分享背景
在做前台应用时,我们经常遇到以下这些场景:
- 一个接口需要远程调用各个域的N个接口,耗时过长,压测不达标
- 某些接口考虑到DB等中间件的读取性能,想查询所有的数据需要循环调用
- 在较大数据量的批作业场景想加快任务执行的速度
异步与同步,阻塞和非阻塞
同步和异步描述的是消息通信机制,阻塞和非阻塞描述的是程序在获取执行结果时的状态
- 同步型调用,应用层需要主动向系统内核问询数据是否准备完毕,如果未准备完毕则应用层需要根据其阻塞和非阻塞的策略,或挂起或执行其他程序(所以同步和异步并不决定其等待数据返回时的状态);如果数据读取完毕,此时系统内核将数据返回给应用层,应用层即可以用取得的数据执行相关的程序。
- 异步型的调用,应用层无须主动向系统内核问询,因为系统在内核读取完文件数据之后会主动通知应用层数据已经读取完毕,此时应用层即可以接收系统内核返回的数据来执行相关的程序。
阻塞型I/O和非阻塞型I/O的区别:
- 如果应用层调用的是阻塞型 I/O,那么在调用后,应用层即刻被挂起直到系统内核从磁盘读取完数据并返回时,才能进行接下来的操作。
如果应用层调用的是非阻塞 I/O,那么调用后,系统内核会立即返回,应用层也不会被挂起而立刻可以开始执行其他操作。
并发与并行
目标都是最大化CPU的使用率
- 并发可认为是一种程序的逻辑结构的设计模式
-可以用并发的设计方式去设计模型,然后运行在一个单核系统上
-可以将这种模型不加修改地运行在多核系统上,实现真正的并行
- 并行是程序执行的一种属性 – 真正的同时执行(或发生)
- Concurrency is about correctly and efficiently controlling access to shared resources
-Example: constructing thread-safe data structures
-Primitives: Locks, events, semaphores, coroutines, STM
- Parallelism is about using additional resources to produce an answer faster Example: searching a large data set by partitioning
扩展阅读:
《From Concurrent to Parallel》- https://www.youtube.com/watch?v=NsDE7E8sIdQ
《Rob Pike - ‘Concurrency Is Not Parallelism’》 - https://www.youtube.com/watch?v=qmg1CF3gZQ0
CPU三级缓存架构与JMM
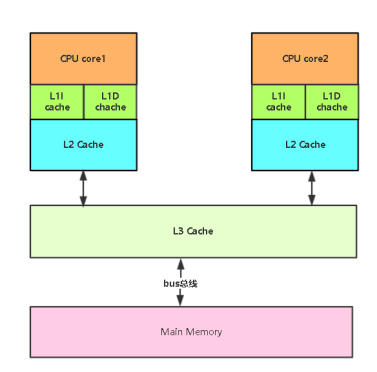
上图是常见的现代计算机CPU的三级缓存架构图,缓存是为了解决CPU和内存之间的频率不匹配问题,但缓存又带来新的问题:数据一致性问题,常见的解决方式有:1.bus总线锁、2.缓存一致性协议。
bus总线锁代价大
缓存一致性协议: MESI协议缓存状态(Modified、Exclusive、shared、invalid)涉及到本地读、本地写、远端读、远端写等操作指令,十分复杂,JMM(Java Memory Model)正是为了解决与底层操作系统指令耦合的问题,从而在JVM层面抽象出来的模型:
理论上Java程序员只需要关注JMM模型就可以写出“正确的”并发代码,但是一些性能优化的问题,比如伪共享等,还是需要回归到CPU三级缓存架构去理解。
Java并发编程的三个概念
原子性:即一个操作或者多个操作,要么全部执行并且的过程不会被任何因素打断,要么就都不执行。
可见性:是指当多个线程访问同一变量时,一个线程修改了这个变量的值其他线程能够立即看得到修改的值。
有序性:即程序执行的顺按照代码先后顺序(编译优化、指令重排等会影响)
线程池原理
线程池体系介绍
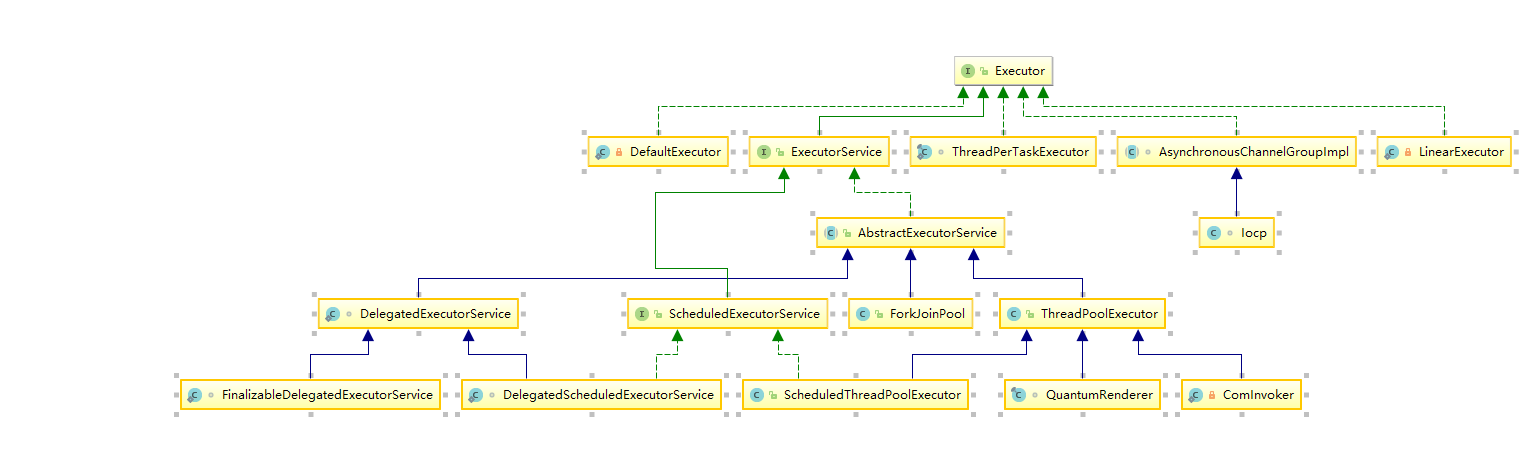
普通线程池ThreadPoolExecutor
定时线程池ScheduledThreadPoolExecutor
| 层级 | 名称 | 方法 | 说明 | 类型 |
|---|---|---|---|---|
| 1 | java.util.concurrent.Executor | java.util.concurrent.Executor#execute | 执行接口 | 接口 |
| 2 | java.util.concurrent.ExecutorService | java.util.concurrent.ExecutorService#submit(java.util.concurrent.Callable |
提交接口 | 接口 |
| 3 | java.util.concurrent.AbstractExecutorService | java.util.concurrent.AbstractExecutorService#submit(java.util.concurrent.Callable |
把执行和提交接口进行合并 | 抽象类 |
| 4 | java.util.concurrent.ThreadPoolExecutor | java.util.concurrent.ThreadPoolExecutor#execute | 调用 addwork( offer->task) Run方法调用 runwork方法 getTask(从队列 拿数据) |
实现类 |
| 5 | java.util.concurrent.ScheduledExecutorService | Schedule、 scheduleAtFixedRat、 scheduleWithFixedDelay | 定义方法 | 接口 |
| 6 | java.util.concurrent.ScheduledThreadPoolExecutor | delayedExecute | 具体实现 add->task->addWork |
实现类 |
ThreadPoolExecutor原理分析

5个内部类分两种类型: policy(策略) worker(工人)
内部工作原理 (构造方法赋值)
- corePoolSize :池中所保存的常驻线程数,空闲时不会被杀死
- maximumPoolSize:池中允许的最大线程数
- keepAliveTime: 当线程数大于核心时,此为终止前多余的空闲等待新任务最长间 当线程数大于核心时,此为终止前多余的空闲等待新任务最长间
- unit:keepAliveTime 参数的时间单位 参数的时间单位
- workQueue :执行前用于保持任务的队列。此仅由 execute方法提交的 Runnable任务
- threadFactory:执行程序创建新线时使用的工厂
- handler:超出线程数范围和队列容量时执行的策略
线程池核心算法
- 如果poolSize小于corePoolSize ,则创建新线程执行任务
- 如果poolSize大于corePoolSize ,且等待队列未满则进入队列
- 如果等待队列已满且poolSize大于corePoolSize 但小于maximumPoolSize,则创建新线程执行任务
- 以上都不满足则调用拒绝策略
- AbortPolicy:抛出异常, 默认
- CallerRunsPolicy:不使用线程池执行,任务将由调用者线程去执行
- DiscardPolicy:直接丢弃任务
- DiscardOldestPolicy:丢弃队列中最老的任务

线程池核心流程
(以上方法分别指:
java.util.concurrent.ThreadPoolExecutor#execute、java.util.concurrent.ThreadPoolExecutor#addWorker、java.util.concurrent.ThreadPoolExecutor#runWorker、java.util.concurrent.ThreadPoolExecutor#processWorkerExit)
ForkJoinPool
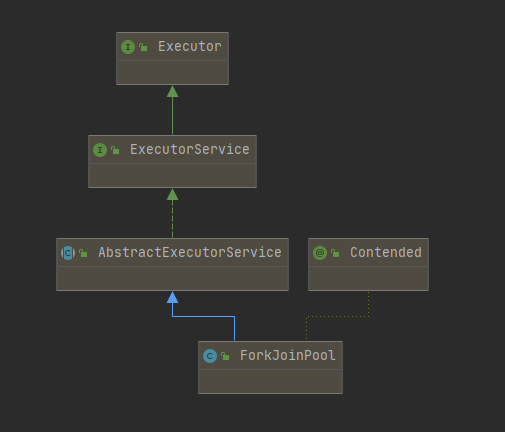
ForkJoinPool也继承自AbstractExecutorService,这意味着ThreadPoolExcutor该有的方法ForkJoinPool也有。
ForkJoin原理
- Java 1.7 引入了一种新的并发框架—— Fork/Join Framework 主要用于实现“分而治之”的算法,特别是分治之后递归调用的函数
- 提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架
- 与ThreadPool共存,并不是要替换ThreadPool
分治法 (Divide and Conquer)
基本思想:把一个规模大的问题划分为规模较小的子问题,然后分而治之,最后合并子问题的解得到原问题的解。
步骤:
- 分割原问题
- 求解子问题
- 合并子问题的解为原问题的解
在分治法中,子问题一般是相互独立的,因此,经常通过递归调用算法来求解子问题。
用一段伪代码表达ForkJoin的核心思想:
R solve(Problem<R> problem) {if (problem.isSmall())return problem.solveSequentially();R leftResult,rightResult;CONCURRENT {leftResult = solve(problem.left());rightResult = solve(problem.right());}return problem.combine(leftResult,rightResult);}
ForkJoinPool 框架主要类:
- ForkJoinPool 实现ForkJoin的线程池 - ThreadPool
- ForkJoinWorkerThread 实现ForkJoin的线程
- ForkJoinTask
一个描述ForkJoin的抽象类 Runnable/Callable - RecursiveAction 无返回结果的ForkJoinTask实现Runnable
- RecursiveTask
有返回结果的ForkJoinTask实现Callable - CountedCompleter
在任务完成执行后会触发执行一个自定义的钩子函数
- ForkJoinPool 实现了Executor Service 接口
- ExecutorService 是Java Executor框架的基础类
- 其他ExecutorService的实现执行Runnable或Callables任务
- ForkJoinPool执行ForkJoinTasks任务
- ForkJoinPool 实现了Executor Service 接口
- ExecutorService 是Java Executor框架的基础类
- 其他ExecutorService的实现执行Runnable或Callables任务
- ForkJoinPool执行ForkJoinTasks任务
- Executors. newWorkStealPool创建ForkJoinPool
| 返回值 | 方法签名 |
| —- | —- |
| void | execute(ForkJoinTask<?> task)
execute(Runnable task) | | T | invoke(ForkJoinTasktask) | | List > tasks) | |
ForkJoinTask
submit(ForkJoinTask
submit(Callable
submit(Runnable task)
submit(Runnable task, T result) |
- ForkJoinTask封装了数据及其相应的计算
- 支持细粒度的数据并行
- ForkJoinTask比线程要轻量
- ForkJoinPool中少量工作线程能够运行大量的ForkJoinTask
- ForkJoinTask主要包括两个方法分别实现任务的分拆与合并:

- fork()类似于Thread.start(),但是它并不立即执行任务,而是将任务放入工作队列中
- 跟Thread.join()不同,ForkJoinTask的join()方法并不简单的阻塞线程
- 利用工作线程运行其他任务
- 当一个工作线程中调用join(),它将处理其他任务,直到注意到目标子任务已经完成
ForkJoinTask有3个子类:
ForkJoinPool中的所有的工作线程均有一个自己的工作队列WorkQueue
- 双端队列(Deque)
- 从队头取任务
- 线程私有,不共享

- ForkJoinTask中fork的子任务,将放入运行该任务的工作线程的队头
- 工作线程以LIFO的顺序来处理它队列中的任务

- 为了最大化CPU利用率,空闲的线程将从其他线程的队列中“窃取”任务来执行
- 从工作队列的队尾“窃取”任务,以减少竞争
- 任务的“窃取”是以FIFO顺序进行的,因为先放入的任务往往表示更大的工作量
- 支持“窃取”线程进行进一步的递归分解
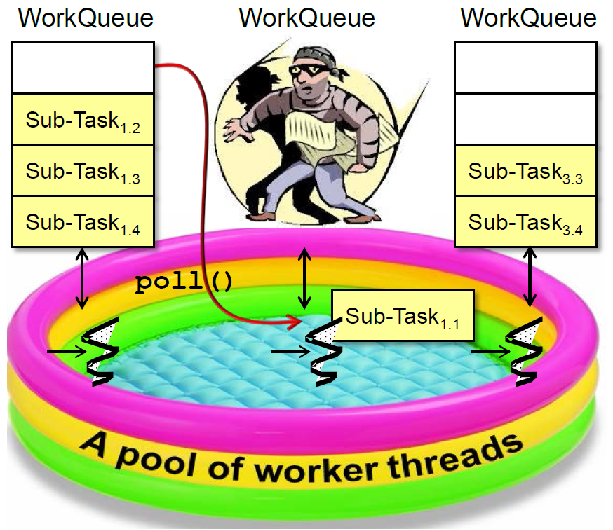
- WorkQueue双端队列最小化任务“窃取”的竞争
- push()/pop()仅在其所有者工作线程中调用 这些操作都是通过CAS来实现的,是Wait-free的
- poll() 则由其他工作线程来调用“窃取”任务
- 可能不是wait-free

ForkJoin最佳实践
- 按照需求分别继承RecursiveAction 、RecursiveTask、CountedCompleter实现ForkJoin(样例代码在:https://github.com/DandyLuo/java-async-demos,async.demo.forkjoin路径下)
- 最适合的是计算密集型的任务
- 在需要阻塞工作线程时,可以使用 ManagedBlocker。是否内联方法
- If one of the FJ Threads has to block, a new thread can be started to take its place
- 不应该在RecursiveTask
的内部使用ForkJoinPool.invoke() - ForkJoin算法的核心思想是通过分割数据,并行执行,故而有三个要求:
- Don’t share
- Don’t mutate
- Coordinate access
——出自《From Concurrent to Parallel》
ForkJoin的反思
如果我们从ForkJoin的核心算法Divide and Conquer出发,很容易发现此算法其实对数据结构与场景有比较严格的要求,否则是难以达到ForkJoin的初衷的(Keep cpu busy in useful calculation)
- 需要考虑数据结构是否天生易于spilit,比如array是而linkedList不是,在不适用场景下使用ForkJoin会导致性能大部分浪费在spilit的操作上。
- 需要数据结构是否易于merge,比如array是而map不是,倘若我们使用map作为容器来实现分治,要么是需要多次创建一个新的map,再进行数据迁移;要么是制造一个新的外观map:将两个旧的map维护进一个引用集,而无论是哪种方案显然都耗费了大量的代价在分治本身而不在计算任务。
- 需要进行多种考量甚至测算,诸如:任务的NQ模型是否足够大(),任务本身是否足够复杂,机器的CPU性能是多少,程序并行执行的提升是否覆盖ForkJoin本身带来的额外开销。
ParallelStream
并行流内部使用了默认的ForkJoinPool,它默认的线程数量就是你的处理器数量,这个值是由Runtime.getRun
time().available- Processors()得到的。但是你可以通过系统属性java.util.concurrent.ForkJoinPool.common.parallelism来改变线程池大小,如下所示: System.setProperty(“java.util.concurrent.ForkJoinPool.common.parallelism”,”12”); 这是一个全局设置,因此它将影响代码中所有的并行流。反过来说,目前还无法专为某个 并行流指定这个值。一般而言,让ForkJoinPool的大小等于处理器数量是个不错的默认值, 除非你有很好的理由,否则我们强烈建议你不要修改它。
——引自《java 8 实战》
什么场景可以使用ParallelStream?如何正确地使用ParallelStream?
适用场景分析
CPU密集型任务。计算类型就属于CPU密集型了,这种操作并行流就能提高运行效率。
public void mockJob(final int size) {final long mainStartTime = System.currentTimeMillis();//开始并行执行IntStream.range(0, size).parallel().forEach(i -> {try {//模拟CPU运算时间Thread.sleep(1000);System.err.println("index:" + i + "," + "currentThread:" + Thread.currentThread().getName());} catch (final InterruptedException e) {e.printStackTrace();}});final long mainEndTime = System.currentTimeMillis();System.out.println("执行完毕,总共耗时:" + (mainEndTime - mainStartTime));}
我们需要保证在流中使用的共享变量是线程安全的。以下是一个误用的例子:
/*** 错误原因:在parallelStream内使用线程不安全的容器ArrayList* @param size* @return highly possible not equal to size* @throws java.lang.ArrayIndexOutOfBoundsException*/public int addToList(final int size) {final List<Integer> values = new ArrayList<>();IntStream.range(0, size).parallel().forEach(values::add);return values.size();}
以下是两个正确的例子:
/*** parallel add to List** @param size** @return exactly equal to size*/public int threadSafeAddToList(final int size) {final List<Integer> values = new CopyOnWriteArrayList<>();IntStream.range(0, size).parallel().forEach(values::add);return values.size();}/*** parallel add to List** @param values** @return exactly equal to values.size*/public int threadSafeAddToList2(final List<Integer> values) {if (CollectionUtils.isEmpty(values)) {return 0;}List<Integer> collect = values.stream().parallel().collect(Collectors.toList());return collect.size();}
可以看到解决方案是:1.使用线程安全的容器。2.使用collect()操作。
再来看一个常用的使用场景:并行计算数组对象中某个属性之和
/**
* 正确示范
* 计算总和
*
* @param entityList
*
* @return exactly equal to size
*/
public static int sum(final List<Entity> entityList) {
return entityList.stream().parallel().mapToInt(Entity::getPrice).sum();
}
不适用场景
- I/O密集型方法的任务就不适合用ParallelStream,比如磁盘I/O、网络I/O等操作,这部分操作是较少消耗CPU资源。一般ParallelStream不适用于I/O密集型的操作,比如调用远程服务或者进行大批量的消息推送等。由于我们系统中的I/O操作一般是阻塞型I/O调用,即使用ParallelStream作用也不大,由于ParallelStream底层统一使用ForkJoinPool.common线程池处理,如果在流中执行阻塞操作可能会长时间占用线程资源。
有状态操作不能使用并行流,会由于线程调度而得到不可预测的结果。以下摘自Oracle的官方文档(原文链接:https://docs.oracle.com/javase/8/docs/api/java/util/stream/package-summary.html#Statelessness): ``` …..An example of a stateful lambda is the parameter to map() in:
Set
seen = Collections.synchronizedSet(new HashSet<>()); stream.parallel().map(e -> { if (seen.add(e)) return 0; else return e; })…
Here, if the mapping operation is performed in parallel, the results for the same input could vary from run to run, due to thread scheduling differences, whereas, with a stateless lambda expression the results would always be the same.
再来简单解释一下有状态和无状态这个概念:有状态操作指的是操作之间会互相关联或影响,调换数据的访问顺序会影响到执行结果;而无状态操作则相反,操作之间互不干扰。
```java
//有状态操作使用了并行流,结果不可预测
final AtomicReference<Integer> last = new AtomicReference<>(1);
Integer sum1 = (IntStream.range(0, 4).parallel().map(e -> {
final Integer tempLast = last.get();
last.set(e);
return tempLast;
}).sum());
//无状态操作,结果稳定
Integer sum2 = (IntStream.range(0, 4).parallel().sum());
CompletableFuture
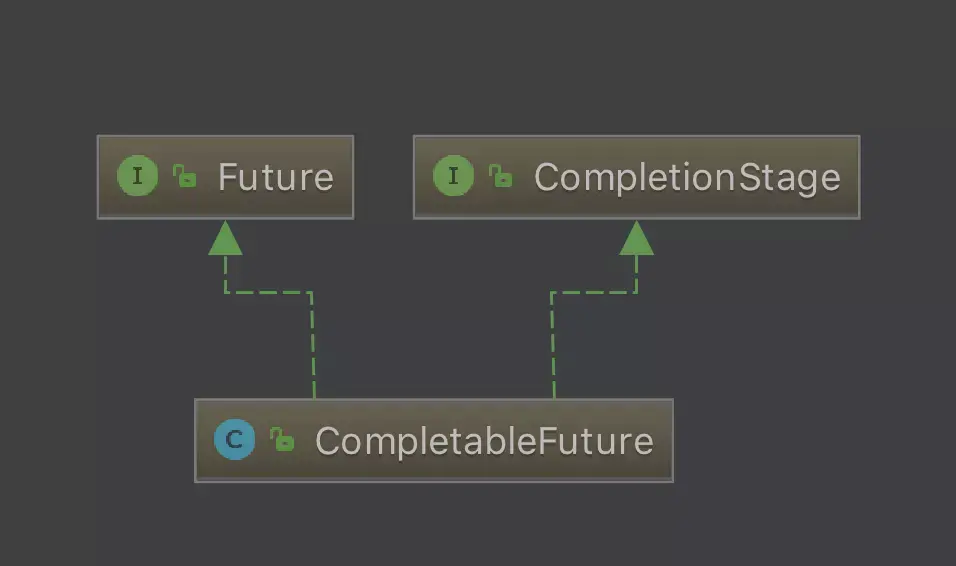
JDK5中新增的Future提供了异步任务的处理能力,但调用get()方法获取结果是阻塞的,或者通过isDone()方法轮询。为了解决这个弊端,JDK8推出了CompletableFuture特性。
CompletableFuture实现了CompletionStage和Future接口
引用JDK官方文档解释:
- CompletableFuture是一个在完成时可以触发相关方法和操作的Future,并且它可以视作为CompletableStage。
- 除了直接操作状态和结果的这些方法和相关方法外(CompletableFuture API提供的方法),CompletableFuture还实现了以下的CompletionStage的相关策略:
- 非异步方法的完成,可以由当前CompletableFuture的线程提供,也可以由其他调用完方法的线程提供。
- 所有没有显示使用Executor的异步方法,会使用ForkJoinPool.commonPool()(那些并行度小于2的任务会创建一个新线程来运行)。为了简化监视、调试和跟踪异步方法,所有异步任务都被标记为CompletableFuture.AsynchronouseCompletionTask。
- 所有CompletionStage方法都是独立于其他公共方法实现的,因此一个方法的行为不受子类中其他方法的覆盖影响。
- CompletableFuture还实现了Future的以下策略:
- 不像FutureTask,因CompletableFuture无法直接控制计算任务的完成,所以CompletableFuture的取消会被视为异常完成。调用cancel()方法会和调用completeExceptionally()方法一样,具有同样的效果。isCompletedEceptionally()方法可以判断CompletableFuture是否是异常完成
- 在调用get()和get(long, TimeUnit)方法时以异常的形式完成,则会抛出ExecutionException,大多数情况下都会使用join()和getNow(T),它们会抛出CompletionException
简单来说CompletableFuture封装了Future,使其拥有组合多个任何、回调等新能力。
使用方法与场景
api演示(代码可见https://github.com/DandyLuo/java-async-demos,async.demo.completablefuture.Demo):
/**
* 模拟耗时工作
*
* @param size
*
* @return
*/
public static List<CompletableFuture<Void>> getFutureList(final int size) {
final List<CompletableFuture<Void>> list = new ArrayList<>(size);
IntStream.range(0, size).forEach(num ->
list.add(CompletableFuture.runAsync(() ->
System.out.println(Thread.currentThread().getName() + " job done"))));
return list;
}
public static void main(final String[] args) throws ExecutionException, InterruptedException {
//接收参数为Runnable,无返回值
CompletableFuture.runAsync(() -> System.out.println(Thread.currentThread().getName() + " job done"));
//接收参数为Supplier,有返回值
CompletableFuture.supplyAsync(() -> Thread.currentThread().getName()).get();
//组合操作
//thenRun:接受一个runnable ,无法读取前面的结果
CompletableFuture.supplyAsync(() -> Thread.currentThread().getName()).thenRun(() -> System.out.println("thenRun执行,无法拿到前置任务的结果"));
////thenApply:接收一个function,可以读取前面的结果并返回新的结果
final CompletableFuture<String> thenApplyFuture = CompletableFuture.supplyAsync(() -> Thread.currentThread().getName()).thenApply(e -> "thenApply添加" + e);
System.out.println(Thread.currentThread().getName() + thenApplyFuture.get());
//thenAccept:可以接收一个consumer,能读取到前面的结果
CompletableFuture.supplyAsync(() -> Thread.currentThread().getName()).thenAccept(e -> System.out.println("then accept 可以收到前置任务的结果为:" + e));
//whenComplete:可以设置回调函数
final CompletableFuture<String> whenCompleteFuture = CompletableFuture.supplyAsync(() -> Thread.currentThread().getName());
//设置回调,t代表异常thrown
whenCompleteFuture.whenComplete((e, t) -> System.out.println(Thread.currentThread().getName() + "whenComplete " + e));
//thenCombine:收集前面的和当前的CompletableFuture的返回值作为参数,传递给function
final CompletableFuture<String> thenCombineFuture = CompletableFuture.supplyAsync(() -> "then").thenCombine(CompletableFuture.supplyAsync(() -> "combine"), (a, b) -> a + " + " + b);
System.out.println(thenCombineFuture.get());
//thenCompose:前面的CompletableFuture返回值可以作为下一个CompletableFuture的参数
final CompletableFuture<String> thenComposeFuture = CompletableFuture.supplyAsync(() -> "then").thenCompose(str -> CompletableFuture.supplyAsync(() -> str + " + compose"));
System.out.println(thenComposeFuture.get());
//all of: 当所有CompletableFuture完成时,使用一个新的CompletableFuture接收结果
final List<CompletableFuture<Void>> allOfList = Demo.getFutureList(50);
final CompletableFuture<Void> all = CompletableFuture.allOf(allOfList.toArray(new CompletableFuture[0]));
//这里返回就代表列表中所有的future全返回了
all.get();
System.out.println(allOfList.stream().filter(e -> !e.isDone()).count());
//any of :当任何一个CompletableFuture完成时,使用一个新的CompletableFuture接收结果
final List<CompletableFuture<Void>> anyOfList = Demo.getFutureList(50);
final CompletableFuture<Object> any = CompletableFuture.anyOf(anyOfList.toArray(new CompletableFuture[0]));
any.get();
System.out.println(anyOfList.stream().filter(e -> !e.isDone()).count());
}
Completable
适用场景:
- 多个任务互相依赖,在前缀任务完成时获取返回值以进行下一个任务
- 多任务同时作业,在结果都准备好时执行回调函数
举例说明:
场景1:前台应用需要聚合多个中台提供的dubbo的返回结果
public class Demo2 {
RemoteService remoteService = new RemoteService();
@Data
@AllArgsConstructor
@NoArgsConstructor
public class FrontEntity {
private Long id;
private String contentA;
private String contentB;
}
private class RemoteService {
public final ConcurrentMap<Long, EntityA> repositoryA = new ConcurrentHashMap<>();
public final ConcurrentMap<Long, EntityB> repositoryB = new ConcurrentHashMap<>();
public final String contentRepository = "ABCDEFGHIJKLMNOPQ";
{
LongStream.range(1, 101).forEach(id ->
{
this.repositoryA.put(id, new EntityA(id, this.contentRepository.charAt(RandomUtils.nextInt(0, 17)) + ""));
this.repositoryB.put(id, new EntityB(id, this.contentRepository.charAt(RandomUtils.nextInt(0, 17)) + ""));
});
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public class EntityA {
private Long id;
private String contentA;
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public class EntityB {
private Long id;
private String contentB;
}
private EntityA getEntityA(final Long id) {
try {
Thread.sleep(1000);
return this.repositoryA.getOrDefault(id, null);
} catch (final InterruptedException e) {
e.printStackTrace();
}
return null;
}
private EntityB getEntityB(final Long id) {
try {
Thread.sleep(1000);
return this.repositoryB.getOrDefault(id, null);
} catch (final InterruptedException e) {
e.printStackTrace();
}
return null;
}
}
private FrontEntity aggregateResult(final Long id) throws ExecutionException, InterruptedException {
if (null == id) {
return new FrontEntity();
}
final CompletableFuture<FrontEntity> completableFuture = CompletableFuture.supplyAsync(() -> this.remoteService.getEntityA(id))
.thenCombine(
CompletableFuture.supplyAsync(() -> this.remoteService.getEntityB(id)),
(a, b) -> new FrontEntity(a.getId(), a.getContentA(), b.getContentB()));
return completableFuture.get();
}
public static void main(final String[] args) throws ExecutionException, InterruptedException {
final long start = System.currentTimeMillis();
System.out.println(new Demo2().aggregateResult(2L));
final long end = System.currentTimeMillis();
System.out.printf("耗时:%s", end - start);
}

线性调用耗时:O(A) + O(B),并发调用耗时:Max(A,B),所以这里耗时只需1046毫秒而不是2000+ms
场景2:批量修改任务+消息中间件的异步场景
public class RemoteService {
public static final RemoteService WORKER = new RemoteService();
//模拟数据库
public static final ConcurrentMap<Long, Entity> REPOSITORY = new ConcurrentHashMap<>();
public static final String CONTENT_REPOSITORY = "ABCDEFGHIJKLMNOPQ";
//模拟消息中间件
public static final ConcurrentMap<Long, String> MESSAGE_MAP = new ConcurrentHashMap<>();
static {
LongStream.range(1, 101).forEach(id ->
{
REPOSITORY.put(id, new Entity(id, CONTENT_REPOSITORY.charAt(RandomUtils.nextInt(0, 17)) + ""));
});
}
private Entity getEntity(final Long id) {
try {
Thread.sleep(1000);
return REPOSITORY.getOrDefault(id, null);
} catch (final InterruptedException e) {
e.printStackTrace();
}
return null;
}
private int updateEntity(final Entity entity) {
try {
Thread.sleep(100);
return null != REPOSITORY.put(entity.getId(), entity) ? 1 : 0;
} catch (final InterruptedException e) {
e.printStackTrace();
}
return 0;
}
private void reportFinish(final Long transactionId, final Throwable t) {
MESSAGE_MAP.put(transactionId, null != t ? "EXCEPTION" : "OK");
}
private void batchUpdate(final List<Entity> entityList, final Long transactionId) {
if (CollectionUtils.isEmpty(entityList)) {
return;
}
CompletableFuture.allOf(entityList.stream().map(entity ->
CompletableFuture.runAsync(() -> this.updateEntity(entity))).toArray(CompletableFuture[]::new))
.whenComplete((v, t) -> this.reportFinish(transactionId, t));
}
public static void main(String[] args) throws InterruptedException {
System.out.println("before:" + REPOSITORY);
final List<Entity> entityList = new ArrayList<>(100);
LongStream.range(1, 101).forEach(id -> entityList.add(new Entity(id, (CONTENT_REPOSITORY.charAt(RandomUtils.nextInt(0, 17)) + "").toLowerCase())));
final Long transactionId = 1L;
WORKER.batchUpdate(entityList, transactionId);
//轮询,模拟消息中间件的消息消费
while (null == MESSAGE_MAP.get(transactionId)) {
Thread.sleep(100);
}
System.out.println("----" +
"after:" + REPOSITORY);
}
}
批量执行任务,生成一个CompletableFutureList,最终用一个CompletableFuture.allOf接收,当所有CompletableFuture执行完毕时whenComplete会触发回调函数,发送消息

若有收获,就点个赞吧
0 人点赞
