通过使用软化目标方法促进多分类神经网络的泛化性和学习速度,软化目标方法通过求硬目标(one hot编码方法)的加权平均值和标签上的均匀分布得到。通过这种方式平滑的标签可以防止网络过拟合,标签平滑技术在很多当前最先进的模型中得到应用,包括图像分类,翻译和语音识别。尽管应用广泛,但是标签平滑计数仍然不能被理解。本文通过实验说明,标签平滑不仅可以提高网络的泛化性能,而且可以促进网络校准(网络校准的定义:https://zhuanlan.zhihu.com/p/325834653),因此可以大幅提升束搜索。但是我们同样观察到如果教师网络使用标签平滑进行训练,学生网络学到的知识就没有效果。为了解释这些现象,将标签平滑对于网络倒数第二层学习到的表示进行可视化。发现标签平滑鼓励相同类的训练样本会分组成更加紧凑的簇。这会导致 logits 中关于不同类别实例之间相似性的信息丢失,这是蒸馏所必需的,但不会影响模型预测的泛化或校准。
预备工作
在叙述本文发现之前,需要提供标签平滑的数学描述。设将神经网络的输出看做倒数第二层的激活函数的函数: ,其中
,其中 是模型对第k个类预测的似然,
是模型对第k个类预测的似然, 表示最后一层的权重和偏置,
表示最后一层的权重和偏置, 是倒数第二层的激活,结尾另外多一个1,将偏置也包含进来。使用硬目标的训练网络,目标是要最小化真实值
是倒数第二层的激活,结尾另外多一个1,将偏置也包含进来。使用硬目标的训练网络,目标是要最小化真实值 和网络输出
和网络输出 之间的交叉熵的期望值,即
之间的交叉熵的期望值,即 ,其中
,其中 对于正确的类来说是1,对其他类是0.对于使用参数
对于正确的类来说是1,对其他类是0.对于使用参数 的标签平滑训练的网络来说,最小化经过修改之后的目标
的标签平滑训练的网络来说,最小化经过修改之后的目标 和目标的输出
和目标的输出 之间的交叉熵损失,其中
之间的交叉熵损失,其中 .
.
2 倒数第二层的表示(没看懂。。。也没查到其他的资料)
使用标签平滑计数训练的网络鼓励正确类和错误类的logit间的差距是一个取决于 的常数。与此相反,使用硬目标训练的网络通常都会得到相比任何不正确类的logit大得多的正确类的logit,并且不正确的类的logit相互之间差异较大。直观的看,第k类的logit
的常数。与此相反,使用硬目标训练的网络通常都会得到相比任何不正确类的logit大得多的正确类的logit,并且不正确的类的logit相互之间差异较大。直观的看,第k类的logit 可以看做倒数第二层的激活输出和模板
可以看做倒数第二层的激活输出和模板 之间的平方欧式距离的度量,
之间的平方欧式距离的度量, .每个类都有一个模板
.每个类都有一个模板 ,
, 在计算softmax输出的时候被分离出来,
在计算softmax输出的时候被分离出来, 通常是跨类别的常量。因此标签平滑鼓励倒数第二层的激活输出与正确类的模板接近,并且与不正确的类有相同的距离。为了显示这一属性,提出新的可视化方案:(1)选择三个类(2)找到穿过这三类模板的平面的正交基(3)将这三类样本的倒数第二层的激活输出映射到这个平面上。
通常是跨类别的常量。因此标签平滑鼓励倒数第二层的激活输出与正确类的模板接近,并且与不正确的类有相同的距离。为了显示这一属性,提出新的可视化方案:(1)选择三个类(2)找到穿过这三类模板的平面的正交基(3)将这三类样本的倒数第二层的激活输出映射到这个平面上。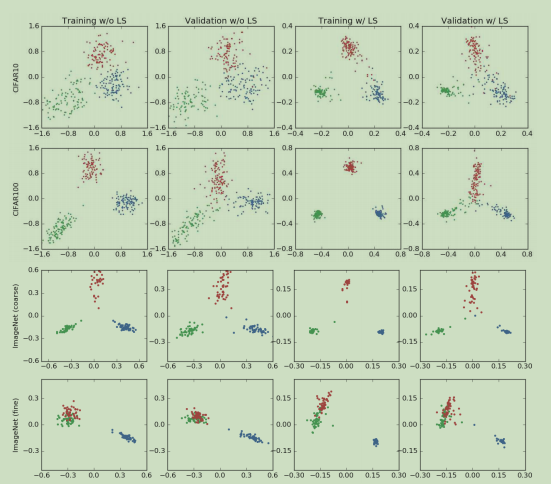
图1. 倒数第二层的输出可视化:alexnet/cifar-10(第一行),cifar-100/ResNet-56(第二行),ImageNet/inception-v4三个语义上不同的类(第三行),两个语义上相同的类和另一个类(第四行)。
图1展示的是在cifar10和cifar100和ImageNet数据集上训练的Alexnet,ResNet-56和Inception-v4的倒数第二层的表示(representation)。表2显示的是标签平滑对于这些模型的影响。图1的第一行是cifar-10中的“飞机”,“汽车”和“鸟”的可视化结果。前两列是没有标签平滑的效果。可以看到这些映射扩展到了宽泛的簇。后两列是标签平滑因子为0.1。可以看到每个簇都相当紧凑,因为标签平滑鼓励训练集中的每一个样本都与其他类的模板有相同的距离。因此,这些在使用标签平滑时簇形成的是正三角形,而使用硬目标训练的情况下则无法观察到正三角形结构。注意这些网络具有相似的精度,尽管激活的聚类性质不同。
第二行展示的是不同数据集/网络结构的激活图形(CIFAR100/ResNet-56).在“海狸”,“海豚”,“海獭”三个分类上观察到了同样的分布。与上一行不同的是,使用标签平滑计数训练的网络具有更好的准确率。另外,使用了标签平滑的网络与不使用的网络的映射区间大小是不同的。使用标签平滑时,两个类的logit之间的差距被限制在某个绝对值,来得到期望的软目标。不使用标签平滑时,映射就会得到更大的绝对值,表示网络得到更加自信的预测。
最后,在Inception-v4/ImageNet上测试我们的可视化方案,在语义相似的类上观察标签平滑的效应,Imagenet数据集具有很多细粒度的类(如不同种类的狗子)。第三行说明了语义不同的类的映射与之前的实验具有相同的效应。第四行的结果更有趣,因为我们选取了两个语义上相似的类(玩具贵宾犬和微型贵宾犬)和另一个语义不相似的类丁鲷(用蓝色表示)。使用硬目标时,语义相似的类会以各项同性(各向同性和各向异性是指物理性质在不同的方向进行测量得到的结论。如果各个方向的测量结果是相同的,说明其物理性质与取向无关,就称为各向同性。如果物理性质和取向密切相关,不同取向的测量结果迥异,就称为各向异性。)的分布与彼此集群靠近。与之相反的是,使用标签平滑时,相似的类会位于一个圆弧上。在上述两种情况下,语义相似的类彼此之间都很难区分开,但是标签平滑技术可以强制每一个样本与剩余的类的模板等距离,这就导致了圆弧形状的产生。还注意到在不使用标签平滑时,丁鲷集群和贵宾犬集群之间的变化是连续的。此时可以隐式地估计“一个贵宾犬有多大程度是一个丁鲷”。然而当使用标签平滑时,这一信息被抹除了。最后该图显示标签平滑的效果与网络结构,数据集和精度无关。
3 隐式模型校准
通过人工软化目标,标签平滑可以防止网络变得过度自信。但标签平滑是否能够通过更加准确地反映预测的准确性,来提升网络的校准呢?这一部分就来回答这一问题。有文献已经证明现在的神经网络没有很好地校准并且是过于自信的,尽管相比于之前的更好的校准网络它们有着更好的性能。为了评价校准,作者计算校准误差估计期望(ECE),他们证明了使用一种叫做temperature scaling的后处理技术可以减少ECE校准网络。在此我们证明使用标签平滑同样可以减少ECE并且在不使用temperature scaling的情况下对网络进行校准。
图像分类
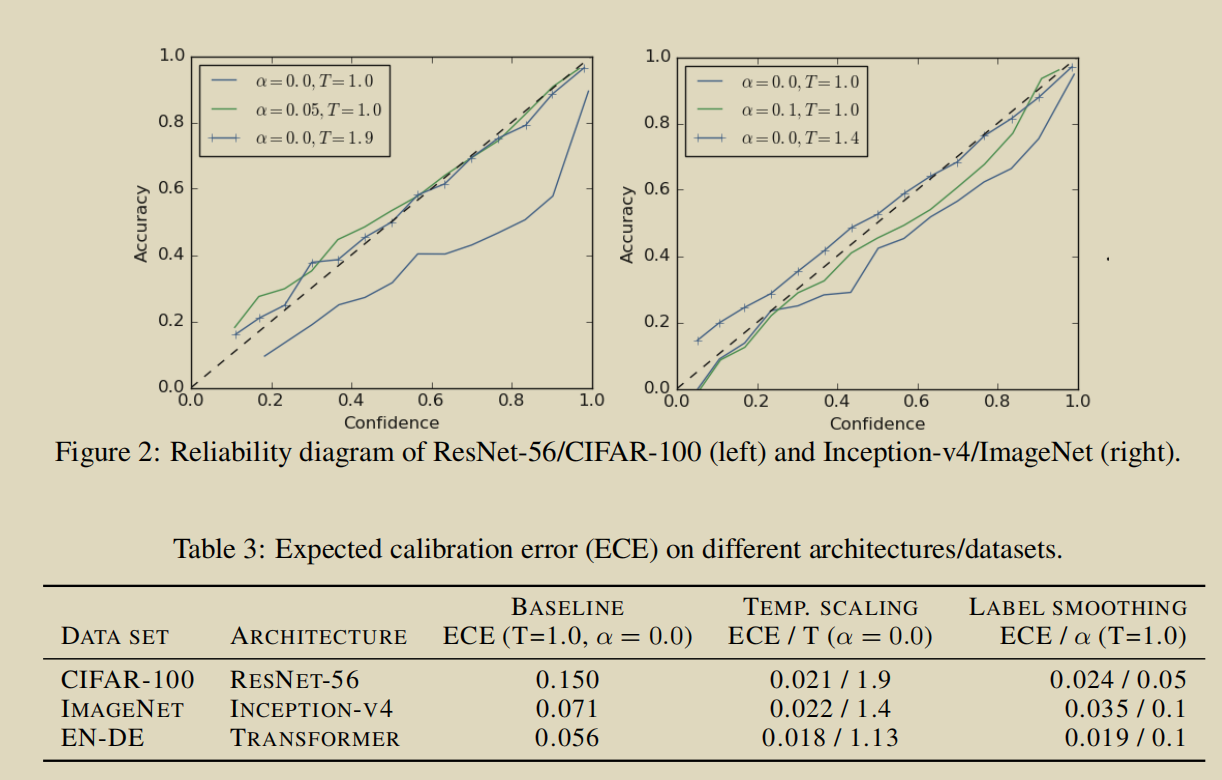
以分析图像分类模型的校准作为开始。图2(左)展示的是在cifar-100上训练的resnet-56的15个bin的可靠性图(可靠性图的相关解释:https://towardsdatascience.com/introduction-to-reliability-diagrams-for-probability-calibration-ed785b3f5d44)。点线表示完美的网络校准,输出的置信度完美地预测了精度。在不使用temperature scaling时,使用硬目标训练的网络很明显过度自信,因为精确度一直低于置信度。为了对模型进行校准,可以对模型进行temperature scaling调整,参数为1.9.可以观察到在可靠性图像中,带x的蓝色线段的斜率接近1,模型被更好地校准了。通过使用标签平滑( )训练同一模型,可以得到与temperature scaling相同的效果。表3显示了标签平滑和temperature scaling对ECE的影响。两种方法都可以将ECE减少到相似的较小值。
)训练同一模型,可以得到与temperature scaling相同的效果。表3显示了标签平滑和temperature scaling对ECE的影响。两种方法都可以将ECE减少到相似的较小值。
图2(右)展示的是在ImageNet数据集上进行的实验。使用硬目标训练的网路再次变得过于自信,并且ECE高达0.071,使用temperature scaling(T=1.4),ECE减少到0.022。使用标签平滑(0.1)将ECE减小到0.035,获得了比不适用标签平滑的网络更好的校准。

若有收获,就点个赞吧
0 人点赞
