综述
将YOLO检测器变为anchor-free的,并且使用了很多其他的先进技术,如解耦检测头和标签分配策略SimOTA,在多种不同大小的模型上取得了SOTA结果:YOLO-Nano在COCO数据集上的mAP比NanoDet的结果提高了1.8%,达到25.3%;将YOLOv3在相同数据集上的结果提高到47.3% AP,超过最好的YOLOv3实现达3.0%;而对于YOLOv5-L这个级别的模型来说,得到50.0%mAP,比之前的最高得分提高了1.8% AP。
YOLOX实现细节
训练细节
在COCO train2017数据集上训练300个epoch,前5个epoch用来warmup。使用随机梯度下降方法训练网络,初始学习率:0.01,使用cosine学习率方案,并将学习率设置为lrbatch_size / 64。weight decay:0.0005,sgd的momentum取0.9。在8个GPU的设备上设置batch size为128,其他的batch size设置和单GPU训练仍然可以进行良好训练。输入大小从448到832,步长为32。
解耦检测头
在目标检测中,分类和回归任务之间的冲突是广为人知的,在很多一阶检测器和二阶检测器上都有解耦检测头的应用,然而就YOLO系列而言,由于其backbone和neck一直在演进,所以解耦检测头并不没有在该算法上取得应用。实验表明耦合检测头对于算法性能有很大的负面影响:首先,将YOLO系列的检测头替换为解耦检测头可以加速模型收敛;其次,解耦检测头对于端到端的YOLO算法有重要的作用,后面会有介绍。从表1中可以看出,使用耦合检测头对于端到端的YOLO会有高达4.2%的性能下降,与之形成对比的是使用解耦检测头性能下降只有0.8%。因此使用如图2所示的方式,将YOLO的检测头改为解耦合方式。解耦合方式会带来推理时间的提高,在V100GPU上,batch size为1时,推理耗时从10.5 ms增加到11.6 ms。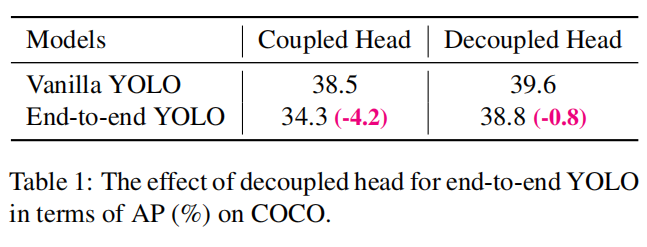
多种数据增强方式
使用Mosaic和mixup数据增强方式,并在最后15个epoch时将这些数据增强关闭,如表2所示,最终得到42.0%mAP。在使用多种数据增强方式之后,发现在imagenet数据集上的预训练并没有什么实际的助益,因此之后的实验都是从头开始训练的。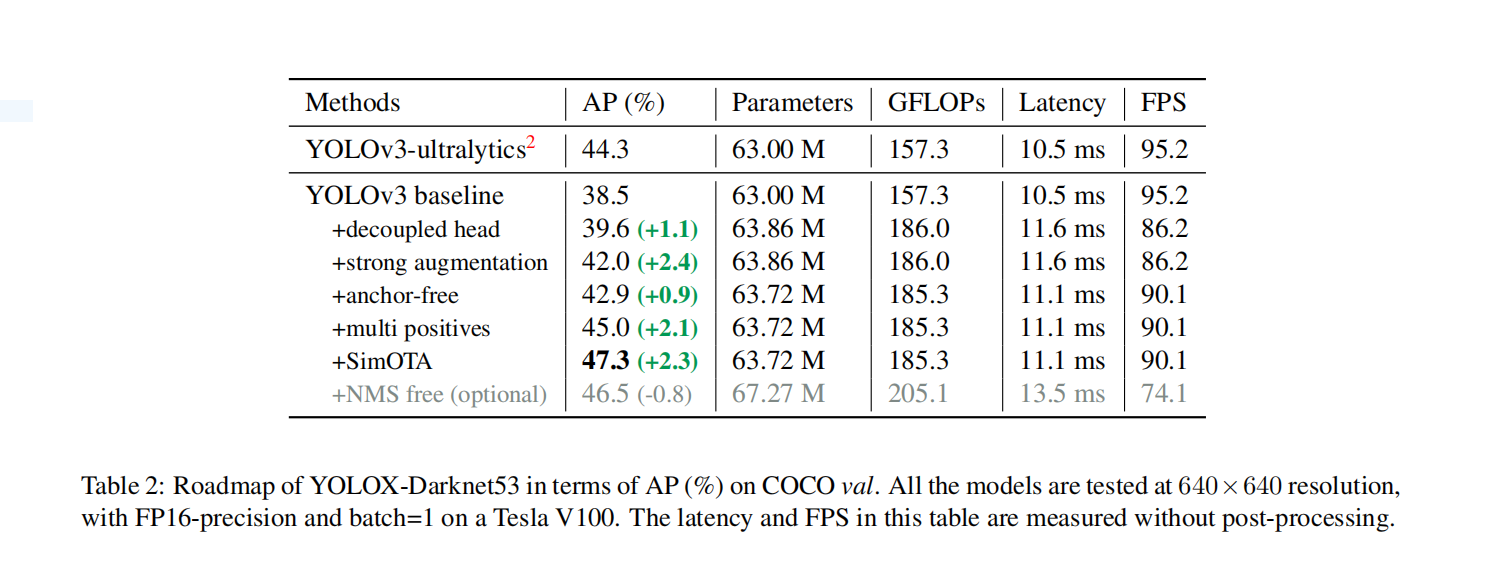
anchor-free方式
YOLOv4和YOLOv5都遵循YOLOv3的基于anchor的方式。但anchor机制存在许多问题:首先,为了得到最优检测性能,必须在训练之前在数据上进行聚类分析,得到最优anchor的集合,这些anchor都是针对特定数据的,泛化性并不好;其次anchor机制增加了算法的复杂度,并且对每一张图像都会产生很多检测结果,对边缘AI系统不友好。anchor-free检测器在过去两年取得长足发展,证明了anchor-free的检测器可以得到和基于anchor的检测器相同的性能。anchor free机制大大减少了超参数量,使检测器的训练和测试阶段变得更加简单。将YOLO变为anchor free算法很简单。将输出特征图上的每个位置的预测数量由3减少到1,直接预测四个值:相对于该位置对应的原图位置的左上角的两个偏移量和预测框的宽高。将每个目标的中心作为正样本,并且定义一个范围来指定用于预测每一个物体的FPN网络层级。这一改进可以在减少参数量和计算量的同时获得更好的性能。
多正样本
为了与YOLOv3的分配方式一致,上述方法选择物体的中心位置为正样本,忽略了其他的高质量正样本,然而这些优化高质量样本也可以产生有益的的梯度,进而减轻正负样本不平衡问题。将中心位置3x3的区域看作正样本,使用该技术之后mAP达到45.0% 。
SimOTA
先进的标签分配技术是目标检测领域中重要的组成部分,基于OTA,总结出优秀的标签分配技术具有以下四个关键属性:1,对损失/质量敏感;2,中心先验;3,对于每个gt有动态数量的正anchor;4,全局视野。OTA算法将标签分配问题视作Optimal Transport (OT) 问题,然而当使用Sinkhorn-Knopp算法求解该Optimal Transport问题时会增加25%的额外训练时间,因此动态地挑选前K个结果作为近似最优解。
*端到端YOLO
添加了两个卷积层,一对一的标签分配和梯度截至。这些措施让我们可以以端到端的方式训练YOLO,但是对结果和推理速度有一定影响。因此不予采用。

若有收获,就点个赞吧
0 人点赞
