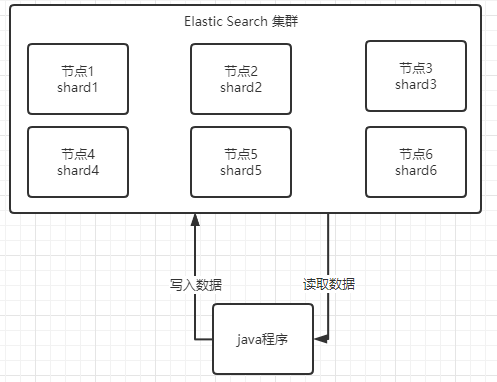
基本架构
- Elastic Search对复杂分布式机制的透明隐藏特性
Elastic Search是一套分布式架构的系统,分布式是为了应对大数据量,隐藏了复杂的分布式机制。
分片机制(shard)
在使用Elastic Search的时候,我们无须关心数据落在哪个分片上。
Cluster集群发现
Elastic Search能自动发现加入到集群中的节点。
Shard负载均衡
Elastic Search对存入的数据进行均衡的读写负载请求。
- Elastic Search的垂直扩容和水平扩容
- 垂直扩容
- 采购更高性能的服务器,以支持现在的业务。特点:成本高昂,服务器性能高
- 水平扩容
- 采购普通的服务器,性能一般,但是很多普通的服务器集群在一起,性能提升。
业界一般采用的是水平扩容的方式。
- Rebalance
在生产中,总有一些服务器的负载会比其他的服务器要高,承受的数据量和请求会更大一些。Elastic Search会重新平衡节点的负载。
- Master节点
通常情况下,master节点不会承载所有的请求,因此不会是一个单点瓶颈。
master节点所做的事情:
- 管理Es集群的元数据,例如:索引的创建与删除,节点的增加与移除。
- 默认情况下,ES会选择一个节点做为master节点。
分片(Shard)
Shard 也叫做分片。Es是分布式搜索引擎,一个索引包含多个Shard。
- 一个Shard就是一个最小的工作单元,承载部分数据,并且拥有完整的建立索引和处理请求的能力。
- 增加节点时,Shard会自动在node中负载均衡
主分片(Primary Shard) & 副本分片(Replica Shard)
分片可分为 Primary Shard(主分片)和Replica Shard(副本分片)。
- 每个document肯定只存在某一个Primary Shard以及对应的的Replica Shard,不可能存在于多个Primary Shard。
- Replica Shard是Primary Shard的副本,负责容错,以及承担请求负载。
- Primary Shard的数量(number_of_shards)在创建索引时已经固定,Replica Shard的数量(number_of_replicas)可以随时修改。
- Primary Shard的默认数量是1,Replica的默认数量是1。
- Primary Shard不能和自己的Replica Shard存放在同一个节点上。可以和其他的primary Shard的replica Shard放一起。
- Primary Shard 与 Replica Shard的数据是一致的。
Replica的作用
- 容灾备份
- 提高查询性能
单Node下,Shard的分配
下图展示了:Es单节点的情况下,shard的分配。
单个node中,由于主,副分片不能存放在一起,因此,只有主分片会被创建。
两个Node下,Shard的分配

其中,P代表Primary Shard,R代表Replica Shard
横向扩容
现有节点2个,Shard 6个,3主,3副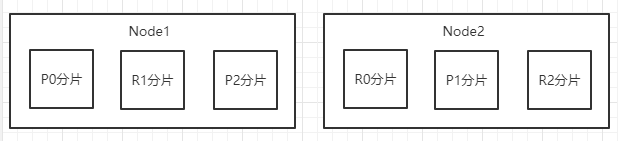
增加了一个节点Node3 ,分片情况如下
横向扩容后,每个shard能获取到更多的IO/CPU资源,性能更好。
超出系统扩容瓶颈
现有节点3个,shard6个,3主,3副
需求:节点增加到9个,Es应该如何扩容?
方法:增加副本数量,将3个副本增加到6个。
3(Primary Shard) + 6(Replica Shard) = 9
容错
现有节点3个,shard6个,3主,3副
需求1:最多允许``多少台服务器失败?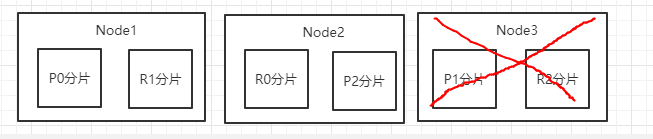
这种情况,最多只能允许一台服务器宕机。Node1和Node2能恢复所有数据。
需求2:将宕机容忍数量增加2台,需要如何配置Shard?
方法:增加副本节点数量到6个,即可最高容忍2台服务器宕机。
宕机->节点选举->恢复
现有节点3个,shard9个,3主,6副
现在Node1宕机了!
宕机:Node1宕机后,P0分片这个Primary shard就丢失了。cluster Status 变成红色。因为不是所有的Primary shard都是active的状态了。

选举:自动选举新的Node作为Master。

将丢失掉的P0的Replica Shard 提升为Primary Shard。cluster Status变为黄色,因为所有的Primary Shard都是active的状态了,但是少了P0的一个Replica Shard,不是所有的Replica Shard都是active。
恢复:重启故障节点,new Master会将缺失的副本都拷贝一份到新的节点上。该node会使用之前的Shard的数据,只是同步一下在宕机时期修改后的数据。cluster Status 变为绿色,因为Primary Shard 和 Replica Shard都齐全了。


若有收获,就点个赞吧
0 人点赞
