document的元数据介绍
创建Document
PUT /my_index/my_type/1{"testContent":"aaaa"}//查询结果"_index" : "my_index","_type" : "my_type","_id" : "1","_score" : 1.0,"_source" : {"testContent" : "aaaa"}
_index
- 标识这个document存入在哪个index中
- 不要将无关紧要的document放入到同一个index中,这样不方便搜索和拆分
- 索引名称小写,不能以下滑线开头,不能包含逗号。
_type
- 标识document属于index的哪个类别。一个index有多个类别。_type在后面的版本被官方废弃掉了,使用“_doc”来代替,如果不写_type那么默认就是_doc。
- 命名规则与索引一样
_id
- document的唯一标识。与index和type一起可以唯一标识一条记录。
- id可以手动指定,也可以自动生成
document的ID生成方式
- 手动指定id
一般来说,从某些系统中导出数据到Es,会采用指定id的这种方式。就是把系统中数据已有的唯一标识作为Es 中document的id。
创建方式:PUT /index/type/id
- 自动生成id
如果要开发一个系统,这个系统主要的存储方式就Es一种。这个时候,就不太适合自己设置id了,因为不知道id是什么。
创建方式:POST /index/type
_source元数据的使用
正常情况下查询,Es会将索引下的所有字段返还。
有些时候,我们可能不需要返还所有字段,就可以使用_source来指定或者排除某些字段。
自定义Es搜索的返还值
没有用_source之前:
"_index" : "human","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "zhagnsan","age" : 1}
用了_source之后。GET /human/_search?_source=name 只要求查询结果返还name字段。
"_index" : "human","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "zhagnsan"}
_source_excludes用来指定排除的字段数组_source_includes用来指定返回的字段数组
document的一些操作
全量替换
PUT /human/_doc/1{"name":"aa","age":23}
当Es中没有id=1时,则会创建一个索引。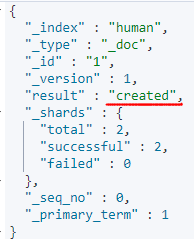
当Es中有Id为1的文档时, 则会更新文档的version。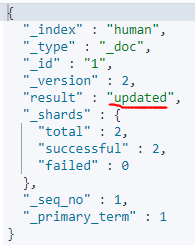
document是不可变的,如果要修改document的内容,可以使用全量替换的方式。Es会将老的document标记为deleted,然后新增一个我们给定的document。当创建的document越来越多时,Es就会自动删除那些标记为deleted的document。
全量替换图示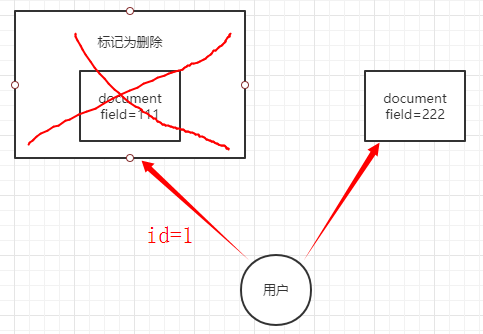
全量替换后的document并没有真正的被物理删除,而是标记为deleted。
强制创建
如果我们只想创建文档而不想替换它,那么我们可以这样做
PUT /human1/_doc/2/_create{"name":"aa","age":23}
在创建文档的后面加_create。如果有id已存在,则抛出 “version conflict, document already exists (current version [1])”的错误。
删除文档DELETE /index/type/id
Es 不会直接物理删除文档。Es先将文档标识为deleted,当数据越来越多的时候,在后头自动删除。
_mget 批量查询document
使用_mget可以减少网络请求开销,提高查询效率。
语法:
GET /_mget{"docs":[{"_index":"索引名称","_id":"id"}]}
需求:批量查询human索引下的文档
GET /_mget{"docs":[{"_index":"human","_id":1}, {"_index":"human","_id":2}]}//查询结果{"docs" : [{"_index" : "human","_type" : "_doc","_id" : "1","_version" : 12,"_seq_no" : 17,"_primary_term" : 2,"found" : true,"_source" : {"field1" : "huangjy","field2" : "zhangsan"}},{"_index" : "human","_type" : "_doc","_id" : "2","_version" : 3,"_seq_no" : 29,"_primary_term" : 2,"found" : true,"_source" : {"script" : "ctx._source.num+=1","upsert" : {"num" : 0,"tags" : [ ]}}}]}
如果都是在同一个索引下查询,也可以写成这样
GET /human/_mget{"ids":[1,2]}//查询结果{"docs" : [{"_index" : "human","_type" : "_doc","_id" : "1","_version" : 12,"_seq_no" : 17,"_primary_term" : 2,"found" : true,"_source" : {"field1" : "huangjy","field2" : "zhangsan"}},{"_index" : "human","_type" : "_doc","_id" : "2","_version" : 3,"_seq_no" : 29,"_primary_term" : 2,"found" : true,"_source" : {"script" : "ctx._source.num+=1","upsert" : {"num" : 0,"tags" : [ ]}}}]}
mget的重要性
mget能大大提高程序的查询性能,减少网络开销,可以将性能提高十倍,甚至数十倍。
_bulk代价较小的批量操作
_bulk是Es提供的一种轻量级的批量操作方法,其操作包含create,update,delete,index。
_bulk请求体格式:
{"action":{metadata}}\n{request body}\n{"action":{metadata}}\n...
格式说明:
- 每一行都要以\n结尾,包括最后一行,换行符作为一个标记,可以有效的分割行(\n也就是换行符)
- 这些行不能包含未转义的换行符,因为他们会对解析造成干扰。
action
- create:创建一个文档(如果不存在,则创建,否则失败)
- index:创建一个文档或替换一个文档
- delete:删除一个文档
- update:更新一个文档
metadata
指定文档的_index,_type,_id。用来定位文档。
创建文档
POST /_bulk{"create":{"_index":"mybulk","_id":"1"}}{"title":"names"}//或者POST /_bulk{"index":{"_index":"mybulk","_id":"1"}}{"title":"names"}
删除文档
POST /_bulk{"delete":{"_index":"mybulk","_id":"1"}}
更新文档
POST /_bulk{"update":{"_index":"mybulk","_id":"1"}}{"doc":{"title":"myname"}}
合并操作
POST /_bulk{"delete":{"_index":"mybulk","_id":1}}{"create":{"_index":"bulkindex","_id":"1"}}{"name":"zhangsan","age":2}{"index":{"_index":"bulkindex","_id":"2"}}{"name":"lisi","age":3}{"update":{"_index":"bulkindex","_id":1}}{"doc":{"name":"wangwu"}}{"update":{"_index":"bulkindex","_id":2}}{"doc":{"age":"10"}}
delete操作后面不能由请求体
操作结果
{"took" : 5875,"errors" : true,"items" : [{"delete" : {"_index" : "mybulk","_type" : "_doc","_id" : "1","_version" : 6,"result" : "deleted","_shards" : {"total" : 2,"successful" : 2,"failed" : 0},"_seq_no" : 5,"_primary_term" : 1,"status" : 200}},{"create" : {"_index" : "bulkindex","_type" : "_doc","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 2,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1,"status" : 201}},{"index" : {"_index" : "builkindex","_type" : "_doc","_id" : "2","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 2,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1,"status" : 201}},{"update" : {"_index" : "bulkindex","_type" : "_doc","_id" : "1","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 2,"failed" : 0},"_seq_no" : 1,"_primary_term" : 1,"status" : 200}},{"update" : {"_index" : "bulkindex","_type" : "_doc","_id" : "2","status" : 404,"error" : {"type" : "document_missing_exception","reason" : "[_doc][2]: document missing","index_uuid" : "yPlsUibdR5SFeKm5CbCkbQ","shard" : "0","index" : "bulkindex"}}}]}
结果会将每一个操作都展示出来,每个子请求都是独立的。某个子请求的失败并不会影响到其他请求。
这也意味着bulk是不能通过事务来控制执行的。
简化请求
POST /bulkindex/_bulk{"delete":{"_id":"2"}}
不用重复指定_index和_type(7.x版本,type可以不用指定,默认为_doc)
_bulk的奇怪格式
为什么bulk的请求格式都单独写一行,而不是发送包装在json数组中的请求,不像mget那样可读?
批量请求中引用的每个文档可能来自于不同的分片,每个分片可能会被分配给集群中的任何节点。这意味着bulk中的每个操作都需要被转发到正确节点上的正确分片。
如果单个请求被包装在json数组中,意味着将要执行如下步骤:
- 将JSON解析为JSONArray数组,这个时候,内存中就出现两份一模一样的数据:一个是json文本,一个是JSONArray对象。
- 解析json数组中的每个json,对每个请求中的json进行路由
- 为路由到同一个shard上的多个请求创建一个请求数组
- 将请求数组序列化为内部传输格式
- 将序列化后的数组发送到对应的分片上去
优缺点
如果不适用bulk的这种格式,会使用大量的内存来存储原本相同的数据副本,并将创建更多的数据结构,jvm也会花费更多的时间来进行垃圾回收。
相反,Elasticsearch可以直接读取被网络缓冲区接收的原始数据。 它使用换行符字符来识别和解析小的 action/metadata 行来决定哪个分片应该处理每个请求。
这些原始请求会被直接转发到正确的分片。没有冗余的数据复制,没有浪费的数据结构。整个请求尽可能在最小的内存中处理。
_
document的路由原理
索引,文档,节点,分片关系图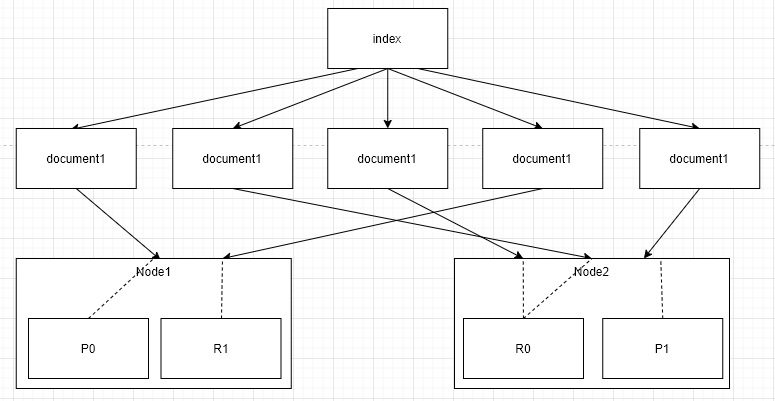
关系描述:
- 一个索引里面有多个文档。
- 一个索引可以被分片成多个shard。
- shard又分为primary shard和replica shard。
- shard存在不同的Node中。
document路由
当客户端创建一个document的时候,Es就将决定把这个document放到哪个index的shard上。这个过程,成为document routing,数据路由。
document路由原理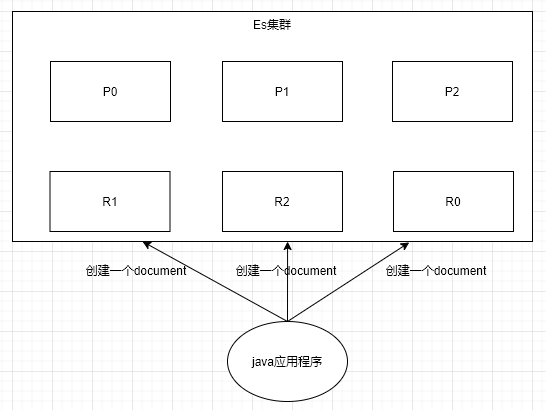
- 路由算法
shard = hash(routing_num) % num_of_primary_shard
routing_num:每次增删查改的时候,都会带过来一个routing_num,默认就是这个document的_id(可以手动指定,也可以自动生成)
num_of_primary_shard:主分片数量
- 路由过程:
- 将routing_num通过hash算法,得到一个值A。
- 将A与主分片数取余数
- 最终得到的值就是document要插入到的那个shard。
- 案例:
现假设,6个shard,3个primary shard 先计算hash值,假设hash(routing_num) = 21 然后拿21%3 = 0,那这个document就会落到P0节点上了
决定一个document落在哪个shard上,是由routing值决定的(默认为_id)。也可以手动指定routing的取值来源,相同的routing值,在hash后,产生的hash值一定是相同的。
为什么primary shard的数量不能修改?
通过上图,我们知道:文档是通过hash算法写入到对应shard中的,那么也需要按照同样的方式获取数据,否则就会数据丢失(其实是查不到数据)
自定义routing值
自定义routing值,可以让某一类document落到一个shard上去,那么在后续进行应用级别的负载均衡以及提升批量读取性能时很有帮助。
案例:
在创建索引的时候,指定routing字段
PUT /mycustom/_doc/1?routing=routing_id{"routing_id":1,"routing_name":"routing2"}PUT /mycustom/_doc/2?routing=routing_id{"routing_id":1,"routing_name":"routing2"}
相同routing值会落到同一个shard上
查看shard中的doc数量:GET /_cat/shards/mycustom?v
文档只会落到一个primary 分片上(主分片会同步到自己的replica 分片上)。
document增删改操作内部原理
原理图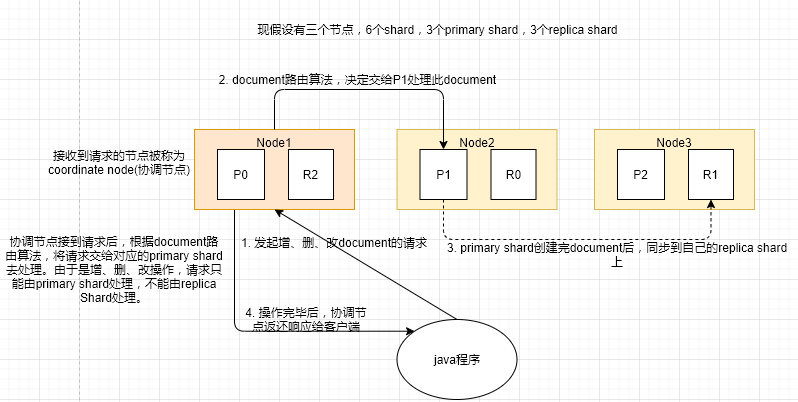
操作流程:
- 客户端程序将增、删、改document的请求随便发送到一个节点上,这个node就被称为coordinate node(协调节点)
- coordinate node会对document进行路由,将请求转发给对应的primary shard。
- primary shard处理完document,将数据发送给replica shard
- coordinate node发现primary shard和replica shard都完成后,就将响应结果返还给客户端
document写一致性原理&quorum机制(5.x废弃掉了)
document写一致性原理指的是在创建document的时候,可以带上一个consistency参数,来标识shard在某种情况下的操作。
one:要求我们这个写操作,只要有一个primary shard是active活跃可用的,就可以执行
all:要求我们这个写操作,必须所有的primary shard和replica shard都是活跃的,才可以执行这个写操作
quorum:默认的值,要求所有的shard中,必须是大部分的shard都是活跃的,可用的,才可以执行这个写操作
目前es已经没有consistency关键字了。
document查询内部原理
查询原理图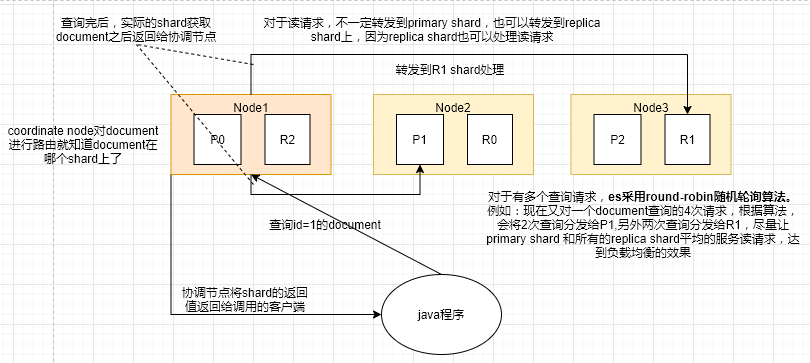
原理流程:
- 客户端发送一个查询请求到任意节点,成为coordinate node
- coordinate node对document进行路由,找到document所在的shard,将请求转发到对应的node。此时使用round-robin算法,在primary shard和replica shard中随机选取一个,作为读请求的负载。
- 接收请求的node将查询到的结果返还给coordinate node。
- coordinate node将查询结果返回给客户端
特殊情况
如果在查询请求到来的时候,document还在创建索引中,可能只有primary shard有,replica shard暂未同步过去,那可能会出现短暂无法读取到document的情况。当document完成建立索引后,primary shard和replica shard就都可以查到了。

若有收获,就点个赞吧
0 人点赞
