_search
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "bulkindex","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "wangwu","age" : 2}}]}}
_search结果分析
took:花费多少ms
_shards:一般来说,每次搜索会打到index的所有primary shard上去,每个primary shard都可能又一个或多个replica shard。因此一次查询也会打到replica shard上。
hits.total:本次搜索返回了几条结果
hits.max_score:本次搜索结果中,最大的相关度是多少。每一条document对于search的相关度,越相关,_score的分数越大,排位越靠前。
hits.hits:默认查询前10条数据,_score降序排序。
termQuery和matchQuery的区别
- termQuery在查询的时候不会去分词,直接匹配字符串
- matchQuery在查询的时候会先去分词然后再匹配字符串。
timeout详解
- timeout机制
在某些搜索场景,用户对搜索的时间很敏感,过长的搜索时间会带来很差的用户反馈。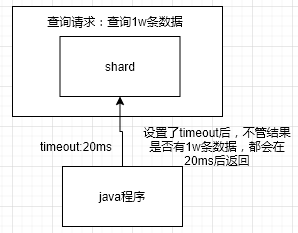
这个时候,我们就需要设置es的timeout,指定shard在timeout时间范围内,将搜索到的部分数据(也可能能搜索到全部的了)直接立即返回给客户端,而不是等所有的数据都查出来再返回。
timeout确保一次请求可以在指定时间内完成,为一些时间敏感的搜索提供良好的支持。
GET /human/_search?timeout=10ms
注意:搜索时,默认是没有timeout的,也就是说直到查询结果全部返回才结束。
分页搜索&deep paging性能问题
分页搜索格式
GET /uat_midea_auth_role_resource/_search?size=2GET /uat_midea_auth_role_resource/_search?from=0&size=10GET /uat_midea_auth_role_resource/_search?from=2&size=2
size:返回查询结果数量,默认是10
from:跳过的初始数量,默认是0
deep paging
深度分页指的是在Es中搜索过深的查询。
分页流程
我们可以假设在一个有 5 个主分片的索引中搜索。 当我们请求结果的第一页(结果从 1 到 10 ),每一个分片产生前 10 的结果,并且返回给 协调节点 ,协调节点对 50 个结果排序得到全部结果的前 10 个。
- deep paging流程图
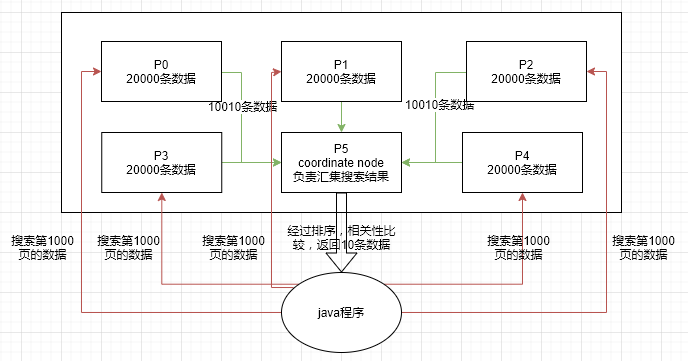
- 案例:
背景:总共有10w条数据,分布在5个shard中,每个shard有2w条数据。
需求:现在需要搜索第1000页的数据。
步骤:Es会获取到每个shard的10001-10010条数据,不是10条,而是10010条数据。每个shard的操作都一样,总共需要拿出50050条数据。然后,coordinate node(协调节点)在这些数据中排序,根据_score,相关度倒叙排序。最终拿到我们需要的第1000页的10条数据。
deep paging的劣势
在分布式系统中,对结果排序的成本随分页的深度成指数上升。这就是 web 搜索引擎对任何查询都不要返回超过 1000 个结果的原因。
queryString&_all元数据
queryString使用
//查询field1是“huangjy”的文档GET /human/_search?q=field1:huangjy//查询field1包含“huangjy”的文档GET /human/_search?q=-field1:huangjy//查询field1不包含“huangjy”的文档GET /human/_search?q=+field1:huangjy
_all元数据
- 概念
当在Es中插入一个document的时候,它里面包含了多个field。此时,es会自动将多个field的值,全部用字符串的方式串联起来,变成一个长的字符串,作为_all field的值,同时建立索引。后面在搜索的时候,如果没有指定field搜索,则默认搜索_all field,其中_all field包含了所有field的值。
- 使用_all元数据搜索文档
生产环境不推荐使用这种方式搜索数据。//如果没有定义搜索的字段,则搜索所有字段。任意一个field包含关键字的都可以搜索出来。GET /human/_search?q=huangjy
_mapping是什么?
插入三条document
对三条document执行搜索请求PUT /book/_doc/1{"name":"the first book","isbn":"123","price":10.89,"publication_date":"2020-12-11"}PUT /book/_doc/2{"name":"the second book","isbn":"456","price":20.11,"publication_date":"2020-10-11"}PUT /book/_doc/3{"name":"the third book","isbn":"789","price":30.55,"publication_date":"2020-09-11"}
上述搜索结果的差异是由于字段的不同类型导致搜索结果不一样的。//0条数据GET /book/_search?q=01//1条数据GET /book/_search?q=2020-09-11//1条数据GET /book/_search?q=publication_date:2020-10-11//0条数据GET /book/_search?q=publication_data:2020
_mapping是什么?
在Es中,index的数据结构和相关配置,我们叫做_mapping。
mapping中包含了每个field的数据类型以及分词等设置。
查看索引的mapping结构
{"book" : {"mappings" : {"properties" : {"isbn" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"name" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"price" : {"type" : "float"},"publication_date" : {"type" : "date"}}}}}
精确搜索VS全文搜索
精确搜索:将搜索的字段与结果完全匹配,才能搜索出来。
例如:name=zhangsan
在精确搜索的情况下,有且只有name=zhangsan的用户才会被搜索出来。
全文搜索:可以通过搜索目标的缩写,格式转换,大小写,同义词等方式搜索出结果。
例如:
搜索usa 可以搜索出United States
搜索like 可以搜索出liked
全文搜索不仅仅是匹配一个完整的值,而是可以对值进行拆分后进行匹配,也可以通过缩写,时态,大小写,同义词等方式匹配。
倒排索引
Es中,使用一种称为倒排索引的数据结构,它适用于快速的全文搜索。
倒排索引由文档中不重复的列表构成,对于其中每个词,都有一个包含它的文档列表。
例如,现有两个文档
doc1:i eat noodle for breakfast
doc2:i am eating breakfast in home
下一步,需要将文档拆分成单独的词,创建一个包含不重复的排序列表,然后列出每个词条(Term)出现在那个文档。
| term | doc1 | doc2 |
|---|---|---|
| i | x | x |
| eat | x | x |
| noodle | x | |
| for | x | |
| breakfast | x | x |
| home | x | |
| am | x | |
| eating | x |
现在假设我们要搜索 “eat breakfast”这个词,需要查询包含这个词的问题。
| term | doc1 | doc2 |
|---|---|---|
| eat | x | |
| breakfast | x | x |
doc1和doc2都被匹配出来了,但是doc1的匹配度更高。如果我们使用仅计算匹配词条数量的简单相似性算法来说,doc1要比doc2更好。
这里的倒排索引还有些问题:
eat和eating是同一个意思,只是单词的时态不一样。
时态的转换,单复数的转换,同义词的转换,大小写的转换。
normalization,建立倒排索引的时候,会执行一个操作,也就是说对拆分出的各个单词进行相应的处理,以提升后面搜索的时候能够搜索到相关联的文档的概率。
分词器
什么是分词器分词器就是能将句子拆分成词,并且同时对每个单词进行normalization(时态转换,单复数转换)的工具。
各种分词器的功能character filter:在一段文本进行处理之前,先进行预处理。比如最常见的:去除html标签。tokenizer filter:分词过滤器,将句子拆分成单个的词。例如:how are you =>how,are,youtoken filter:像大小写转换,停词处理,synonymom代名词处理。例如:HOW =》how ; the/a/an,
mom->mother等。
Es默认分词器:
- Standard analyzer:标准分词器(Es默认使用)
- Simple analyzer:简单分词器
- whitespace analyzer:以空格为分词的分词器
- language analyzer:语言分词器

若有收获,就点个赞吧
0 人点赞
