学习排序算法,除了要学习思路,代码实现之外,我们还要学会如何分析这个排序算法,那么,可以从那几个维度来入手分析呢,可以参照下面的思维导图: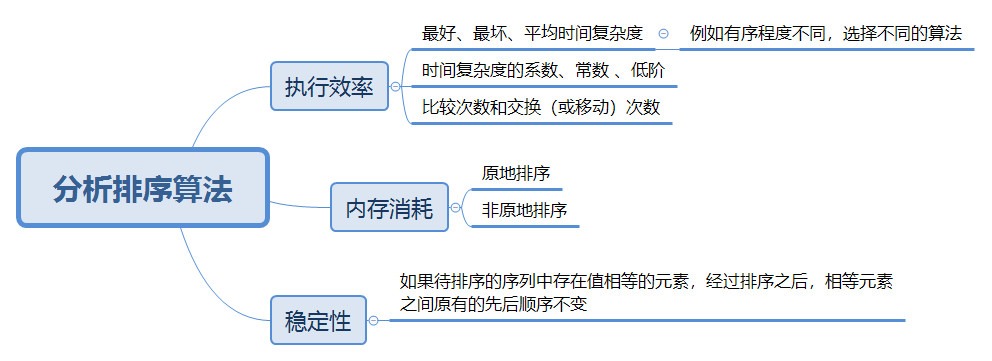
1. 冒泡排序
示例:排序以下元素:4,5,6,3,2,1
第一轮冒泡结果: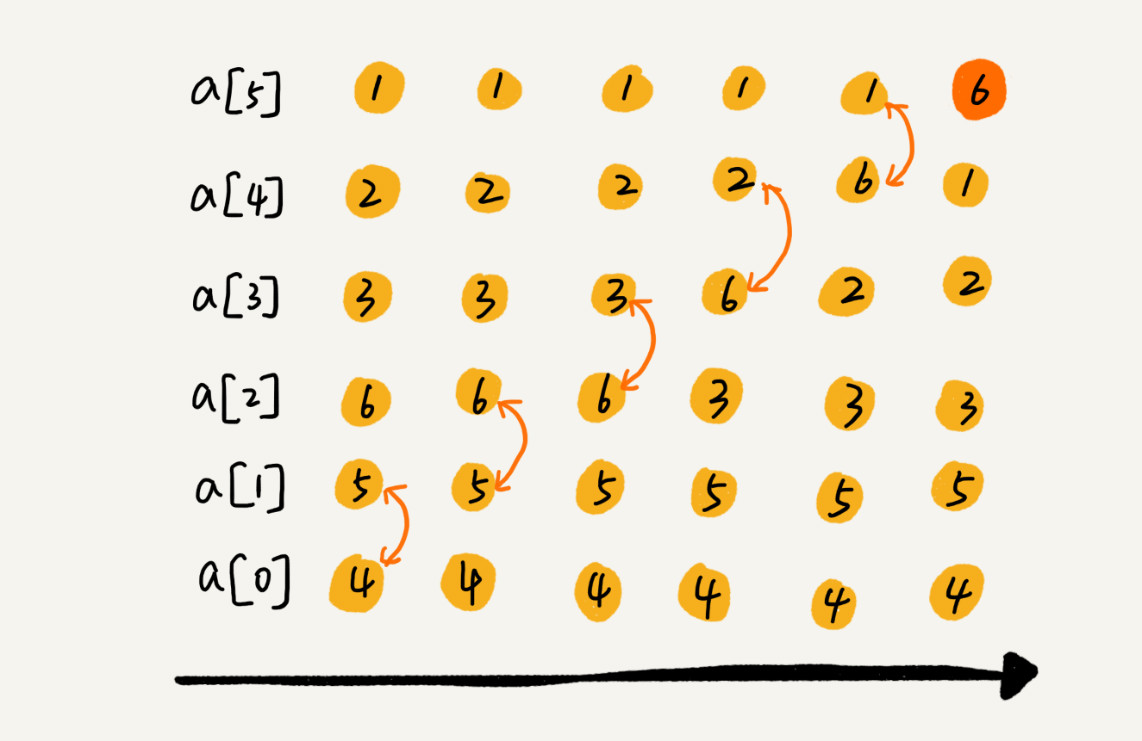
6已经在正确位置了,那么,为了完成排序,使得每个元素都在正确位置,那么我们只需要6次冒泡即可
当然,还有优化的步骤,如果排序过程中发现没有元素交换,说明已经是有序的了,那么不用再继续冒泡下去了,例如: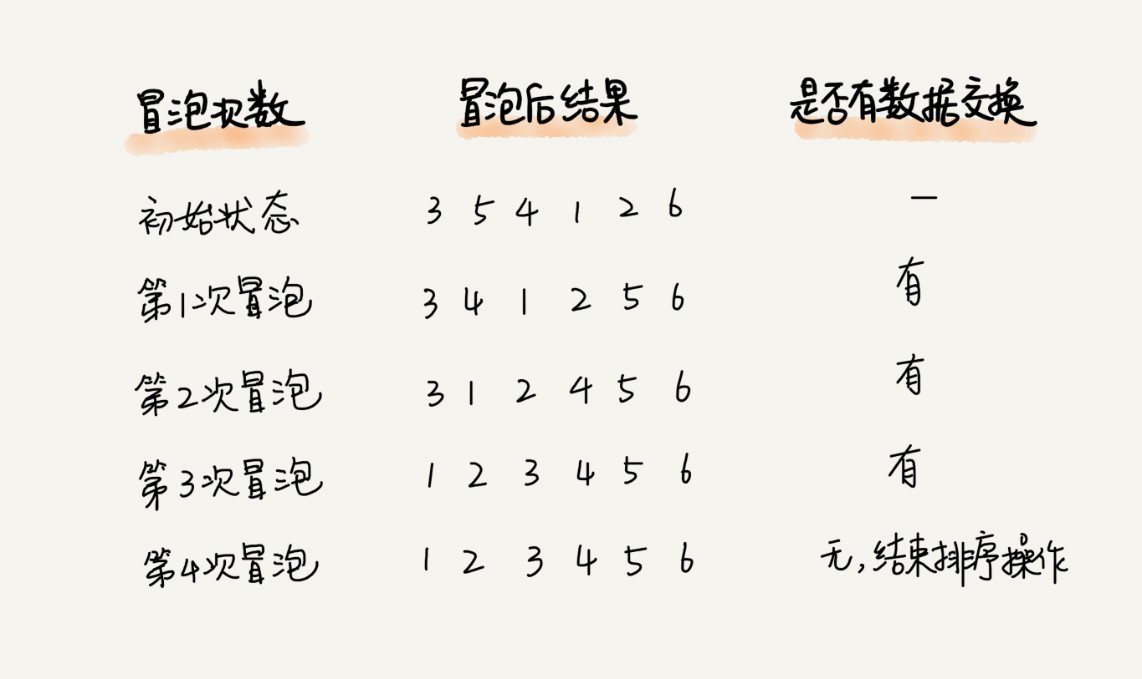
具体代码实现如下:
function bubbleSort(array, count) {if(count < 1) return;for(let i = 0; i < n; i++) {// 提前退出冒泡循环的标志位let isExchange = false;for(let j = 0; j < n - 1 - i; j++) {if(array[j] > array[j+1]) {let tmp = array[j];array[j] = array[j+1];array[j+1] = tmp;isExchange = true; // 表示有数据交换}}if(!isExchange) break; // 没有数据交换, 提前退出}}
冒泡排序分析: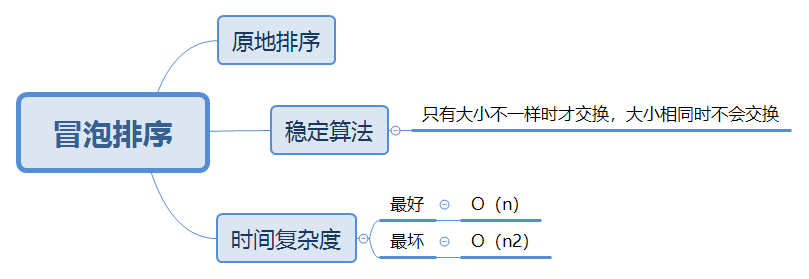
2. 插入排序
对于一个问题,如何在一个有序数组中插入元素,并保证数组仍然有序,这很简单嘛,我们可以从头遍历数组,然后在正确的位置插入即可
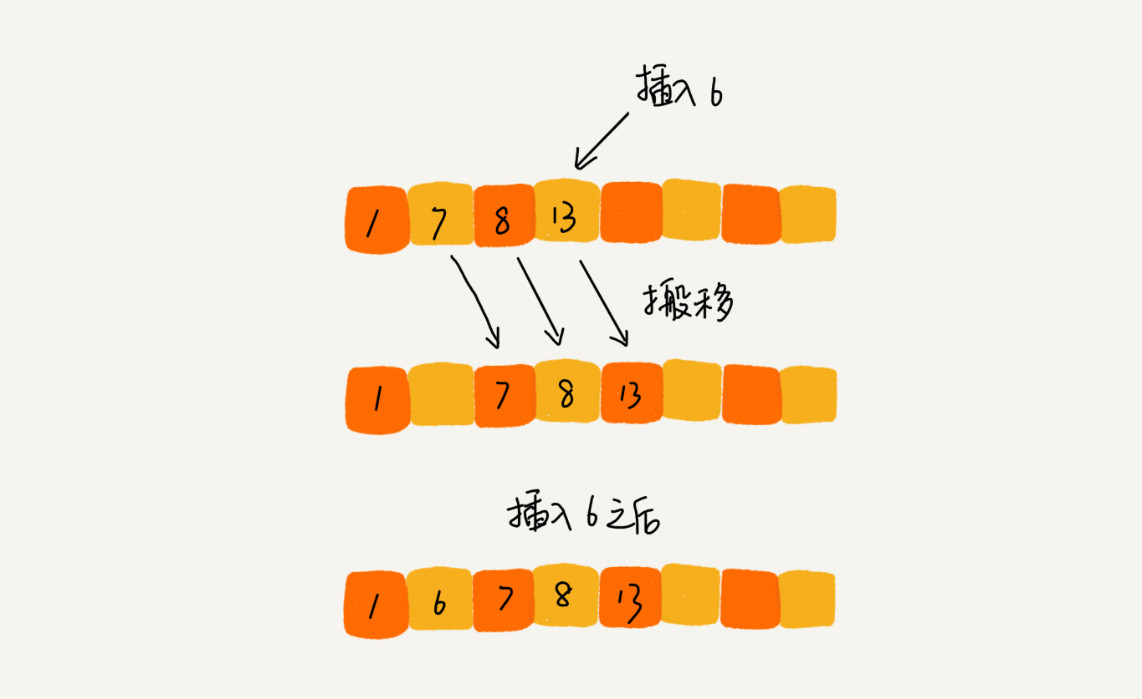
插入排序的思想也是如此,首先,我们将数组中的数据分为两个区间,已排序区间和未排序区间。初始已排序区间只有一个元素,就是数组的第一个元素。插入算法的核心思想是取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序。重复这个过程,直到未排序区间中元素为空,算法结束。
例如对于4,5,6,1,3,2,左边是已排序区间,右边是未排序区间
代码实现如下:
function insertionSort(arr, n) {if(n < 1) return;for(let i = 1; i < n; i++) {let value = arr[i];let j = i - 1;// 查找插入位置for(;j >= 0; --j) {if(arr[j] > value) {arr[j+1] = arr[j]; // 数据移动} else {break;}}arr[j + 1] = value;}}
插入排序分析:
3. 选择排序
选择排序算法的实现思路有点类似插入排序,也分已排序区间和未排序区间。但是选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾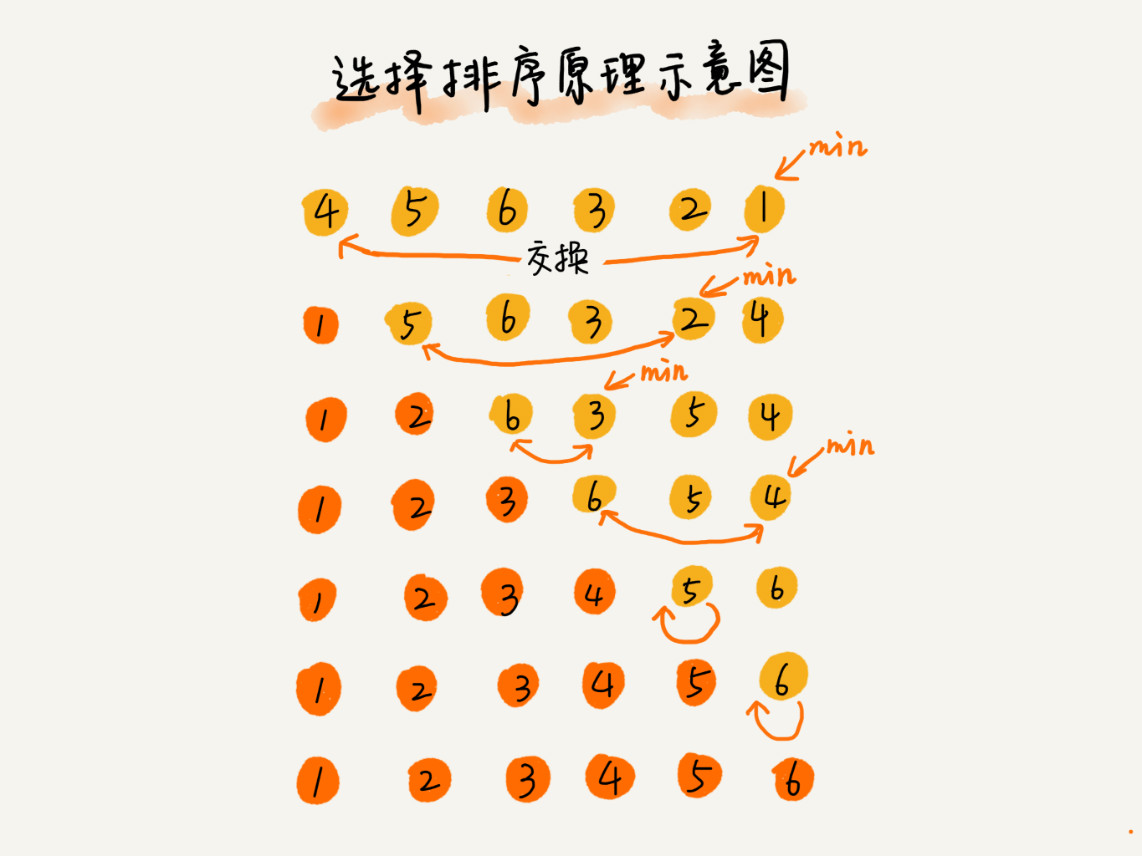
代码实现如下:
function selectionSort(arr, n) {
if(n < 1) return;
for(let i = 0; i < n; i++) {
let k = i;
for(let j = i + 1; j < n; j++) {
if(arr[j] < arr[k]) {
k = j;
}
}
if(k !== i) {
let tmp = arr[k];
arr[k] = arr[i];
arr[i] = tmp;
}
}
}
选择排序分析:
4. 冒泡对比插入
插入比冒泡好,原因如下,从代码实现上来看,冒泡排序的数据交换要比插入排序的数据移动要复杂,冒泡排序需要 3 个赋值操作,而插入排序只需要 1 个
// 冒泡排序中数据的交换操作:
if (a[j] > a[j+1]) { // 交换
let tmp = a[j];
a[j] = a[j+1];
a[j+1] = tmp;
flag = true;
}
// 插入排序中数据的移动操作:
if (a[j] > value) {
a[j+1] = a[j]; // 数据移动
} else {
break;
}
插入排序的算法思路也有很大的优化空间,我们只是讲了最基础的一种。如果对插入排序的优化感兴趣,可以学习一下希尔排序。
5. 归并排序
归并排序的核心思想还是蛮简单的。如果要排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了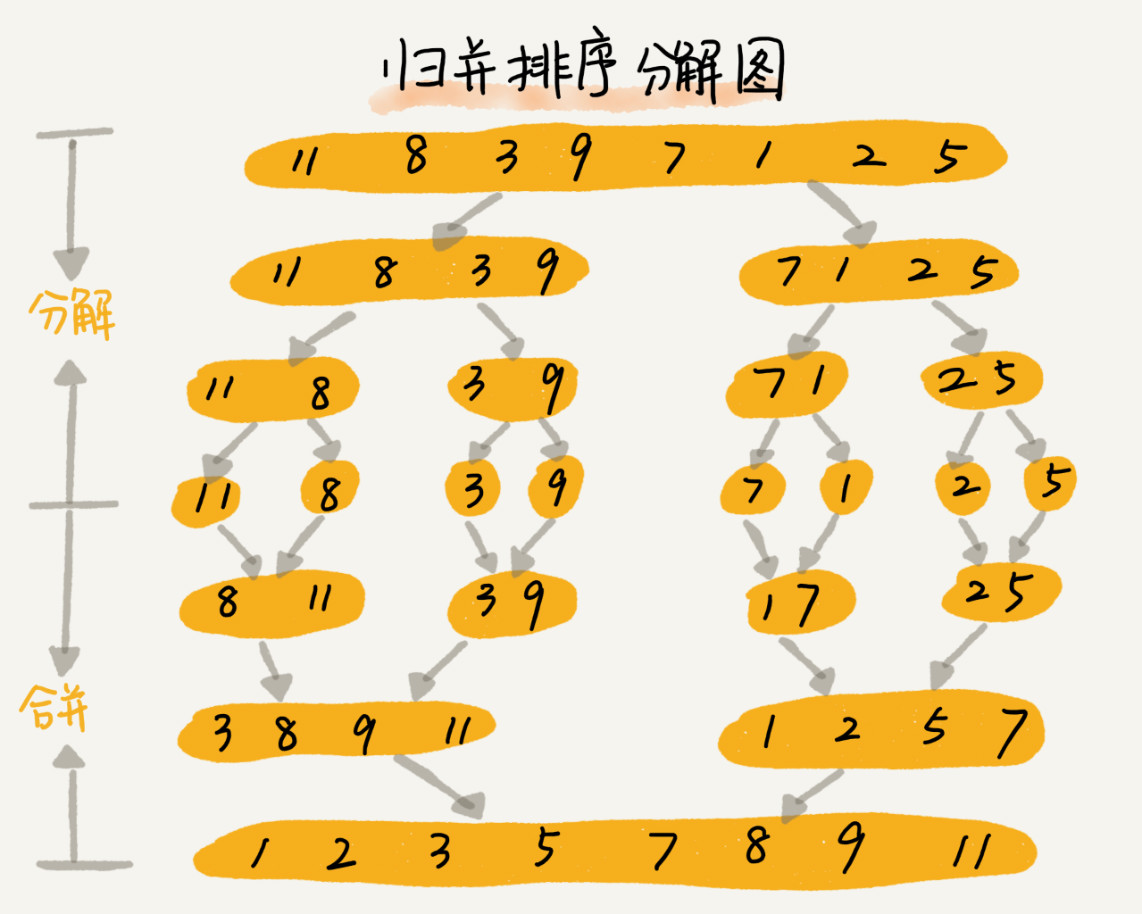
代码实现如下:
const mergeArr = (left, right) => {
let temp = []
let leftIndex = 0
let rightIndex = 0
// 判断2个数组中元素大小,依次插入数组
while (left.length > leftIndex && right.length > rightIndex) {
if (left[leftIndex] <= right[rightIndex]) {
temp.push(left[leftIndex])
leftIndex++
} else {
temp.push(right[rightIndex])
rightIndex++
}
}
// 合并 多余数组
return temp.concat(left.slice(leftIndex)).concat(right.slice(rightIndex))
}
const mergeSort = (arr) => {
// 当任意数组分解到只有一个时返回。
if (arr.length <= 1) return arr
const middle = Math.floor(arr.length / 2) // 找到中间值
const left = arr.slice(0, middle) // 分割数组
const right = arr.slice(middle)
// 递归 分解 合并
return mergeArr(mergeSort(left), mergeSort(right))
}
归并排序分析: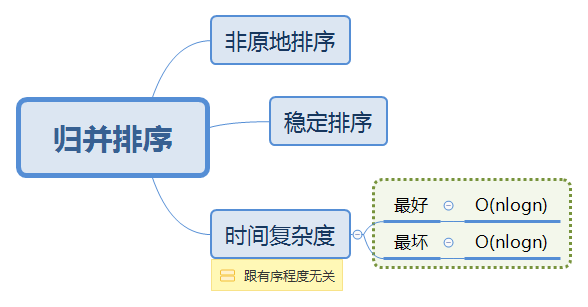
6. 快速排序
如果要排序数组中下标从 p 到 r 之间的一组数据,我们选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。我们遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。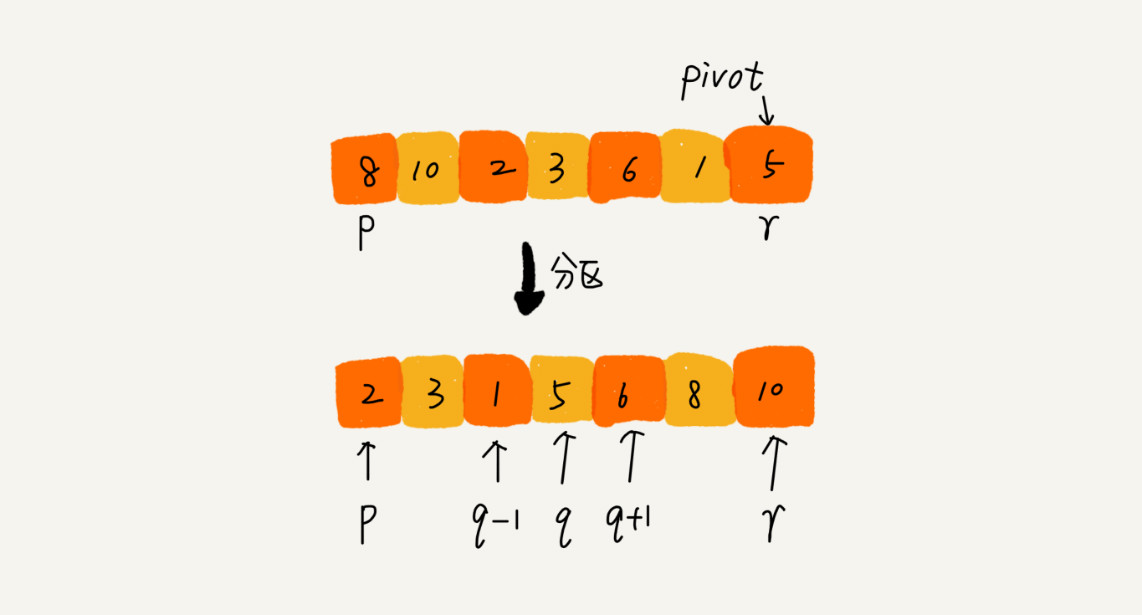
根据分治、递归的处理思想,我们可以用递归排序下标从 p 到 q-1 之间的数据和下标从 q+1 到 r 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。
const swap = (arr, i, j) => {
const temp = arr[i]
arr[i] = arr[j]
arr[j] = temp
}
// 获取 pivot 交换完后的index
const partition = (arr, pivot, left, right) => {
const pivotVal = arr[pivot]
let startIndex = left
for (let i = left; i < right; i++) {
if (arr[i] < pivotVal) {
swap(arr, i, startIndex)
startIndex++
}
}
swap(arr, startIndex, pivot)
return startIndex
}
const quickSort = (arr, left, right) => {
if (left < right) {
let pivot = right
let partitionIndex = partition(arr, pivot, left, right)
quickSort(arr, left, partitionIndex - 1 < left ? left : partitionIndex - 1)
quickSort(arr, partitionIndex + 1 > right ? right : partitionIndex + 1, right)
}
}
const testArr = []
let i = 0
while (i < 10) {
testArr.push(Math.floor(Math.random() * 1000))
i++
}
console.log('unsort', testArr)
quickSort(testArr, 0, testArr.length - 1);
console.log('sort', testArr)
partition() 分区函数。partition() 分区函数实际上我们前面已经讲过了,就是随机选择一个元素作为 pivot(一般情况下,可以选择 p 到 r 区间的最后一个元素),然后对 A[p…r]分区,函数返回 pivot 的下标。
如果我们不考虑空间消耗的话,partition() 分区函数可以写得非常简单。我们申请两个临时数组 X 和 Y,遍历 A[p…r],将小于 pivot 的元素都拷贝到临时数组 X,将大于 pivot 的元素都拷贝到临时数组 Y,最后再将数组 X 和数组 Y 中数据顺序拷贝到 A[p…r]。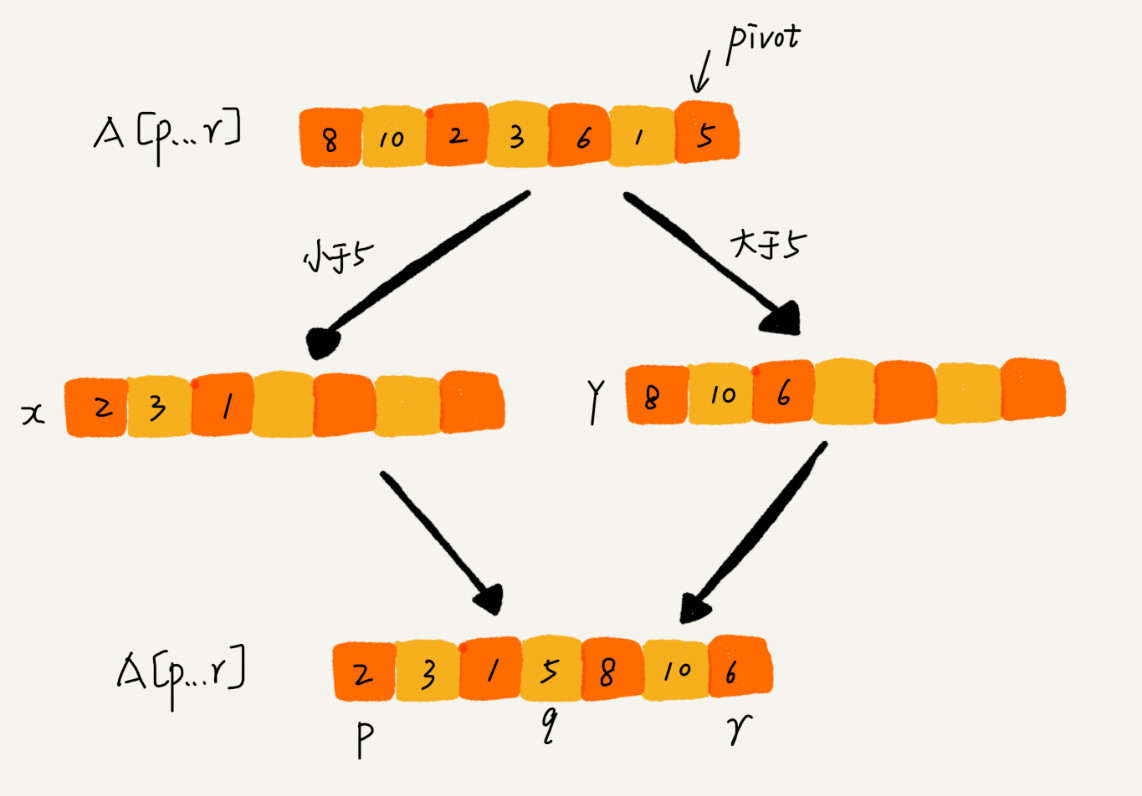
但是,如果按照这种思路实现的话,partition() 函数就需要很多额外的内存空间,所以快排就不是原地排序算法了。如果我们希望快排是原地排序算法,那它的空间复杂度得是 O(1),那 partition() 分区函数就不能占用太多额外的内存空间,我们就需要在 A[p…r]的原地完成分区操作。
伪代码如下:
partition(A, p, r) {
pivot := A[r]
i := p
for j := p to r-1 do {
if A[j] < pivot {
swap A[i] with A[j]
i := i+1
}
}
swap A[i] with A[r]
return i
这里的处理有点类似选择排序。我们通过游标 i 把 A[p…r-1]分成两部分。A[p…i-1]的元素都是小于 pivot 的,我们暂且叫它“已处理区间”,A[i…r-1]是“未处理区间”。我们每次都从未处理的区间 A[i…r-1]中取一个元素 A[j],与 pivot 对比,如果小于 pivot,则将其加入到已处理区间的尾部,也就是 A[i]的位置。数组的插入操作还记得吗?在数组某个位置插入元素,需要搬移数据,非常耗时。当时我们也讲了一种处理技巧,就是交换,在 O(1) 的时间复杂度内完成插入操作。这里我们也借助这个思想,只需要将 A[i]与 A[j]交换,就可以在 O(1) 时间复杂度内将 A[j]放到下标为 i 的位置。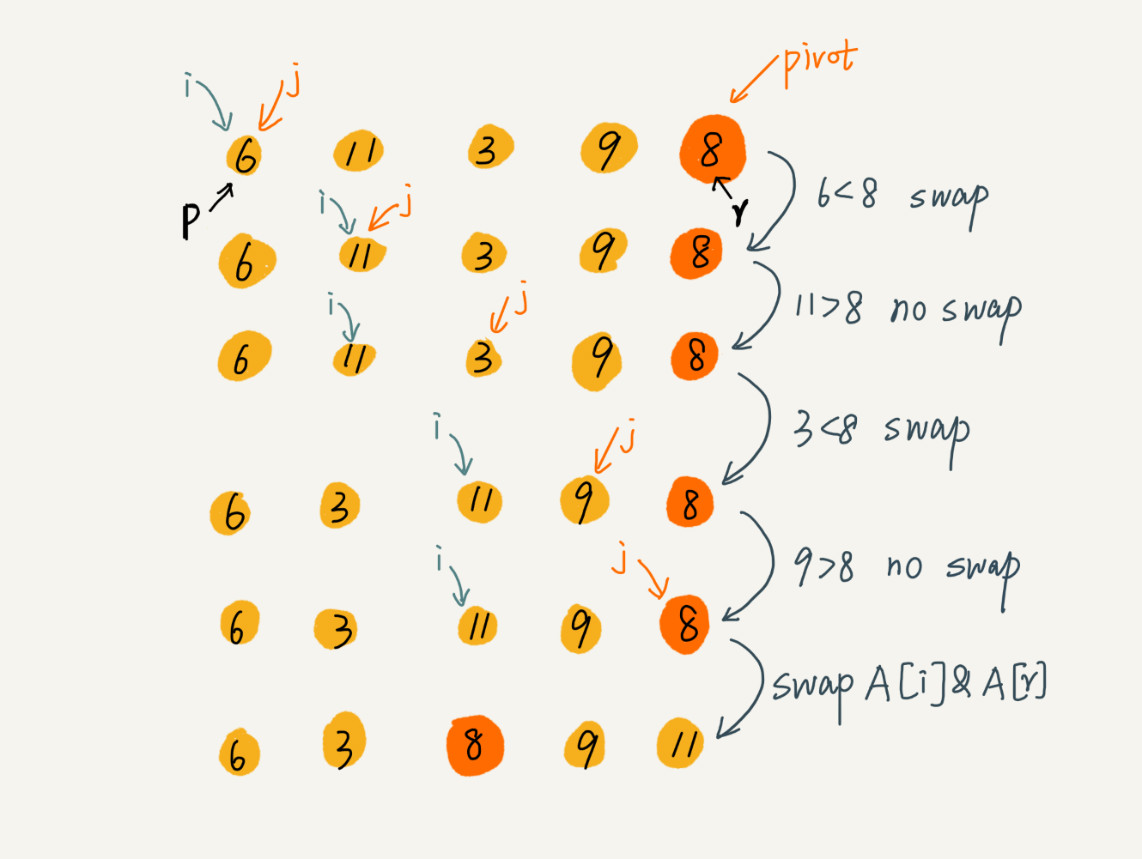
快速排序分析: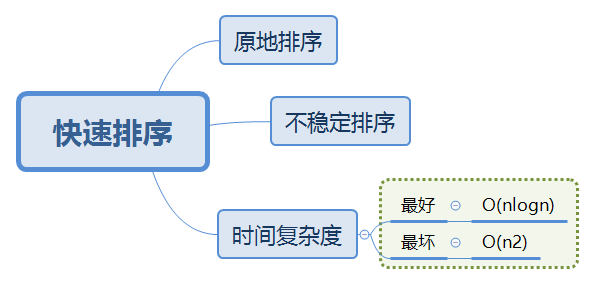
7. 算法动态演示站点

若有收获,就点个赞吧
0 人点赞
