一、背景
一年一度由世界知名科技媒体 InfoWorld 评选的 Bossie Awards 于 9 月 26 日公布,本次 Bossie Awards 评选出了最佳数据库与数据分析平台奖、最佳软件开发工具奖、最佳机器学习项目奖等多个奖项。在《最佳开源数据库与数据分析平台奖》中,之前曾连续两年入选的 Kafka 意外滑铁卢落选,取而代之的是新兴项目 Pulsar。 Bossie Awards中对 Pulsar 点评如下:Pulsar 旨在取代 Apache Kafka 多年的主宰地位。Pulsar在很多情况下提供了比 Kafka 更快的吞吐量和更低的延迟,并为开发人员提供了一组兼容的 API,让他们可以很轻松地从 Kafka 切换到 Pulsar。Pulsar 的最大优点在于它提供了比 Apache Kafka 更简单明了、更健壮的一系列操作功能,特别在解决可观察性、地域复制和多租户方面的问题。在运行大型 Kafka 集群方面感觉有困难的企业可以考虑转向使用 Pulsar。
二、Pulsar 相关概念和术语
生产者、消费者和主题
向 Pulsar 发送数据的应用程序叫作生产者(producer),而从 Pulsar 读取数据的应用程序叫作消费者(consumer)。有时候消费者也被叫作订阅者。主题(topic)是 Pulsar 的核心资源,一个主题可以被看成是一个通道,消费者向这个通道发送数据,消费者从这个通道拉取数据。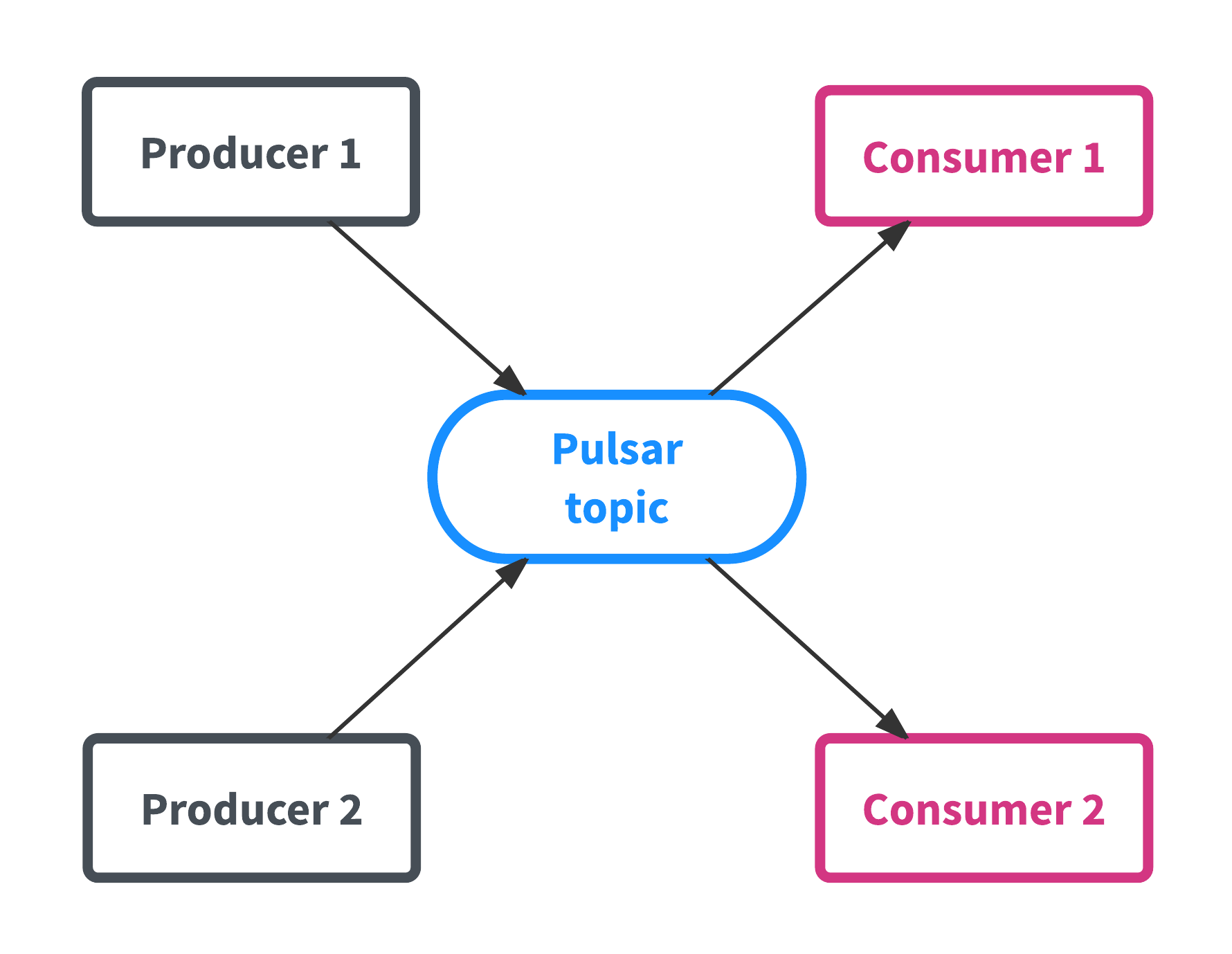
Pulsar 各个组件间的关系
构建 Pulsar 的目的是为了支持多租户(multi-tenant)应用场景。Pulsar 的多租户机制包含了两种资源:资产(property)和命名空间(namespace)。资产代表系统里的租户。假设有一个 Pulsar 集群用于支持多个应用程序,集群里的每个资产可以代表一个组织的团队、一个核心的功能或一个产品线。一个资产可以包含多个命名空间,一个命名空间可以包含任意个主题。
- 命名空间是 Pulsar 最基本的管理单元。在命名空间层面,我们可以设置权限、调整复制选项、管理跨集群的数据复制、 控制消息的过期时间或执行其他关键任务。命名空间里的主题会继承命名空间的配置,所以我们可以一次性对同一个命名空间内的所有主题进行配置。命名空间可以分为两种:
- 本地(local)——本地命名空间只在集群内可见。
- 全局(global)——命名空间对多个集群可见,可以是同一个数据中心内的集群,也可以是跨地域数据中心的集群。该功能取决于是否启用了集群复制功能。

虽然本地命名空间和全局命名空间的作用域不同,但它们都可以在不同的团队或不同的组织内共享。如果应用程序获得了命名空间的写入权限,就可以往该命名空间内的所有主题写入数据。如果写入的主题不存在,就会创建该主题。
每个命名空间可以包含一到多个主题,每个主题可以有多个订阅者,每个订阅者可以接收所有发布到该主题的消息。为了给应用程序提供更大的灵活性,Pulsar 提供了三种订阅类型,它们可以共存在同一个主题上,分别是:独享(exclusive)订阅、共享(shared)订阅、失效备援(failover)订阅,在消息模型的章节里面会详细介绍。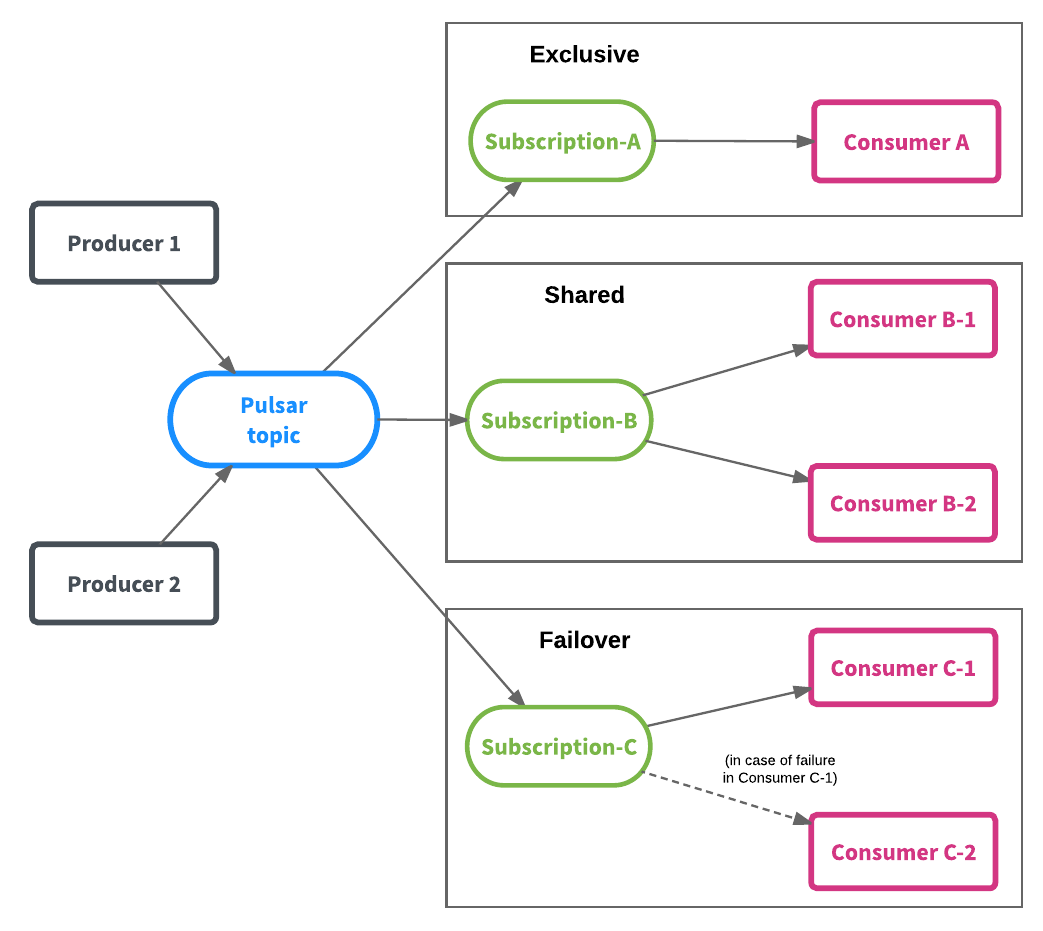
三、Pulsar的系统架构设计
Pulsar 的分层架构
Apache Pulsar 和其他消息系统最根本的不同是采用分层架构。 Apache Pulsar 集群由两层组成:无状态服务层,由一组接收和传递消息的 Broker 组成;以及一个有状态持久层,由一组名为 bookies 的 Apache BookKeeper 存储节点组成,可持久化地存储消息。 下图显示了 Apache Pulsar 的典型部署。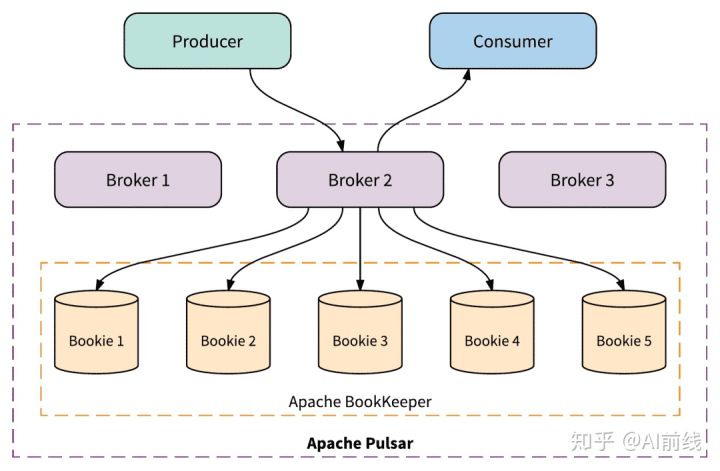
在 Pulsar 客户端中提供生产者和消费者(Producer & Consumer)接口,应用程序使用 Pulsar 客户端连接到 Broker 来发布和消费消息。
Pulsar 客户端不直接与存储层 Apache BookKeeper 交互。 客户端也没有直接的 Zookeeper 访问权限。这种隔离,为 Pulsar 实现安全的多租户统一身份验证模型提供了基础。
Apache Pulsar 为客户端提供多种语言的支持,包括 Java,C ++,Python,Go 和 Websockets。Apache Pulsar 还提供了一组兼容 Kafka 的 API,用户可以通过简单地更新依赖关系并将客户端指向 Pulsar 集群来迁移现有的 Kafka 应用程序,这样现有的 Kafka 应用程序可以立即与 Apache Pulsar 一起使用,无需更改任何代码。
Broker 层:无状态服务层
Broker 集群在 Apache Pulsar 中形成无状态服务层。服务层是“无状态的”,因为 Broker 实际上并不在本地存储任何消息数据。有关 Pulsar 主题的消息,都被存储在分布式日志存储系统(Apache BookKeeper)中。我们将在下一节中更多地讨论 BookKeeper。
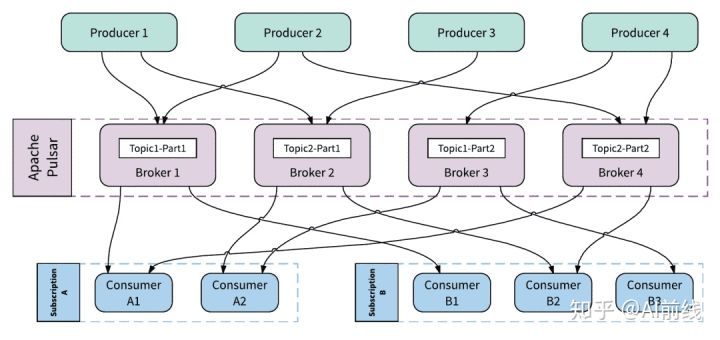
每个主题分区(Topic Partition)由 Pulsar 分配给某个 Broker,该 Broker 称为该主题分区的所有者。 Pulsar 生产者和消费者连接到主题分区的所有者 Broker,以向所有者代理发送消息并消费消息。
如果一个 Broker 失败,Pulsar 会自动将其拥有的主题分区移动到群集中剩余的某一个可用 Broker 中。这里要说的一件事是:由于 Broker 是无状态的,当发生 Topic 的迁移时,Pulsar 只是将所有权从一个 Broker 转移到另一个 Broker,在这个过程中,不会有任何数据复制发生。
下图显示了一个拥有 4 个 Broker 的 Pulsar 集群,其中 4 个主题分区分布在 4 个 Broker 中。每个 Broker 拥有并为一个主题分区提供消息服务。
BookKeeper 层:持久化存储层
Apache BookKeeper 是 Apache Pulsar 的持久化存储层。 Apache Pulsar 中的每个主题分区本质上都是存储在 Apache BookKeeper 中的分布式日志。
每个分布式日志又被分为 Segment 分段。 每个 Segment 分段作为 Apache BookKeeper 中的一个 Ledger,均匀分布并存储在 BookKeeper 群集中的多个 Bookie(Apache BookKeeper 的存储节点)中。
Segment 的创建时机包括以下几种:基于配置的 Segment 大小;基于配置的滚动时间;或者当 Segment 的所有者被切换。
通过 Segment 分段的方式,主题分区中的消息可以均匀和平衡地分布在群集中的所有 Bookie 中。 这意味着主题分区的大小不仅受一个节点容量的限制; 相反,它可以扩展到整个 BookKeeper 集群的总容量。
下面的图说明了一个分为 x 个 Segment 段的主题分区。 每个 Segment 段存储 3 个副本。 所有 Segment 都分布并存储在 4 个 Bookie 中。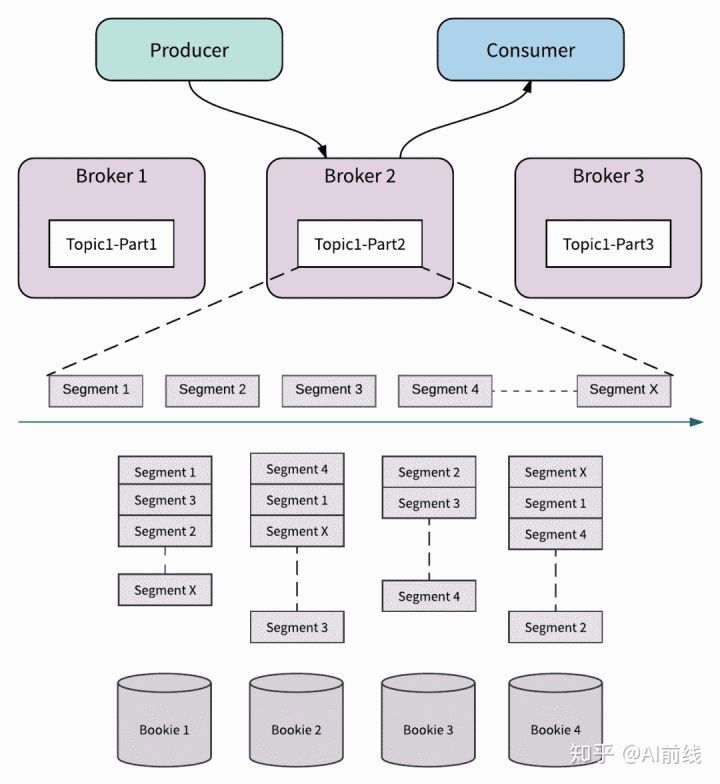
Segment 为中心的存储
存储服务的分层的架构 和 以 Segment 为中心的存储 是 Apache Pulsar(使用 Apache BookKeeper)的两个关键设计理念。 这两个基础为 Pulsar 提供了许多重要的好处:
- 无限制的主题分区存储
- 即时扩展,无需数据迁移
- 无缝 Broker 故障恢复
- 无缝集群扩展
- 无缝的存储(Bookie)故障恢复
- 独立的可扩展性
下面我们分别展开来看这几个好处。
- 无限制的主题分区存储:由于主题分区被分割成 Segment 并在 Apache BookKeeper 中以分布式方式存储,因此主题分区的容量不受任何单一节点容量的限制。 相反,主题分区可以扩展到整个 BookKeeper 集群的总容量,只需添加 Bookie 节点即可扩展集群容量。 这是 Apache Pulsar 支持存储无限大小的流数据,并能够以高效,分布式方式处理数据的关键。 使用 Apache BookKeeper 的分布式日志存储,对于统一消息服务和存储至关重要。
- 即时扩展,无需数据迁移:由于消息服务和消息存储分为两层,因此将主题分区从一个 Broker 移动到另一个 Broker 几乎可以瞬时内完成,而无需任何数据重新平衡(将数据从一个节点重新复制到另一个节点)。 这一特性对于高可用的许多方面至关重要,例如集群扩展;对 Broker 和 Bookie 失败的快速应对。 我将使用例子在下文更详细地进行解释。
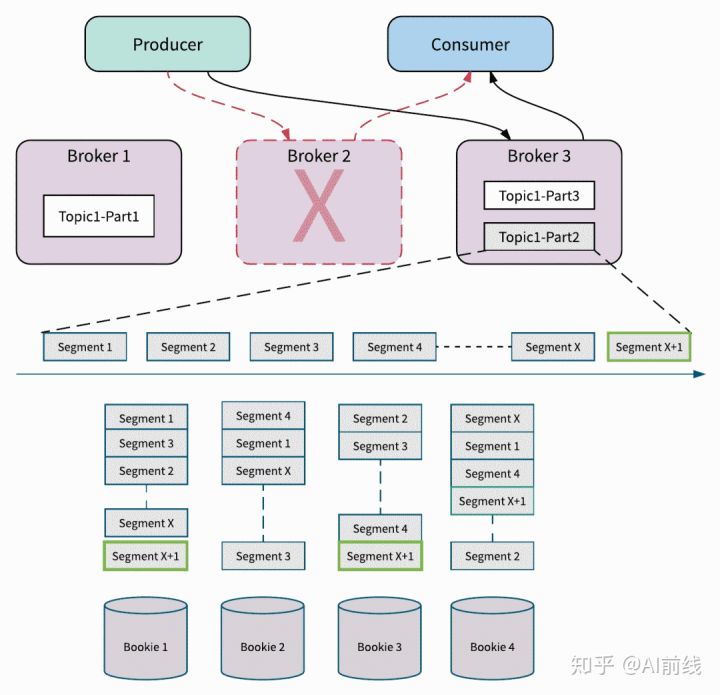
- 无缝 Broker 故障恢复:下图说明了 Pulsar 如何处理 Broker 失败的示例。 在例子中 Broker 2 因某种原因(例如停电)而断开。 Pulsar 检测到 Broker 2 已关闭,并立即将 Topic1-Part2 的所有权从 Broker 2 转移到 Broker 3。在 Pulsar 中数据存储和数据服务分离,所以当代理 3 接管 Topic1-Part2 的所有权时,它不需要复制 Partiton 的数据。 如果有新数据到来,它立即附加并存储为 Topic1-Part2 中的 Segment x + 1。 Segment x + 1 被分发并存储在 Bookie1, 2 和 4 上。因为它不需要重新复制数据,所以所有权转移立即发生而不会牺牲主题分区的可用性。
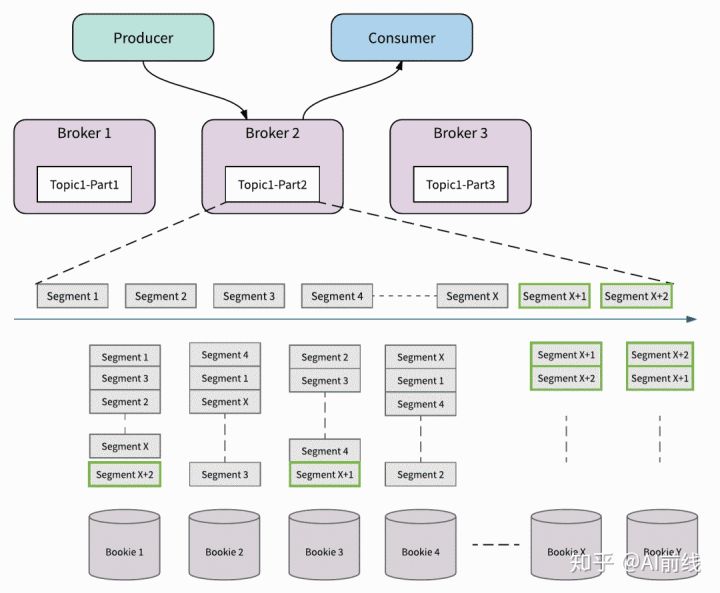
- 无缝集群容量扩展:下图说明了 Pulsar 如何处理集群的容量扩展。 当 Broker 2 将消息写入 Topic1-Part2 的 Segment X 时,将 Bookie X 和 Bookie Y 添加到集群中。 Broker 2 立即发现新加入的 Bookies X 和 Y。然后 Broker 将尝试将 Segment X + 1 和 X + 2 的消息存储到新添加的 Bookie 中。 新增加的 Bookie 立刻被使用起来,流量立即增加,而不会重新复制任何数据。 除了机架感知和区域感知策略之外,Apache BookKeeper 还提供资源感知的放置策略,以确保流量在群集中的所有存储节点之间保持平衡。
- 无缝的存储(Bookie)故障恢复:下图说明了 Pulsar(通过 Apache BookKeeper)如何处理 bookie 的磁盘故障。 这里有一个磁盘故障导致存储在 bookie 2 上的 Segment 4 被破坏。Apache BookKeeper 后台会检测到这个错误并进行复制修复。

Apache BookKeeper 中的副本修复是 Segment(甚至是 Entry)级别的多对多快速修复,这比重新复制整个主题分区要精细,只会复制必须的数据。 这意味着 Apache BookKeeper 可以从 bookie 3 和 bookie 4 读取 Segment 4 中的消息,并在 bookie 1 处修复 Segment 4。所有的副本修复都在后台进行,对 Broker 和应用透明。即使有 Bookie 节点出错的情况发生时,通过添加新的可用的 Bookie 来替换失败的 Bookie,所有 Broker 都可以继续接受写入,而不会牺牲主题分区的可用性。
- 独立的可扩展性:由于消息服务层和持久存储层是分开的,因此 Apache Pulsar 可以独立地扩展存储层和服务层。这种独立的扩展,更具成本效益:
- 当您需要支持更多的消费者或生产者时,您可以简单地添加更多的 Broker。主题分区将立即在 Brokers 中做平衡迁移,一些主题分区的所有权立即转移到新的 Broker。
- 当您需要更多存储空间来将消息保存更长时间时,您只需添加更多 Bookie。通过智能资源感知和数据放置,流量将自动切换到新的 Bookie 中。 Apache Pulsar 中不会涉及到不必要的数据搬迁,不会将旧数据从现有存储节点重新复制到新存储节点。
四、与 Kafka 的对比
Apache Kafka 和 Apache Pulsar 都有类似的消息概念。 客户端通过主题与消息系统进行交互。 每个主题都可以分为多个分区。 然而,Apache Pulsar 和 Apache Kafka 之间的根本区别在于 Apache Kafka 是以分区为存储中心,而 Apache Pulsar 是以 Segment 为存储中心。
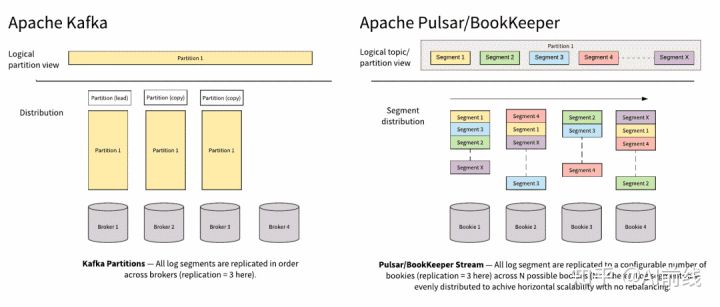
上图显示了以分区为中心和以 Segment 为中心的系统之间的差异。
在 Apache Kafka 中,分区只能存储在单个节点上并复制到其他节点,其容量受最小节点容量的限制。这意味着容量扩展需要对分区重新平衡,这反过来又需要重新复制整个分区,以平衡新添加的代理的数据和流量。
重新传输数据非常昂贵且容易出错,并且会消耗网络带宽和 I/O。维护人员在执行此操作时必须非常小心,以避免破坏生产系统。
Kafka 中分区数据的重新拷贝不仅发生在以分区为中心的系统中的群集扩展上。许多其他事情也会触发数据重新拷贝,例如副本故障,磁盘故障或计算机的故障。在数据重新复制期间,分区通常不可用,直到数据重新复制完成。例如,如果您将分区配置为存储为 3 个副本,这时,如果丢失了一个副本,则必须重新复制完整个分区后,分区才可以再次可用。
在用户遇到故障之前,通常会忽略这种缺陷,因为许多情况下,在短时间内仅是对内存中缓存数据的读取。当数据被保存到磁盘后,用户将越来越多地不可避免地遇到数据丢失,故障恢复的问题,特别是在需要将数据长时间保存的场合。
相反,在 Apache Pulsar 中,同样是以分区为逻辑单元,但是以 Segment 为物理存储单元。分区随着时间的推移会进行分段,并在整个集群中均衡分布,旨在有效地迅速地扩展。
Pulsar 是以 Segment 为中心的,因此在扩展容量时不需要数据重新平衡和拷贝,旧数据不会被重新复制,这要归功于在 Apache BookKeeper 中使用可扩展的以 Segment 为中心的分布式日志存储系统。
通过利用分布式日志存储,Pulsar 可以最大化 Segment 放置选项,实现高写入和高读取可用性。 例如,使用 BookKeeper,副本设置等于 2,只要任何 2 个 Bookie 启动,就可以对主题分区进行写入。 对于读取可用性,只要主题分区的副本集中有 1 个处于活动状态,用户就可以读取它,而不会出现任何不一致。
总之,Apache Pulsar 这种独特的基于分布式日志存储的以 Segment 为中心的发布 / 订阅消息系统可以提供许多优势,例如可靠的流式系统,包括无限制的日志存储,无需分区重新平衡的即时扩展,快速复制修复以及通过最大化数据放置实现高写入和读取可用性选项。
五、参考资料
https://www.infoq.cn/article/2017/11/Apache-Pulsar-brief-introduction
https://zhuanlan.zhihu.com/p/47388267

若有收获,就点个赞吧
0 人点赞
