatis-plus 可以节省我们大量的代码,尽量不要同事导入mybatis mybatis-plus
4.配置数据库
application.properties
#mysql 5 驱动不同#spring.datasource.username=root#spring.datasource.password=123456#spring.datasource.url=jdbc:mysql://localhost:3306/mp_text?useSSL=false&useUnicode=true&characterEncoding=UTF-8#spring.datasource.driver-class-name=com.mysql.jdbc.Driver#mysql 8 驱动不同 需要配置时区 serverTimezone=GMT%2B8spring.datasource.username=rootspring.datasource.password=123456spring.datasource.url=jdbc:mysql://localhost:3306/mp_text?useSSL=false&serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=UTF-8spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
5.(传统方式)
pojo-dao(链接mybatis,配置mapper.xml文件)-
service-
controller
6.使用了 mybatis-plus之后
pojo
package com.text.mybatiasplus.pojo;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import org.omg.CosNaming.NamingContextExtPackage.StringNameHelper;@Data@AllArgsConstructor@NoArgsConstructor//@Data 生成getter,setter ,toString等函数//@NoArgsConstructor 生成无参构造函数//@AllArgsConstructor //生成全参数构造函数public class User {private Integer id;private String name;private Integer age;private String email;}
mapper接口
package com.text.mybatiasplus.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;import com.text.mybatiasplus.pojo.User;import org.springframework.stereotype.Repository;//在对应的mapper上面继承基本的接口 BaseMapper@Repositorypublic interface UserMapper extends BaseMapper<User> {//所有的CRUD操作已经编写完成//不需要像以前一样配置一大堆文件}
使用
首先在主接口MybatiasPlusApplication中加入
其次在MybatiasPlusApplicationTests测试
package com.text.mybatiasplus;import com.text.mybatiasplus.mapper.UserMapper;import com.text.mybatiasplus.pojo.User;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import java.util.List;@SpringBootTestclass MybatiasPlusApplicationTests {@Autowiredprivate UserMapper userMapper;@Testvoid contextLoads() {//查询所有的用户 参数是一个Wrapper,条件构造器,这里我们先不用List<User> users = userMapper.selectList(null);for (User user : users) {System.out.println(user);}}}
结果
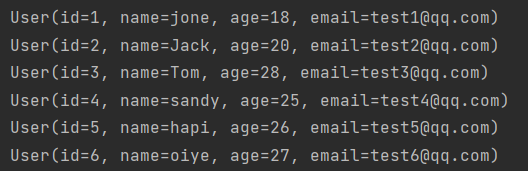
四、思考问题?
1.SQL语句谁帮我们写的?Mybatis-Plus
2.方法哪来的?Mybatis-Plus 写好了 直接使用就可以
五、配置日志
application.properties
# 配置日志 mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
六、CRUD扩展
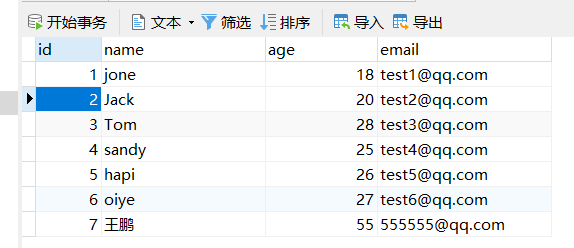
测试插入1(有id)
//测试插入@Testpublic void testInsert(){User u = new User(7,"王鹏",55,"555555@qq.com");userMapper.insert(u);}

测试插入2(无id)
@Testpublic void testInsert(){User u = new User();u.setName("呼呼呼呼");u.setAge(99);u.setEmail("2943198749@qq.com");userMapper.insert(u);}
很明显 报错了:错误是Caused by: org.apache.ibatis.reflection.ReflectionException: Could not set property ‘id’ of ‘class com.text.mybatiasplus.pojo.User’ with value ‘1410970377955766274’ Cause: java.lang.IllegalArgumentException: argument type mismatch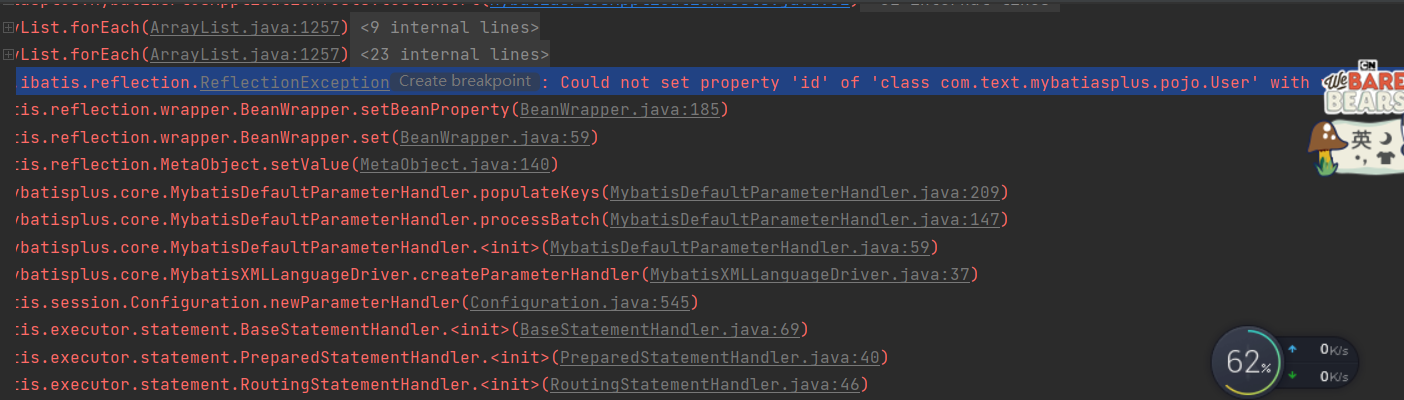
这个错误并不是因为没有id的时候报错 而是mybatis-plus给我们自动生成long型的id为l’1410970377955766274’远远超出了我们数据库设置的int字段长度
我们数据库设计为: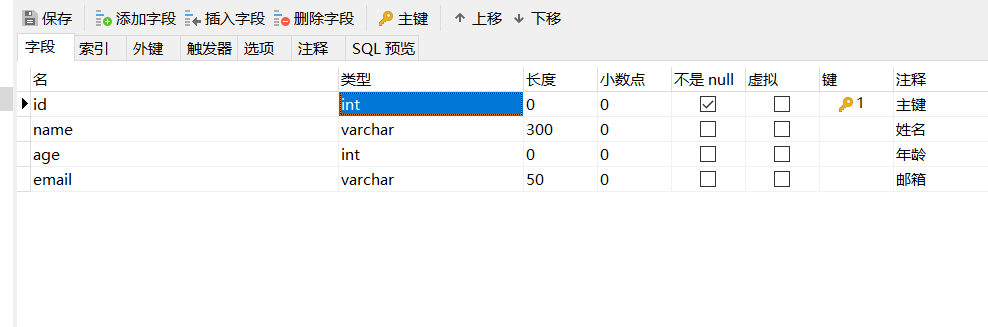
所以他会报错,
解决办法:
在pojo User 类中
private Integer id;改为 private long id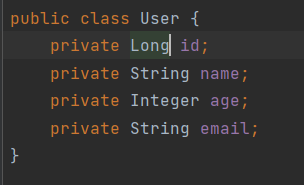
数据库中 int 类型 改为 bigint
主键自增
我们需要配置主键自增
在实体类字段id上加@TableId(type = IdType.AUTO) //主键自增 注意数据库上也需要勾选自增。
package com.text.mybatiasplus.pojo;import com.baomidou.mybatisplus.annotation.IdType;import com.baomidou.mybatisplus.annotation.TableId;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import org.omg.CosNaming.NamingContextExtPackage.StringNameHelper;@Data@AllArgsConstructor@NoArgsConstructor//@Data 生成getter,setter ,toString等函数//@NoArgsConstructor 生成无参构造函数//@AllArgsConstructor //生成全参数构造函数public class User {@TableId(type = IdType.AUTO)private Long id;private String name;private Integer age;private String email;}
@TableId几个参数的含义
public enum IdType {AUTO(0),//数据库id自增NONE(1),//未设置idINPUT(2),//手动输入,需要set id 如果没有 就返回nullID_WORKER(3),//默认的全局idUUID(4),//uuid 全局唯一idID_WORKER_STR(5);//ID_WORKER 字符串表示法
测试更新
我们修改id=1的用户
sql语句:UPDATE user SET age=?, email=? WHERE id=?
注意:参数是一个对象,但是对象中必须要有id
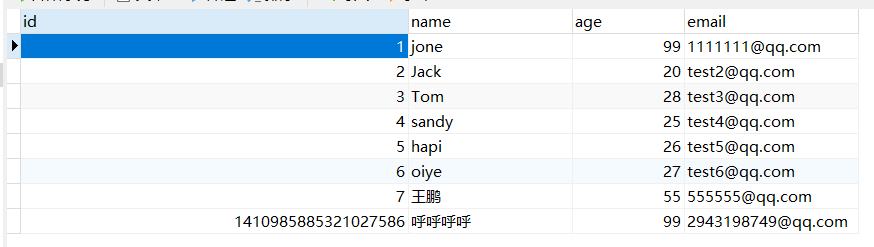
@Testpublic void testUpdate(){User u = new User();u.setId(1L);u.setAge(99);u.setEmail("1111111@qq.com");userMapper.updateById(u);}
自动填充(修改时间等)
创建时间,修改时间!这些个操作一般都是自动化完成的,我们不希望手动更新!
阿里巴巴开发手册:所有的数据库表:gmt_create、gmt_modified、几乎所有表都要创建上 因为我们要去追踪这个数据什么时候被创建,什么时候被修改的! 而且需要自动化
方式一:数据级别(工作中不建议修改数据库)
1.在表中新增字段,create_time,update_time
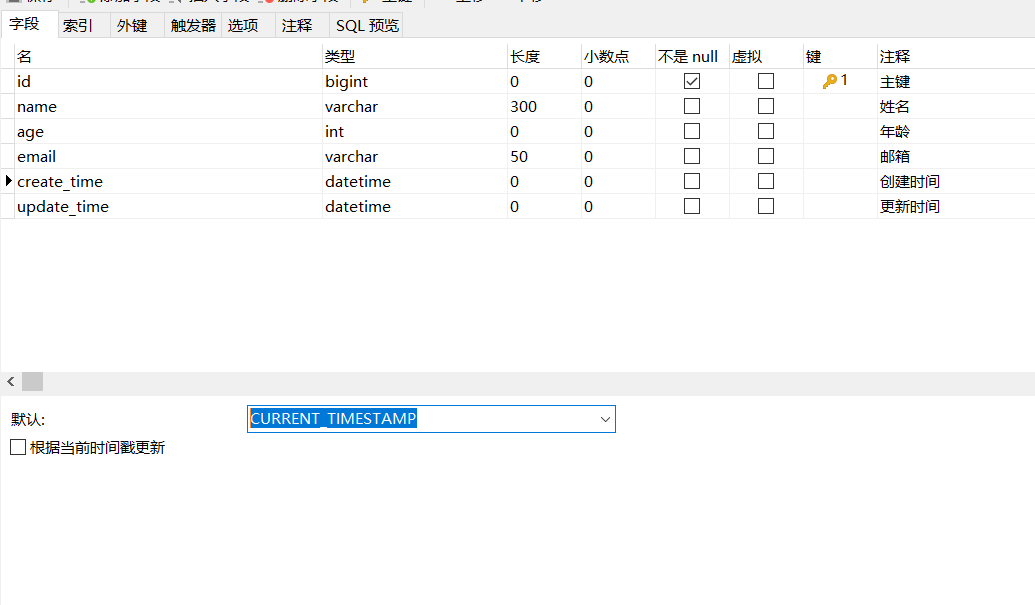
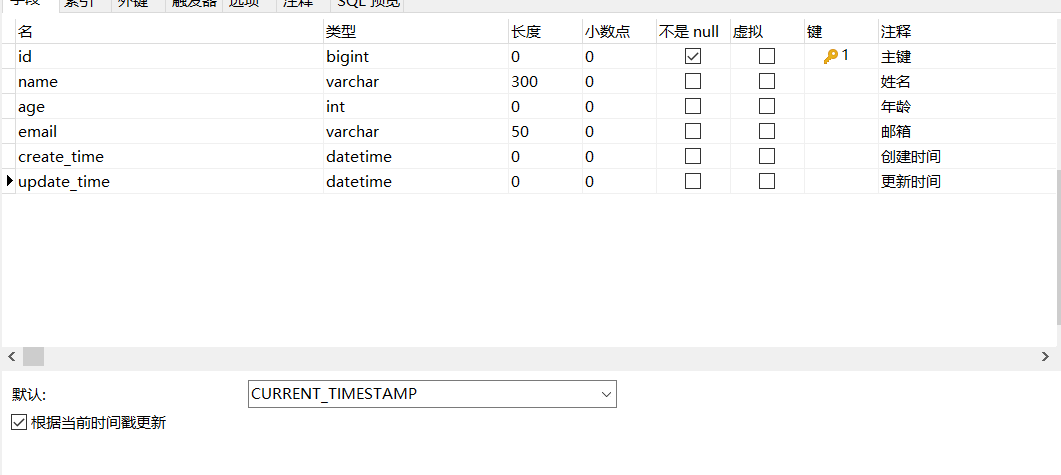
时间默认值:CURRENT_TIMESTAMP
更新需要根据当前时间更新
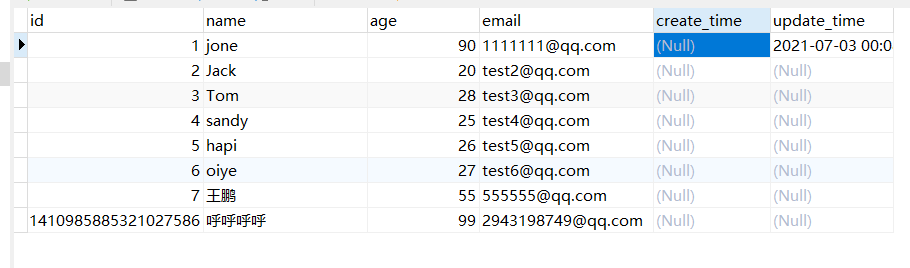
2.再次测试插入方法
同步实体类:
package com.text.mybatiasplus.pojo;import com.baomidou.mybatisplus.annotation.IdType;import com.baomidou.mybatisplus.annotation.TableId;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import org.omg.CosNaming.NamingContextExtPackage.StringNameHelper;import java.util.Date;@Data@AllArgsConstructor@NoArgsConstructor//@Data 生成getter,setter ,toString等函数//@NoArgsConstructor 生成无参构造函数//@AllArgsConstructor //生成全参数构造函数public class User {@TableId(type = IdType.AUTO)private Long id;private String name;private Integer age;private String email;private Date createTime;private Date updateTime;}
方式二:代码级别
1.首先我们将这两个字段的默认值变为null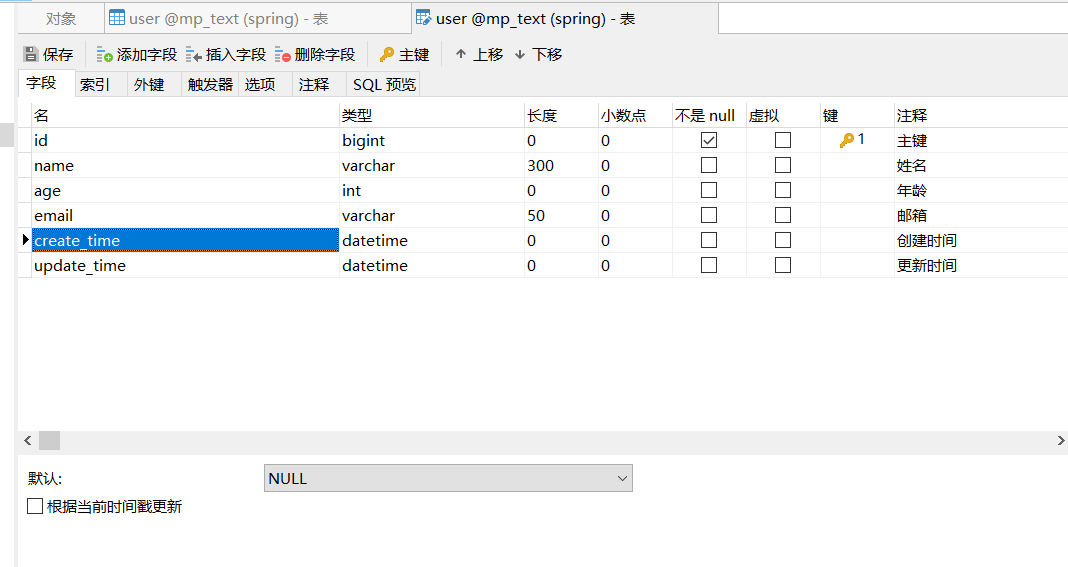
2.实体类字段中加属性
//字段增加填充内容@TableField(fill = FieldFill.INSERT)private Date createTime;@TableField(fill = FieldFill.INSERT_UPDATE)private Date updateTime;
其余的填充策略
public enum FieldFill {DEFAULT,//默认的不操作INSERT,//插入的时候更新UPDATE,//更新的时候操作INSERT_UPDATE;//插入和更新的时候都操作
3.编写处理器来处理注解即可!
新建一个handler包,在handler包中创建MyMetaObjectHandler类
package com.text.mybatiasplus.handler;import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler;import lombok.extern.slf4j.Slf4j;import org.apache.ibatis.reflection.MetaObject;import org.springframework.stereotype.Component;import java.util.Date;@Slf4j //日志@Component //需要被springboot识别 要注入到ioc容器中public class MyMetaObjectHandler implements MetaObjectHandler {//插入时候填充策略@Overridepublic void insertFill(MetaObject metaObject) {//日志log.info("start insert fill.......");//三个参数 第一个:fieldName:想给哪个字段插入值// 第二个:Object fieldVal:想给字段插入什么值// 第三个:MetaObject metaObject:本方法中的metaObjectthis.setFieldValByName("createTime",new Date(),metaObject);this.setFieldValByName("updateTime",new Date(),metaObject);}//更新时候填充策略@Overridepublic void updateFill(MetaObject metaObject) {log.info("start update fill.......");this.setFieldValByName("updateTime",new Date(),metaObject);}}
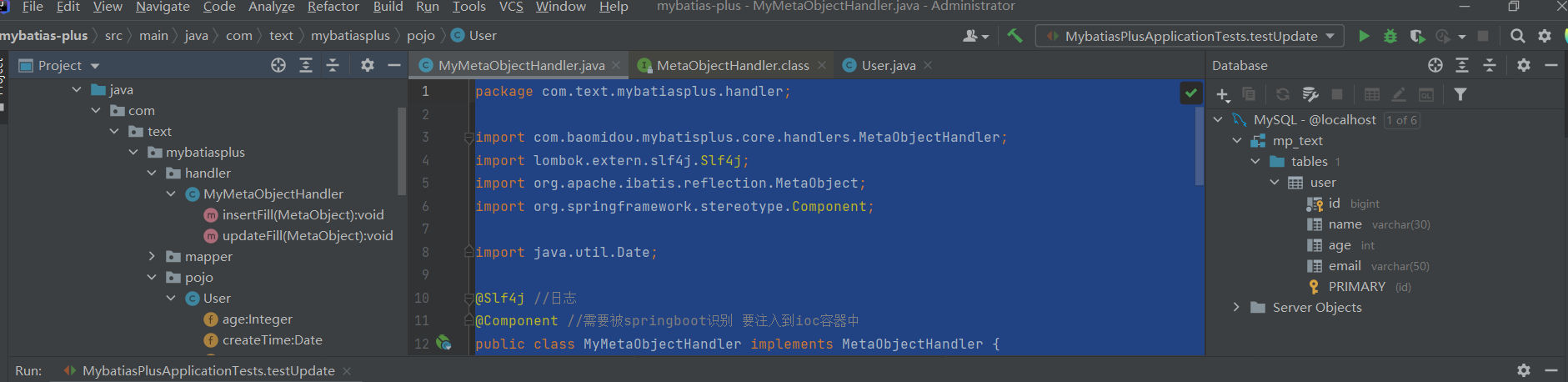
我们测试插入 :
@Testpublic void testInsert(){User u = new User();u.setName("明明就");u.setAge(96);u.setEmail("2943198749@qq.com");userMapper.insert(u);}
可见结果成功
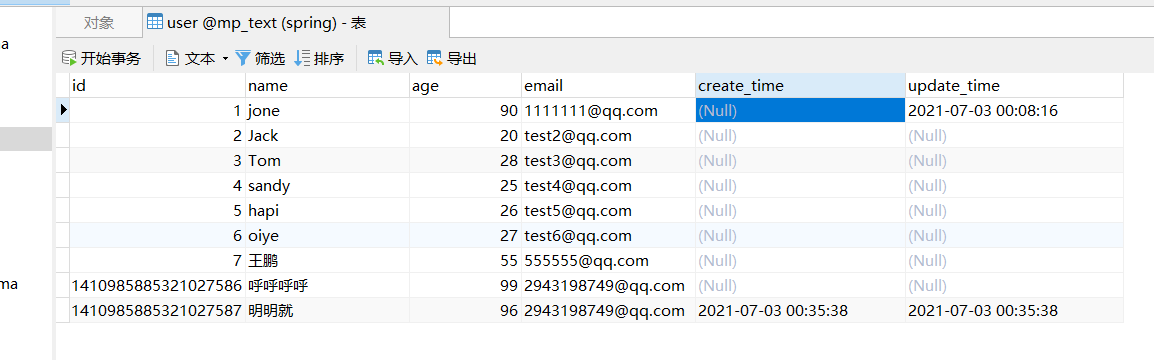
我们测试更新
@Testpublic void testUpdate(){User u = new User();u.setId(1L);u.setAge(75);u.setEmail("11111@qq.com");userMapper.updateById(u);}

乐观锁
在面试过程中,我们经常会被问到乐观锁,悲观锁!
乐观锁:顾名思义 ,十分乐观,总是认为不会出现问题,无论干什么不去上锁。如果出现了问题就再次更新测试
悲观锁:顾名思义,十分悲观,总是认为一直会出现问题,无论干什么都会出现问题,无论干什么都会上锁。再去操作。
乐观锁的实现方式
- 取出记录时,获取当前的version(版本号)
- 更新时,带上这个version
- 执行更新时,set version = newVersion where version = oldVersion
- 如果version不对,就更新失败
1、取出记录时:先查询 获取版本号 version = 1
2、更新的时候 除了id条件外 还加入了version 版本
3、执行更新的时候 要把旧version版本变成新的version版本 也就是version+1
4、如果version不对 就更新失败
通俗点说就是我们现在要修改一个数据: 把user表中的name字段修改成“zhangsan”
此时我们有A B 两条线程
AB同时进行-----Aupdate user set name ="zhangsan" , version = version + 1 where id = 2and version =1-----B B线程抢先完成 ,此时version = 2 会导致A修改失败update user set name ="zhangsan" , version = version + 1 where id = 2and version =1-
这样也能实现我们线程通讯安全 ,给所有的记录加一个version
测试一个MP乐观锁插件
1.给数据库中增加version字段 让他默认值为1
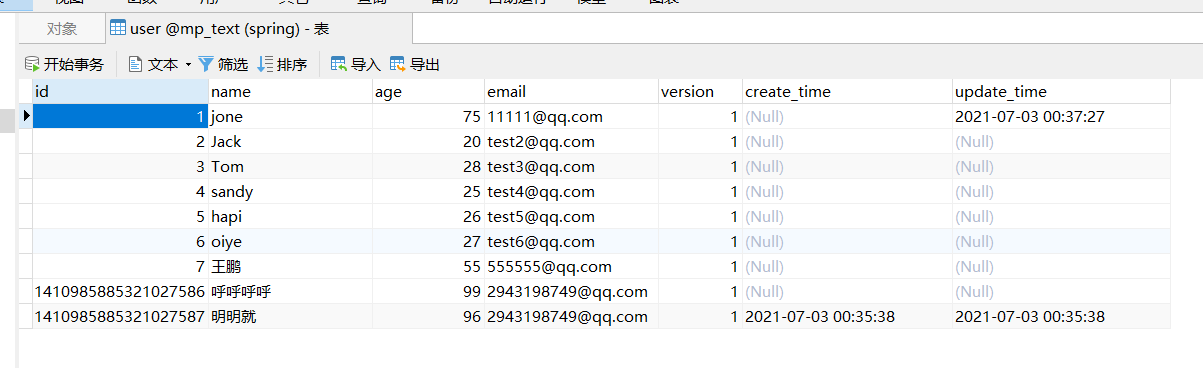
2.实体类加对应的字段
3.在version加入@Version注解
@Version
private Integer version;
4.注册组件
一般我们的配置都在config目录下 并将启动类上的@MapperScan(“com.text.mybatiasplus.mapper”)
并增加注解
@Configuration //配置类@EnableTransactionManagement //自动管理事务
增加到mybatisplusconfig文件里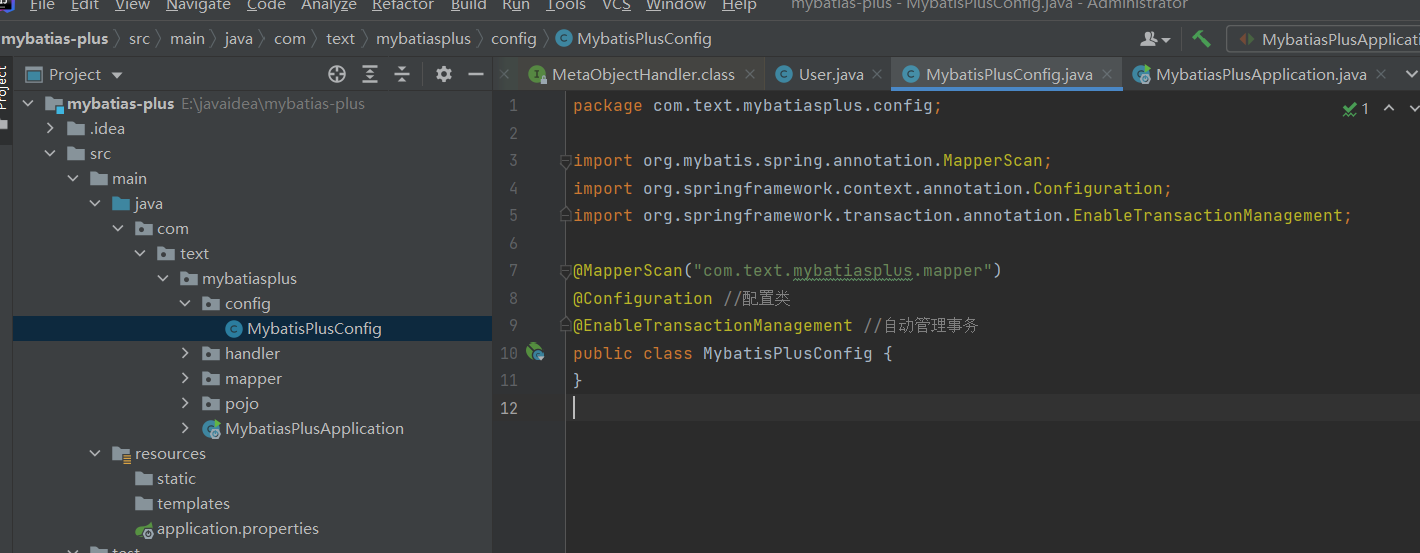
乐观锁只需要加入以下代码就配置完成
@Beanpublic OptimisticLockerInterceptor optimisticLockerInterceptor(){return new OptimisticLockerInterceptor();}
MybatisPlusConfig.java全部代码
package com.text.mybatiasplus.config;import com.baomidou.mybatisplus.extension.plugins.OptimisticLockerInterceptor;import org.mybatis.spring.annotation.MapperScan;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.transaction.annotation.EnableTransactionManagement;@MapperScan("com.text.mybatiasplus.mapper")@Configuration //配置类@EnableTransactionManagement //自动管理事务public class MybatisPlusConfig {//注册乐观锁插件@Beanpublic OptimisticLockerInterceptor optimisticLockerInterceptor(){return new OptimisticLockerInterceptor();}}
5.单线程下测试乐观锁
@Test //单线程环境下测试乐观锁成功public void testLock(){User user = userMapper.selectById(1L);user.setAge(999);user.setEmail("我不会玩@qq.com");userMapper.updateById(user);}


6.多线程下测试乐观锁失败
代码:
@Test //多线程下测试乐观锁失败public void testsLock(){//线程一:User user = userMapper.selectById(1L);user.setAge(66);user.setEmail("我是线程一@qq.com");//线程二: 模拟线程进行了插队操作User user2 = userMapper.selectById(1L);user2.setAge(55);user2.setEmail("我是线程二@qq.com");//线程二首先更新userMapper.updateById(user2);//线程一更新userMapper.updateById(user);}
执行查询的时候可见都执行成功了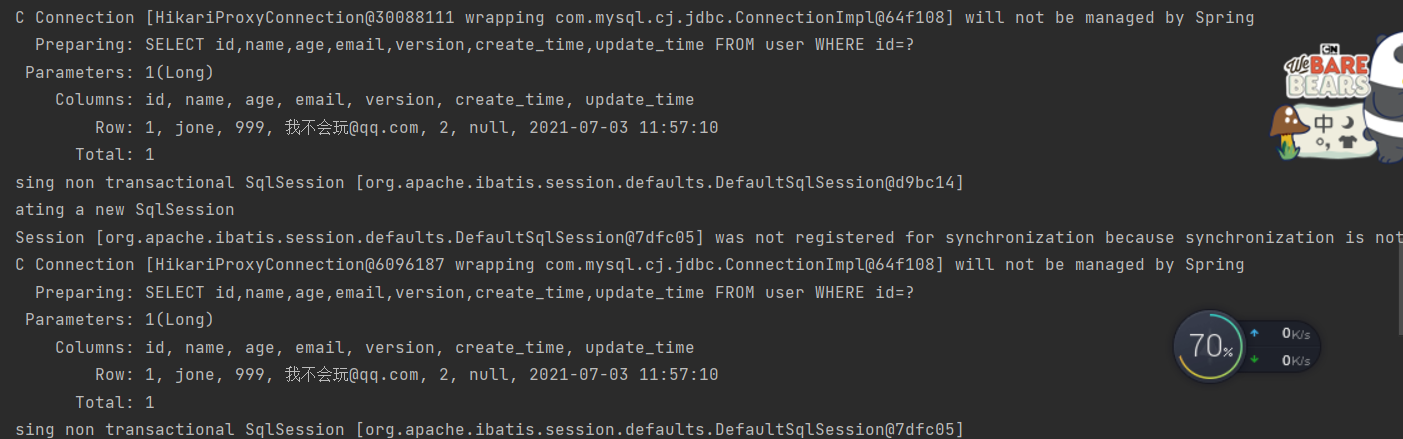
更新的时候因为version字段 只有线程二更新成功,线程一失败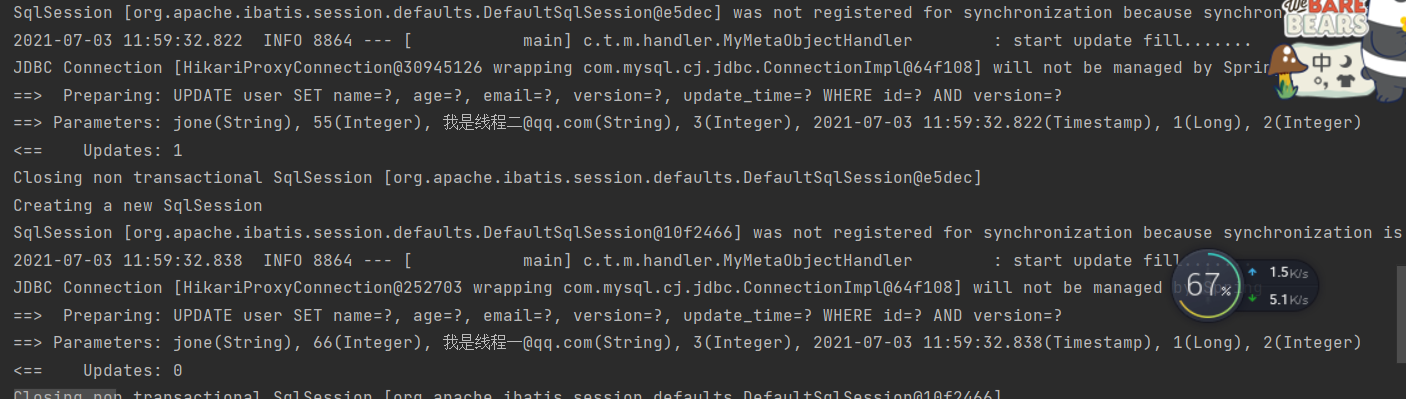
测试查询操作
//查询@Testpublic void testselect() {// 查询单个用户//User user = userMapper.selectById(1L);//System.out.println(user);//查询多个用户// List<User> users = userMapper.selectBatchIds(Arrays.asList(1L, 2L, 3L));// for (User user1 : users) {// System.out.println(user1);// }//条件查询,使用map封装 对应执行的sql//SELECT id,name,age,email,version,create_time,update_time FROM user WHERE name = ? AND id = ?HashMap<String, Object> map = new HashMap<>();//自定义查询 查询name = “jone”的用户map.put("name","jone");//自定义查询 查询id = 1l的用户map.put("id",1L);userMapper.selectByMap(map);}
分页查询
MybatisPlus其实也内置了分页插件
1.在MybatisPlusConfig直接注册分页插件
//注册分页插件@Beanpublic PaginationInterceptor paginationInterceptor(){return new PaginationInterceptor();}
2.使用page对象即可
@Testpublic void testPage(){//current查询第1页,size第一页中有五个数据Page<User> page = new Page<>(1,5);page.getTotal();//查询有多少页userMapper.selectPage(page,null);for (User record : page.getRecords()) {System.out.println(record);}}
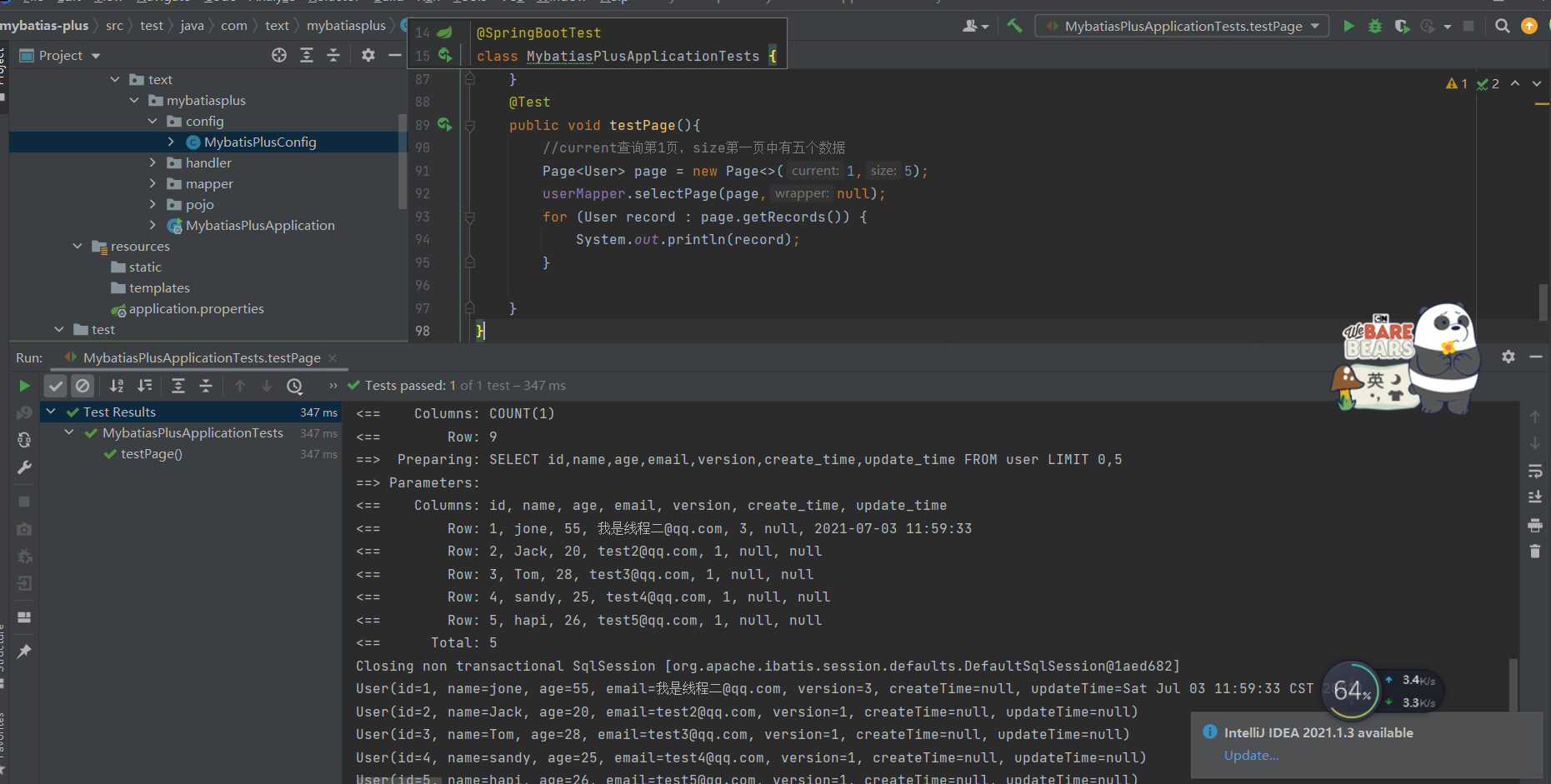
page的其他对象
page.getRecords();//获取分页后的数据page.getPages();//一共多少页page.getTotal();//一共多少数据page.getCurrent();//当前第几页
测试删除
@Testpublic void testDelete(){//通过id批量删除userMapper.deleteById(1L);//批量删除userMapper.deleteBatchIds(Arrays.asList(2,3,4));}
逻辑删除
1.物理删除:从数据库中直接移除
2.逻辑删除:在数据库中没有直接移除,而是通过变量让他失效 失效后查询会查询不到
常见的功能:管理员可以查看被删除的记录!防止数据丢失,类似回收站,如果管理员想删除,我们可以在管理员界面上增加delete删除
3在数据表中增加一个deleted字段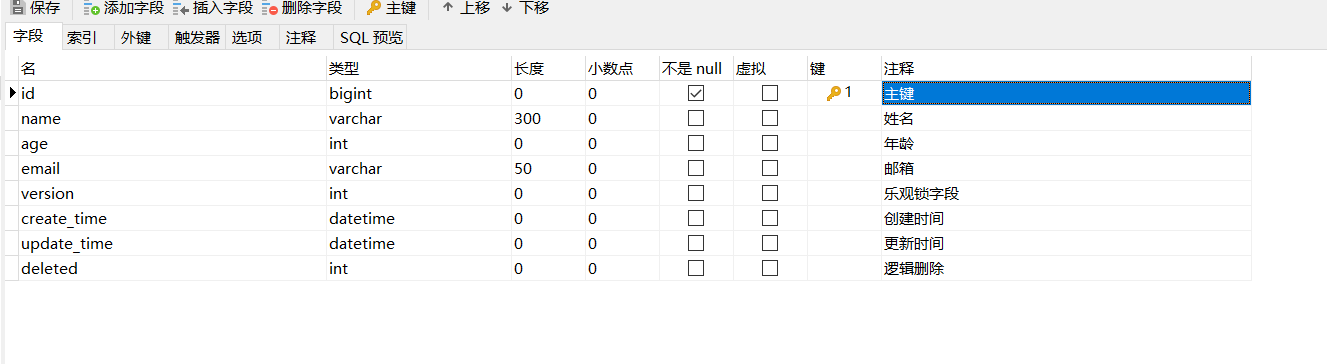
4.在pojo中增加属性
@TableLogic//逻辑删除private Integer deleted;
5.在配置文件中注册逻辑删除组件
//逻辑删除插件@Beanpublic ISqlInjector sqlInjector(){return new LogicSqlInjector();}
6.在application.properties文件中配
置未删除时deleted的值
#配置逻辑删除的值#删除的值为1mybatis-plus.global-config.db-config.logic-delete-value=1#没有删除的值为0mybatis-plus.global-config.db-config.logic-not-delete-value=0
7.当我们配置了逻辑删除后,执行删除语句
@Testpublic void testDelete(){//通过id批量删除userMapper.deleteById(1L);//批量删除userMapper.deleteBatchIds(Arrays.asList(2,3,4));}
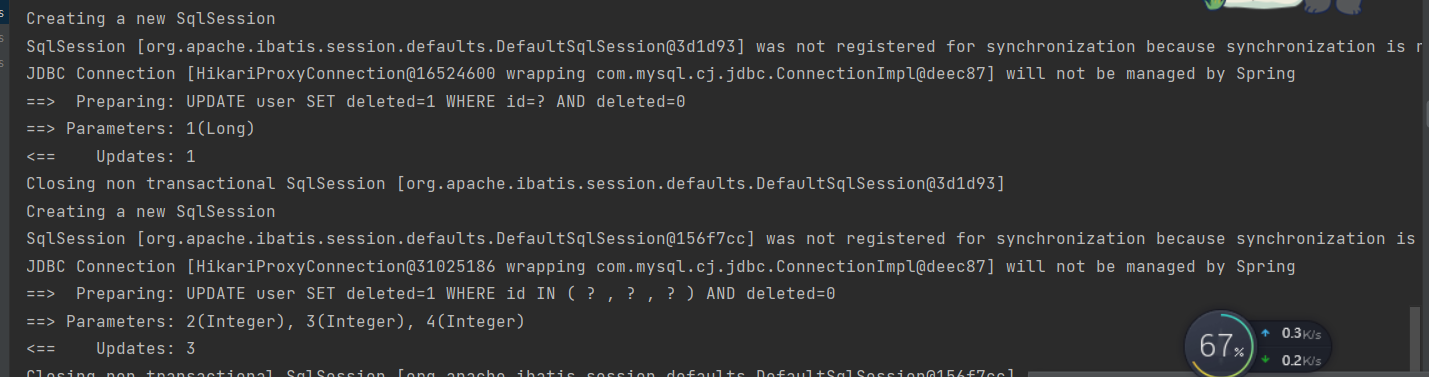
可以看到本质上走得是更新操作,他的deleted字段都从0变成了1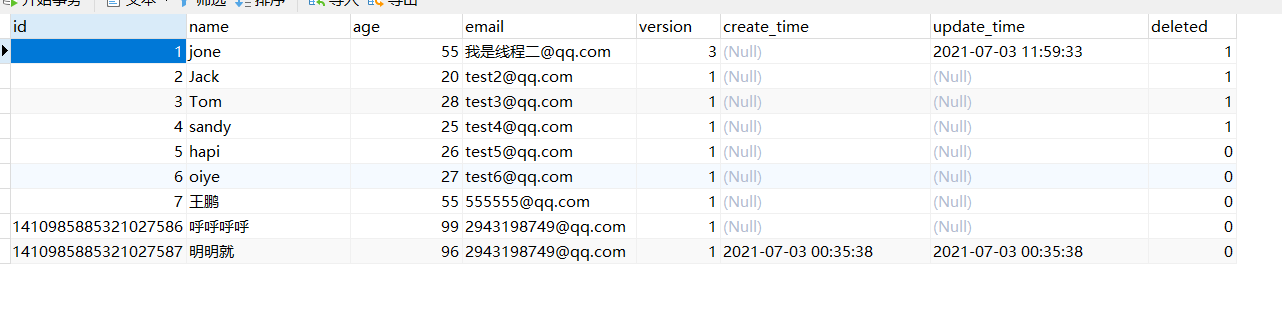
我们现在去执行一下查询语句 查询id为1的用户
我们可以看到,没有 他在后面加了条件deleted =0
七、性能分析插件
我们在平时的开发中,会遇到一些慢sql。我们一般通过一些测试来将慢sql揪出来
mybatisPlus也提供了性能分析插件
作用:性能分析拦截器,用于输出每条sql语句以及其执行时间,如果超出这个时间就停止
1.导入插件
@Bean@Profile({"dev","test"}) //设置dev(开发环境) ,test(测试环境) 环境下使用public PerformanceInterceptor performanceInterceptor(){PerformanceInterceptor performanceInterceptor = new PerformanceInterceptor();performanceInterceptor.setMaxTime(1);//设置sql能够执行的最大时间,单位毫秒 如果超过了就不执行performanceInterceptor.setFormat(true);//是否开格式化支持 //可以让sql语句看到清除return performanceInterceptor;}}
执行语句后我们可以看到 数据可视化
报错 The SQL execution time is too large, please optimize ! 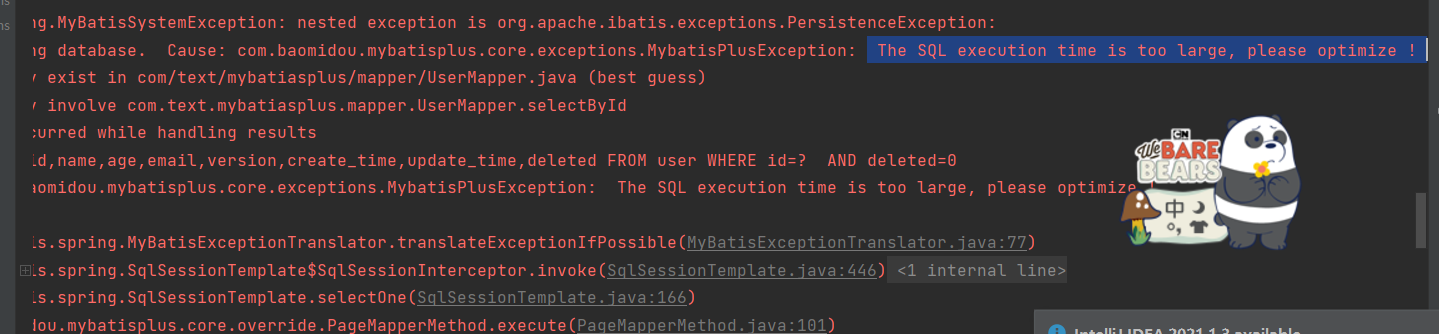
这个sql执行时间超过了1毫秒,请修改sql语句
八、条件构造器
十分重要 Wrapper
我们写一下复杂的sql就可以使用他来替代
官方文档
//条件构造器 测试1@Testpublic void testwapper1(){//查询name不为空的的用户,并且邮箱不为空的用户,年龄大于等于12QueryWrapper<User> wrapper = new QueryWrapper<>();wrapper.isNotNull("name").isNotNull("email").ge("age", 12);List<User> users = userMapper.selectList(wrapper);for (User user : users) {System.out.println(user);}}//测试2@Testpublic void testwapper2(){QueryWrapper<User> user = new QueryWrapper<>();user.eq("name","jone");userMapper.selectOne(user);}//测试3@Testpublic void testwapper3(){QueryWrapper<User> user = new QueryWrapper<>();//查询年龄在80-100岁之间user.between("age",80,100);Integer integer = userMapper.selectCount(user);//查询结果数System.out.println(integer);}//测试4//模糊查询@Testpublic void testwapper4(){QueryWrapper<User> user = new QueryWrapper<>();//查询名字中没有“e” 的人//左和右 notlike 本质就是百分号 %e%//likeLeft 左对应的就是%e//likeRight右对应的就是e%user.notLike("name","e").likeLeft("email","t");List<Map<String, Object>> maps = userMapper.selectMaps(user);}//测试5@Testpublic void testwapper5(){QueryWrapper<User> user = new QueryWrapper<>();//本质where in查询user.inSql("id","select id from user where id<3");List<Object> objects = userMapper.selectObjs(user);for (Object object : objects) {System.out.println(object);}}//测试6//排序@Testpublic void testwapper6(){QueryWrapper<User> user = new QueryWrapper<>();user.orderByDesc("id");//通过id进行排序List<User> users = userMapper.selectList(user);}
(扩展)主键生成策略
因为主键在数据库中都是唯一的,所以我们使用到的策略有(uuid,自增id,雪花算法,redis,zookeeper!)
很明显我们这里使用的“1410970377955766274”是雪花算法
参考博客:
https://www.cnblogs.com/haoxinyue/p/5208136.html
系统唯一ID是我们在设计一个系统的时候常常会遇见的问题,也常常为这个问题而纠结。生成ID的方法有很多,适应不同的场景、需求以及性能要求。所以有些比较复杂的系统会有多个ID生成的策略。下面就介绍一些常见的ID生成策略。
1. 数据库自增长序列或字段
最常见的方式。利用数据库,全数据库唯一。
优点:
1)简单,代码方便,性能可以接受。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理。
2)在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。
3)在性能达不到要求的情况下,比较难于扩展。(不适用于海量高并发)
4)如果遇见多个系统需要合并或者涉及到数据迁移会相当痛苦。
5)分表分库的时候会有麻烦。
6)并非一定连续,类似MySQL,当生成新ID的事务回滚,那么后续的事务也不会再用这个ID了。这个在性能和连续性的折中。如果为了保证连续,必须要在事务结束后才能生成ID,那性能就会出现问题。
7)在分布式数据库中,如果采用了自增主键的话,有可能会带来尾部热点。分布式数据库常常使用range的分区方式,在大量新增记录的时候,IO会集中在一个分区上,造成热点数据。
优化方案:
1)针对主库单点,如果有多个Master库,则每个Master库设置的起始数字不一样,步长一样,可以是Master的个数。比如:Master1 生成的是 1,4,7,10,Master2生成的是2,5,8,11 Master3生成的是 3,6,9,12。这样就可以有效生成集群中的唯一ID,也可以大大降低ID生成数据库操作的负载。
2. UUID
常见的方式。可以利用数据库也可以利用程序生成,一般来说全球唯一。UUID是由32个的16进制数字组成,所以每个UUID的长度是128位(16^32 = 2^128)。UUID作为一种广泛使用标准,有多个实现版本,影响它的因素包括时间、网卡MAC地址、自定义Namesapce等等。
优点:
1)简单,代码方便。
2)生成ID性能非常好,基本不会有性能问题。
3)全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点:
1)没有排序,无法保证趋势递增。
2)UUID往往是使用字符串存储,查询的效率比较低。
3)存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。
4)传输数据量大
5)不可读。
3. UUID的变种
1)为了解决UUID不可读,可以使用UUID to Int64的方法。及
/// <summary>/// 根据GUID获取唯一数字序列/// </summary>public static long GuidToInt64(){byte[] bytes = Guid.NewGuid().ToByteArray();return BitConverter.ToInt64(bytes, 0);}
2)为了解决UUID无序的问题,NHibernate在其主键生成方式中提供了Comb算法(combined guid/timestamp)。保留GUID的10个字节,用另6个字节表示GUID生成的时间(DateTime)。
/// <summary>/// Generate a new <see cref="Guid"/> using the comb algorithm./// </summary>private Guid GenerateComb(){byte[] guidArray = Guid.NewGuid().ToByteArray();DateTime baseDate = new DateTime(1900, 1, 1);DateTime now = DateTime.Now;// Get the days and milliseconds which will be used to build//the byte stringTimeSpan days = new TimeSpan(now.Ticks - baseDate.Ticks);TimeSpan msecs = now.TimeOfDay;// Convert to a byte array// Note that SQL Server is accurate to 1/300th of a// millisecond so we divide by 3.333333byte[] daysArray = BitConverter.GetBytes(days.Days);byte[] msecsArray = BitConverter.GetBytes((long)(msecs.TotalMilliseconds / 3.333333));// Reverse the bytes to match SQL Servers orderingArray.Reverse(daysArray);Array.Reverse(msecsArray);// Copy the bytes into the guidArray.Copy(daysArray, daysArray.Length - 2, guidArray,guidArray.Length - 6, 2);Array.Copy(msecsArray, msecsArray.Length - 4, guidArray,guidArray.Length - 4, 4);return new Guid(guidArray);}
用上面的算法测试一下,得到如下的结果:作为比较,前面3个是使用COMB算法得出的结果,最后12个字符串是时间序(统一毫秒生成的3个UUID),过段时间如果再次生成,则12个字符串会比图示的要大。后面3个是直接生成的GUID。
如果想把时间序放在前面,可以生成后改变12个字符串的位置,也可以修改算法类的最后两个Array.Copy。
4. Redis生成ID
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
这个,随便负载到哪个机确定好,未来很难做修改。但是3-5台服务器基本能够满足器上,都可以获得不同的ID。但是步长和初始值一定需要事先需要了。使用Redis集群也可以方式单点故障的问题。
另外,比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
2)需要编码和配置的工作量比较大。
5. Twitter的snowflake算法(雪花算法)
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。具体实现的代码可以参看https://github.com/twitter/snowflake。雪花算法支持的TPS可以达到419万左右(2^22*1000)。
雪花算法在工程实现上有单机版本和分布式版本。单机版本如下,分布式版本可以参看美团leaf算法:https://github.com/Meituan-Dianping/Leaf
C#代码如下:
/// <summary>/// From: https://github.com/twitter/snowflake/// An object that generates IDs./// This is broken into a separate class in case/// we ever want to support multiple worker threads/// per process/// </summary>public class IdWorker{private long workerId;private long datacenterId;private long sequence = 0L;private static long twepoch = 1288834974657L;private static long workerIdBits = 5L;private static long datacenterIdBits = 5L;private static long maxWorkerId = -1L ^ (-1L << (int)workerIdBits);private static long maxDatacenterId = -1L ^ (-1L << (int)datacenterIdBits);private static long sequenceBits = 12L;private long workerIdShift = sequenceBits;private long datacenterIdShift = sequenceBits + workerIdBits;private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;private long sequenceMask = -1L ^ (-1L << (int)sequenceBits);private long lastTimestamp = -1L;private static object syncRoot = new object();public IdWorker(long workerId, long datacenterId){// sanity check for workerIdif (workerId > maxWorkerId || workerId < 0){throw new ArgumentException(string.Format("worker Id can't be greater than %d or less than 0", maxWorkerId));}if (datacenterId > maxDatacenterId || datacenterId < 0){throw new ArgumentException(string.Format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));}this.workerId = workerId;this.datacenterId = datacenterId;}public long nextId(){lock (syncRoot){long timestamp = timeGen();if (timestamp < lastTimestamp){throw new ApplicationException(string.Format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));}if (lastTimestamp == timestamp){sequence = (sequence + 1) & sequenceMask;if (sequence == 0){timestamp = tilNextMillis(lastTimestamp);}}else{sequence = 0L;}lastTimestamp = timestamp;return ((timestamp - twepoch) << (int)timestampLeftShift) | (datacenterId << (int)datacenterIdShift) | (workerId << (int)workerIdShift) | sequence;}}protected long tilNextMillis(long lastTimestamp){long timestamp = timeGen();while (timestamp <= lastTimestamp){timestamp = timeGen();}return timestamp;}protected long timeGen(){return (long)(DateTime.UtcNow - new DateTime(1970, 1, 1, 0, 0, 0, DateTimeKind.Utc)).TotalMilliseconds;}}
测试代码如下:
private static void TestIdWorker(){HashSet<long> set = new HashSet<long>();IdWorker idWorker1 = new IdWorker(0, 0);IdWorker idWorker2 = new IdWorker(1, 0);Thread t1 = new Thread(() => DoTestIdWoker(idWorker1, set));Thread t2 = new Thread(() => DoTestIdWoker(idWorker2, set));t1.IsBackground = true;t2.IsBackground = true;t1.Start();t2.Start();try{Thread.Sleep(30000);t1.Abort();t2.Abort();}catch (Exception e){}Console.WriteLine("done");}private static void DoTestIdWoker(IdWorker idWorker, HashSet<long> set){while (true){long id = idWorker.nextId();if (!set.Add(id)){Console.WriteLine("duplicate:" + id);}Thread.Sleep(1);}}
snowflake算法可以根据自身项目的需要进行一定的修改。比如估算未来的数据中心个数,每个数据中心的机器数以及统一毫秒可以能的并发数来调整在算法中所需要的bit数。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)ID按照时间在单机上是递增的。
缺点:
1)在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,在算法上要解决时间回拨的问题。
6. 利用zookeeper生成唯一ID
zookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号。
很少会使用zookeeper来生成唯一ID。主要是由于需要依赖zookeeper,并且是多步调用API,如果在竞争较大的情况下,需要考虑使用分布式锁。因此,性能在高并发的分布式环境下,也不甚理想。
7. MongoDB的ObjectId
MongoDB的ObjectId和snowflake算法类似。它设计成轻量型的,不同的机器都能用全局唯一的同种方法方便地生成它。MongoDB 从一开始就设计用来作为分布式数据库,处理多个节点是一个核心要求。使其在分片环境中要容易生成得多。
其格式如下: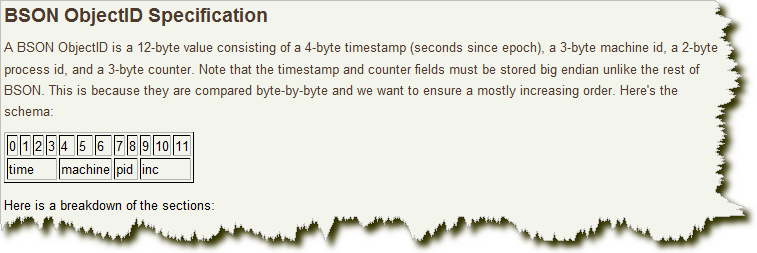
前4 个字节是从标准纪元开始的时间戳,单位为秒。时间戳,与随后的5 个字节组合起来,提供了秒级别的唯一性。由于时间戳在前,这意味着ObjectId 大致会按照插入的顺序排列。这对于某些方面很有用,如将其作为索引提高效率。这4 个字节也隐含了文档创建的时间。绝大多数客户端类库都会公开一个方法从ObjectId 获取这个信息。
接下来的3 字节是所在主机的唯一标识符。通常是机器主机名的散列值。这样就可以确保不同主机生成不同的ObjectId,不产生冲突。
为了确保在同一台机器上并发的多个进程产生的ObjectId 是唯一的,接下来的两字节来自产生ObjectId 的进程标识符(PID)。
前9 字节保证了同一秒钟不同机器不同进程产生的ObjectId 是唯一的。后3 字节就是一个自动增加的计数器,确保相同进程同一秒产生的ObjectId 也是不一样的。同一秒钟最多允许每个进程拥有2563(16 777 216)个不同的ObjectId。
实现的源码可以到MongoDB官方网站下载。
8. TiDB的主键
TiDB默认是支持自增主键的,对未声明主键的表,会提供了一个隐式主键_tidb_rowid,因为这个主键大体上是单调递增的,所以也会出现我们前面说的“尾部热点”问题。
TiDB也提供了UUID函数,而且在4.0版本中还提供了另一种解决方案AutoRandom。TiDB 模仿MySQL的 AutoIncrement,提供了AutoRandom关键字用于生成一个随机ID填充指定列。

若有收获,就点个赞吧
0 人点赞

{kind=link}