摘要:CoMoGAN 是一个连续的 GAN,它依赖于在功能流形上对目标数据进行无监督的重组。为此,我们引入了一个新的功能实例归一化层和残差机制,它们共同将图像内容与目标流形上的位置分开。我们依靠朴素的受物理启发的模型来指导训练,同时允许使用私有迁移模型。CoMoGAN 可以与任何 GAN 主干一起使用,并允许新类型的图像迁移,例如像延时生成这样的循环图像迁移,或分离的线性迁移。在所有数据集和指标上,它都优于现存文献结果。
简介:本文引入了 CoMoGAN,这是第一个使用无监督目标数据学习非线性连续迁移规则的 i2i(image to image) 框架。它使用简单的物理启发模型进行训练,同时通过域特征的连续分解来放松模型依赖性。有趣的结果是,CoMoGAN在无人监督的情况下发现了目标数据流形排序。为了评估,我们提出了新的翻译任务,如图 1 所示,要么是循环的/线性的,要么是与源连接的/分离的。我们的贡献是:
• 用于连续 i2i 的新型模型引导设置,
• CoMoGAN:一个无监督框架,通过使用简单的模型指导,用于分解生成图像的不断发展的特征
• 一个新的功能实例归一化 (FIN) 层,
• 根据最近的基线和新任务对 CoMoGAN 的评估,在所有方面都优于现有文献。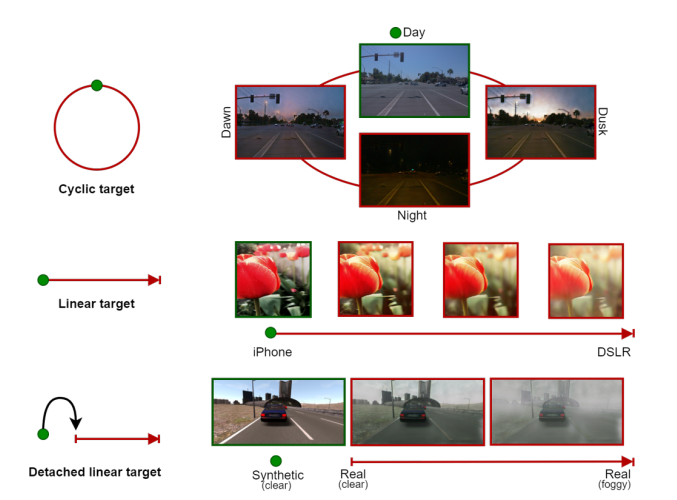
图1
图1.与传统的 i2i 迁移方法不同,我们感兴趣的是在单模态或多模态设置中从源域(绿点)到目标域(红线)的连续映射。本文提出的一个关键特征是沿函数流形(顶部:循环,中间/底部:线性)对数据进行无监督的重组。我们利用了白天图像(顶部)的照明转换、对焦图像的较浅景深(中间)或合成清晰图像到逼真的有雾图像(底部)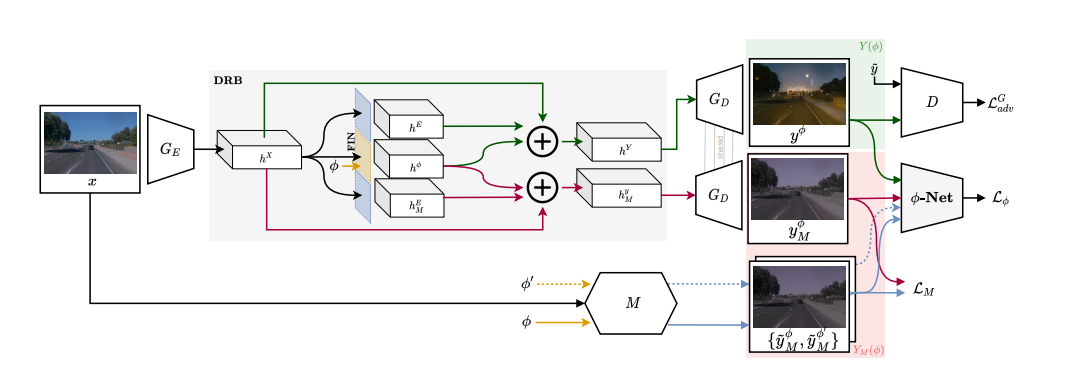
图2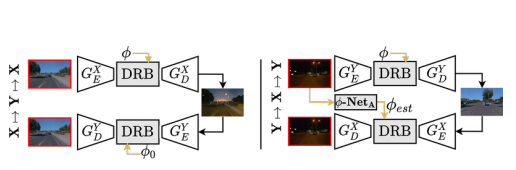
图3
3.CoMoGAN
CoMoGAN学习的不是点对点映射( ),而是由
),而是由 控制的连续域转换,即
控制的连续域转换,即 。训练使用源数据(固定的
。训练使用源数据(固定的 )和无监督目标数据(未知的
)和无监督目标数据(未知的 )。它重新塑造了由朴素的物理启发模型(例如色调映射、模糊等)引导的数据流形。我们不是模仿,而是放松模型,让网络通过我们对输出、
)。它重新塑造了由朴素的物理启发模型(例如色调映射、模糊等)引导的数据流形。我们不是模仿,而是放松模型,让网络通过我们对输出、 和风格的分解来发现私有图像特征。
和风格的分解来发现私有图像特征。
图 2 是我们的未知架构网络的概述。它依赖于三个关键组件。我们首先介绍功能实例归一化层(第3.1节),该层可实现 流形重塑。其次,我们的分解残差模块(第 3.2 节)负责对输入数据中的
流形重塑。其次,我们的分解残差模块(第 3.2 节)负责对输入数据中的 进行分解。最后,我们详细介绍了
进行分解。最后,我们详细介绍了 -Net,这是一个成对的
-Net,这是一个成对的 回归网络(第 3.3 节),它加强了流形距离的一致性。
回归网络(第 3.3 节),它加强了流形距离的一致性。
本文使用简单的非神经模型 (其中
(其中 是源图像)来指导学习。因此,根据直觉可以粗糙模型发现目标流形:夜晚类似于黑暗的白天,雾看起来像模糊的灰色清晰图像,等等。由于我们从迁移模型中分离了共享和私有特征,因此我们不再需要复杂的物理指导就可以发现复杂的非建模特征(例如夜间的光源)。模型在4.1 和补充材料中有描述。
是源图像)来指导学习。因此,根据直觉可以粗糙模型发现目标流形:夜晚类似于黑暗的白天,雾看起来像模糊的灰色清晰图像,等等。由于我们从迁移模型中分离了共享和私有特征,因此我们不再需要复杂的物理指导就可以发现复杂的非建模特征(例如夜间的光源)。模型在4.1 和补充材料中有描述。
3.1. 功能实例归一化
为了利用本质上连续的模型指导,必须允许我们的网络编码 连续性。为此,提出了实例归一化,该方法可以保存与风格相关的信息,输入为
连续性。为此,提出了实例归一化,该方法可以保存与风格相关的信息,输入为 ,可以写作:
,可以写作:
其中 和
和 是输入特征的统计量,
是输入特征的统计量, 和
和 是仿射变换的可学习的参数.将其进行扩展,得到了功能实例归一化:
是仿射变换的可学习的参数.将其进行扩展,得到了功能实例归一化:
在这里,不再学习具体的仿射变换的参数数值,而是学习变换 和
和 的分布.直觉是根据转换的演变方式来塑造
的分布.直觉是根据转换的演变方式来塑造 -流形。 与其他的工作相比,这使我们能够更好地解释学习到的流形。 根据
-流形。 与其他的工作相比,这使我们能够更好地解释学习到的流形。 根据 的性质,我们可以相应地对FIN层进行编码。 在这项工作中,我们研究了线性和循环编码。 线性编码通常会遇到,并假设线性重组特征。 例如,考虑到恶劣的天气现象,恶劣条件(例如浓雾)总是位于轻条件(即轻雾)之后,对线性的FIN参数进行建模:
的性质,我们可以相应地对FIN层进行编码。 在这项工作中,我们研究了线性和循环编码。 线性编码通常会遇到,并假设线性重组特征。 例如,考虑到恶劣的天气现象,恶劣条件(例如浓雾)总是位于轻条件(即轻雾)之后,对线性的FIN参数进行建模:
其中 都是可学习的参数.
都是可学习的参数.
相反,一些迁移路径循环回源,就像白天发生的那样,它本质上是循环的,从白天到黄昏→夜晚→黎明和白天。 在这种情况下,我们使用如下公式对循环 FIN 层进行编码:
3.2 分解残差模块
严格模型依赖的缺陷在于 GAN 只会学习模仿模型。 为了防止这种情况,必须允许目标域 和模型域
和模型域 具有共享的建模特征
具有共享的建模特征 还有私有的非建模特征
还有私有的非建模特征 和
和 ,写作:
,写作:
\begin {equation}
Y(\phi)={Y^{\phi}, Y^E}, \
Y_M(\phi)={Y_M^{\phi}, Y_M^E}
\tag {5}
\end {equation}
使用 Disentanglement Residual Block(DRB,如图2所示)在任一域中启用私有特征,其目标是提取给定 的分解表示。 DRB 由残差块组成,将编码器特征图
的分解表示。 DRB 由残差块组成,将编码器特征图 映射到输出图像的分解表达。 令
映射到输出图像的分解表达。 令 ,下式成立:
,下式成立:
DRB工作方式如下.如图2所示,输入表示 由残差块处理,每一个残差块都提取与之前引入的原子特征相关联的特征,例如
由残差块处理,每一个残差块都提取与之前引入的原子特征相关联的特征,例如 .具体讲,用于提取
.具体讲,用于提取 的残差块使用FIN层进行归一化以编码连续特征。 隐藏的潜在表示
的残差块使用FIN层进行归一化以编码连续特征。 隐藏的潜在表示 和
和 是由分解特征和
是由分解特征和 的总和获得的,以简化梯度传播。公式如下:
的总和获得的,以简化梯度传播。公式如下:
直观地说,为了优化,我们需要两者的反馈真实数据相似性和模型输出的模仿。而前者必须依靠对抗训练,因为使用的是未配对的图像,我们可以强制以成对的模型进行重建 。参考LSGAN的训练和鉴别器 D,我们得到:
。参考LSGAN的训练和鉴别器 D,我们得到:
在生成器更新期间最小化上述两个损失函数可以实现 和
和 的分解.
的分解.
3.3 成对回归网络( -Net)
-Net)
DRB 在特征级别强制解缠结和流形形状,但它需要专门的训练策略来实际解开真实图像的连续特征,而不是陷入陷阱,例如网络仅利用 进行目标翻译而忽略
进行目标翻译而忽略 。因此,我们引入了一种基于相似性的训练策略,迫使网络利用提取的连续信息并遵循模型指导。 假设输入图像为
。因此,我们引入了一种基于相似性的训练策略,迫使网络利用提取的连续信息并遵循模型指导。 假设输入图像为 ,由网络映射进行映射
,由网络映射进行映射 。 如图 2所示,我们随机采样
。 如图 2所示,我们随机采样 和
和 并将
并将 作用于
作用于 ,得到一对
,得到一对 。 我们使用卷积神经网络(
。 我们使用卷积神经网络( -Net)进行域相似性发现。 它将一对图像作为输入并回归它们的
-Net)进行域相似性发现。 它将一对图像作为输入并回归它们的 差异,满足:
差异,满足:
通过加强真实和建模目标域图像之间的一致性以端到端的形式同时优化 -Net和生成器(G)的参数,在下述公式中:
-Net和生成器(G)的参数,在下述公式中: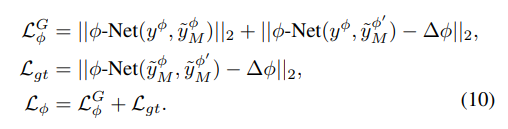
 强制生成器G遵循物理模型的反馈对流形进行组织,最终生成的
强制生成器G遵循物理模型的反馈对流形进行组织,最终生成的 和
和 能够被映射到被
能够被映射到被 -Net发现的相同的
-Net发现的相同的 .这样,尽管模型输出和学习的迁移规则之间存在差异,但是网络可以识别遵循相似性标准的图像,从而得到由物理模型引导的潜在空间的组织。
.这样,尽管模型输出和学习的迁移规则之间存在差异,但是网络可以识别遵循相似性标准的图像,从而得到由物理模型引导的潜在空间的组织。 仅利用建模数据,避免了训练崩溃。 对于线性 FIN,我们在
仅利用建模数据,避免了训练崩溃。 对于线性 FIN,我们在 和
和 上进行训练,尽管可以通过评估
上进行训练,尽管可以通过评估 的
的 投影上的每个损失来增加循环稳定性。
投影上的每个损失来增加循环稳定性。
3.4训练策略
COMOGAN可以进行端到端的训练,并且可以用于任何i2i网络,只要在编码器和解码器之间添加DRB模块并使用我们的损失函数.生成器最终的目标取决于源和目标是否解耦,即 ,一旦解耦,生成器更新步骤写作:
,一旦解耦,生成器更新步骤写作:
对于耦合的源和目标,强制执行源( )的身份信息?:
)的身份信息?:
使用任一 的定义,有时与正则化成对损失结合使用以简化训练。
的定义,有时与正则化成对损失结合使用以简化训练。
使用目标真实数据( ),判别器最小化损失
),判别器最小化损失
循环一致性
除了有映射 ,很多网络还会执行映射
,很多网络还会执行映射 ,目的是保持内容的循环一致性.为了解决后者的需求,将共享DRB插入到每一个编码器/解码器之间,这样可以利用到多个源.如图3所示.还是用另一个称作
,目的是保持内容的循环一致性.为了解决后者的需求,将共享DRB插入到每一个编码器/解码器之间,这样可以利用到多个源.如图3所示.还是用另一个称作 的无监督网络来回归目标数据集的
的无监督网络来回归目标数据集的 .在图3左侧,因为
.在图3左侧,因为 被注入映射
被注入映射 之间,我们通过将
之间,我们通过将 添加到生成器目标来强制正确传播所有
添加到生成器目标来强制正确传播所有 值.
值.

若有收获,就点个赞吧
0 人点赞
